¿Quieres obtener la certificación de Elastic? ¡Descubre cuándo se realizará la próxima capacitación Elasticsearch Engineer! Puedes iniciar una prueba gratuita en el cloud o prueba Elastic en tu máquina local ahora mismo.
Prepárate:
Este blog en individuo es diferente de lo habitual. No es una explicación de una nueva función ni un tutorial. Esto trata sobre una sola línea de código que tardó tres días en escribir. Estaremos corrigiendo una posible corrupción en el índice Apache Lucene. Algunas conclusiones que espero que tengáis:
- Todas las pruebas poco estables son repetibles, si se tiene tiempo suficiente y las herramientas adecuadas
- Muchas capas de pruebas son clave para sistemas robustos. Sin embargo, niveles más altos de pruebas se vuelven cada vez más difíciles de depurar y reproducir.
- Sleep es un excelente depurador
Cómo prueba Elasticsearch
En Elastic, tenemos una gran cantidad de pruebas que se ejecutan contra la base de código de Elasticsearch. Algunas son pruebas funcionales simples y enfocadas, otras son pruebas de integración de "happy path" de un solo nodo, y otras intentan romper el clúster para cerciorar de que todo funcione correctamente en un caso de fallo. Cuando una prueba falla continuamente, un ingeniero o automatización de herramientas crea un problema en github y lo señala para que un equipo en individuo lo investigue. Este error en individuo fue descubierto mediante una prueba del último tipo. Estas pruebas son complicadas, a veces solo repetibles tras muchas pruebas.
¿Qué es realmente esta prueba?
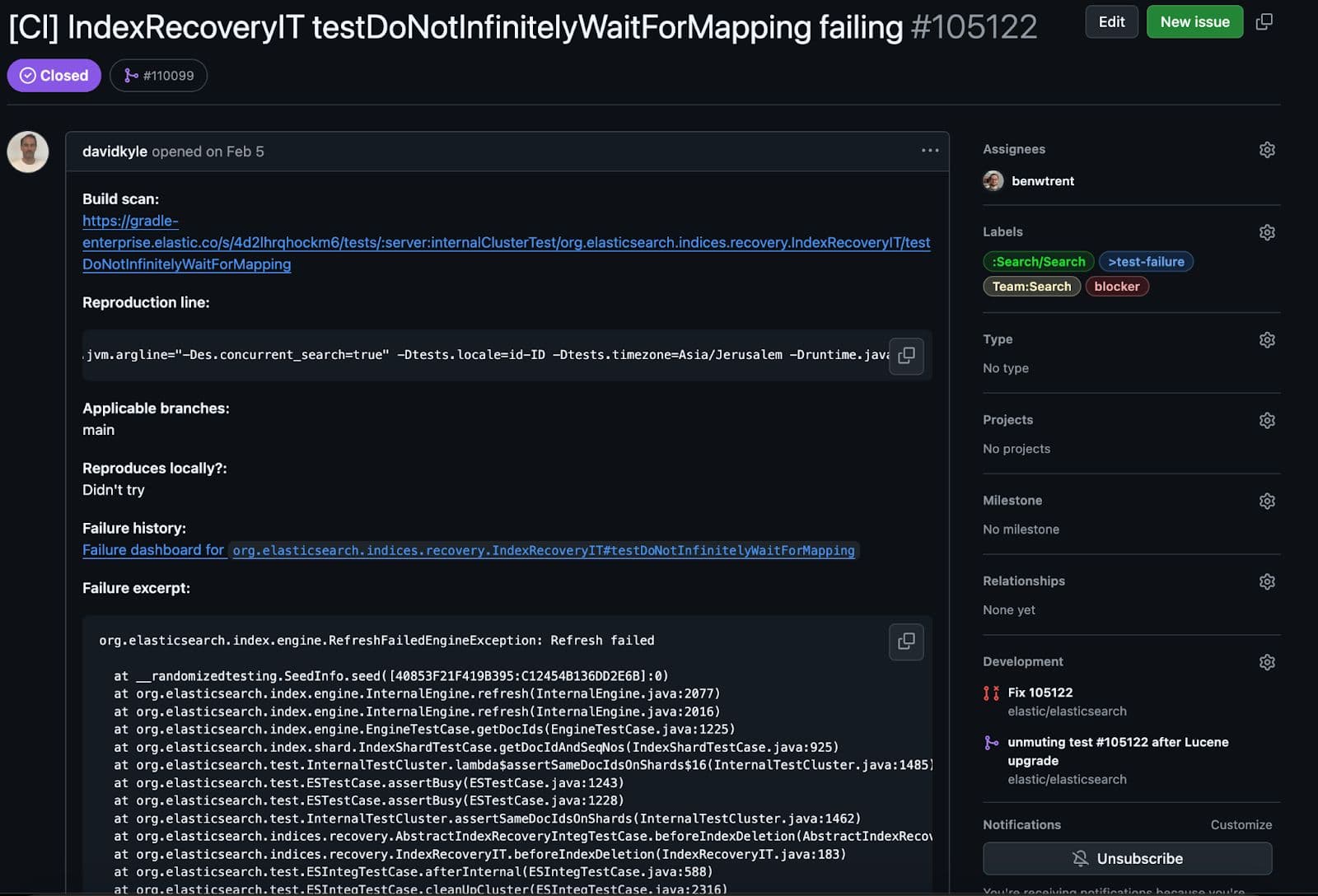
Esta prueba en individua es interesante. Creará un mapeo particular y lo aplicará a un fragmento primario. Luego, al intentar crear una réplica. La diferencia clave es que cuando la réplica intenta analizar el documento, la prueba inyecta una excepción, lo que provoca que la recuperación falle de una manera sorprendente (pero esperada).
Sin embargo, todo funcionaba como se esperaba, con un inconveniente importante. Durante la limpieza de la prueba, validamos la consistencia, y ahí esta prueba se topó con un problema.
Esta prueba estaba fallando de la manera esperada. Durante la comprobación de consistencia verificábamos que todos los archivos replicados y los principales de segmentos de Lucene fueran consistentes. Es decir, no corrompido y completamente replicado. Tener datos parciales o corruptos es mucho peor que que algo falle por completo. Aquí está la pista aterradora y abreviada de la pila del fallo.
De alguna manera, durante el fallo de replicación forzada, ¡el fragmento replicado acabó corrompido! Permítanme explicar la parte clave del error en un lenguaje sencillo.
Lucene es una arquitectura basada en segmentos, lo que significa que cada segmento conoce y gestiona sus propios archivos de solo lectura. Este segmento en individuo estaba siendo validado a través de sus SegmentCoreReaders para cerciorar que todo estuviera en orden. Cada lector central almacena metadatos que indican qué tipos de campos y archivos existen para un segmento determinado. Sin embargo, al validar el Lucene90PointsFormat, faltaban ciertos archivos esperados. Con los segmentos _0.cfs archivo esperábamos un archivo de formato puntual llamado kdi. cfs significa "sistema de archivos compuesto" en el que Lucene a veces combina todos los tipos de campos y todos los archivos diminutos en un único archivo más grande para una replicación y uso de recursos más eficiente. De hecho, faltaban las tres extensiones de archivo de puntos: kdd, kdiy kdm . ¿Cómo podríamos llegar al punto en que un segmento de Lucene espera encontrar un archivo puntual pero falta?! ¡Parece un error de corrupción aterrador!
El primer paso para cada corrección de error es replicarlo
Replicar el fallo de este error en individuo fue extremadamente doloroso. Aunque aprovechamos las pruebas de valor aleatorizadas en Elasticsearch, nos cercioramos de proporcionar a cada fallo una semilla aleatoria (esperemos) reproducible para que todos puedan ser investigados. Bueno, esto funciona muy bien para todos los fallos excepto los causados por una condición de carrera.
Por mucho que lo intentara, la semilla en individua nunca repetía el fallo localmente. Pero hay formas de poner a prueba las pruebas y avanzar hacia un fracaso más repetible.
Nuestro conjunto de pruebas en individua permite que una prueba se ejecute más de una vez en el mismo comando mediante el parámetro -Dtests.iters . Pero esto no era suficiente, necesitaba cerciorarme de que los hilos de ejecución estuvieran cambiando y así aumentaran la probabilidad de que ocurriera esta condición de carrera. Otro problema era que la prueba tardaba tanto en ejecutar que el corredor de pruebas se apagaba. Al final, usé el siguiente pesadilla para ejecutar la prueba de forma repetida:
Entra el estrés. Esto te permite iniciar rápidamente un proceso que solo consumirá núcleos de CPU durante la comida. Spamear stress-ng aleatoriamente mientras ejecutaba varias iteraciones de la prueba fallida finalmente me permitió replicar el fallo. Un paso más. Para estresar el sistema, simplemente abre otra ventana de terminal y ejecuta:
Revelando el error
Ahora que el fallo de la prueba que revela el error es mayormente repetible, es hora de intentar encontrar la causa. Lo que hace extraño este test en individuo es que Lucene lanza porque espera valores de puntos, pero no se agregan directamente por la prueba. Solo valores de texto. Esto me llevó a considerar los cambios recientes en nuestros optimistas campos de control de concurrencia : _seq_no y _primary_term. Ambos están indexados como puntos y existen en todos los documentos de Elasticsearch.
¡De hecho, un commit cambió nuestro _seq_no mapeador! ¡SÍ! ¡Esta tiene que ser la causa! Pero mi entusiasmo duró poco. Esto solo cambió el orden en que se agregaron los campos al documento. Antes de este cambio, _seq_no campos se agregaron al último en el documento. Después, ellos fueron agregados primero. No hay manera de que el orden de agregar campos a un documento Lucene causara este fallo...
Sí, cambiar el orden en que se agregaron los campos causó el fallo. ¡Esto fue sorprendente y resultó ser un error en Lucene mismo! Cambiar el orden de los campos analizados no debería modificar el comportamiento de analizar un documento.
El bicho en Lucene
De hecho, el insecto en Lucene se centró en las siguientes condiciones:
- Indexación de un campo de valor de puntos (por ejemplo,
_seq_no) - Intentando indexar un lanzamiento de campo de texto durante el análisis
- En este estado extraño, abrimos un Lector en Tiempo Casi Real del autor que experimenta la excepción de análisis de índice de texto
Pero por muchas formas que lo intentara, no pude replicarlo completamente. Agregué directamente puntos de pausa para depurar en toda la base de código de Lucene. Intenté abrir lectores al azar durante el camino de excepción. Incluso imprimí megabytes y megabytes de registros intentando encontrar la ruta exacta por donde ocurrió este fallo. Simplemente no pude hacerlo. Pasé todo un día luchando y perdiendo.
Luego me dormí.
Al día siguiente volví a leer el rastro original de la pila y descubrí la siguiente línea:
En todos mis intentos de recreación, nunca establecí específicamente la política de fusión de retención. La Política de Fusión SoftDeletesRetentionMergePolicy la emplea Elasticsearch para que podamos replicar con precisión las eliminaciones en réplicas y cerciorarnos de que todos nuestros controles de concurrencia se encarguen de cuándo se eliminan realmente los documentos. Por lo demás, Lucene tiene el control total y los eliminará en cualquier fusión.
Una vez que agregué esta política y replicé los pasos más básicos mencionados anteriormente, el fallo se replicó inmediatamente.
Nunca estuve más feliz de abrir un micrófono en Lucene.
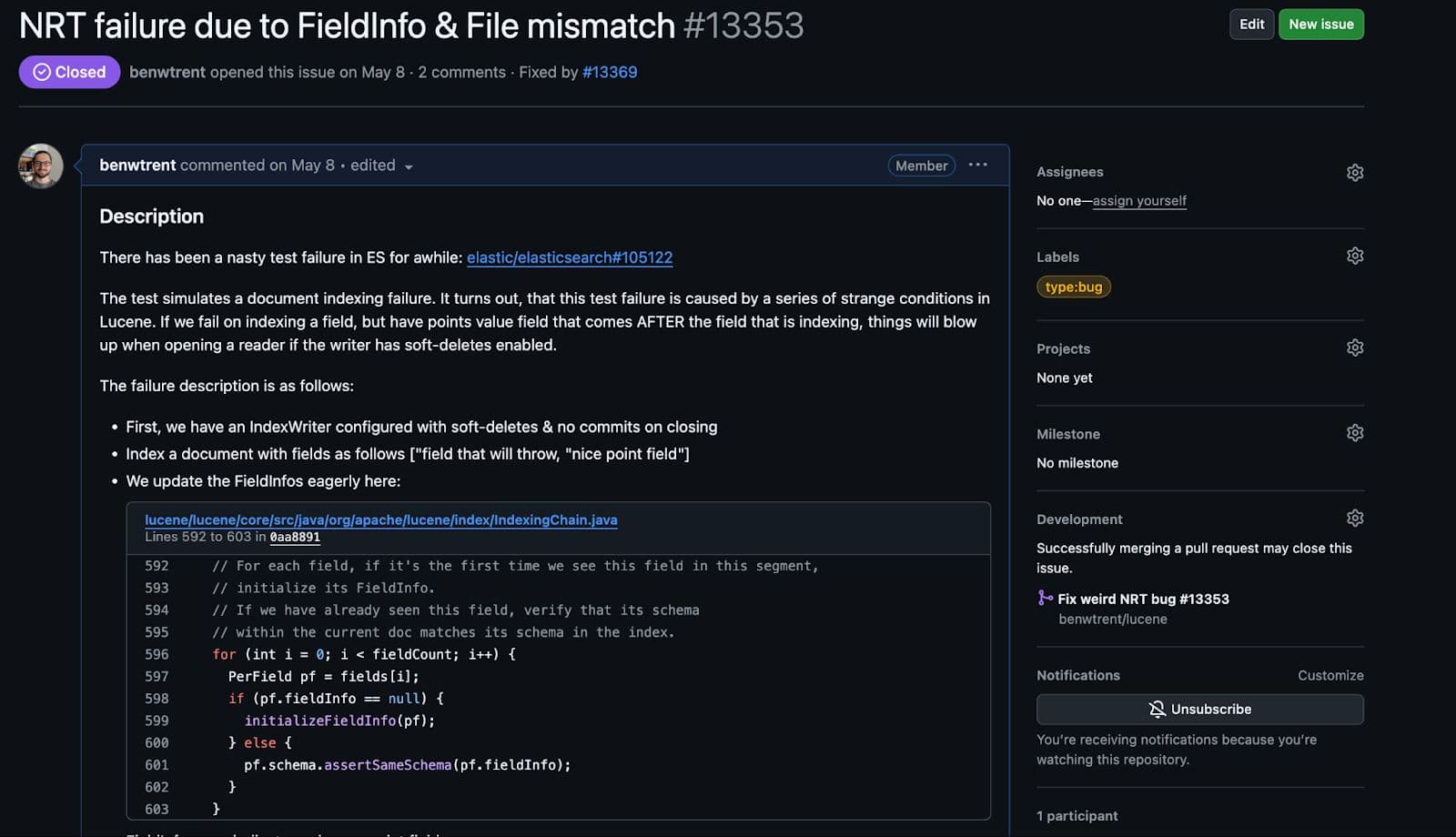
Aunque se presentaba como una condición de raza en Elasticsearch, era sencillo escribir una prueba repetidamente suspendida en Lucene una vez cumplidas todas las condiciones.
Al final, como todos los buenos errores, se solucionó con solo una línea de código. Varios días de trabajo, solo por una línea de código.
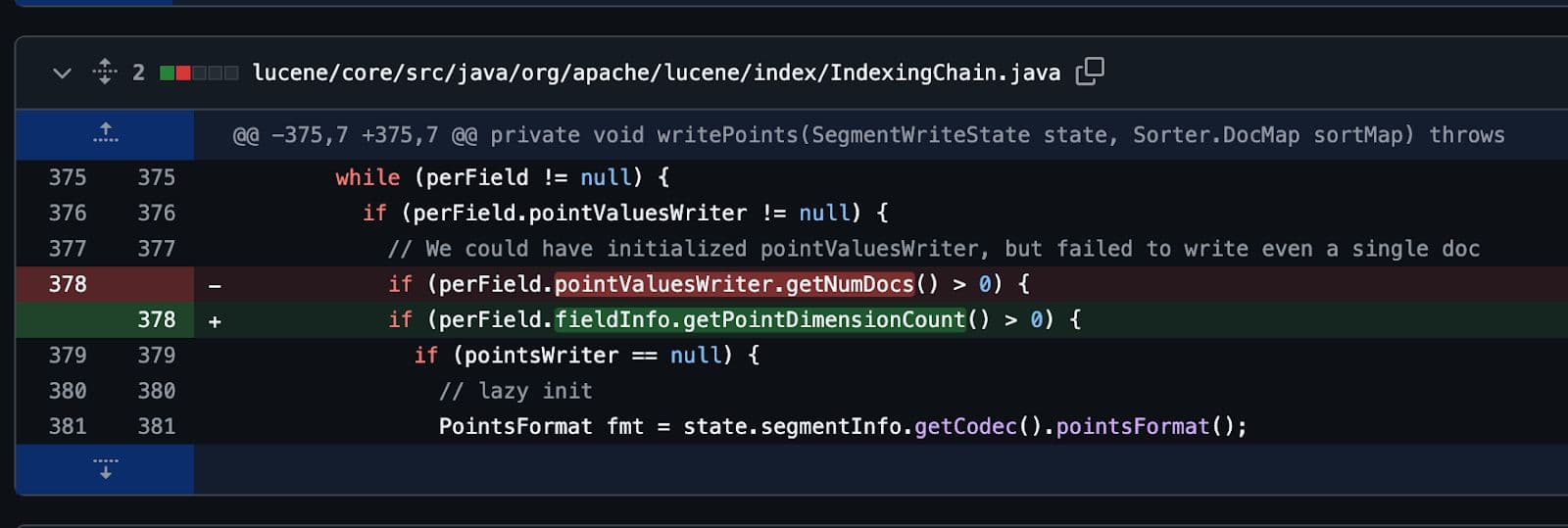
Pero valió la pena.
No es el final
¡Espero que disfrutaste de esta aventura salvaje conmigo! Escribir software, especialmente software tan empleado y complejo como Elasticsearch y Apache Lucene, es gratificante. Sin embargo, a veces resulta excepcionalmente frustrante. Me encanta y odio el software a la vez. ¡La corrección de errores nunca termina!
Contenido relacionado

3 de septiembre de 2025
Filtrado de búsqueda vectorial: Mantenerlo relevante
Realizar una búsqueda vectorial para encontrar los resultados más similares a una consulta no es suficiente. A menudo se necesita filtrar para reducir los resultados de búsqueda. Este artículo explica cómo funciona el filtrado para la búsqueda vectorial en Elasticsearch y Apache Lucene.

7 de abril de 2025
Acelerar la fusión de gráficos HNSW
Explore el trabajo que estuvimos haciendo para reducir la sobrecarga de crear varios gráficos HNSW, en individuo reducir el costo de fusionar gráficos.

7 de febrero de 2025
Errores de concurrencia en Lucene: Cómo corregir fallos de concurrencia optimistas
Gracias a Fray, un marco determinista de pruebas de concurrencia del laboratorio PASTA de CMU, localizamos un bug complicado de Lucene y lo eliminamos

3 de enero de 2025
Lucene Wrapped 2024
2024 fue otro año importante para Apache Lucene. En este blog, exploraremos los puntos clave más destacados.

26 de junio de 2024
Elasticsearch vs. OpenSearch: Comparación del rendimiento de búsqueda vectorial
Elasticsearch es de 2 a 12 veces más rápido que OpenSearch para la búsqueda vectorial