De la recherche vectorielle aux API REST puissantes, Elasticsearch met à disposition des développeurs la boîte à outils de recherche la plus complète. Explorez nos notebooks d’exemple dans le dépôt Elasticsearch Labs pour tester de nouvelles approches. Vous pouvez également démarrer un essai gratuit ou exécuter Elasticsearch en local dès aujourd’hui.
Tout le code peut être trouvé dans le repo de Searchlabs, dans la branche advanced-rag-techniques.
Bienvenue dans la deuxième partie de notre article sur les techniques avancées de RAG ! Dans la première partie de cette série, nous avons mis en place, discuté et implémenté les composants de traitement des données du pipeline RAG avancé :
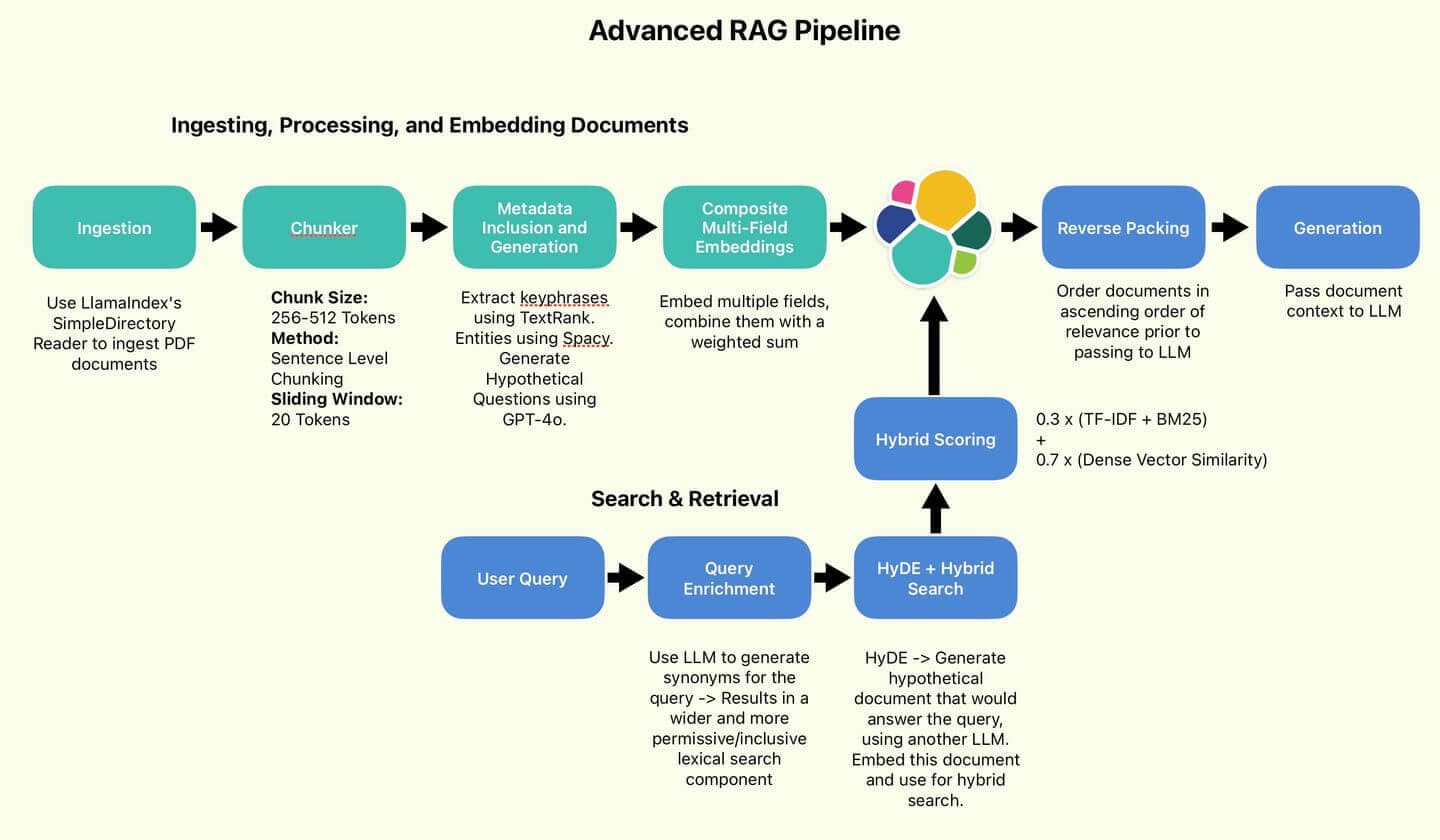
Le pipeline RAG utilisé par l'auteur.
Dans cette partie, nous allons procéder à l'interrogation et au test de notre mise en œuvre. Allons droit au but !
Table des matières
- Recherche et récupération, génération de réponses
- Expériences
- Conclusion
- Annexe
Recherche et récupération, génération de réponses
Posons notre première question, idéalement une information trouvée principalement dans le rapport annuel. Que diriez-vous de.. :
Appliquons maintenant quelques-unes de nos techniques pour améliorer la requête.
Enrichir les requêtes avec des synonymes
Tout d'abord, améliorons la diversité de la formulation de la requête et transformons-la en une forme qui peut être facilement traitée dans une requête Elasticsearch. Nous ferons appel à GPT-4o pour convertir la requête en une liste de clauses OR. Écrivons ce message :
Appliqué à notre requête, GPT-4o génère des synonymes de la requête de base et du vocabulaire connexe.
Dans la classe ESQueryMaker, j'ai défini une fonction pour diviser la requête :
Son rôle est de prendre cette chaîne de clauses OR et de les diviser en une liste de termes, ce qui nous permet d'effectuer une correspondance multiple sur les champs clés du document :
Finalement, nous avons abouti à cette requête :
Cela permet de couvrir beaucoup plus de bases que la requête initiale, réduisant ainsi le risque de manquer un résultat de recherche en raison de l'oubli d'un synonyme. Mais nous pouvons faire plus.
HyDE (Hypothetical Document Embedding)
Faisons à nouveau appel à GPT-4o, cette fois pour mettre en œuvre HyDE.
Le principe de base de HyDE est de générer un document hypothétique - le type de document qui contiendrait probablement la réponse à la requête initiale. Le caractère factuel ou l'exactitude du document n'est pas en cause. En gardant cela à l'esprit, rédigeons l'invite suivante :
La recherche vectorielle s'appuyant généralement sur la similarité vectorielle cosinusoïdale, HyDE part du principe que l'on peut obtenir de meilleurs résultats en faisant correspondre des documents à des documents plutôt que des requêtes à des documents.
Ce qui nous importe, c'est la structure, le flux et la terminologie. Ce n'est pas tant le cas pour les faits. Le GPT-4o produit un document HyDE comme celui-ci :
Il semble assez crédible, comme le candidat idéal pour les types de documents que nous aimerions indexer. Nous allons l'intégrer et l'utiliser pour la recherche hybride.
Recherche hybride
C'est le cœur de notre logique de recherche. Notre composante de recherche lexicale sera les chaînes de clauses OR générées. Notre composante vectorielle dense sera le document HyDE intégré (également appelé vecteur de recherche). Nous utilisons KNN pour identifier efficacement les documents candidats les plus proches de notre vecteur de recherche. Nous appelons notre composant de recherche lexicale Scoring with TF-IDF and BM25 par défaut. Enfin, les scores des vecteurs lexicaux et denses seront combinés en utilisant le ratio 30/70 recommandé par Wang et al.
Enfin, nous pouvons reconstituer une fonction RAG. Notre RAG, de la question à la réponse, suivra ce flux :
- Convertir la requête en clauses OR.
- Générer un document HyDE et l'intégrer.
- Transmettre ces deux informations à la recherche hybride.
- Récupérer les n premiers résultats, les inverser de façon à ce que le score le plus pertinent soit le "plus récent" dans la mémoire contextuelle du LLM (Reverse Packing) Reverse Packing Exemple : Requête : "Techniques d'optimisation des requêtes Elasticsearch" Documents récupérés (ordonnés par pertinence) : Ordre inversé pour le contexte LLM : En inversant l'ordre, l'information la plus pertinente (1) apparaît en dernier dans le contexte, recevant potentiellement plus d'attention de la part du LLM pendant la génération de la réponse.
- "Utilisez les requêtes bool pour combiner efficacement plusieurs critères de recherche."
- "Mettre en œuvre des stratégies de mise en cache pour améliorer les temps de réponse des requêtes."
- "Optimiser les mappages d'index pour accélérer les performances de recherche."
- "Optimiser les mappages d'index pour accélérer les performances de recherche."
- "Mettre en œuvre des stratégies de mise en cache pour améliorer les temps de réponse des requêtes."
- "Utilisez les requêtes bool pour combiner efficacement plusieurs critères de recherche."
- Transmettre le contexte au LLM pour qu'il le génère.
Exécutons notre requête et obtenons notre réponse :
C'est une bonne chose. C'est exact.
Expériences
Il faut maintenant répondre à une question importante. Qu'avons-nous obtenu en investissant tant d'efforts et de complexité supplémentaire dans ces mises en œuvre ?
Faisons une petite comparaison. Le pipeline RAG que nous avons mis en œuvre par rapport à la recherche hybride de base, sans aucune des améliorations que nous avons apportées. Nous allons effectuer une petite série de tests et voir si nous constatons des différences substantielles. Nous appellerons le RAG que nous venons de mettre en œuvre AdvancedRAG et le pipeline de base SimpleRAG.

RAG Pipeline simple et sans fioritures
Synthèse des résultats
Ce tableau résume les résultats de cinq tests effectués sur les deux pipelines RAG. J'ai évalué la supériorité relative de chaque méthode sur la base du détail et de la qualité des réponses, mais il s'agit d'un jugement totalement subjectif. Les réponses réelles sont reproduites sous ce tableau pour votre considération. Ceci étant dit, jetons un coup d'œil sur leurs résultats !
SimpleRAG n'a pas pu répondre aux questions 1 & 5. AdvancedRAG a également répondu de manière beaucoup plus détaillée aux questions 2, 3 et 4. Sur la base de ces détails, j'ai jugé la qualité des réponses d'AdvancedRAG meilleure.
| Test | Question | AdvancedRAG Performance | Performance de SimpleRAG | AdvancedRAG Latence | Latence de SimpleRAG | Gagnant |
|---|---|---|---|---|---|---|
| 1 | Qui audite Elastic ? | A correctement identifié PwC comme étant l'auditeur. | L'auditeur n'a pas été identifié. | 11.6s | 4.4s | AdvancedRAG |
| 2 | Quel a été le revenu total en 2023 ? | A fourni le chiffre d'affaires correct. Inclusion d'un contexte supplémentaire avec les recettes des années précédentes. | A fourni le chiffre d'affaires correct. | 13.3s | 2.8s | AdvancedRAG |
| 3 | De quel produit la croissance dépend-elle principalement ? Combien ? | A correctement identifié l'Elastic Cloud comme étant le facteur clé. Le contexte général des recettes a été inclus & de manière plus détaillée. | A correctement identifié l'Elastic Cloud comme étant le facteur clé. | 14.1s | 12.8s | AdvancedRAG |
| 4 | Décrire le régime d'avantages sociaux des employés | Description complète des régimes de retraite, des programmes de santé et des autres avantages. Incluait des montants de cotisation spécifiques pour différentes années. | A donné un bon aperçu des avantages, y compris la rémunération, les plans de retraite, l'environnement de travail et le programme Elastic Cares. | 26.6s | 11.6s | AdvancedRAG |
| 5 | Quelles sont les entreprises acquises par Elastic ? | A corrigé la liste des acquisitions récentes mentionnées dans le rapport (CmdWatch, Build Security, Optimyze). Il a fourni quelques dates d'acquisition et des prix d'achat. | Échec de la recherche d'informations pertinentes dans le contexte fourni. | 11.9s | 2.7s | AdvancedRAG |
Test 1 : Qui vérifie Elastic ?
AdvancedRAG
SimpleRAG
Résumé: SimpleRAG n'a pas identifié PWC comme étant l'auditeur.
D'accord, c'est assez surprenant. Cela ressemble à un échec de recherche de la part de SimpleRAG. Aucun document relatif à l'audit n'a été retrouvé. Réduisons un peu la difficulté avec le test suivant.
Test 2 : recettes totales en 2023
AdvancedRAG
SimpleRAG
Résumé: les deux RAG ont obtenu la bonne réponse : 1 068 989 000 dollars de recettes totales en 2023.
Ils étaient tous les deux ici. Il semble qu'AdvancedRAG ait acquis un plus grand nombre de documents ? La réponse est certainement plus détaillée et intègre des informations des années précédentes. On peut s'y attendre compte tenu des améliorations que nous avons apportées, mais il est encore trop tôt pour se prononcer.
Augmentons la difficulté.
Test 3 : De quel produit la croissance dépend-elle principalement ? Combien ?
AdvancedRAG
SimpleRAG
Résumé: les deux groupes d'experts ont correctement identifié Elastic Cloud comme le principal moteur de croissance. Cependant, AdvancedRAG fournit plus de détails, en tenant compte des revenus d'abonnement et de la croissance de la clientèle, et mentionne explicitement d'autres offres d'Elastic.
Test 4 : Décrire le régime d'avantages sociaux des salariés
AdvancedRAG
SimpleRAG
Résumé: AdvancedRAG va beaucoup plus en profondeur et en détail, en mentionnant le plan 401K pour les employés basés aux États-Unis, ainsi qu'en définissant les plans de contribution en dehors des États-Unis. Il mentionne également les régimes de santé et de bien-être, mais ne mentionne pas le programme Elastic Cares, que SimpleRAG mentionne.
Test 5 : Quelles sont les entreprises acquises par Elastic ?
AdvancedRAG
SimpleRAG
Résumé: SimpleRAG ne récupère aucune information pertinente sur les acquisitions, ce qui entraîne un échec de la réponse. AdvancedRAG répertorie correctement CmdWatch, Build Security et Optimyze, qui sont les principales acquisitions mentionnées dans le rapport.
Conclusion
D'après nos tests, nos techniques avancées semblent augmenter l'étendue et la profondeur des informations présentées, ce qui pourrait améliorer la qualité des réponses RAG.
En outre, il est possible que la fiabilité soit améliorée, car les questions formulées de manière ambiguë, telles que Which companies did Elastic acquire? et Who audits Elastic, ont été correctement répondues par AdvancedRAG, mais pas par SimpleRAG.
Toutefois, il convient de garder à l'esprit que dans 3 cas sur 5, le pipeline RAG de base, intégrant la recherche hybride mais aucune autre technique, a réussi à produire des réponses qui capturaient la plupart des informations clés.
Il convient de noter qu'en raison de l'incorporation des LLM dans les phases de préparation des données et d'interrogation, la latence d'AdvancedRAG est généralement de 2 à 5 fois supérieure à celle de SimpleRAG. Il s'agit d'un coût important qui pourrait faire en sorte qu'AdvancedRAG ne convienne qu'aux situations où la qualité de la réponse est prioritaire par rapport à la latence.
Les coûts de latence importants peuvent être réduits en utilisant un LLM plus petit et moins cher comme Claude Haiku ou GPT-4o-mini à l'étape de préparation des données. Conservez les modèles avancés pour la génération de réponses.
Cela correspond aux conclusions de Wang et al. Comme le montrent leurs résultats, les améliorations apportées sont relativement progressives. En bref, un simple RAG de base vous permet d'obtenir un produit final décent, tout en étant moins cher et plus rapide. Pour moi, c'est une conclusion intéressante. Pour les cas d'utilisation où la vitesse et l'efficacité sont essentielles, SimpleRAG est un choix judicieux. Pour les cas d'utilisation où chaque goutte de performance doit être extraite, les techniques incorporées dans AdvancedRAG peuvent offrir une solution.

Les résultats de l'étude de Wang et al révèlent que l'utilisation de techniques avancées entraîne des améliorations constantes mais progressives.
Annexe
Prompts
Question du RAG - invite à répondre
Invitation à faire en sorte que le LLM génère des réponses basées sur la requête et le contexte.
Générateur de requêtes élastiques
Invite à enrichir les requêtes avec des synonymes et à les convertir au format OR.
Questions potentielles : invite à la création d'un générateur
Invite à générer des questions potentielles, à enrichir les métadonnées des documents.
Invite du générateur HyDE
Invite à générer des documents hypothétiques à l'aide de HyDE
Exemple de requête de recherche hybride
Pour aller plus loin

Décrivez, ne dessinez pas : tableaux de bord Kibana IA natifs via MCP et ES|QL
Du prompt au tableau de bord. Apprenez à créer des tableaux de bord Kibana en langage naturel grâce à example-mcp-dashbuilder : une application MCP open source qui écrit des requêtes ES|QL, crée des graphiques interactifs et exporte des tableaux de bord entièrement fonctionnels directement vers Kibana.

23 avril 2026
Comment nous avons construit Elasticsearch simdvec pour faire de la recherche vectorielle l'une des plus rapides au monde
Comment nous avons conçu Elasticsearch simdvec, la bibliothèque de noyaux SIMD optimisée manuellement qui alimente chaque requête de recherche vectorielle dans Elasticsearch.

4 mai 2026
Comment mesurer et améliorer le rappel de recherche Elasticsearch : de 0,43 à 0,75 avec la recherche hybride
Découvrez comment mesurer et améliorer le rappel de recherche dans Elasticsearch en combinant la recherche lexicale BM25 avec les embeddings vectoriels de Jina AI, en utilisant l’API rank_eval pour valider l’amélioration avec des données chiffrées.

10 avril 2026
Clustering de documents non supervisé avec Elasticsearch + Jina embeddings
Une approche pratique et reproductible pour le clustering non supervisé de documents avec Elasticsearch et les embeddings Jina.

2 avril 2026
Quand les TSDS rencontrent l'ILM : Concevoir des flux de données temporelles qui ne rejettent pas les données en retard
Comment les limites temporelles des TSDS interagissent avec les phases de l'ILM ; et comment concevoir des politiques qui tolèrent les métriques arrivant en retard.