Elastic Open Web Crawler와 CLI 기반 아키텍처를 사용하면 이제 버전이 관리되는 크롤러 구성과 로컬 테스트가 포함된 CI/CD 파이프라인을 매우 간단하게 구축할 수 있습니다.
기존에는 크롤러 관리가 수작업으로 이루어졌고 오류가 발생하기 쉬운 프로세스였습니다. UI에서 직접 구성을 편집하고 크롤링 구성 복제, 롤백, 버전 관리 등으로 어려움을 겪어야 했습니다. 크롤러 구성을 코드로 취급하면 소프트웨어 개발에서 기대하는 반복성, 추적성 및 자동화와 같은 이점을 제공함으로써 이 문제를 해결할 수 있습니다.
이 워크플로우를 사용하면 Elastic Web Crawler나 App Search Crawler와 같은 이전 Elastic Crawler에서는 훨씬 더 까다로웠던 롤백, 백업, 마이그레이션 작업을 위해 CI/CD 파이프라인에 Open Web Crawler를 더 쉽게 도입할 수 있습니다.
이 글에서는 그 방법을 알아보겠습니다:
- GitHub를 사용하여 크롤링 구성 관리하기
- 배포하기 전에 파이프라인을 테스트할 수 있는 로컬 설정이 있습니다.
- 메인 브랜치에 변경 사항을 푸시할 때마다 새로운 설정으로 웹 크롤러를 실행하도록 프로덕션 설정을 만듭니다.
프로젝트 리포지토리는 여기에서찾을 수 있습니다. 이 글을 쓰는 현재, 저는 Elasticsearch 9.1.3과 Open Web Crawler 0.4.2를 사용하고 있습니다.
필수 구성 요소
- Docker 데스크톱
- Elasticsearch 인스턴스
- SSH 액세스 권한이 있는 가상 머신(예: AWS EC2) 및 Docker가 설치된 가상 머신
단계
- 폴더 구조
- 크롤러 구성
- Docker-작성 파일(로컬 환경)
- 깃허브 액션
- 로컬 테스트
- 프로덕션에 배포
- 변경 및 다시 배포
폴더 구조
이 프로젝트의 파일 구조는 다음과 같습니다:
크롤러 구성
crawler-config.yml, 아래에 다음을 입력합니다:
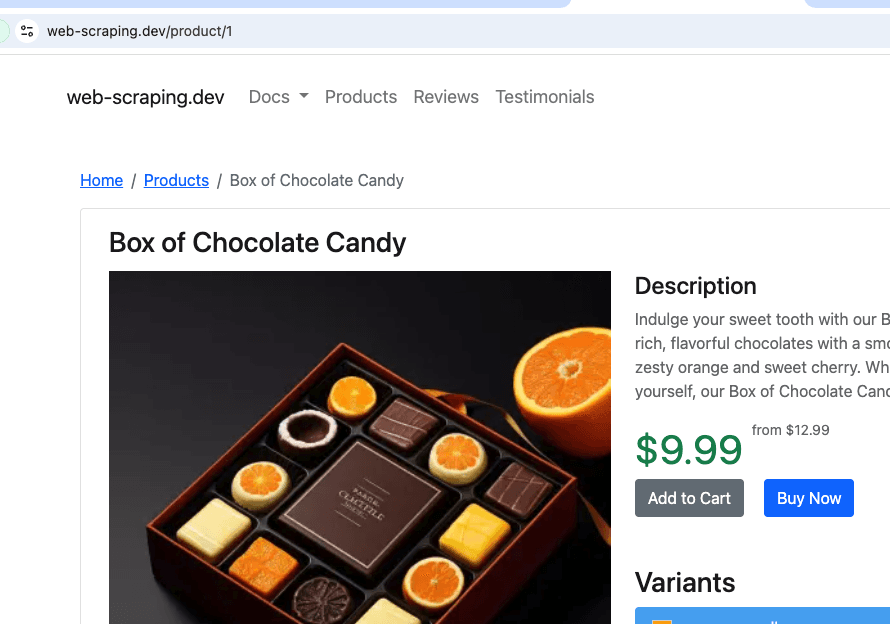
제품 모의 사이트인 https://web-scraping.dev/products 에서 크롤링됩니다. 처음 세 개의 제품 페이지만 크롤링합니다. max_crawl_depth 설정은 크롤러가 seed_urls 으로 정의된 페이지보다 더 많은 페이지를 발견하지 못하도록 하여 그 안의 링크를 열지 않도록 합니다.
Elasticsearch host 및 api_key 는 스크립트를 실행하는 환경에 따라 동적으로 채워집니다.
Docker-작성 파일(로컬 환경)
로컬 docker-compose.yml, 의 경우, 프로덕션에 배포하기 전에 크롤링 결과를 쉽게 시각화할 수 있도록 크롤러와 단일 Elasticsearch 클러스터 + Kibana를 배포합니다.
크롤러가 Elasticsearch를 실행할 준비가 될 때까지 기다리는 방식에 주목하세요.
깃허브 액션
이제 새 설정을 복사하고 메인으로 푸시할 때마다 가상 머신에서 크롤러를 실행하는 GitHub 액션을 만들어야 합니다. 이렇게 하면 가상 머신에 수동으로 들어가서 파일을 업데이트하고 크롤러를 실행할 필요 없이 항상 최신 구성이 배포되어 있습니다. 가상 머신 공급자로 AWS EC2를 사용하겠습니다.
첫 번째 단계는 호스트(VM_HOST), 머신 사용자(VM_USER), SSH RSA 키(VM_KEY), Elasticsearch 호스트(ES_HOST), Elasticsearch API 키(ES_API_KEY)를 GitHub Action 시크릿에 추가하는 것입니다:
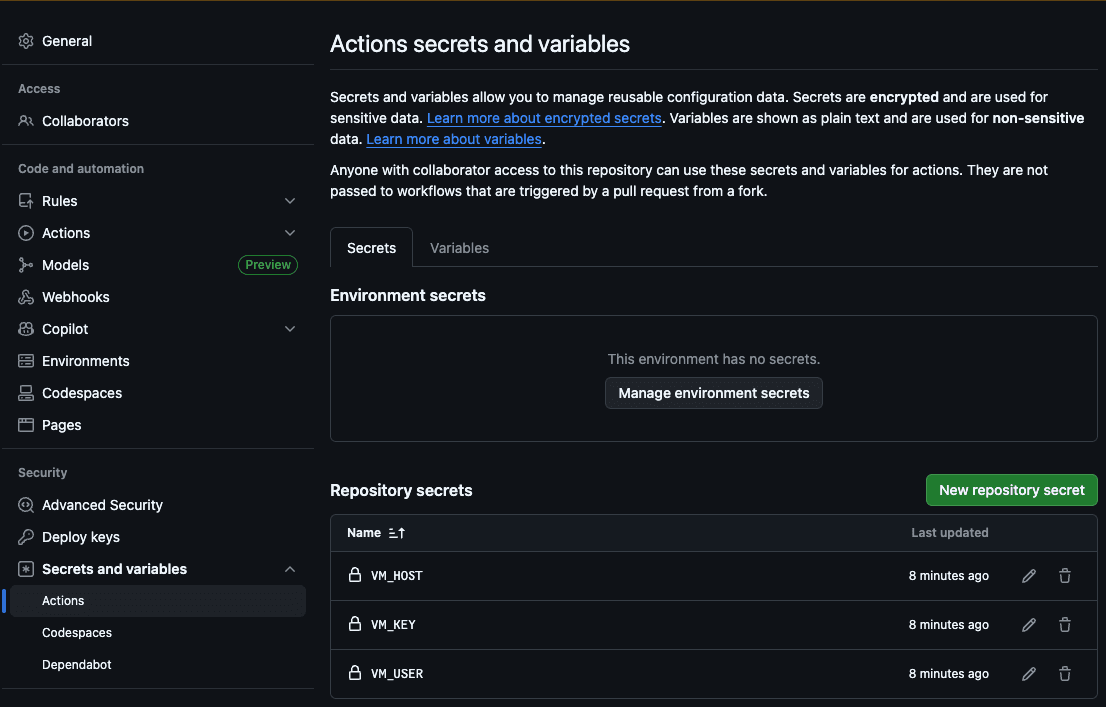
이렇게 하면 액션이 서버에 액세스하여 새 파일을 복사하고 크롤링을 실행할 수 있습니다.
이제 .github/workflows/deploy.yml 파일을 만들어 보겠습니다:
이 작업은 크롤러 구성 파일에 변경 사항을 푸시할 때마다 다음 단계를 실행합니다:
- yml 구성에서 Elasticsearch 호스트 및 API 키 채우기
- 구성 폴더를 VM에 복사합니다.
- SSH를 통해 VM에 연결
- 리포지토리에서 방금 복사한 구성으로 크롤링을 실행합니다.
로컬 테스트
로컬에서 크롤러를 테스트하기 위해, Docker의 로컬 호스트에 Elasticsearch 호스트를 채우고 크롤링을 시작하는 bash 스크립트를 만들었습니다. ./local.sh 을 실행하여 실행할 수 있습니다.
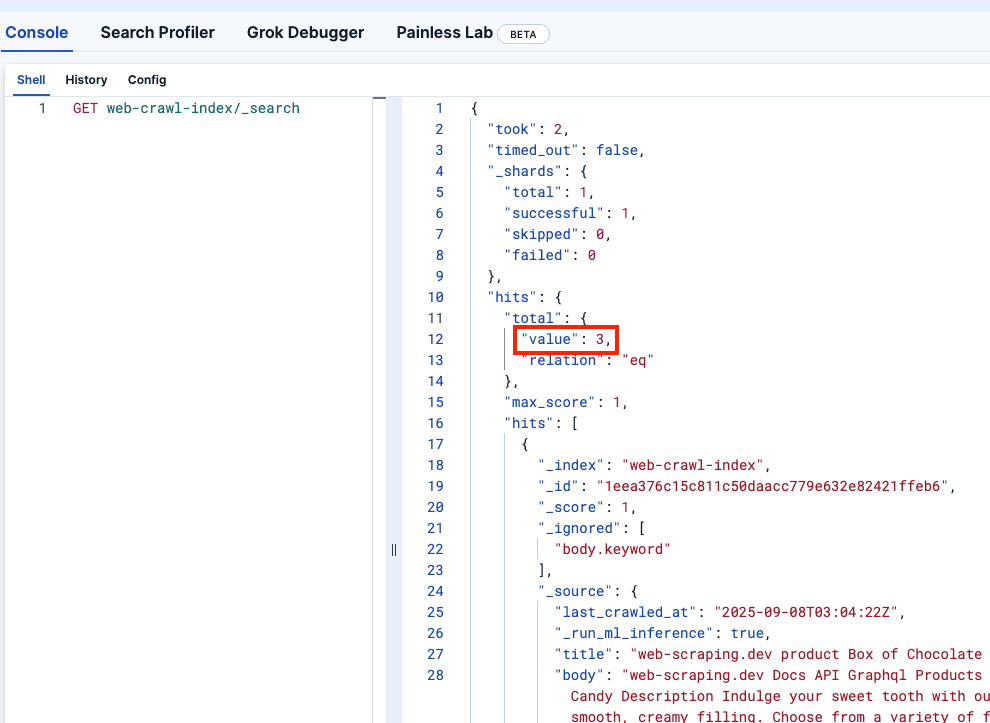
Kibana 개발자 도구를 살펴보고 web-crawler-index 이 올바르게 채워졌는지 확인해 보겠습니다:
프로덕션에 배포
이제 가상 머신에 크롤러를 배포하고 서버리스 Elasticsearch 인스턴스로 로그 전송을 시작하는 메인 브랜치로 푸시할 준비가 되었습니다.
그러면 가상 머신 내에서 배포 스크립트를 실행하고 크롤링을 시작하는 GitHub 액션이 트리거됩니다.
GitHub 리포지토리로 이동하여 "작업" 탭을 방문하면 작업이 실행되었는지 확인할 수 있습니다:

변경 및 다시 배포
눈에 띄는 점은 각 제품의 price 이 문서 본문 필드의 일부라는 점입니다. 가격을 별도의 필드에 저장하여 필터를 실행할 수 있도록 하는 것이 가장 이상적입니다.
crawler.yml 파일에 이 변경 사항을 추가하여 추출 규칙을 사용하여 product-price CSS 클래스에서 가격을 추출해 보겠습니다:
또한 가격에는 달러 기호($)가 포함되어 있으며, 범위 쿼리를 실행하려면 이 기호를 제거해야 합니다. 이를 위해 수집 파이프라인을 사용할 수 있습니다. 위의 새 크롤러 구성 파일에서 이를 참조하고 있습니다:
프로덕션 Elasticsearch 클러스터에서 해당 명령을 실행할 수 있습니다. 개발의 경우, 임시적이므로 다음 서비스를 추가하여 docker-compose.yml 파일에 파이프라인 생성 부분을 만들 수 있습니다. 또한 크롤러 서비스에 depends_on 을 추가하여 파이프라인이 성공적으로 생성된 후에 시작되도록 했습니다.
이제 `./local.sh` 을 실행하여 로컬에서 변경 사항을 확인해 보겠습니다:

훌륭합니다! 이제 변경 사항을 적용해 보겠습니다:
모든 것이 제대로 작동하는지 확인하려면 프로덕션 Kibana를 확인하면 변경 사항이 반영되어 달러 기호가 없는 새 필드로 가격이 표시되어야 합니다.
결론
Elastic Open Web Crawler를 사용하면 크롤러를 코드로 관리할 수 있으므로 개발부터 배포까지 전체 파이프라인을 자동화하고 임시 로컬 환경을 추가하고 크롤링된 데이터에 대해 프로그래밍 방식으로 테스트하는 등 몇 가지 예를 들 수 있습니다.
공식 리포지토리를 복제하고 이 워크플로우를 사용하여 자체 데이터 색인화를 시작할 수 있습니다. 이 문서에서 크롤러가 생성한 인덱스에 대해 시맨틱 검색을 실행하는 방법을 알아볼 수도 있습니다.
관련 콘텐츠

2026년 5월 18일
안전한 쿼리 실행을 위한 Elasticsearch의 결정론적 가드레일을 사용한 에이전틱 AI 검색
에이전틱 AI 검색 시스템은 LLM이 쿼리를 직접 생성할 때 실패하는 경우가 많습니다. 결정론적 가이드레일과 제어 평면 아키텍처가 어떻게 Elasticsearch를 사용해 안전하고 신뢰할 수 있는 관리형 쿼리를 실행하는 방법을 알아보세요.

2026년 5월 11일
이커머스 검색 개인화: 구매 이력 및 사용자 코호트 통합하기
거버넌스를 유지하면서 Elasticsearch에서 개인화된 이커머스 검색 경험을 구축하는 방법을 알아보세요. 본 게시물에서는 구매자가 이전에 구매했던 상품을 부스트하는 방법과 사용자 프로필을 기반으로 코호트별 맞춤 정책을 활성화하는 방법을 설명합니다.

2026년 5월 4일
전자상거래 검색 관리를 위한 Elasticsearch 퍼콜레이터: 모호한 쿼리를 통제된 검색 전략으로 변환
Elasticsearch 퍼콜레이터를 사용하여 검색 거버넌스를 구현하는 방법을 알아보세요. 이 블로그에서는 실제 운영 환경에서 거버넌스가 적용된 정책 엔진을 구축하고, 통제된 검색 전략을 만드는 데 필요한 패턴들을 설명합니다.

2026년 5월 1일
전자 상거래 검색을 관리하기 위한 제어 평면 구축
코드 변경 없이 충돌하는 검색 정책을 단일 실행 계획으로 통합하는 전자 상거래용 거버넌스 기반 제어 평면을 구축하는 방법을 알아봅니다.

2026년 4월 24일
매핑 충돌로 인한 데이터 스트림 재색인
데이터 스트림을 재색인하여 Elasticsearch 매핑 충돌을 해결하는 방법을 알아보세요. 이 블로그에서는 재색인 프로세스와 새 데이터가 올바르게 매핑되는지 확인하는 방법을 설명합니다.