Elastic認定の取得をご希望ですか?次回のElasticsearch Engineerトレーニングがいつ開催されるかご確認ください。無料のクラウドトライアルを開始するか、ローカルマシンでElasticを試すことができます。
Luceneにおける自動バイト量子化
HNSW はベクトルを保存および検索するための強力かつ柔軟な方法ですが、高速に実行するには大量のメモリが必要です。たとえば、768 次元の 1MM float32 ベクトルをクエリするには、およその RAM が必要です。大量のベクトルを検索し始めると、コストが高くなります。メモリ使用量を約削減する方法の 1 つは、バイト量子化を使用することです。Lucene と Elasticsearch は以前からベクトルのインデックス作成をサポートしてきましたが、これらのベクトルの構築はユーザーの責任でした。Lucene にスカラー量子化が導入されたため、この状況は変わりつつあります。
スカラー量子化101
すべての量子化手法は、生データの非可逆変換であると見なされます。つまり、スペースの都合上、一部の情報が失われます。スカラー量子化の詳細な説明については、 「スカラー量子化 101」を参照してください。大まかに言えば、スカラー量子化は非可逆圧縮技術です。簡単な計算により、リコールにほとんど影響を与えずに、大幅にスペースを節約できます。
建築を探る
Elasticsearch の使用に慣れている方は、これらの概念にすでに馴染みがあるかもしれませんが、ここでは検索対象ドキュメントの配布について簡単に概要を説明します。
各 Elasticsearch インデックスは複数のシャードで構成されます。各シャードは 1 つのノードにのみ割り当てることができますが、インデックスごとに複数のシャードを割り当てることで、ノード間で並列計算が可能になります。
各シャードは単一のLucene インデックスとして構成されます。Lucene インデックスは複数の読み取り専用セグメントで構成されます。インデックス作成中、ドキュメントはバッファリングされ、定期的に読み取り専用セグメントにフラッシュされます。特定の条件が満たされると、これらのセグメントをバックグラウンドでより大きなセグメントにマージできます。これらはすべて構成可能であり、独自の複雑さを伴います。ただし、セグメントとマージについて話すときは、読み取り専用の Lucene セグメントと、これらのセグメントの定期的な自動マージについて話しています。ここでは、セグメントのマージと設計上の決定について詳しく説明します。
Luceneにおけるセグメントごとの量子化
Lucene のすべてのセグメントには、個々のベクトル、HNSW グラフ インデックス、量子化されたベクトル、および計算された分位数が保存されます。簡潔にするために、Lucene が量子化されたベクトルと生のベクトルを保存する方法に焦点を当てます。すべてのセグメントについて、 ファイル内の生のベクトル、 内の量子化されたベクトルと単一の補正乗数浮動小数点数、およびファイル内の量子化に関するメタデータを追跡します。

図 1: 生のベクター保存ファイルの簡略化されたレイアウト。 値は 4 バイトなので、 dimension量子化しているため、これらは HNSW 検索中に読み込まれません。これらは、特に要求された場合にのみ使用されます(例:再スコアリングによるブルートフォースセカンダリ、またはセグメントマージ中の再量子化に使用します。

図2: の簡略化されたレイアウトファイル。のスペースを占有し、検索中にメモリにロードされます。バイトは、スコアリングを調整して精度と再現性を向上させるために使用される補正乗数浮動小数点数を表します。

図 3: メタデータ ファイルの簡略化されたレイアウト。ここで、このセグメントの計算された分位数とともに、量子化とベクトル構成を追跡します。
したがって、各セグメントについて、量子化されたベクトルだけでなく、これらの量子化されたベクトルの作成に使用された分位数と元の生のベクトルも保存します。しかし、なぜ生のベクトルを保存しておくのでしょうか?
あなたとともに成長する量子化
Lucene は定期的にセグメントを読み取り専用にフラッシュするため、各セグメントにはすべてのデータの部分的なビューのみが表示されます。つまり、計算された四分位数は、データ全体のそのサンプル セットにのみ直接適用されます。さて、サンプルがコーパス全体を適切に代表しているのであれば、これは大した問題ではありません。しかし、Lucene ではさまざまな方法でインデックスを並べ替えることができます。したがって、セグメントごとの分位数計算にバイアスを追加する方法でソートされたデータをインデックス化することができます。また、いつでも好きなときにデータをフラッシュできます。サンプル セットは、たとえ 1 つのベクトルだけでも非常に小さい可能性があります。さらにもう一つの問題は、マージがいつ発生するかを制御できることです。Elasticsearch ではデフォルトと定期的なマージが設定されていますが、 _force_merge API を介していつでもマージを要求できます。では、どうすれば、優れた再現性をもたらす適切な量子化を実現しながら、こうした柔軟性をすべて実現できるのでしょうか?
Lucene のベクトル量子化は時間の経過とともに自動的に調整されます。Lucene は読み取り専用セグメント アーキテクチャで設計されているため、各セグメントのデータが変更されていないことが保証され、コード内で更新できるタイミングが明確に区別されます。つまり、セグメントのマージ中に、必要に応じて分位数を調整し、ベクトルを再量子化できる可能性があります。
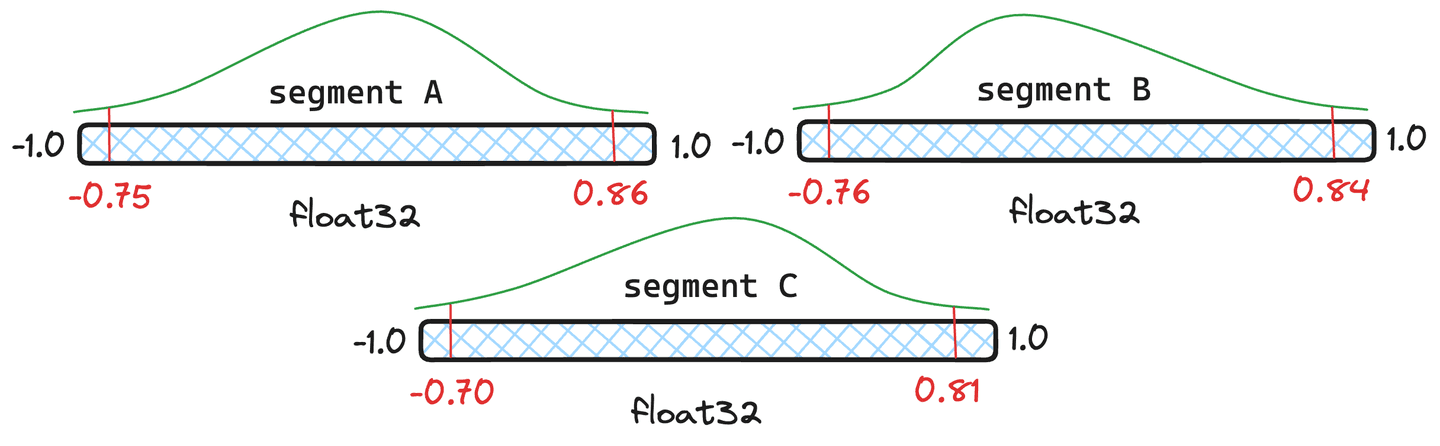
図 4: 異なる分位数を持つ 3 つのセグメントの例。
しかし、再量子化はコストがかかるのではないですか?多少のオーバーヘッドはありますが、Lucene は分位数をインテリジェントに処理し、必要な場合にのみ完全に再量子化します。図 4 のセグメントを例に挙げてみましょう。セグメントとにそれぞれドキュメントを割り当て、セグメントにはドキュメントのみを割り当てます。Lucene は、四分位数の加重平均を取得し、その結果として得られる結合された四分位数がセグメントの元の四分位数に十分近い場合、そのセグメントを再量子化する必要がなく、新しく結合された四分位数を利用します。
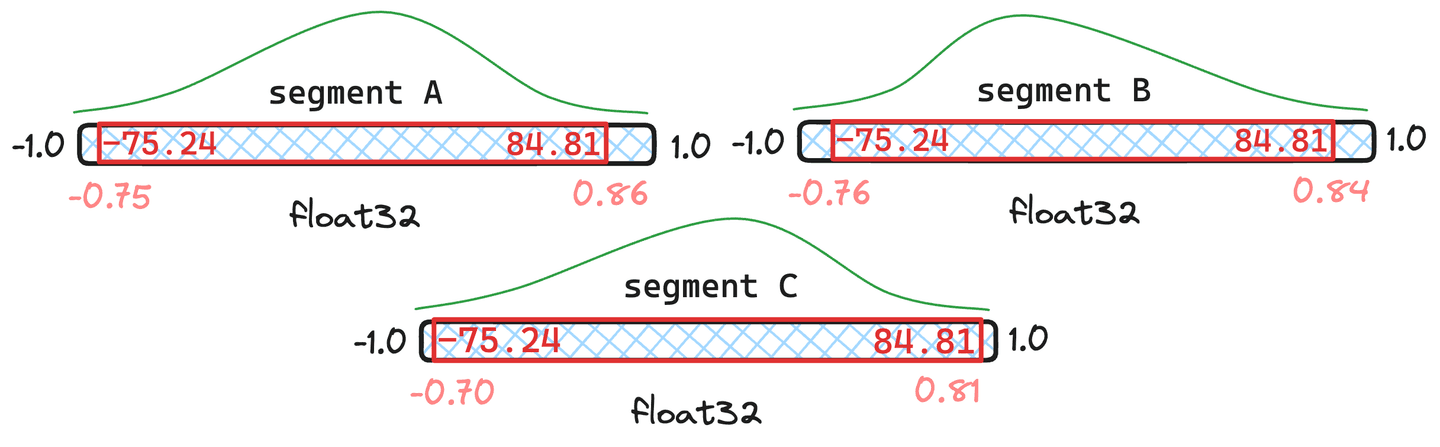
図 5: セグメントとにドキュメントがあり、セグメントにはドキュメントしかない場合の結合された分位数の例。
図5に示されている状況では、結果として得られる統合された分位数は、 との元の分位数と非常に類似していることがわかります。したがって、ベクトルを量子化する必要性は認められません。セグメントは、逸脱しすぎているようです。その結果、 のベクトルは、新しく結合された分位値で再量子化されます。
実際、結合された四分位数が元の四分位数と大幅に異なる極端なケースもあります。この場合、各セグメントからサンプルを取得し、四分位数を完全に再計算します。
量子化性能と数値
それで、それは高速であり、良好なリコールを提供し続けるのでしょうか?c3-standard-8 GCP インスタンスで実験を実行すると、次の数値が収集されました。との公平な比較を確実にするために、生のベクトルをメモリ内に保持するのに十分な大きさのインスタンスを使用しました。最大内積を使用してCohere Wikiベクトルをインデックスしました。
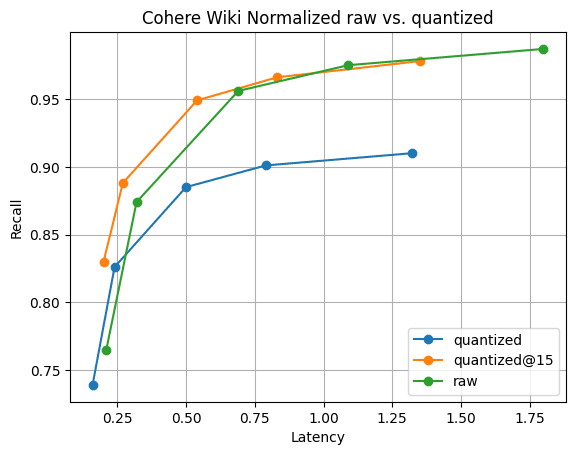
図 6: 量子化ベクトルと生のベクトルの Recall@10。量子化ベクトルの検索パフォーマンスは生のベクトルよりも大幅に高速で、さらに 5 つのベクトルを集めるだけでリコールをすぐに回復できます。これはで確認できます。
図6にそのストーリーを示します。予想通り、再現率の違いはありますが、それは大きな差ではありません。そして、さらに 5 つのベクトルを集めるだけで、再現率の差は消えます。これらすべてを、セグメントのマージが高速化し、 ベクトルの 1/4 のメモリで実現します。
まとめ
Lucene は、難しい問題に対する独自のソリューションを提供します。量子化には「トレーニング」や「最適化」のステップは必要ありません。Lucene では、問題なく動作します。データがシフトした場合にベクトル インデックスを「再トレーニング」する必要があることを心配する必要はありません。Lucene は重要な変更を検出し、データの存続期間中これを自動的に処理します。この機能が Elasticsearch に導入されるのを楽しみにしてください。
よくあるご質問
スカラー量子化とは何ですか?
スカラー量子化は非可逆圧縮技術です。簡単な計算により、リコールにほとんど影響を与えずに、大幅にスペースを節約できます。
関連記事

2026年4月10日
Elasticsearch + Jina埋め込みによる教師なし文書クラスタリング
ElasticsearchとJina埋め込みを使用した教師なし文書クラスタリングへの実用的で再現可能なアプローチ。

2025年9月3日
ベクター検索フィルタリング: 関連性を保つ
クエリに最も類似した結果を見つけるためにベクトル検索を実行するだけでは不十分です。検索結果を絞り込むには、フィルタリングが必要になることがよくあります。この記事では、Elasticsearch と Apache Lucene でのベクトル検索のフィルタリングの仕組みについて説明します。

MLを使用したフィルターとファセットの生成
ML モデルを使用した検索エクスペリエンスにおけるフィルターとファセットの作成を自動化することと、従来のハードコードされたアプローチを比較して、長所と短所を検討します。

2025年4月7日
HNSWグラフのマージを高速化する
複数の HNSW グラフを構築する際のオーバーヘッドを削減するために、特にグラフのマージにかかるコストを削減するために私たちが行ってきた作業について説明します。

2025年2月7日
Lucene の同時実行バグ: 楽観的同時実行の失敗を修正する方法
CMUのPASTAラボの決定論的並行性テストフレームワークであるFrayのおかげで、私たちはLuceneの厄介なバグを追跡し、それを潰すことができました。