De la recherche vectorielle aux API REST puissantes, Elasticsearch met à disposition des développeurs la boîte à outils de recherche la plus complète. Explorez nos notebooks d’exemple dans le dépôt Elasticsearch Labs pour tester de nouvelles approches. Vous pouvez également démarrer un essai gratuit ou exécuter Elasticsearch en local dès aujourd’hui.
La recherche vectorielle constitue la base de la mise en œuvre d'une recherche sémantique pour le texte ou d'une recherche de similarité pour les images, les vidéos ou les fichiers audio. Dans le cas de la recherche vectorielle, les vecteurs sont des représentations mathématiques de données qui peuvent être énormes et parfois lentes. La meilleure quantification binaire (ci-après dénommée BBQ) est une méthode de compression pour les vecteurs. Il vous permet de trouver les bonnes correspondances tout en réduisant les vecteurs pour les rendre plus rapides à rechercher et à traiter. Cet article traite de BBQ et de rescore_vector, un champ disponible uniquement pour les indices quantifiés et qui permet de rescorer automatiquement les vecteurs.
Toutes les requêtes complètes et les résultats mentionnés dans cet article peuvent être trouvés dans notre dépôt de code Elasticsearch Labs.
Pourquoi mettre en œuvre une meilleure quantification binaire (BBQ) dans votre cas d'utilisation ?
Remarque : pour une compréhension approfondie du fonctionnement mathématique du BBQ, veuillez consulter la section "Apprentissage complémentaire" ci-dessous. Dans le cadre de ce blog, l'accent est mis sur la mise en œuvre.
Bien que les mathématiques soient intrigantes, elles sont essentielles si vous voulez comprendre pourquoi vos recherches vectorielles restent précises. En fin de compte, il s'agit d'une question de compression, car il s'avère qu'avec les algorithmes actuels de recherche vectorielle, vous êtes limité par la vitesse de lecture des données. Par conséquent, si vous pouvez placer toutes ces données dans la mémoire, vous bénéficiez d'un gain de vitesse significatif par rapport à la lecture à partir du stockage(la mémoire est environ 200 fois plus rapide que les disques SSD).
Il y a quelques points à garder à l'esprit :
- Les indices basés sur les graphes, tels que HNSW (Hierarchical Navigable Small World), sont les plus rapides pour la recherche vectorielle.
- HNSW : un algorithme de recherche approximative du plus proche voisin qui construit une structure de graphe multicouche pour permettre des recherches de similarité efficaces en haute dimension.
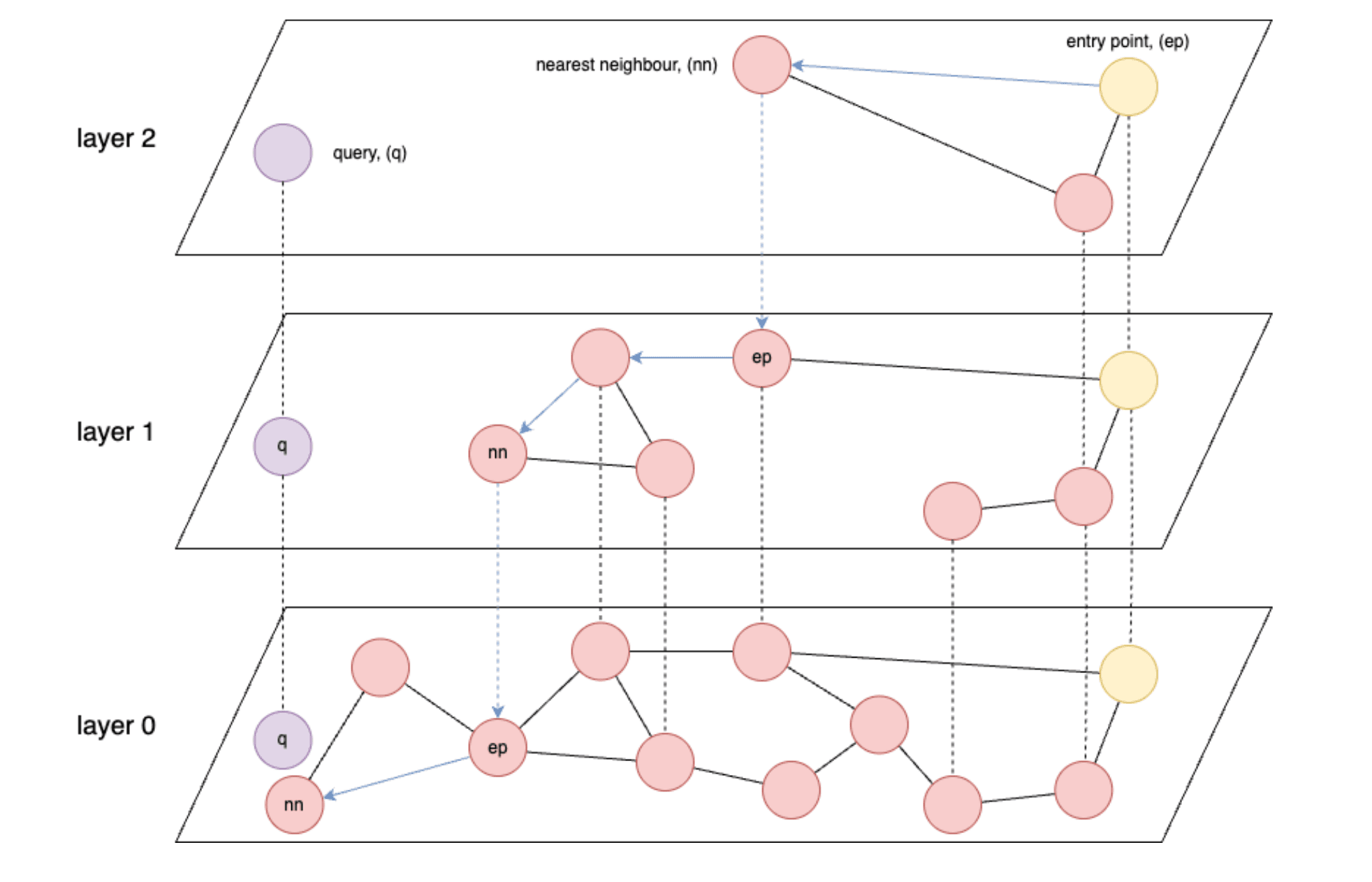
- La vitesse de HNSW est fondamentalement limitée par la vitesse de lecture des données à partir de la mémoire ou, dans le pire des cas, à partir du stockage.
- L'idéal est de pouvoir charger tous les vecteurs stockés dans la mémoire.
- Les modèles d'intégration produisent généralement des vecteurs avec une précision float32, soit 4 octets par nombre à virgule flottante.
- Enfin, selon le nombre de vecteurs et/ou de dimensions que vous avez, vous pouvez très rapidement manquer de mémoire pour conserver tous vos vecteurs.
Si l'on prend cela pour acquis, on constate qu'un problème se pose rapidement dès que l'on commence à ingérer des millions, voire des milliards de vecteurs, chacun ayant potentiellement des centaines, voire des milliers de dimensions. La section intitulée "Chiffres approximatifs sur les taux de compression" fournit quelques chiffres approximatifs.
De quoi avez-vous besoin pour commencer ?
Pour commencer, vous aurez besoin des éléments suivants :
- Si vous utilisez Elastic Cloud ou on-prem, vous aurez besoin d'une version d'Elasticsearch supérieure à 8.18. Alors que BBQ a été introduit dans la version 8.16, dans cet article, vous utiliserez
vector_rescore, qui a été introduit dans la version 8.18. - En outre, vous devrez également vous assurer qu'il existe un nœud d'apprentissage automatique (ML) dans votre cluster. (Remarque : un nœud ML doté d'un minimum de 4 Go est nécessaire pour charger le modèle, mais vous aurez probablement besoin de nœuds beaucoup plus grands pour des charges de travail de production complètes).
- Si vous utilisez Serverless, vous devrez sélectionner une instance optimisée pour les vecteurs.
- Vous aurez également besoin d'une connaissance de base des bases de données vectorielles. Si vous n'êtes pas encore familiarisé avec les concepts de recherche vectorielle dans Elastic, vous pouvez consulter les ressources suivantes :
Meilleure implémentation de la quantification binaire (BBQ)
Pour que ce blog reste simple, vous utiliserez les fonctions intégrées lorsqu'elles sont disponibles. Dans ce cas, vous disposez du modèle d'intégration vectorielle .multilingual-e5-small qui s'exécutera directement dans Elasticsearch sur un nœud d'apprentissage automatique. Notez que vous pouvez remplacer le modèle text_embedding par l'intégrateur de votre choix(OpenAI, Google AI Studio, Cohere et bien d'autres). Si le modèle que vous préférez n'est pas encore intégré, vous pouvez également apporter vos propres encastrements vectoriels denses).
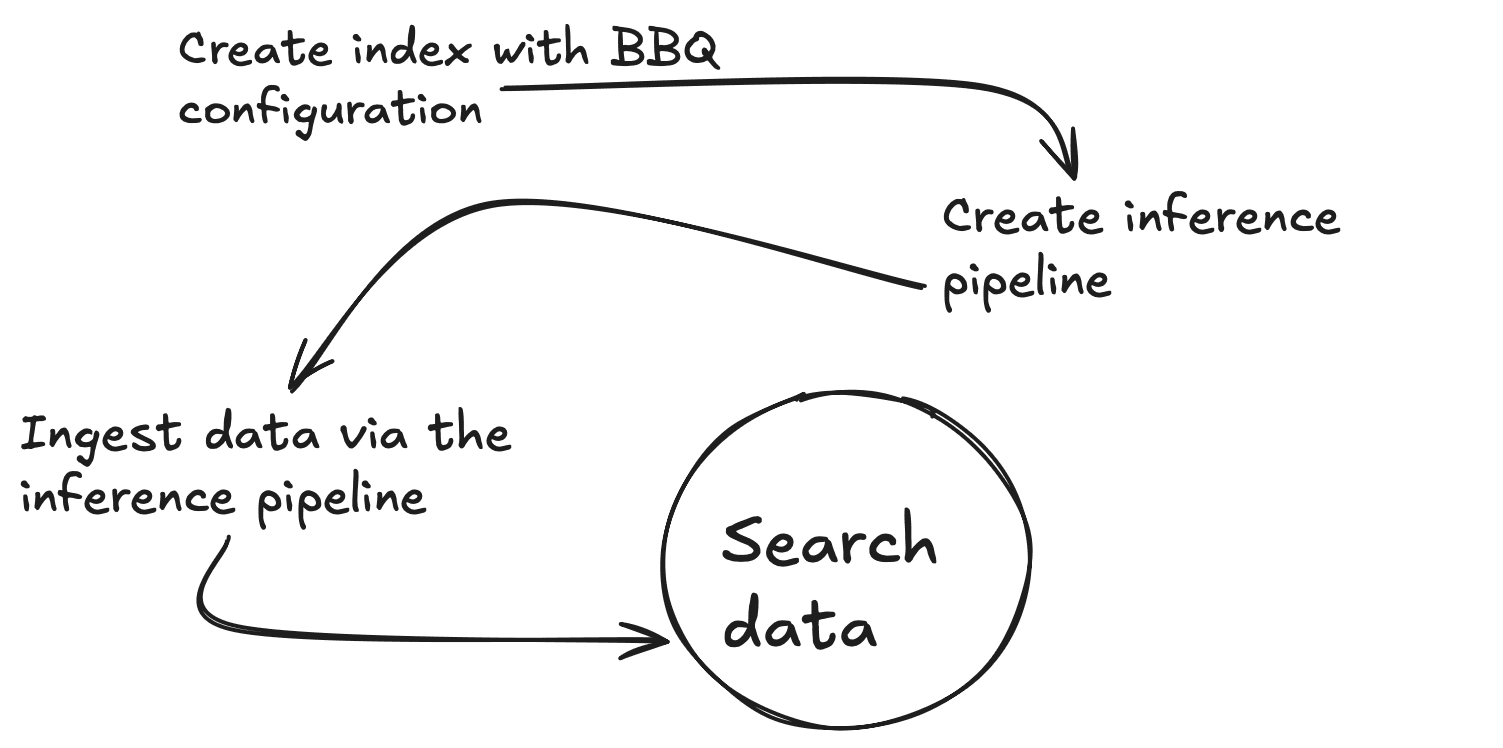
Tout d'abord, vous devrez créer un point final d'inférence pour générer des vecteurs pour un morceau de texte donné. Vous exécuterez toutes ces commandes à partir de la console Kibana Dev Tools. Cette commande permet de télécharger le site .multilingual-e5-small. S'il n'existe pas encore, il configurera votre point d'accès ; cette opération peut prendre une minute. Vous pouvez voir le résultat attendu dans le fichier 01-create-an-inference-endpoint-output.json dans le dossier Outputs.
Une fois qu'il est revenu, votre modèle est configuré et vous pouvez tester que le modèle fonctionne comme prévu à l'aide de la commande suivante. Vous pouvez voir le résultat attendu dans le fichier 02-embed-text-output.json dans le dossier Outputs.
Si vous rencontrez des problèmes liés au fait que votre modèle formé n'est affecté à aucun nœud, il se peut que vous deviez démarrer votre modèle manuellement.
Créons maintenant un nouveau mappage avec deux propriétés, un champ de texte standard (my_field) et un champ vectoriel dense (my_vector) avec 384 dimensions pour correspondre à la sortie du modèle d'intégration. Vous pouvez également passer outre l'adresse index_options.type to bbq_hnsw. Vous pouvez voir le résultat attendu dans le fichier 03-create-byte-qauntized-index-output.json dans le dossier Outputs.
Pour s'assurer qu'Elasticsearch génère vos vecteurs, vous pouvez utiliser un pipeline d'ingestion. Ce pipeline nécessite trois éléments : le point final (model_id), le site input_field pour lequel vous souhaitez créer des vecteurs et le site output_field dans lequel vous souhaitez stocker ces vecteurs. La première commande ci-dessous crée un pipeline d'ingestion d'inférence, qui utilise le service d'inférence sous le capot, et la seconde teste le bon fonctionnement du pipeline. Vous pouvez voir le résultat attendu dans le fichier 04-create-and-simulate-ingest-pipeline-output.json dans le dossier Outputs.
Vous êtes maintenant prêt à ajouter des documents à l'aide des deux premières commandes ci-dessous et à tester le fonctionnement de vos recherches à l'aide de la troisième commande. Vous pouvez vérifier le résultat attendu dans le fichier 05-bbq-index-output.json dans le dossier Outputs.
Comme nous l'avons recommandé dans cet article, le recalage et le suréchantillonnage sont conseillés lorsque vous passez à des quantités de données non triviales, car ils permettent de maintenir une précision de rappel élevée tout en bénéficiant des avantages de la compression. À partir de la version 8.18 d'Elasticsearch, vous pouvez le faire de cette façon en utilisant rescore_vector. Le résultat attendu se trouve dans le fichier 06-bbq-search-8-18-output.json dans le dossier Outputs.
Comment ces résultats se comparent-ils à ceux que vous obtiendriez avec des données brutes ? Si vous refaites tout ce qui précède mais avec index_options.type: hnsw, vous verrez que les scores sont très comparables. Vous pouvez voir le résultat attendu dans le fichier 07-raw-vector-output.json dans le dossier Outputs.
Chiffres approximatifs sur les taux de compression
Les exigences en matière de stockage et de mémoire peuvent rapidement devenir un défi important lorsque l'on travaille avec la recherche vectorielle. La décomposition suivante illustre comment les différentes techniques de quantification réduisent considérablement l'empreinte mémoire des données vectorielles.
| Vecteurs (V) | Dimensions (D) | brut (V x D x 4) | int8 (V x (D x 1 + 4)) | int4 (V x (D x 0,5 + 4)) | bbq (V x (D x 0,125 + 4)) |
|---|---|---|---|---|---|
| 10,000,000 | 384 | 14.31GB | 3.61GB | 1.83GB | 0.58GB |
| 50,000,000 | 384 | 71.53GB | 18.07GB | 9.13GB | 2.89GB |
| 100,000,000 | 384 | 143.05GB | 36.14GB | 18.25GB | 5.77GB |
Conclusion
BBQ est une optimisation que vous pouvez appliquer à vos données vectorielles pour les compresser sans sacrifier la précision. Il convertit les vecteurs en bits, ce qui vous permet d'effectuer des recherches efficaces dans les données et de faire évoluer vos flux de travail d'IA pour accélérer les recherches et optimiser le stockage des données.
Poursuite de l'apprentissage
Si vous souhaitez en savoir plus sur le barbecue, n'hésitez pas à consulter les ressources suivantes :
- Quantification binaire (BBQ) dans Lucene et Elasticsearch
- Meilleure quantification binaire (BBQ) vs quantification par produit
- Quantification scalaire optimisée : Une quantification binaire encore meilleure
- Meilleure quantification binaire (BBQ) : De l'octet au BBQ, le secret d'une meilleure recherche vectorielle par Ben Trent
Pour aller plus loin

23 avril 2026
Comment nous avons construit Elasticsearch simdvec pour faire de la recherche vectorielle l'une des plus rapides au monde
Comment nous avons conçu Elasticsearch simdvec, la bibliothèque de noyaux SIMD optimisée manuellement qui alimente chaque requête de recherche vectorielle dans Elasticsearch.

4 mai 2026
Comment mesurer et améliorer le rappel de recherche Elasticsearch : de 0,43 à 0,75 avec la recherche hybride
Découvrez comment mesurer et améliorer le rappel de recherche dans Elasticsearch en combinant la recherche lexicale BM25 avec les embeddings vectoriels de Jina AI, en utilisant l’API rank_eval pour valider l’amélioration avec des données chiffrées.

10 avril 2026
Clustering de documents non supervisé avec Elasticsearch + Jina embeddings
Une approche pratique et reproductible pour le clustering non supervisé de documents avec Elasticsearch et les embeddings Jina.

2 avril 2026
Quand les TSDS rencontrent l'ILM : Concevoir des flux de données temporelles qui ne rejettent pas les données en retard
Comment les limites temporelles des TSDS interagissent avec les phases de l'ILM ; et comment concevoir des politiques qui tolèrent les métriques arrivant en retard.

1 avril 2026
LINQ to Elasticsearch ES|QL : écrire en C#, interroger Elasticsearch
Découverte du nouveau fournisseur LINQ to Elasticsearch ES|QL dans le client Elasticsearch .NET, qui vous permet d'écrire du code C# qui est automatiquement converti en requêtes ES|QL.