Elasticsearchは、業界をリードする生成AIツールやプロバイダーとネイティブに統合されています。RAG応用編やElasticベクトルデータベースで本番環境対応のアプリを構築する方法についてのウェビナーをご覧ください。
ユースケースに最適な検索ソリューションを構築するには、無料のクラウドトライアルを始めるか、ローカルマシンでElasticを試してみてください。
LangGraph 検索エージェント テンプレートは、 LangGraph Studio で LangGraph を使用して検索ベースの質問応答システムの作成を容易にするために LangChain によって開発されたスターター プロジェクトです。このテンプレートは Elasticsearch とシームレスに統合するように事前構成されているため、開発者はドキュメントを効率的にインデックスして取得できるエージェントを迅速に構築できます。
このブログでは、LangGraph Studio と LangGraph CLI を使用して LangChain 検索エージェント テンプレートを実行およびカスタマイズすることに焦点を当てています。このテンプレートは、Elasticsearch などのさまざまな検索バックエンドを活用して、検索拡張生成 (RAG) アプリケーションを構築するためのフレームワークを提供します。
エージェントフローをカスタマイズしながら、Elastic を使用してテンプレートを効率的にセットアップ、環境の構成、実行する方法を説明します。
要件
続行する前に、以下がインストールされていることを確認してください。
- Elasticsearch Cloud デプロイメントまたはオンプレミス Elasticsearch デプロイメント (または Elastic Cloud で 14 日間の無料トライアルを作成) - バージョン 8.0.0 以上
- Python 3.9以上
- Cohere (このガイドで使用)、 OpenAI 、 Anthropic/ClaudeなどのLLMプロバイダーへのアクセス
LangGraphアプリの作成
1. LangGraph CLIをインストールする
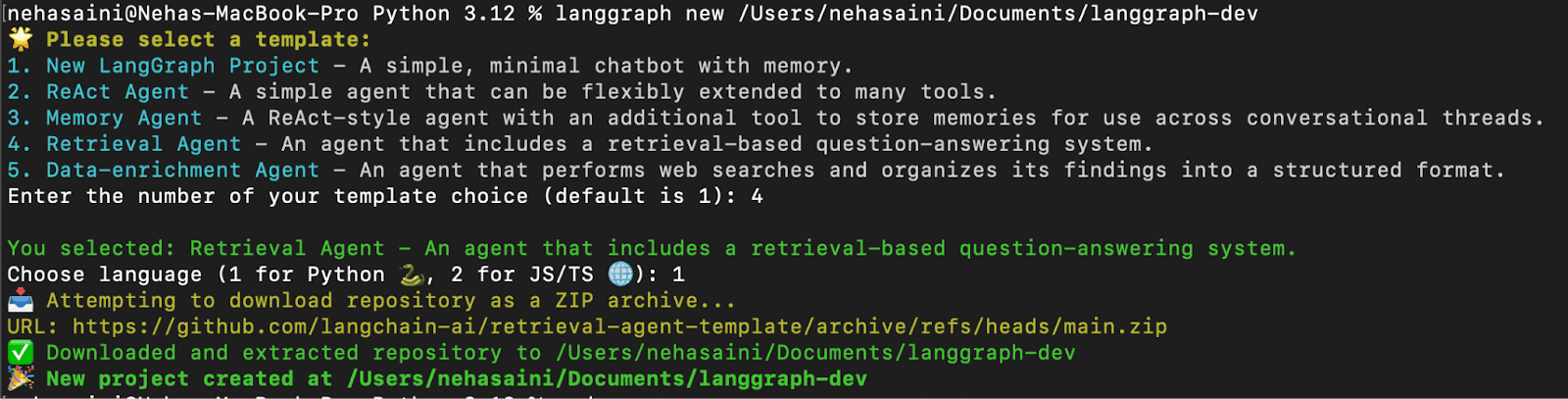
2. 検索エージェントテンプレートからLangGraphアプリを作成する
利用可能なテンプレートのリストから選択できるインタラクティブ メニューが表示されます。以下に示すように、取得エージェントの場合は 4、Python の場合は 1 を選択します。
- トラブルシューティング: 「urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: cannot get local issuer certificate (_ssl.c:1000)>」というエラーが発生した場合「
問題を解決するには、以下に示すように、Python の証明書インストール コマンドを実行してください。

3. 依存関係をインストールする
新しい LangGraph アプリのルートで仮想環境を作成し、依存関係をeditモードでインストールして、ローカルの変更がサーバーで使用されるようにします。
環境の設定
1. .environmentを作成するファイル
.envファイルには、アプリが選択した LLM および取得プロバイダーに接続できるようにするための API キーと構成が保持されます。サンプル設定を複製して新しい.envファイルを生成します。
2. .envを設定するファイル
.envファイルには、デフォルトの構成のセットが付属しています。設定に応じて必要な API キーと値を追加することで更新できます。ユースケースに関係のないキーは、変更せずにそのままにしておくことも、削除することもできます。
- サンプル
.envファイル (Elastic Cloud と Cohere を使用)
以下は、このブログで説明されているように、 Elastic Cloud を取得プロバイダーとして使用し、 Cohere をLLM として使用するためのサンプルの.env構成です。
注: このガイドでは、レスポンス生成と埋め込みの両方にCohereを使用していますが、ユースケースに応じて、 OpenAI 、 Claude 、あるいはローカルLLMモデル などの他のLLMプロバイダーも自由に使用できます 。使用する予定の各キーが.env ファイル に存在し、正しく設定されていることを確認してください。
3. 設定ファイル -configuration.py を更新する
適切な API キーを使用して.envファイルを設定したら、次の手順ではアプリケーションのデフォルトのモデル構成を更新します。構成を更新すると、システムは.envファイルで指定したサービスとモデルを使用するようになります。
構成ファイルに移動します。
configuration.pyファイルには、検索エージェントが 3 つの主なタスクに使用するデフォルトのモデル設定が含まれています。
- 埋め込みモデル– ドキュメントをベクトル表現に変換する
- クエリモデル– ユーザーのクエリをベクトルに変換する
- レスポンスモデル– 最終的なレスポンスを生成する
デフォルトでは、コードはOpenAI (例: openai/text-embedding-3-small ) とAnthropic (例: anthropic/claude-3-5-sonnet-20240620 and anthropic/claude-3-haiku-20240307 ) のモデルを使用します。このブログでは、Cohere モデルの使用に切り替えます。すでに OpenAI または Anthropic を使用している場合は、変更は必要ありません。
変更例(Cohere を使用):
configuration.pyを開き、以下のようにモデルのデフォルトを変更します。
LangGraph CLI で取得エージェントを実行する
1. LangGraphサーバーを起動する
これにより、LangGraph API サーバーがローカルで起動します。これが正常に実行されると、次のような画面が表示されます。
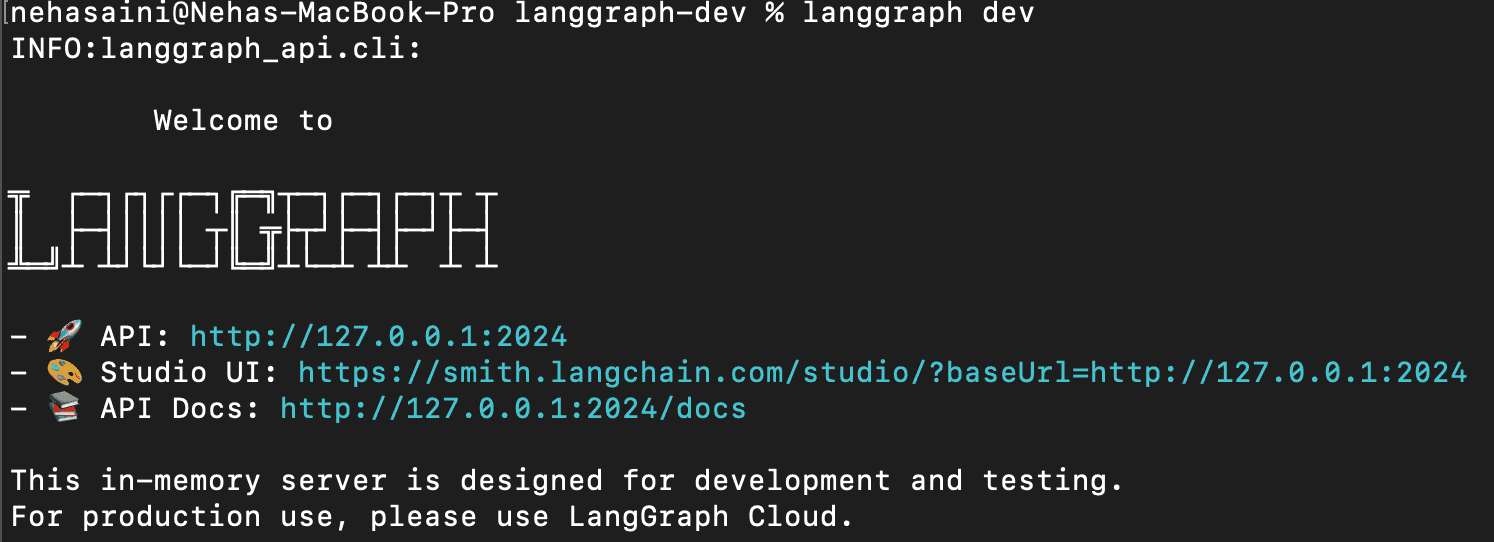
Studio UI URL を開きます。
利用可能なグラフは 2 つあります。
- 取得グラフ: Elasticsearch からデータを取得し、LLM を使用してクエリに応答します。
- インデクサー グラフ: ドキュメントを Elasticsearch にインデックスし、LLM を使用して埋め込みを生成します。

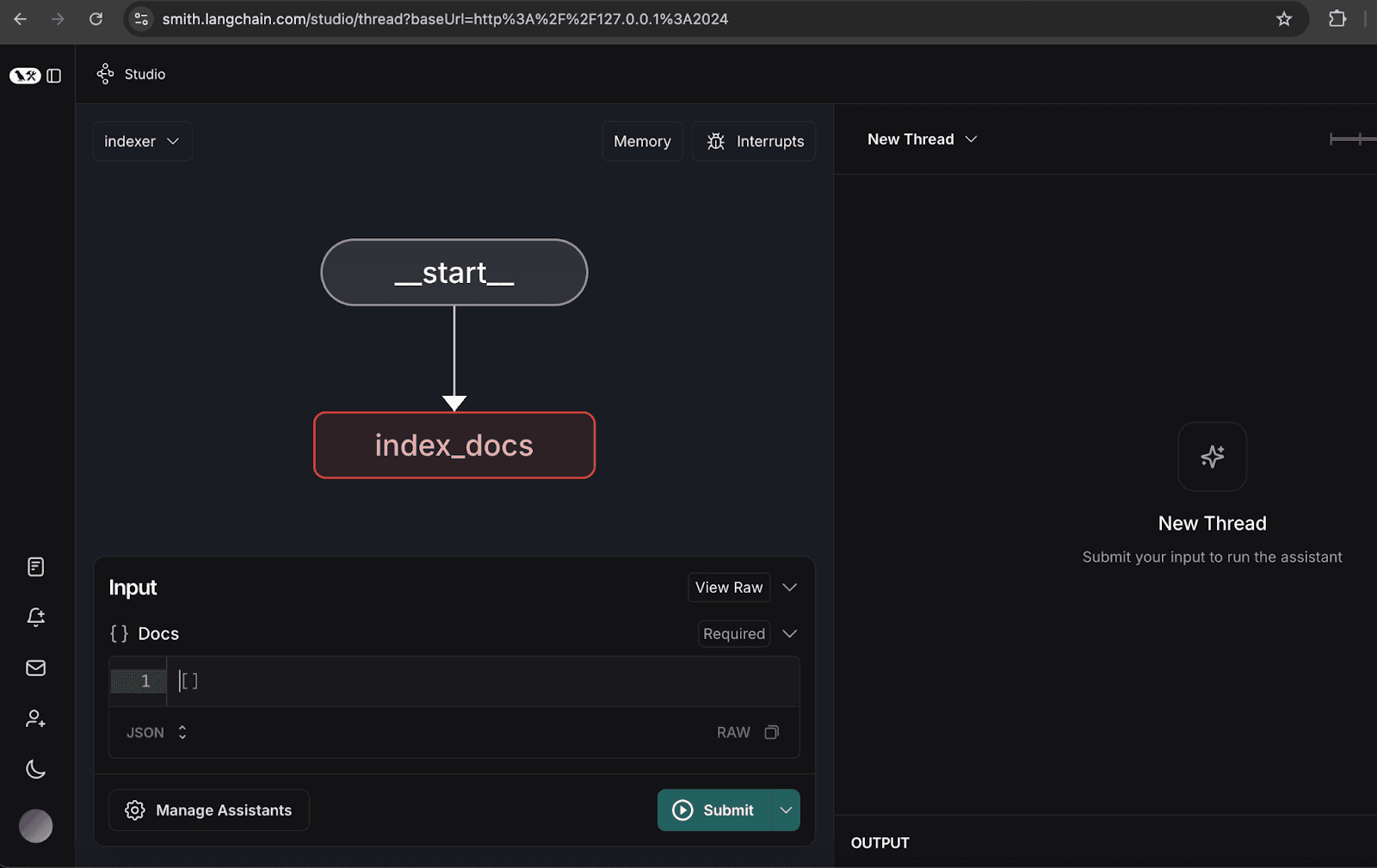
2. インデクサーグラフの設定
- インデクサー グラフを開きます。
- アシスタントの管理をクリックします。
- 「新しいアシスタントを追加」をクリックし、指定どおりにユーザーの詳細を入力して、ウィンドウを閉じます。


3. サンプル文書のインデックス作成
- NoveTech という組織の仮想的な四半期レポートを表す次のサンプル ドキュメントにインデックスを付けます。
ドキュメントがインデックスされると、以下に示すように、スレッドに削除メッセージが表示されます。

4. 検索グラフの実行
- 検索グラフに切り替えます。
- 次の検索クエリを入力してください。

システムは関連するドキュメントを返し、インデックスされたデータに基づいて正確な回答を提供します。
検索エージェントをカスタマイズする
ユーザー エクスペリエンスを向上させるために、検索グラフにカスタマイズ ステップを導入し、ユーザーが次に尋ねる可能性のある 3 つの質問を予測します。この予測は以下に基づいています:
- 取得した文書のコンテキスト
- 以前のユーザーインタラクション
- 最後のユーザークエリ
クエリ予測機能を実装するには、次のコード変更が必要です。
1. graph.pyを更新する
predict_query関数を追加します:
respond関数を変更して、メッセージの代わりにresponseオブジェクトを返します。
- グラフ構造を更新して、predict_query に新しいノードとエッジを追加します。
2. prompts.pyを更新する
prompts.pyでのクエリ予測のプロンプトを作成します:
3. configuration.pyを更新する
predict_next_question_prompt追加:
4. state.pyを更新する
- 次の属性を追加します。
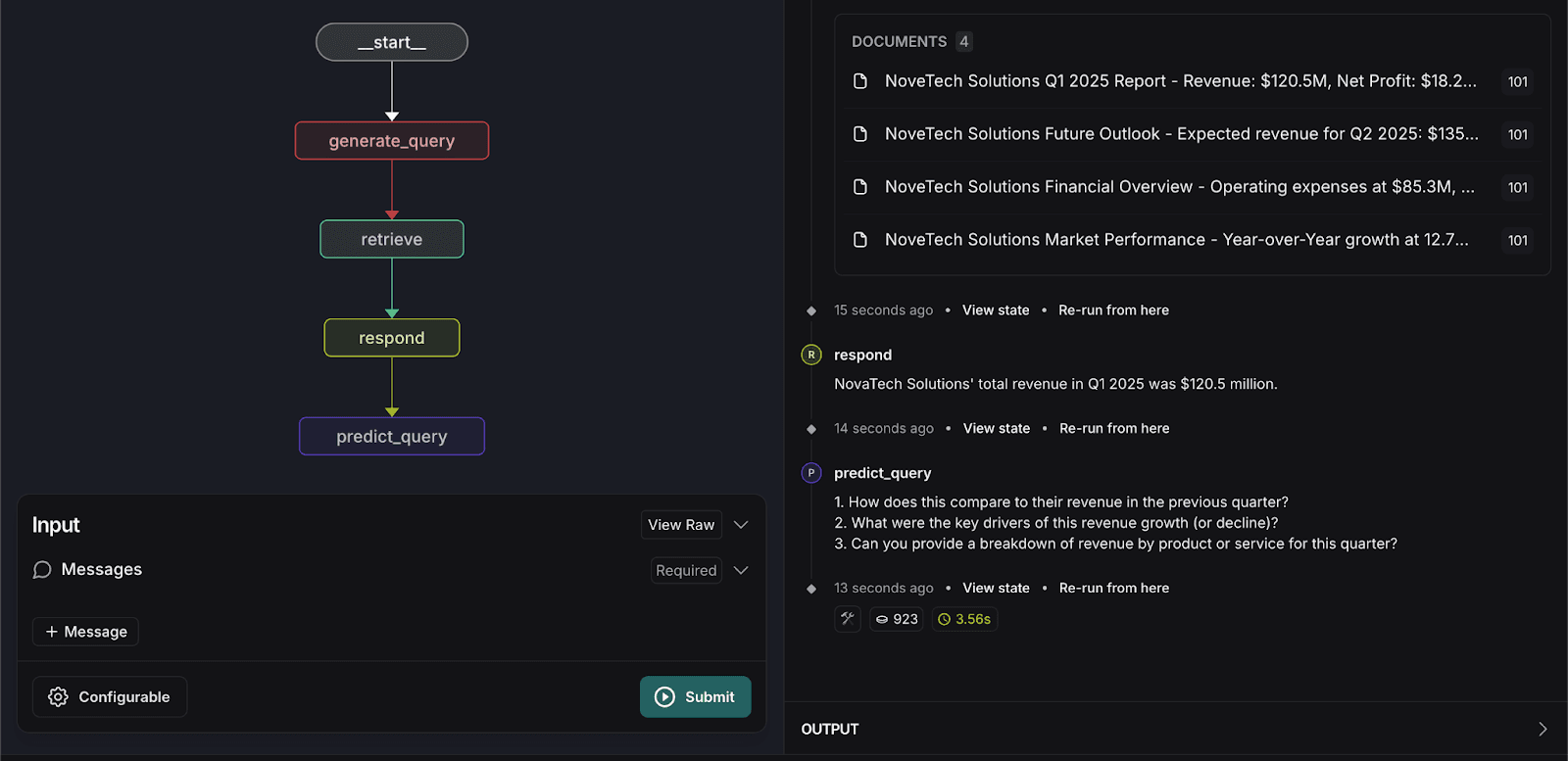
5. 検索グラフを再実行する
- 次の検索クエリをもう一度入力してください。
システムは入力を処理し、以下に示すように、ユーザーが尋ねる可能性のある 3 つの関連する質問を予測します。
まとめ
LangGraph Studio と CLI 内に取得エージェント テンプレートを統合すると、いくつかの重要な利点が得られます。
- 開発の加速: テンプレートと視覚化ツールにより、検索ワークフローの作成とデバッグが効率化され、開発時間が短縮されます。
- シームレスな展開: API と自動スケーリングの組み込みサポートにより、環境間でのスムーズな展開が保証されます。
- 簡単な更新:ワークフローの変更、新しい機能の追加、追加のノードの統合が簡単なので、検索プロセスの拡張と強化が容易になります。
- 永続メモリ: システムはエージェントの状態と知識を保持し、一貫性と信頼性を向上させます。
- 柔軟なワークフロー モデリング: 開発者は、特定のユース ケースに合わせて検索ロジックと通信ルールをカスタマイズできます。
- リアルタイムの対話とデバッグ: 実行中のエージェントと対話できるため、効率的なテストと問題解決が可能になります。
これらの機能を活用することで、組織はデータのアクセシビリティとユーザー エクスペリエンスを向上させる強力で効率的かつスケーラブルな検索システムを構築できます。
このプロジェクトの完全なソースコードはGitHubで入手できます。
よくあるご質問
RAG ワークフローとは何ですか?
RAG (Retrieval-Augmented Generation) ワークフローは、AI モデルにプライベート データへのアクセスを許可し、「幻覚」ではなく、正確で事実に基づいた回答を提供できるようにする方法です。
LangGraph エージェントのデータベースとして Elasticsearch を使用する理由は何ですか?
Elasticsearch はエージェントの「長期メモリ」として機能します。標準のデータベースとは異なり、ベクター検索 (意味の理解) とキーワード検索 (正確な用語の検索) を組み合わせたハイブリッド検索用に構築されています。これにより、「第 1 四半期の収益」を要求した場合でも、「財務成長」を要求した場合でも、Elasticsearch は LangGraph が処理するのに最も関連性の高いドキュメントを提供します。
LangGraph 検索エージェント テンプレートを使用してマルチユーザー システムを構築できますか?
はい。この記事では、user_id (「101」など) を使用したインデクサー グラフ構成を通じてこれを説明します。これにより、ドキュメントに特定の所有者のタグを付けることができるため、検索エージェントは特定のユーザーが表示を許可されている情報のみを検索できるようになります。
関連記事

描くのではなく、説明する:MCPとES|QLによるAIネイティブのKibanaダッシュボード
プロンプトからダッシュボードへ。example-mcp-dashbuilderを使って、自然言語でKibanaダッシュボードを構築する方法を学びましょう。ES|QLクエリを書き、インタラクティブなグラフを作成し、全面的に機能するダッシュボードをKibanaに直接エクスポートするオープンソースのMCPアプリケーションです。

Elasticsearchによるエンティティ解決、パート4:究極のチャレンジ
ショートカットを防ぐために設計された、非常に多様な「究極のチャレンジ」データセットにおけるエンティティ解決の課題の解決と評価。

ElasticsearchとLLMによるエンティティ解決(第2部):LLM判定とセマンティック検索によるエンティティのマッチング
Elasticsearch でのエンティティ解決にセマンティック検索と透過的なLLM判断を使用します。

Elastic Agent BuilderとStrands Agents SDKの使用を開始
Elastic Agent Builderでエージェントを作成する方法を学び、次にStrands Agents SDKで管理されたA2Aプロトコルを介してエージェントを使用する方法を学びましょう。

Cal Hacks 12.0 で取り上げた Elastic Agent Builder のトッププロジェクトと学習内容
Cal Hacks 12.0 のトップ Elastic Agent Builder プロジェクトを探索し、サーバーレス、ES|QL、エージェント アーキテクチャに関する技術的なポイントを詳しく調べます。