Elasticsearch dispose d'intégrations natives avec les outils et fournisseurs d'IA générative leaders du secteur. Consultez nos webinars sur le dépassement des bases de RAG ou sur la création d'applications prêtes à l'emploi avec la Base vectorielle Elastic.
Pour élaborer les meilleures solutions de recherche pour votre cas d'utilisation, commencez un essai gratuit d'Elastic Cloud ou essayez Elastic sur votre machine locale dès maintenant.
Le modèle d'agent de recherche LangGraph est un projet de démarrage développé par LangChain pour faciliter la création de systèmes de réponse aux questions basés sur la recherche en utilisant LangGraph dans LangGraph Studio. Ce modèle est préconfiguré pour s'intégrer de manière transparente à Elasticsearch, ce qui permet aux développeurs de créer rapidement des agents capables d'indexer et d'extraire des documents de manière efficace.
Ce blog se concentre sur l'exécution et la personnalisation du modèle d'agent de récupération LangChain en utilisant LangGraph Studio et LangGraph CLI. Le modèle fournit un cadre pour la construction d'applications de génération augmentée de recherche (RAG), en tirant parti de divers backends de recherche tels qu'Elasticsearch.
Nous vous guiderons dans la mise en place, la configuration de l'environnement et l'exécution efficace du modèle avec Elastic tout en personnalisant le flux de l'agent.
Produits requis
Avant de poursuivre, assurez-vous que les éléments suivants sont installés :
- Déploiement d'Elasticsearch Cloud ou déploiement d'Elasticsearch sur site (ou créer un essai gratuit de 14 jours sur Elastic Cloud) - Version 8.0.0 ou supérieure
- Python 3.9+
- Accès à un fournisseur de LLM tel que Cohere (utilisé dans ce guide), OpenAI, ou Anthropic/Claude
Création de l'application LangGraph
1. Installer l'interface de programmation LangGraph
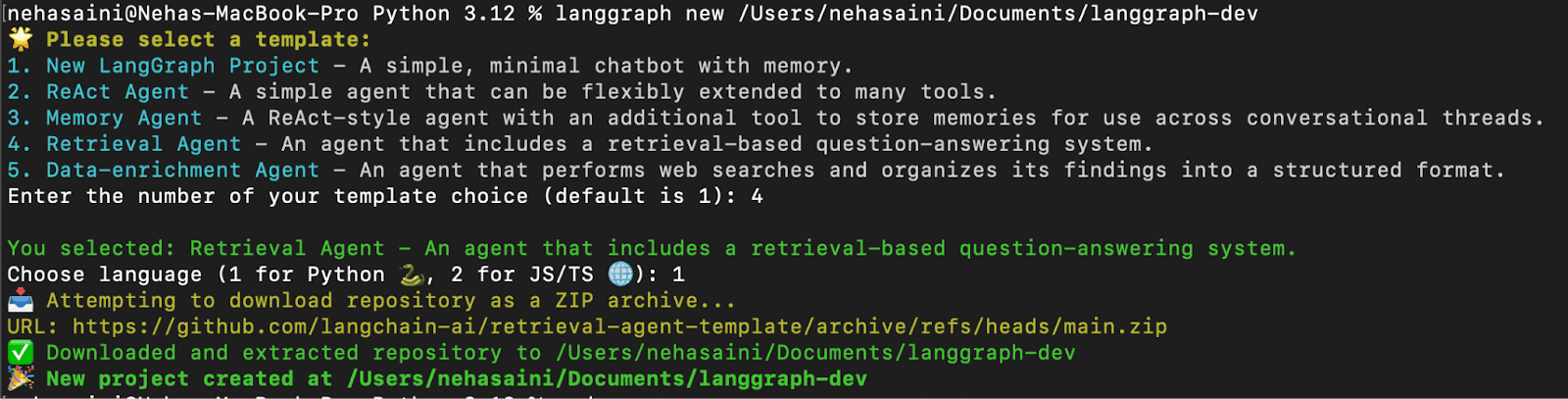
2. Créer une application LangGraph à partir de retrieval-agent-template
Un menu interactif vous permettra de choisir parmi une liste de modèles disponibles. Sélectionnez 4 pour Retrieval Agent et 1 pour Python, comme indiqué ci-dessous :
- Dépannage: Si vous rencontrez l'erreur "urllib.error.URLError : <urlopen error [SSL : CERTIFICATE_VERIFY_FAILED] certificate verify failed : unable to get local issuer certificate (_ssl.c:1000)> "
Veuillez exécuter la commande Install Certificate de Python pour résoudre le problème, comme indiqué ci-dessous.

3. Installer les dépendances
À la racine de votre nouvelle application LangGraph, créez un environnement virtuel et installez les dépendances en mode edit afin que vos modifications locales soient utilisées par le serveur :
Mise en place de l'environnement
1. Créez un environnement . fichier
Le fichier .env contient les clés API et les configurations permettant à l'application de se connecter au fournisseur de LLM et de récupération que vous avez choisi. Générer un nouveau fichier .env en dupliquant l'exemple de configuration :
2. Configurez le fichier .env fichier
Le fichier .env est livré avec un ensemble de configurations par défaut. Vous pouvez le mettre à jour en ajoutant les clés et valeurs API nécessaires en fonction de votre configuration. Les clés qui ne sont pas pertinentes pour votre cas d'utilisation peuvent être laissées inchangées ou supprimées.
- Exemple de fichier
.env(avec Elastic Cloud et Cohere)
Vous trouverez ci-dessous un exemple de configuration .env pour l'utilisation d'Elastic Cloud en tant que fournisseur d'extraction et de Cohere en tant que LLM, comme démontré dans ce blog :
Note : Bien que ce guide utilise Cohere pour la génération de réponses et l'intégration, vous êtes libre d'utiliser d'autres fournisseurs LLM tels que OpenAI, Claude, ou même un modèle LLM local en fonction de votre cas d'utilisation. Assurez-vous que chaque clé que vous avez l'intention d'utiliser est présente et correctement définie dans le fichier.env.
3. Mise à jour du fichier de configuration -configuration.py
Après avoir configuré votre fichier .env avec les clés API appropriées, l'étape suivante consiste à mettre à jour la configuration du modèle par défaut de votre application. La mise à jour de la configuration garantit que le système utilise les services et les modèles que vous avez spécifiés dans votre fichier .env.
Accédez au fichier de configuration :
Le fichier configuration.py contient les paramètres du modèle par défaut utilisés par l'agent de recherche pour trois tâches principales :
- Modèle d'intégration - convertit les documents en représentations vectorielles
- Modèle de requête - traite la requête de l'utilisateur en un vecteur
- Modèle de réponse - génère la réponse finale
Par défaut, le code utilise les modèles d'OpenAI (par exemple, openai/text-embedding-3-small) et d'Anthropic (par exemple, anthropic/claude-3-5-sonnet-20240620 and anthropic/claude-3-haiku-20240307).
Dans ce blog, nous passerons à l'utilisation des modèles Cohere. Si vous utilisez déjà OpenAI ou Anthropic, aucun changement n'est nécessaire.
Exemple de modifications (en utilisant Cohere) :
Ouvrez configuration.py et modifiez les valeurs par défaut du modèle comme indiqué ci-dessous :
Exécution de l'agent de recherche avec LangGraph CLI
1. Lancer le serveur LangGraph
Cette opération permet de démarrer localement le serveur LangGraph API. Si l'opération se déroule correctement, vous devriez voir apparaître quelque chose comme :
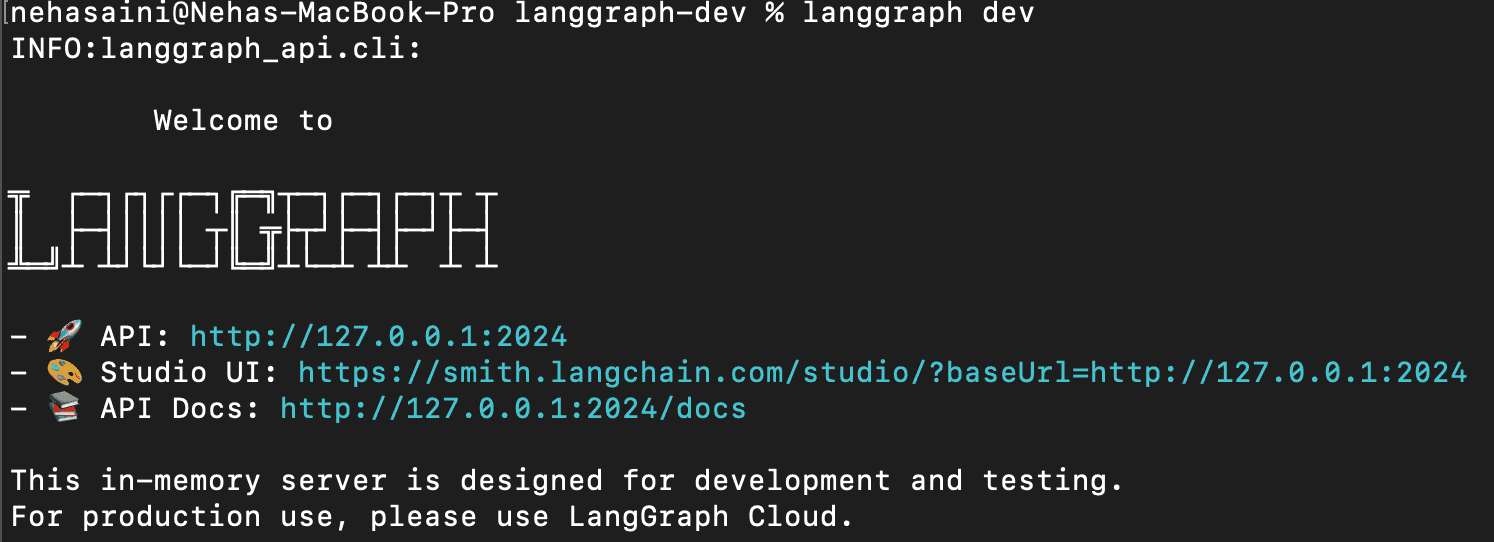
URL de l'interface utilisateur d'Open Studio.
Deux graphiques sont disponibles :
- Graphique de récupération: Récupère les données d'Elasticsearch et répond à la requête à l'aide d'un LLM.
- Graphique d'indexation: Indexe les documents dans Elasticsearch et génère des embeddings à l'aide d'un LLM.

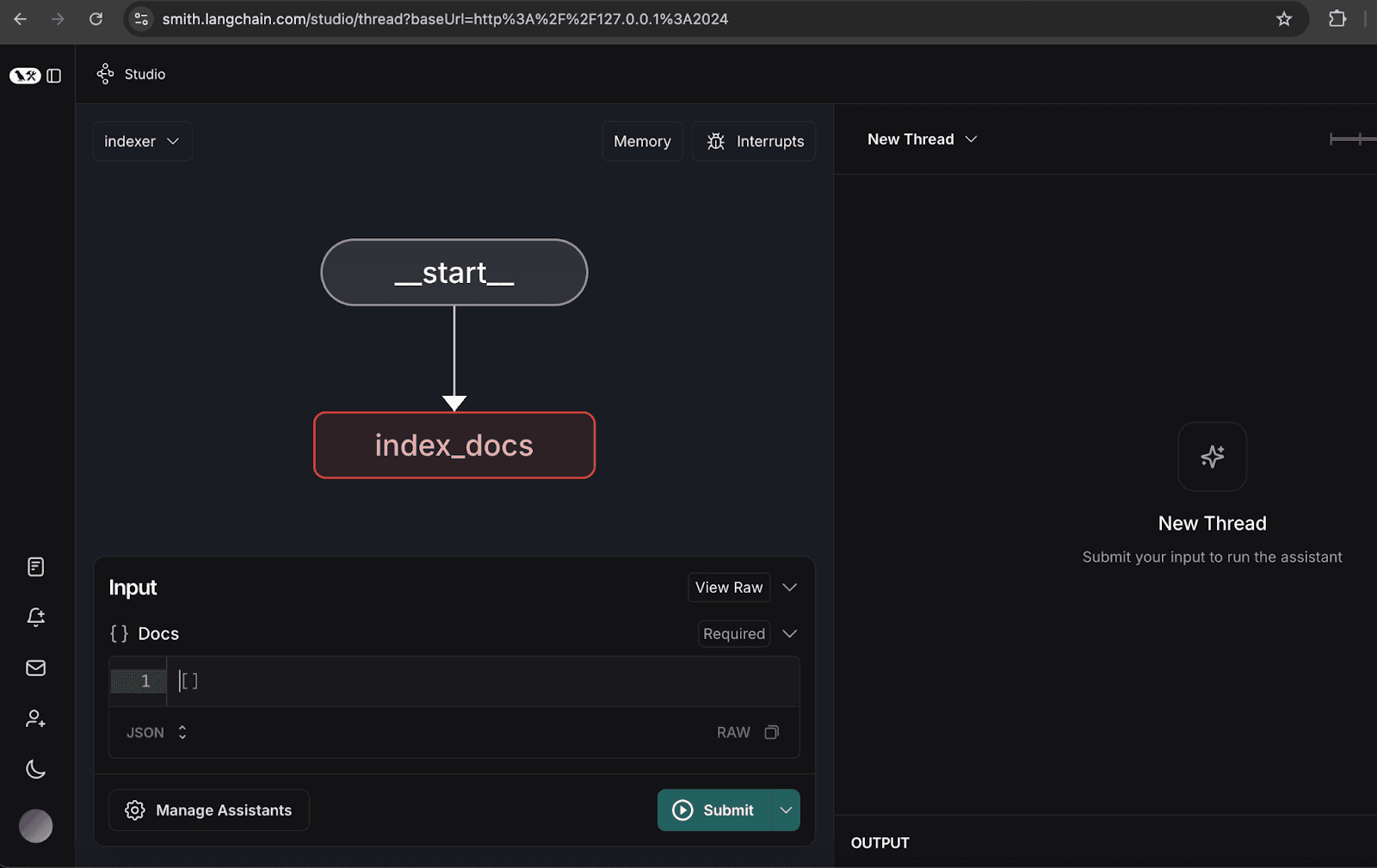
2. Configuration du graphe de l'indexeur
- Ouvrez le graphique de l'indexeur.
- Cliquez sur gérer les assistants.
- Cliquez sur "Ajouter un nouvel assistant", entrez les détails de l'utilisateur comme spécifié, puis fermez la fenêtre.


3. Indexation de documents types
- Indexez les documents types suivants, qui représentent un rapport trimestriel hypothétique pour l'organisation NoveTech :
Une fois les documents indexés, un message de suppression apparaît dans le fil de discussion, comme indiqué ci-dessous.

4. Exécution du graphe de recherche
- Passez au graphique de recherche.
- Saisissez la requête de recherche suivante :

Le système renvoie les documents pertinents et fournit une réponse exacte sur la base des données indexées.
Personnaliser l'agent de recherche
Pour améliorer l'expérience de l'utilisateur, nous introduisons une étape de personnalisation dans le graphe de recherche afin de prédire les trois prochaines questions que l'utilisateur pourrait poser. Cette prédiction est basée sur :
- Contexte des documents extraits
- Interactions avec les utilisateurs précédents
- Dernière requête de l'utilisateur
Les modifications de code suivantes sont nécessaires pour mettre en œuvre la fonction de prédiction des requêtes :
1. Mettez à jour graph.py
- Ajouter la fonction
predict_query:
- Modifier la fonction
respondpour qu'elle renvoie l'objetresponseau lieu du message :
- Mise à jour de la structure du graphe afin d'ajouter un nouveau nœud et une nouvelle arête pour predict_query :
2. Mettez à jour prompts.py
- Demande de devis pour la prédiction de guery dans
prompts.py:
3. Mettez à jour configuration.py
- Ajouter
predict_next_question_prompt:
4. Mettez à jour state.py
- Ajouter les attributs suivants :
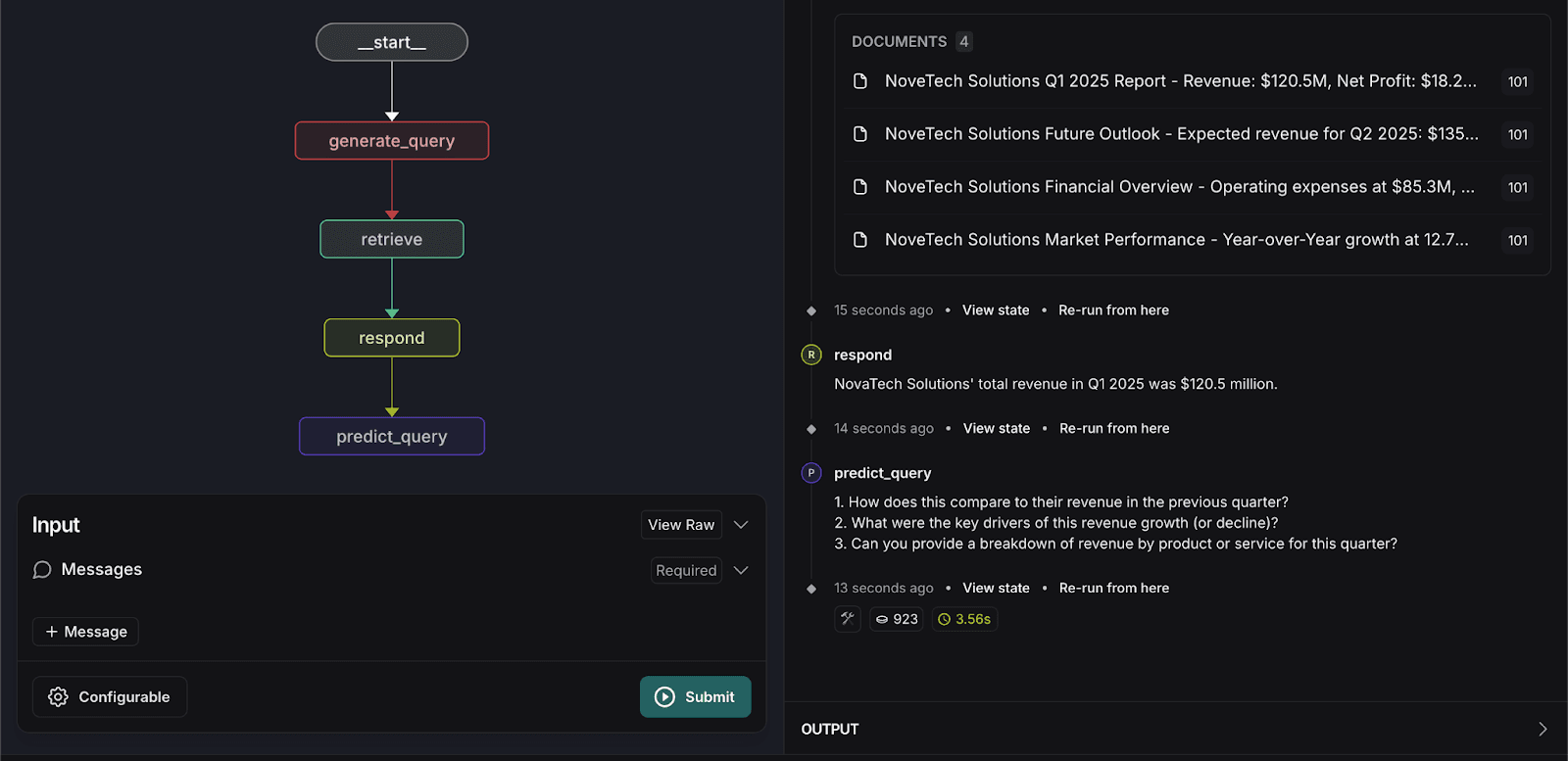
5. Réexécutez le graphique de recherche
- Saisissez à nouveau la requête de recherche suivante :
Le système traitera les données et prévoira trois questions connexes que les utilisateurs pourraient poser, comme indiqué ci-dessous.
Conclusion
L'intégration du modèle Retrieval Agent dans LangGraph Studio et CLI offre plusieurs avantages :
- Développement accéléré: Les modèles et les outils de visualisation rationalisent la création et le débogage des flux de recherche, réduisant ainsi le temps de développement.
- Déploiement transparent: La prise en charge intégrée des API et de la mise à l'échelle automatique garantit un déploiement sans heurts dans tous les environnements.
- Des mises à jour faciles : La modification des flux de travail, l'ajout de nouvelles fonctionnalités et l'intégration de nœuds supplémentaires sont simples, ce qui facilite l'évolution et l'amélioration du processus de recherche.
- Mémoire persistante: Le système conserve les états et les connaissances des agents, ce qui améliore la cohérence et la fiabilité.
- Modélisation flexible des flux de travail: Les développeurs peuvent personnaliser la logique de recherche et les règles de communication pour des cas d'utilisation spécifiques.
- Interaction et débogage en temps réel: La possibilité d'interagir avec les agents en cours d'exécution permet de tester et de résoudre les problèmes de manière efficace.
En tirant parti de ces fonctionnalités, les organisations peuvent construire des systèmes de recherche puissants, efficaces et évolutifs qui améliorent l'accessibilité des données et l'expérience de l'utilisateur.
Le code source complet de ce projet est disponible sur GitHub.
Questions fréquentes
Qu'est-ce qu'un flux de travail RAG ?
Un flux de travail RAG (Retrieval-Augmented Generation) est un moyen de donner à un modèle d'IA l'accès à vos données privées afin qu'il puisse fournir des réponses précises et basées sur des faits au lieu de "halluciner."
Pourquoi utiliser Elasticsearch comme base de données pour un agent LangGraph ?
Elasticsearch fait office de mémoire à long terme "" pour l'agent. Contrairement à une base de données standard, elle est conçue pour la recherche hybride, qui combine la recherche vectorielle (compréhension du sens) et la recherche par mot-clé (recherche de termes exacts). Ainsi, que vous demandiez "Q1 revenue" ou "financial growth," Elasticsearch fournit les documents les plus pertinents à traiter par LangGraph.
Puis-je construire un système multi-utilisateurs avec le modèle d'agent de recherche LangGraph ?
Oui. L'article démontre ceci à travers la configuration du graphe de l'indexeur en utilisant un identifiant d'utilisateur (comme "101"). Cela vous permet de marquer les documents avec des propriétaires spécifiques, ce qui permet à l'agent de recherche de trouver uniquement les informations qu'un utilisateur spécifique est autorisé à voir.
Pour aller plus loin

Décrivez, ne dessinez pas : tableaux de bord Kibana IA natifs via MCP et ES|QL
Du prompt au tableau de bord. Apprenez à créer des tableaux de bord Kibana en langage naturel grâce à example-mcp-dashbuilder : une application MCP open source qui écrit des requêtes ES|QL, crée des graphiques interactifs et exporte des tableaux de bord entièrement fonctionnels directement vers Kibana.

13 mars 2026
Résolution d'entités avec Elasticsearch, partie 4 : le défi ultime
Relever et évaluer les problématiques de réconciliation d’entités dans un ensemble de données complexe et varié, dont la structure interdit l’usage de méthodes simplifiées ou de contournements.

26 février 2026
Résolution d’entités avec Elasticsearch et les LLM, partie 2 : mise en correspondance d’entités avec le jugement des LLM et la recherche sémantique
Utiliser la recherche sémantique et le jugement transparent des LLM pour la résolution d’entités dans Elasticsearch.

5 janvier 2026
Créer des agents avec supervision humaine à l’aide de LangGraph et Elasticsearch
Découvrez comment concevoir des agents avec supervision humaine grâce à LangGraph et Elasticsearch, en intégrant l’humain dans la boucle pour combler les lacunes contextuelles et valider les appels d’outils avant leur exécution.

2 janvier 2026
Automatisation de l'analyse des logs dans Streams avec le ML
Découvrez comment une approche hybride de ML a atteint une précision de 94 % pour l'analyse syntaxique des logs et 91 % pour le partitionnement des logs grâce à des expériences d’automatisation avec l’empreinte des formats de log dans Streams.