Souhaitez-vous recevoir une certification Elastic ? Découvrez quand se déroulera la prochaine formation Elasticsearch Engineer ! Vous pouvez lancer un essai gratuit sur le cloud ou essayer Elastic sur votre machine locale dès maintenant.
Quantification automatique des octets dans Lucene
Bien que HNSW soit un moyen puissant et flexible de stocker et de rechercher des vecteurs, il nécessite une quantité importante de mémoire pour fonctionner rapidement. Par exemple, l'interrogation de 1MM float32 vectors de 768 dimensions nécessite environ de ram. Dès que vous commencez à rechercher un nombre important de vecteurs, cela devient coûteux. La quantification des octets est un moyen d'utiliser environ moins de mémoire. Lucene et, par conséquent, Elasticsearch prennent en charge l'indexation des vecteurs d' depuis un certain temps, mais la construction de ces vecteurs relève de la responsabilité de l'utilisateur. Cela est sur le point de changer, car nous avons introduit la quantification scalaire dans Lucene.
Quantification scalaire 101
Toutes les techniques de quantification sont considérées comme des transformations avec perte des données brutes. Cela signifie que certaines informations sont perdues pour des raisons d'espace. Pour une explication approfondie de la quantification scalaire, voir : Quantification scalaire 101. À un niveau élevé, la quantification scalaire est une technique de compression avec perte. Un simple calcul permet de réaliser des économies d'espace significatives avec très peu d'impact sur le rappel.
Explorer l'architecture
Les personnes habituées à travailler avec Elasticsearch sont peut-être déjà familiarisées avec ces concepts, mais voici un aperçu rapide de la distribution des documents pour la recherche.
Chaque index Elasticsearch est composé de plusieurs tiroirs (shards). Bien que chaque nuage ne puisse être affecté qu'à un seul nœud, plusieurs nuages par index permettent un parallélisme de calcul entre les nœuds.
Chaque tesson est composé d'un seul index Lucene. Un index Lucene se compose de plusieurs segments en lecture seule. Pendant l'indexation, les documents sont mis en mémoire tampon et périodiquement vidés dans un segment en lecture seule. Lorsque certaines conditions sont remplies, ces segments peuvent être fusionnés en arrière-plan en un segment plus large. Tout cela est configurable et comporte son lot de complexités. Mais lorsque nous parlons de segments et de fusion, nous parlons de segments Lucene en lecture seule et de la fusion périodique automatique de ces segments. Voici une analyse plus approfondie de la fusion des segments et des décisions en matière de conception.
Quantification par segment dans Lucene
Chaque segment dans Lucene stocke les éléments suivants : les vecteurs individuels, les indices du graphe HNSW, les vecteurs quantifiés et les quantiles calculés. Par souci de concision, nous nous concentrerons sur la manière dont Lucene stocke les vecteurs quantifiés et bruts. Pour chaque segment, nous conservons la trace des bruts dans le fichier vec, des vecteurs quantifiés et d'un seul multiplicateur correctif dans le ainsi que les métadonnées relatives à la quantification fichier vemq.

Figure 1 : Présentation simplifiée d'un fichier de stockage de vecteurs bruts. Occupe la de l'espace disque puisque les valeurs sont de 4 octets. Étant donné que nous quantifions, ces données ne seront pas chargées lors de la recherche HNSW. Ils ne sont utilisés que sur demande expresse (par ex. secondaire par force brute via le rescore), ou pour la re-quantification lors de la fusion de segments.

Figure 2 : Présentation simplifiée du fichier fichier. Occupe un espace de et sera chargé en mémoire lors de la recherche. Les octets sont destinés à prendre en compte le multiplicateur de correction, utilisé pour ajuster la notation afin d'améliorer la précision et la mémorisation.

Figure 3 : Présentation simplifiée du fichier de métadonnées. C'est ici que nous gardons trace de la quantification et de la configuration du vecteur, ainsi que des quantiles calculés pour ce segment.
Ainsi, pour chaque segment, nous stockons non seulement les vecteurs quantifiés, mais aussi les quantiles utilisés pour créer ces vecteurs quantifiés et les vecteurs bruts originaux. Mais pourquoi conserver les vecteurs bruts ?
Une quantification qui évolue avec vous
Étant donné que Lucene se concentre périodiquement sur les segments en lecture seule, chaque segment n'a qu'une vue partielle de l'ensemble des données. Cela signifie que les quantiles calculés ne s'appliquent directement qu'à cet échantillon de l'ensemble de vos données. Ce n'est pas très grave si votre échantillon représente correctement l'ensemble de votre corpus. Mais Lucene vous permet de trier votre index de différentes manières. Ainsi, vous pourriez indexer des données triées d'une manière qui ajoute un biais pour les calculs de quantile par segment. De plus, vous pouvez effacer les données quand vous le souhaitez ! Votre échantillon peut être minuscule, ne serait-ce qu'un seul vecteur. Un autre avantage est que vous avez le contrôle sur le moment où les fusions ont lieu. Bien qu'Elasticsearch ait configuré des valeurs par défaut et une fusion périodique, vous pouvez demander une fusion quand vous le souhaitez via l'API _force_merge. Alors, comment permettre cette flexibilité tout en assurant une bonne quantification et un bon rappel ?
La quantification vectorielle de Lucene s'adaptera automatiquement au fil du temps. Lucene étant conçu avec une architecture de segments en lecture seule, nous avons la garantie que les données de chaque segment n'ont pas changé et des démarcations claires dans le code pour savoir quand les choses peuvent être mises à jour. Cela signifie que lors de la fusion des segments, nous pouvons ajuster les quantiles si nécessaire et éventuellement ré-équantifier les vecteurs.
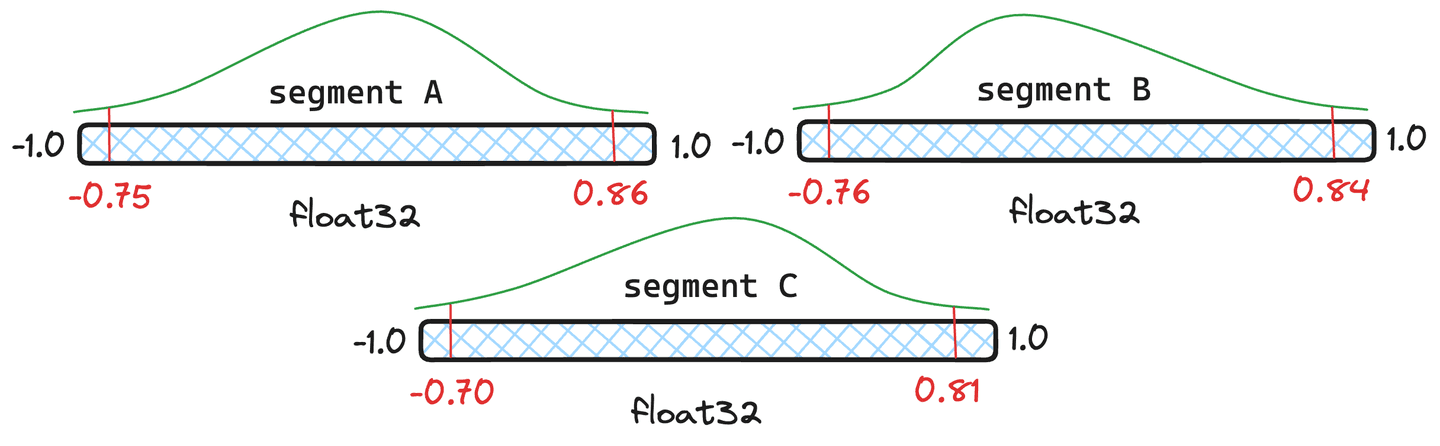
Figure 4 : Trois exemples de segments avec différents quantiles.
Mais la requantification n'est-elle pas coûteuse ? Il y a un certain surcoût, mais Lucene gère les quantiles intelligemment et ne les quantifie complètement que lorsque c'est nécessaire. Prenons l'exemple des segments de la figure 4. Donnons aux segments et documents chacun et au segment seulement documents. Lucene prend une moyenne pondérée des quantiles et si le quantile fusionné qui en résulte est suffisamment proche des quantiles originaux du segment, nous n'avons pas besoin de quantifier à nouveau ce segment et nous utiliserons les quantiles nouvellement fusionnés.
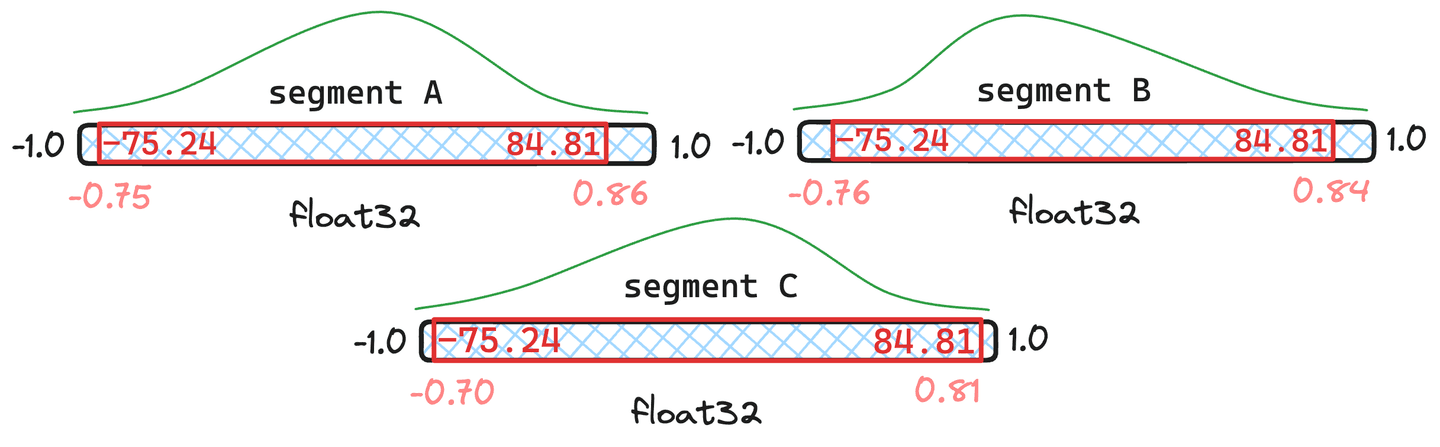
Figure 5 : Exemple de quantiles fusionnés lorsque les segments et ont documents et que le segment n'en a que .
Dans la situation représentée à la figure 5, nous pouvons voir que les quantiles fusionnés qui en résultent sont très similaires aux quantiles originaux en et Ils ne justifient donc pas la quantification des vecteurs. Le segment semble s'écarter trop de la réalité. Par conséquent, les vecteurs de seront quantifiés à nouveau avec les valeurs de quantile nouvellement fusionnées.
Il existe en effet des cas extrêmes où les quantiles fusionnés diffèrent considérablement des quantiles initiaux. Dans ce cas, nous prendrons un échantillon de chaque segment et recalculerons entièrement les quantiles.
Performance de quantification & numbers
Est-il rapide et offre-t-il toujours un bon rappel ? Les chiffres suivants ont été recueillis lors de l'exécution de l'expérience sur une instance GCP c3-standard-8. Pour garantir une comparaison équitable avec , nous avons utilisé une instance suffisamment grande pour contenir des vecteurs bruts en mémoire. Nous avons indexé vecteurs Cohere Wiki en utilisant le produit intérieur maximal.
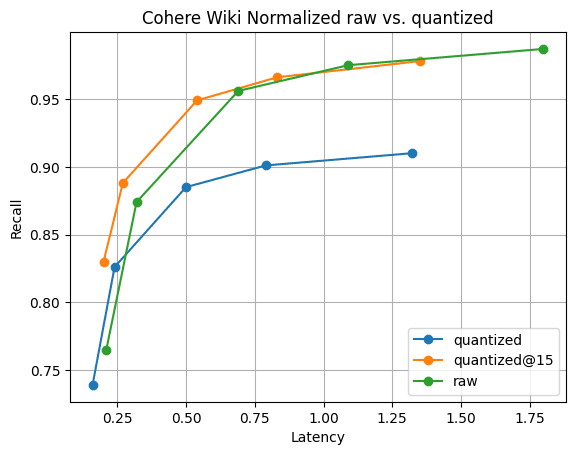
Figure 6 : Rappel@10 pour les vecteurs quantifiés par rapport aux vecteurs bruts. La performance de recherche des vecteurs quantifiés est nettement plus rapide que celle des vecteurs bruts, et le rappel est rapidement récupérable en rassemblant seulement 5 vecteurs supplémentaires ; visible par .
La figure 6 illustre l'histoire. Bien qu'il y ait une différence de rappel, comme on peut s'y attendre, elle n'est pas significative. Et la différence de rappel disparaît en rassemblant seulement 5 vecteurs supplémentaires. Tout cela avec des fusions de segments rapides et 1/4 de la mémoire des vecteurs .
Conclusion
Lucene apporte une solution unique à un problème difficile. La quantification ne nécessite aucune étape de "formation" ou d'"optimisation". Dans Lucene, cela fonctionnera simplement. Il n'y a pas d'inquiétude à avoir quant à la nécessité de "ré-entraîner" votre index vectoriel si vos données changent. Lucene détectera les changements significatifs et s'en chargera automatiquement pendant toute la durée de vie de vos données. Nous attendons avec impatience le moment où nous intégrerons cette fonctionnalité dans Elasticsearch !
Questions fréquentes
Qu'est-ce que la quantification scalaire ?
La quantification scalaire est une technique de compression avec perte. Un simple calcul permet de réaliser des économies d'espace significatives avec un faible impact sur le rappel.
Pour aller plus loin

10 avril 2026
Clustering de documents non supervisé avec Elasticsearch + Jina embeddings
Une approche pratique et reproductible pour le clustering non supervisé de documents avec Elasticsearch et les embeddings Jina.

2 janvier 2026
Automatisation de l'analyse des logs dans Streams avec le ML
Découvrez comment une approche hybride de ML a atteint une précision de 94 % pour l'analyse syntaxique des logs et 91 % pour le partitionnement des logs grâce à des expériences d’automatisation avec l’empreinte des formats de log dans Streams.

3 septembre 2025
Filtrage de la recherche vectorielle : Garder la pertinence
Il ne suffit pas d'effectuer une recherche vectorielle pour trouver les résultats les plus similaires à une requête. Le filtrage est souvent nécessaire pour réduire les résultats de la recherche. Cet article explique comment fonctionne le filtrage pour la recherche vectorielle dans Elasticsearch et Apache Lucene.

3 avril 2025
Générer des filtres et des facettes à l'aide de la ML
Exploration des avantages et des inconvénients de l'automatisation de la création de filtres et de facettes dans une expérience de recherche à l'aide de modèles ML par rapport à l'approche classique codée en dur.

7 avril 2025
Accélérer la fusion des graphiques de HNSW
Explorez le travail que nous avons effectué pour réduire la charge de travail liée à la construction de plusieurs graphes HNSW, en particulier en réduisant le coût de la fusion des graphes.