¿Quieres obtener la certificación de Elastic? ¡Descubre cuándo se realizará la próxima capacitación Elasticsearch Engineer! Puedes iniciar una prueba gratuita en el cloud o prueba Elastic en tu máquina local ahora mismo.
Cuantización automática de bytes en Lucene
Aunque HNSW es una forma poderosa y flexible de almacenar y buscar vectores, requiere una cantidad significativa de memoria para funcionar rápidamente. Por ejemplo, consultar vectores float32 de 1 MM de 768 dimensiones requiere aproximadamente de RAM. Una vez que empiezas a buscar un número significativo de vectores, esto se vuelve caro. Una forma de usar alrededor menos de memoria es mediante cuantización por bytes. Lucene y, en consecuencia, Elasticsearch soportaron la indexación de durante algún tiempo, pero la construcción de estos vectores fue responsabilidad del usuario. Esto está a punto de cambiar, ya que introdujimos la cuantización en Lucene.
Cuantización escalar 101
Todas las técnicas de cuantización se consideran transformaciones con pérdida de los datos en bruto. Es decir, se pierde algo de información por el bien del espacio. Para una explicación detallada de la cuantización escalar, ver: Cuantización Escalar 101. A un nivel general, la cuantización escalar es una técnica de compresión con pérdida. Unas matemáticas sencillas ofrecen un ahorro significativo de espacio con muy poco impacto en la memoria.
Explorando la arquitectura
Quienes están acostumbrados a trabajar con Elasticsearch quizá ya estén familiarizados con estos conceptos, pero aquí tienes un resumen rápido de la distribución de los documentos para la búsqueda.
Cada índice de Elasticsearch está compuesto por múltiples fragmentos. Aunque cada fragmento solo puede asignar a un solo nodo, múltiples fragmentos por índice te dan paralelismo de cálculo entre nodos.
Cada fragmento está compuesto como un único Índice Luceno. Un índice Lucene consta de múltiples segmentos de solo lectura. Durante la indexación, los documentos se almacenan en búfer y periódicamente se vacian en un segmento de solo lectura. Cuando se cumplen ciertas condiciones, estos segmentos pueden fusionar en el fondo en un segmento más grande. Todo esto es configurable y tiene su propio conjunto de complejidades. Pero, cuando hablamos de segmentos y fusiones, nos referimos a segmentos Lucene de solo lectura y a la fusión periódica automática de estos segmentos. Aquí tienes una profundización en la fusión de segmentos y las decisiones de diseño.
Cuantización por segmento en Luceno
Cada segmento en Lucene almacena lo siguiente: los vectores individuales, los índices de grafos HNSW, los vectores cuantizados y los cuantiles calculados. Por brevedad, nos centraremos en cómo Lucene almacena vectores cuantizados y en bruto. Para cada segmento, llevamos un seguimiento de los vectores en bruto en el archivo , los vectores cuantizados y un único flotador de multiplicador correctivo en , así como los metadatos alrededor de la cuantización dentro del archivo .

Figura 1: Diseño simplificado de un archivo de almacenamiento vectorial en bruto. Ocupa de espacio en disco ya que los son 4 bytes. Como estamos cuantizando, estos no se cargarán durante la búsqueda HNSW. Solo se emplean si se aplicar específicamente (por ejemplo, secundario de fuerza bruta mediante repuntuación), o para la recuantización durante la fusión de segmentos.

Figura 2: Diseño simplificado del archivo. Ocupa del espacio y se cargará en memoria durante la búsqueda. El bytes es para tener en cuenta el multiplicador correctivo flotante, empleado para ajustar el puntaje y mejorar la precisión y la recuperación.

Figura 3: El diseño simplificado del archivo de metadatos. Aquí es donde hacemos seguimiento de la cuantización y la configuración vectorial junto con los cuantiles calculados para este segmento.
Así que, para cada segmento, almacenamos no solo los vectores cuantizados, sino también los cuantiles usados para fabricar estos vectores cuantizados y los vectores originales en bruto. Pero, ¿por qué mantenemos los vectores en bruto?
Cuantización que crece contigo
Como Lucene vacía periódicamente para leer solo segmentos, cada segmento solo tiene una vista parcial de todos tus datos. Esto significa que los cuantiles calculados solo se aplican directamente a ese conjunto muestral de todos tus datos. Ahora bien, esto no es un gran problema si tu muestra representa adecuadamente todo tu corpus. Pero Lucene te permite ordenar tu índice de varias maneras. Así que podrías indexar datos ordenados de una manera que agregue sesgo para cálculos de cuantil por segmento. ¡Además, puedes vaciar los datos cuando quieras! Tu conjunto de muestras podría ser muy pequeño, incluso solo un vector. Otro inconveniente es que tienes control sobre cuándo ocurren las fusiones. Aunque Elasticsearch tiene configuraciones por defecto y fusiones periódicas, puedes pedir una fusión cuando quieras a través de _force_merge API. Entonces, ¿cómo permitimos toda esta flexibilidad, proporcionando una buena cuantización que proporcione una buena recordación?
La cuantización vectorial de Lucene se ajustará automáticamente con el tiempo. Como Lucene está diseñado con una arquitectura de segmentos de solo lectura, tenemos garantías de que los datos de cada segmento no cambiaron y demarcaciones claras en el código para cuándo se pueden actualizar cosas. Esto significa que durante la fusión de segmentos podemos ajustar los cuantiles según sea necesario y posiblemente volver a cuantizar los vectores.
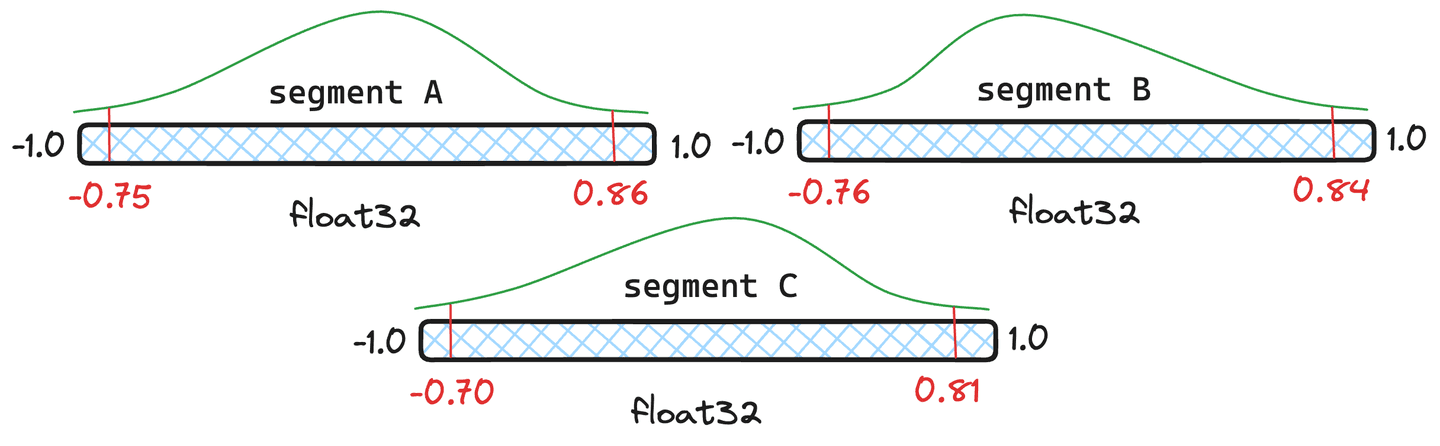
Figura 4: Tres segmentos de ejemplo con diferentes cuantiles.
¿Pero no es caro la recuantización? Tiene cierta sobrecarga, pero Lucene maneja los cuantiles con inteligencia y solo recuantiza completamente cuando es necesario. Usemos los segmentos de la Figura 4 como ejemplo. Demos a los y documentos cada uno y al solo documentos. Lucene tomará un promedio ponderado de los cuantiles y si ese cuantil combinado resultante está lo suficientemente cerca de los cuantiles originales de los segmentos, no tenemos que volver a cuantificar ese segmento y emplearemos los cuantiles recién fusionados.
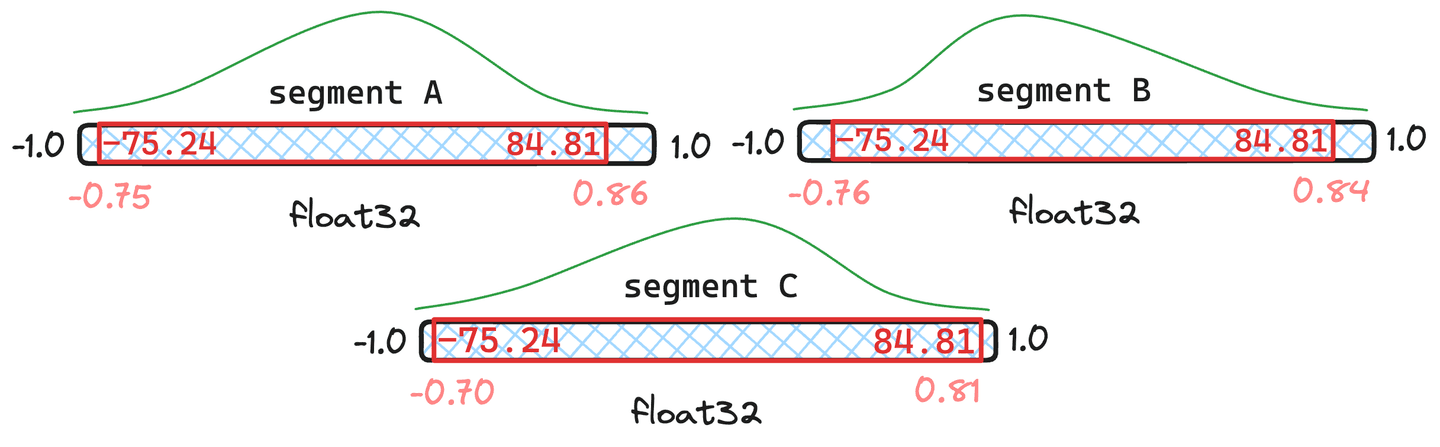
Figura 5: Ejemplo de cuantiles fusionados donde los segmentos y tienen documentos y solo .
En la situación visualizada en la figura 5, podemos ver que los cuantiles fusionados resultantes son muy similares a los cuantiles originales en y . Por tanto, no justifican cuantizar los vectores. El segmento parece desviar demasiado. En consecuencia, los vectores en se recuantizarían con los nuevos valores cuantiles fusionados.
De hecho, existen casos extremos en los que los cuantiles fusionados difieren significativamente de cualquiera de los cuantiles originales. En este caso, tomaremos una muestra de cada segmento y recalcularemos completamente los cuantiles.
Rendimiento y números de cuantización
Entonces, ¿es rápido y sigue proporcionando buena recuperación? Los siguientes números se recopilaron ejecutando el experimento en una instancia c3-standard-8 GCP. Para cerciorar una comparación justa con , usamos una instancia lo suficientemente grande como para almacenar vectores en bruto en memoria. Indexamos vectores de Cohere Wiki usando el producto interno máximo.
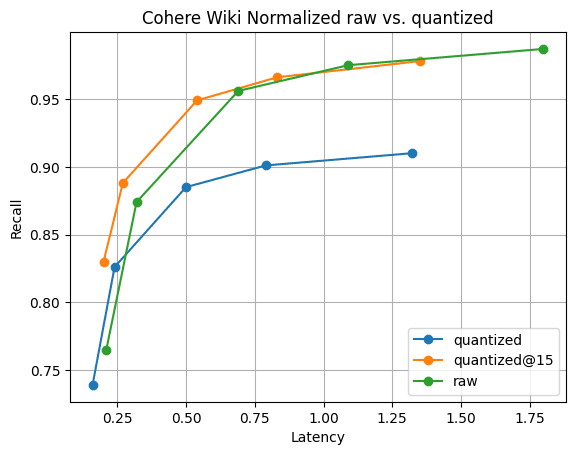
Figura 6: Recall@10 para vectores cuantizados frente a vectores en bruto. El rendimiento de búsqueda de vectores cuantizados es significativamente más rápido que el en bruto, y la recuperación se recupera rápidamente reuniendo solo 5 vectores más; visible .
La Figura 6 muestra la historia. Aunque hay una diferencia en la retirada, como era de esperar, no es significativa. Y la diferencia de recordación desaparece reuniendo solo 5 vectores más. Todo esto con fusiones de segmentos más rápidas y 1/4 de la memoria de vectores .
Conclusión
Lucene ofrece una solución única a un problema difícil. No se requiere ningún paso de "entrenamiento" ni de "optimización" para la cuantización. En Lucene, simplemente funcionará. No hay que preocupar por tener que "reentrenar" tu índice vectorial si tus datos se desplazan. Lucene detectará cambios significativos y se encargará de esto automáticamente durante la vida útil de tus datos. ¡Espero con ganas que lleguemos a incorporar esta capacidad a Elasticsearch!
Preguntas frecuentes
¿Qué es la cuantización escalar?
La cuantización escalar es una técnica de compresión con pérdida. Unas matemáticas sencillas ofrecen un ahorro significativo de espacio con poco impacto en la memoria.
Contenido relacionado

10 de abril de 2026
Agrupación no supervisada de documentos con Elasticsearch + incrustaciones de Jina
Un enfoque práctico y reproducible para la agrupación no supervisada de documentos con Elasticsearch y embeddings de Jina.

2 de enero de 2026
Automatización del análisis de logs en Streams con ML.
Descubre cómo un enfoque híbrido de ML logró un 94 % de precisión en el análisis de logs y un 91 % en la partición de logs mediante experimentos de automatización con huellas digitales de formato de registro en Streams.

3 de septiembre de 2025
Filtrado de búsqueda vectorial: Mantenerlo relevante
Realizar una búsqueda vectorial para encontrar los resultados más similares a una consulta no es suficiente. A menudo se necesita filtrar para reducir los resultados de búsqueda. Este artículo explica cómo funciona el filtrado para la búsqueda vectorial en Elasticsearch y Apache Lucene.

3 de abril de 2025
Generación de filtros y facetas usando ML
Explorando los pros y contras de automatizar la creación de filtros y facetas en una experiencia de búsqueda usando modelos de aprendizaje automático frente al enfoque tradicional codificado de forma dura.

7 de abril de 2025
Acelerar la fusión de gráficos HNSW
Explore el trabajo que estuvimos haciendo para reducir la sobrecarga de crear varios gráficos HNSW, en individuo reducir el costo de fusionar gráficos.