Elastic認定の取得をご希望ですか?次回のElasticsearch Engineerトレーニングがいつ開催されるかご確認ください。無料のクラウドトライアルを開始するか、ローカルマシンでElasticを試すことができます。
準備しておきましょう:
このブログはいつもと違います。新しい機能の説明やチュートリアルではありません。これは、記述に 3 日かかった 1 行のコードです。Apache Lucene インデックスの潜在的な破損を修正します。皆さんが理解して頂けるよう、いくつかのポイントを挙げておきます。
- 十分な時間と適切なツールがあれば、すべての不安定なテストは再現可能である
- 堅牢なシステムには、多層的なテストが重要です。ただし、テストのレベルが上がるにつれて、デバッグと再現がますます難しくなります。
- Sleepは優れたデバッガーです
Elasticsearchのテスト方法
Elastic では、Elasticsearch コードベースに対して実行されるテストが多数あります。シンプルで集中的な機能テストもあれば、単一ノードの「ハッピーパス」統合テスト、さらには障害シナリオですべてが正しく動作することを確認するためにクラスターを破壊しようとするテストもあります。テストが継続的に失敗する場合は、エンジニアまたはツール自動化によって github の問題が作成され、特定のチームが調査できるようにフラグが付けられます。この特定のバグは、最後の種類のテストによって発見されました。これらのテストは扱いが難しいため、何度も実行しないと再現できないこともあります。
このテストは実際に何をテストしているのでしょうか?
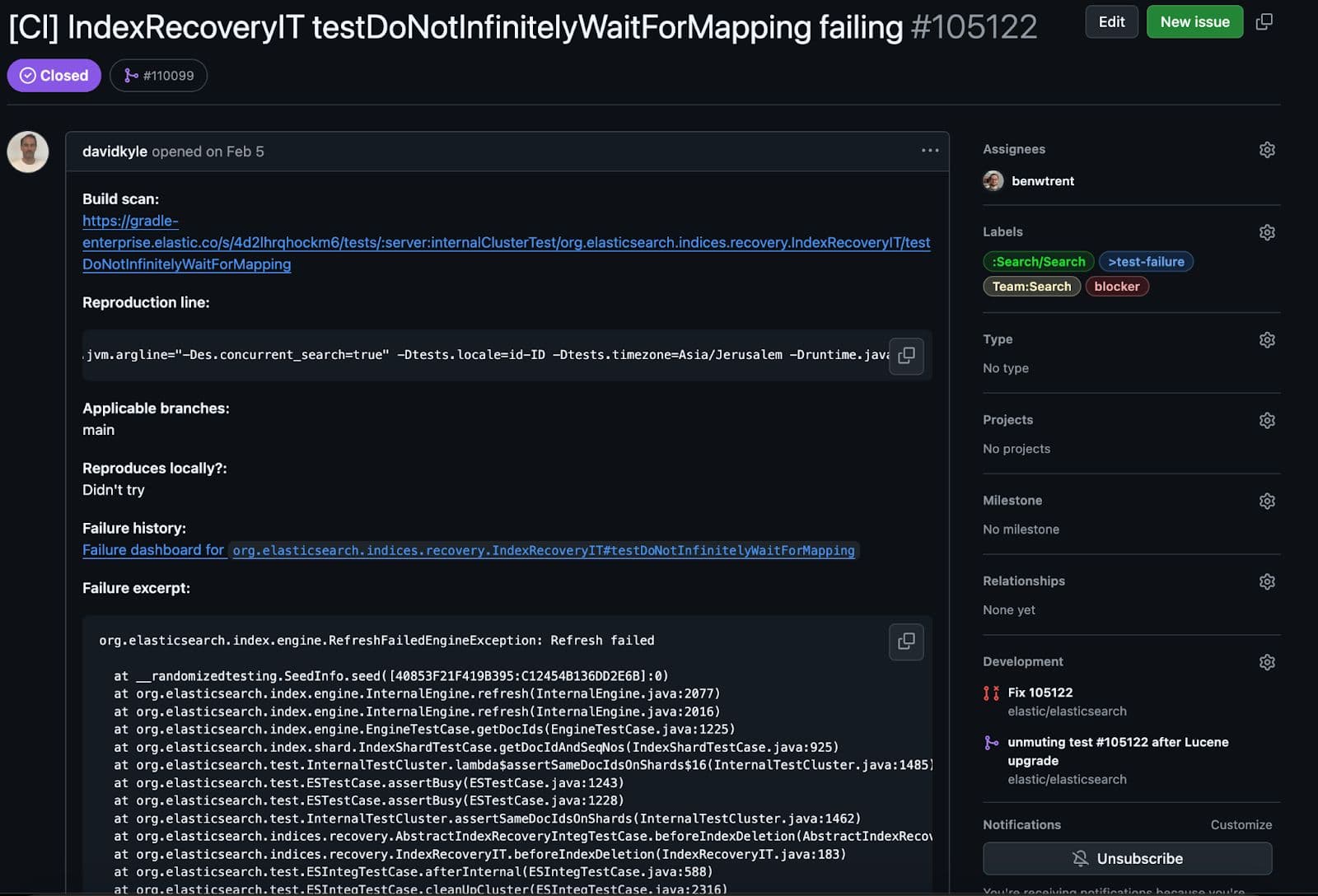
この特定のテストは興味深いものです。特定のマッピングを作成し、それをプライマリ シャードに適用します。次にレプリカを作成しようとします。主な違いは、レプリカがドキュメントを解析しようとすると、テストによって例外が挿入され、その結果、予期しない (しかし予想どおりの) 方法で回復が失敗するという点です。
すべては期待通りに機能していましたが、1つ大きな問題がありました。テストのクリーンアップ中に一貫性を検証したところ、このテストで問題が発生しました。
このテストは予想どおりに失敗しました。整合性チェック中に、複製された Lucene セグメント ファイルとプライマリ Lucene セグメント ファイルがすべて整合性があることを確認します。つまり、破損しておらず、完全に複製されています。部分的なデータや破損したデータが存在することは、何かが完全に機能しなくなるよりもはるかに悪い状況です。以下は、失敗の恐ろしい短縮版スタック トレースです。
何らかの理由で、強制レプリケーションの失敗中に、レプリケートされたシャードが破損してしまいました。エラーの重要な部分を平易な英語で説明しましょう。
Lucene はセグメント ベースのアーキテクチャです。つまり、各セグメントは独自の読み取り専用ファイルを認識して管理します。この特定のセグメントは、すべてが正常であることを確認するために、 SegmentCoreReadersを介して検証されていました。各コア リーダーには、特定のセグメントに存在するフィールド タイプとファイルを示すメタデータが保存されています。ただし、 Lucene90PointsFormatを検証するときに、特定の予期されたファイルが見つかりませんでした。セグメント_0.cfsファイルでは、 kdiと呼ばれるポイント形式ファイルが予期されていました。cfs 「複合ファイル システム」を表します。Lucene は、より効率的なレプリケーションとリソース利用のために、すべてのフィールド タイプとすべての小さなファイルを 1 つの大きなファイルに結合することがあります。実際、ポイント ファイル拡張子kdd 、 kdi 、 kdmの 3 つすべてが欠落していました。Lucene セグメントがポイント ファイルを見つけることを期待しているのに、それが見つからないという状況に陥るのはなぜでしょうか。恐ろしい破損バグのようです。
あらゆるバグ修正の最初のステップは、それを再現すること
この特定のバグの障害を再現するのは非常に困難でした。Elasticsearch のランダム値テストを活用しながら、すべての障害を調査できるように、すべての障害に (できれば) 再現可能なランダム シードを提供するようにしています。そうですね、これは競合状態によって引き起こされる障害を除くすべての障害に対してうまく機能します。
何度試しても、特定のシードはローカルで失敗を繰り返すことはありませんでした。しかし、テストを実行して、より再現性の高い失敗へと導く方法はあります。
私たちの特定のテスト スイートでは、 -Dtests.itersパラメータを使用して、同じコマンドで特定のテストを複数回実行できます。しかし、これだけでは十分ではなく、実行スレッドが切り替わっていることを確認し、競合状態が発生する可能性を高める必要がありました。システムのもう一つの問題は、テストの実行に非常に長い時間がかかり、テスト ランナーがタイムアウトになることでした。最終的に、私は次の悪夢のような bash を使用してテストを繰り返し実行しました。
ストレスが溜まります。これにより、CPU コアを大量に消費するプロセスをすばやく開始できます。失敗するテストを何度も繰り返し実行しながら、ランダムに stress-ng をスパムすることで、最終的に失敗を再現することができました。一歩近づく。システムに負荷をかけるには、別のターミナル ウィンドウを開いて次のコマンドを実行します。
バグの発見
バグを明らかにするテストの失敗がほぼ再現可能になったので、今度は原因を探してみましょう。この特定のテストが奇妙である理由は、Lucene がポイント値を期待しているにもかかわらず、テストによってポイント値が直接追加されないためにエラーがスローされる点です。テキスト値のみ。このため、楽観的同時実行制御フィールド_seq_noと_primary_termの最近の変更点を確認することを検討することにしました。これらは両方ともポイントとしてインデックス化され、すべての Elasticsearch ドキュメントに存在します。
確かにコミットによって_seq_noマッパーが変更されました。はい!原因はきっとこれだ!しかし、私の興奮は長くは続かなかった。これにより、ドキュメントにフィールドが追加される順序のみが変更されました。この変更の前は、 _seq_noフィールドがドキュメントの最後に追加されていました。その後、最初に追加されました。Lucene ドキュメントにフィールドを追加する順序がこの失敗の原因となるはずはありません...
はい、フィールドの追加順序を変更すると、エラーが発生しました。これは驚くべきことで、Lucene 自体のバグであることが判明しました。解析されるフィールドの順序を変更しても、ドキュメントの解析動作は変更されません。
Luceneのバグ
実際、Lucene のバグは次の条件に焦点を当てていました。
- ポイント値フィールドのインデックス作成(例:
_seq_no) - 分析中にテキストフィールドのインデックスを作成しようとしています
- この奇妙な状態では、テキストインデックス分析例外を経験したライターからニアリアルタイムリーダーを開きます。
しかし、どんなに方法を試しても、完全に再現することはできませんでした。Lucene コードベース全体にデバッグ用の一時停止ポイントを直接追加しました。例外パス中にランダムにリーダーを開こうとしました。この障害が発生した正確なパスを見つけようとして、何メガバイトものログを印刷することさえしました。どうしてもできなかったんです。私は一日中戦って負け続けました。
それから私は眠りました。
翌日、元のスタック トレースを再度読み直して、次の行を発見しました。
これまでの再現の試みにおいて、私は保持マージポリシーを具体的に設定したことはありません。SoftDeletesRetentionMergePolicyは Elasticsearch によって使用され、レプリカ内の削除を正確に複製し、ドキュメントが実際に削除されるタイミングをすべての同時実行制御が管理できるようにします。それ以外の場合、Lucene は完全な制御権を持ち、マージ時にそれらを削除します。
このポリシーを追加し、上記の最も基本的な手順を再現すると、障害はすぐに再現されました。
Lucene でバグを発見してこれほどうれしかったことはありません。
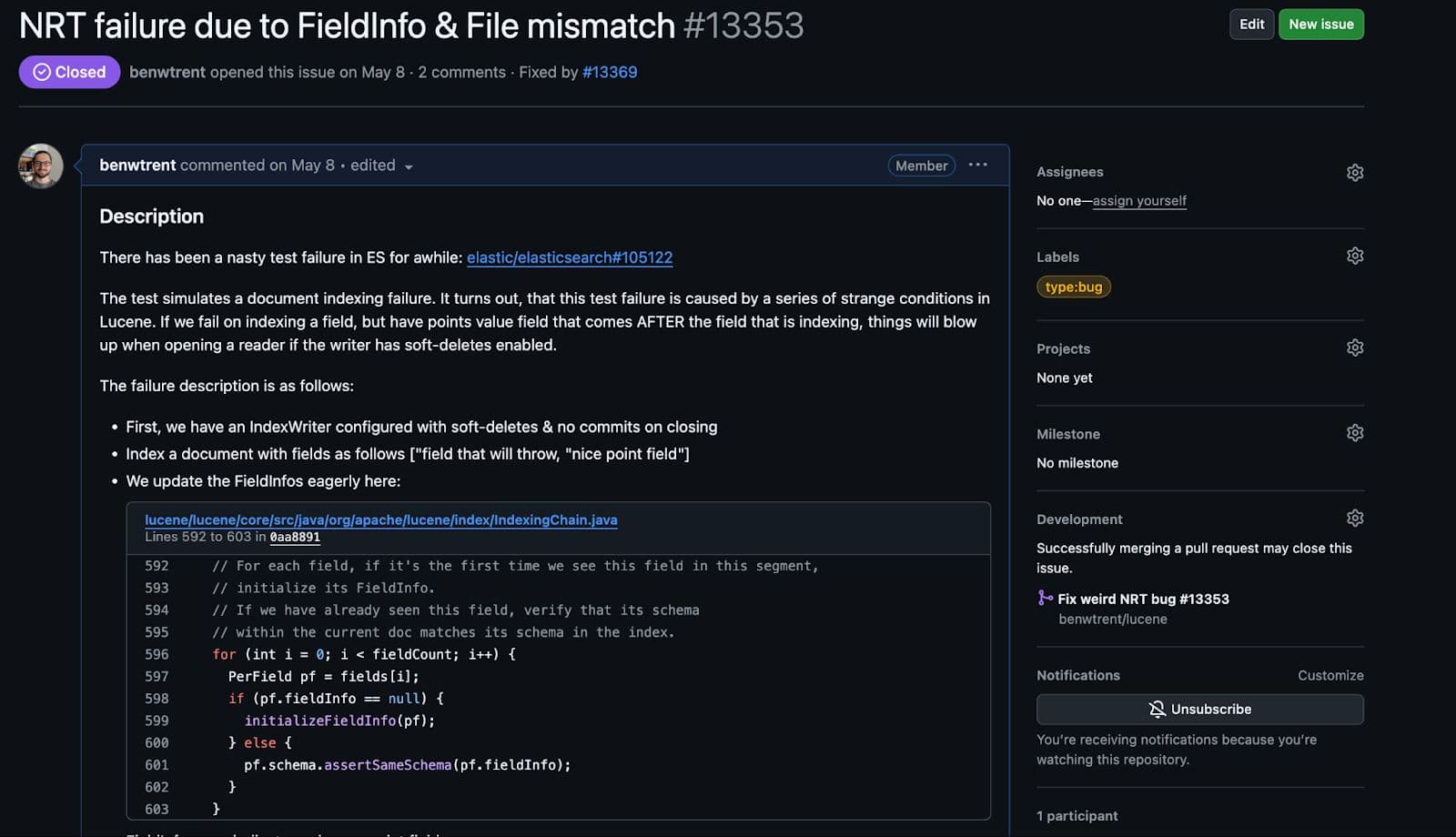
Elasticsearch では競合状態として現れましたが、すべての条件が満たされると、Lucene で繰り返し失敗するテストを書くのは簡単でした。
結局、すべてのバグと同様に、たった 1 行のコードで修正されました。たった 1 行のコードのために、数日間の作業が必要でした。
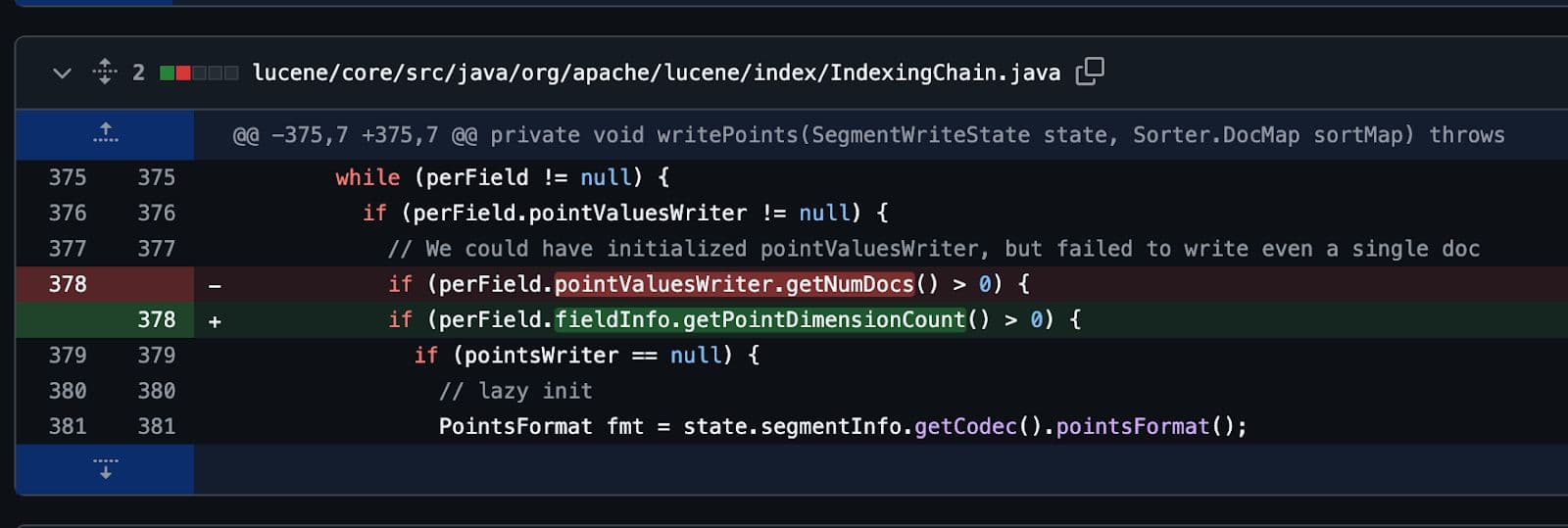
しかし、それは価値がありました。
終わりではない
私と一緒にこのワイルドな旅を楽しんでいただけたら嬉しいです!ソフトウェア、特にElasticsearchやApache Luceneのように広く使用され、複雑なソフトウェアを書くことは、やりがいのあることです。しかし、時には、非常にイライラすることもあります。私はソフトウェアが好きであると同時に嫌いでもあります。バグ修正は決して終わりません!
関連記事

2025年9月3日
ベクター検索フィルタリング: 関連性を保つ
クエリに最も類似した結果を見つけるためにベクトル検索を実行するだけでは不十分です。検索結果を絞り込むには、フィルタリングが必要になることがよくあります。この記事では、Elasticsearch と Apache Lucene でのベクトル検索のフィルタリングの仕組みについて説明します。

2025年4月7日
HNSWグラフのマージを高速化する
複数の HNSW グラフを構築する際のオーバーヘッドを削減するために、特にグラフのマージにかかるコストを削減するために私たちが行ってきた作業について説明します。

2025年2月7日
Lucene の同時実行バグ: 楽観的同時実行の失敗を修正する方法
CMUのPASTAラボの決定論的並行性テストフレームワークであるFrayのおかげで、私たちはLuceneの厄介なバグを追跡し、それを潰すことができました。


2024年6月26日
OpenSearchとElasticsearchの違い:ベクトル検索のパフォーマンス比較
Elasticsearchは、ベクトル検索においてOpenSearchよりもデフォルトのままで2倍から12倍高速です