Desde la búsqueda vectorial hasta las potentes API REST, Elasticsearch ofrece a los desarrolladores el conjunto de herramientas de búsqueda más completo. Explora nuestros cuadernos de muestra en el repositorio de Elasticsearch Labs para probar algo nuevo. También puedes iniciar tu prueba gratuita o ejecutar Elasticsearch localmente hoy mismo.
En este artículo, demostraremos cómo implementar una búsqueda híbrida que combine los resultados de la búsqueda en texto completo con la búsqueda vectorial. Al unificar estos dos enfoques, la búsqueda híbrida mejora la amplitud de resultados, aprovechando lo mejor de ambas estrategias de búsqueda.
Además de integrar la búsqueda híbrida, demostraremos cómo agregar funciones que hagan que tu solución de búsqueda sea aún más robusta. Estas incluyen facetados y promociones personalizadas de productos. Además, te mostraremos cómo capturar las interacciones del usuario y generar información valiosa empleando la herramienta de Análisis de Comportamiento de Elastic.
En esta implementación, verás cómo construir tanto la interfaz que permite a los usuarios ver e interactuar con los resultados de búsqueda como la API responsable de devolver la información. Para acceder a los repositorios con el código fuente, los enlaces se proporcionan a continuación:
- https://github.com/elastic/elasticsearch-labs/tree/main/supporting-blog-content/hybrid-search-for-an-e-commerce-product-catalogue/product-store-search
- https://github.com/elastic/elasticsearch-labs/tree/main/supporting-blog-content/hybrid-search-for-an-e-commerce-product-catalogue/app-product-store
Dividimos esta guía en varios pasos, desde la creación del índice hasta la implementación de funciones avanzadas como el facetado y la personalización de resultados. Al final, tendrás una solución de búsqueda robusta lista para usar en un escenario de comercio electrónico.
Configuración de entornos para búsqueda híbrida de comercio electrónico
Antes de comenzar la implementación, necesitamos configurar el entorno. Puedes elegir usar un servicio en Elastic Cloud o una solución contenedora para gestionar Elasticsearch. Si eliges contenerización, en este repositorio puedes encontrar una configuración mediante Docker Compose: docker-compose.yml.
Creación de índices e ingesta de catálogos de productos
El índice se creará a partir de un catálogo de productos cosméticos, que incluye campos como nombre, descripción, foto, categoría y etiquetas. Los campos usados para la búsqueda en texto completo, como "nombre" y "descripción", se mapearán como text, mientras que los campos usados para agregaciones, como "categoría" y "marca", se mapearán como keyword para permitir el facetado.
El campo "descripción" se empleará para la búsqueda vectorial, ya que proporciona más contexto sobre los productos. Este campo se definirá como dense_vector, almacenar la representación vectorial de la descripción.
El mapeo del índice será el siguiente:
El script para crear el índice se puede encontrar aquí.
Generación de incrustación
Para vectorizar las descripciones de productos, empleamos el modelo all-MiniLM-L6-v2. En este caso, la aplicación es responsable de generar las incrustaciones antes de indexar. Otra opción sería importar el modelo al clúster de Elasticsearch, pero para este entorno local, elegimos realizar la vectorización directamente dentro de la aplicación.
Empleamos el conjunto de datos cosméticos disponible en Kaggle para poblar el índice y, para mejorar la eficiencia de la ingesta de datos, empleamos procesamiento por lotes. Durante esta misma etapa de ingestión, generaremos las incrustaciones para el campo "descripción" e indexarémolas en el nuevo campo "description_embeddings".
El proceso completo de ingesta de datos puede seguir y ejecutar directamente a través del Jupyter Notebook disponible en el repositorio. El cuaderno ofrece una guía paso a paso sobre cómo se leen, procesan e indexan los datos en Elasticsearch, permitiendo una fácil replicación y experimentación.
Puedes acceder al cuaderno en el siguiente enlace: Cuaderno de Ingestión.
Implementación de búsqueda híbrida
Ahora, implementemos la búsqueda híbrida. Para la búsqueda basada en palabras clave, usamos la consulta multi_match , dirigida a los campos "nombre", "categoría" y "descripción". Esto garantiza que se recuperen los documentos que contienen el término de búsqueda en cualquiera de estos campos.
Para la búsqueda vectorial, usamos la consulta KNN. El término de búsqueda debe vectorizarse antes de ejecutar la consulta, y esto se hace usando el método que vectoriza el término de entrada. Ten en cuenta que el mismo modelo usado durante la ingestión también se emplea para el término de búsqueda.
La combinación de ambas búsquedas se realiza mediante el algoritmo de Fusión de Rango Recíproco (RRF), que fusiona los resultados de ambas consultas y aumenta la precisión de la búsqueda al reducir el ruido. RRF permite que tanto las búsquedas basadas en palabras clave como las vectoriales trabajen conjuntamente, mejorando la comprensión de la consulta del usuario.
Comparando resultados: búsqueda por palabras clave vs. búsqueda híbrida
Ahora, comparemos los resultados de una búsqueda tradicional por palabras clave con la búsqueda híbrida. Al buscar "base para piel seca" usando la búsqueda por palabras clave, obtenemos los siguientes resultados:

- Maquillaje Revlon ColorStay para piel normal / secaDescripción: Revlon ColorStay Makeup ofrece una cobertura duradera con una fórmula ligera que no se desvanece, ni se desvanece. Con Time Release \nTechnology, esta fórmula sin aceites y con equilibrio de humedad está especialmente formulada para piel normal o seca para proporcionar hidratación continua. Características: El maquillaje resulta cómodo y se usa hasta 24 horas\nCobertura media a total\nDisponible en una gama de tonos preciosos
- Maybelline Dream Smooth Mousse BaseDescripción: Por qué te encantaráLa base única batida con crema ofrece una perfección 100% suave para bebés.\n\nPiel Se ve y se siente hidratado durante 14 horas - nunca áspero ni seco\tLa fórmula ligera ofrece una cobertura perfectamente hidratante\�Se difumina perfectamente y se siente fresca todo el día\tSin aceite, sin fragancia, probado por dermatólogos, probado por alergias, no comedogénico \u2019 no obstruirá los poros.\nSeguro Para piel sensible.
Análisis: Al buscar "base para piel seca", los resultados se obtuvieron mediante la coincidencia exacta entre las palabras clave de búsqueda y los títulos y descripciones de los productos. Sin embargo, este partido no siempre refleja la mejor elección. Por ejemplo, el maquillaje Revlon ColorStay para piel normal / seca es una buena opción, ya que está formulado específicamente para piel seca. Aunque no contiene aceite, su fórmula está diseñada para proporcionar hidratación continua. En cambio, también recibimos la Maybelline Dream Smooth Mousse Foundation, que, aunque sin aceite y mencionando hidratación, suele recomendar más para piel grasa o mixta, ya que los productos sin aceite tienden a centrar en controlar el sebo en lugar de proporcionar la hidratación extra necesaria para la piel seca. Esto pone de manifiesto la limitación de las búsquedas basadas en palabras clave, que pueden devolver productos que no satisfacen completamente las necesidades específicas de las personas con piel seca.
Ahora, al realizar la misma búsqueda usando el enfoque híbrido:

- CoverGirl Outlast Stay Luminous Foundation Creamy Natural (820):D escription: CoverGirl Outlast Stay Luminous Foundation es perfecta para lograr un acabado luminoso y un brillo sutil. Es sin aceites, con una fórmula no grasienta que da a tu piel una luminosidad natural que dura todo el día. Esta base de maquillaje durante todo el día hidrata la piel y proporciona una cobertura impecable.
Análisis: Este producto es una combinación relevante porque enfatiza la hidratación, algo fundamental para usuarios con piel seca. Los términos "hidrata la piel" y "acabado húmedo" coinciden con la intención del usuario de encontrar una base para piel seca. La búsqueda vectorial probablemente entendió el concepto de hidratación y lo relacionó con la necesidad de una base que trate la piel seca. - Maquillaje Revlon ColorStay para piel normal / seca: Descripción: El maquillaje Revlon ColorStay ofrece una cobertura duradera con una fórmula ligera que no se empacha, no se desvanece ni se desprende de la piel. Con la Tecnología de Liberación Prolongada, esta fórmula sin aceites y equilibrada por la humedad está especialmente formulada para pieles normales o secas para proporcionar hidratación continua.
Análisis: Este producto responde directamente a las necesidades de los usuarios con piel seca, mencionando explícitamente que está formulado para piel normal o seca. La "fórmula de equilibrio de humedad" y la hidratación continua son ideales para quien busca una base adaptada a la piel seca. La búsqueda vectorial recuperó con éxito este resultado, no solo por la coincidencia de palabras clave, sino también por el enfoque en la hidratación y la mención específica de la piel seca como grupo objetivo. - Base de SérumDescripción: Las bases sérum son formulaciones ligeras de cobertura media disponibles en una amplia gama de tonos en 21 tonos. Estas bases ofrecen una cobertura moderada que parece natural y con una sensación de sérum muy ligera. Tienen una viscosidad muy baja y se dispensan con la bomba suministrada o con el gotero de vidrio opcional, disponible para su compra por separado si se prefiere.
Análisis: En este caso, la descripción enfatiza una base sérum ligera con un toque natural, que se adapta a las necesidades de las personas con piel seca, ya que suelen buscar productos suaves, hidratantes y que ofrezcan un acabado no empalagoso. La búsqueda vectorial probablemente captó el contexto más amplio de la ligera y la cobertura natural y la textura similar al sérum, que se asocia con la retención de humedad y una aplicación cómoda, lo que la hace relevante para piel seca, aunque el término "piel seca" no se mencione explícitamente.
Implementación de facetas
Los aspectos son esenciales para refinar y filtrar los resultados de búsqueda de forma eficiente, proporcionando a los usuarios una navegación más enfocada, especialmente en escenarios con una gran variedad de productos, como el comercio electrónico. Permiten a los usuarios ajustar los resultados según atributos como categoría, marca o precio, haciendo la búsqueda más precisa. Para implementar esta función, empleamos agregaciones de términos en los campos category y brand , que se definieron como keyword durante la fase de creación del índice.
El código completo de la implementación se puede encontrar aquí.
A continuación se vean los resultados de la búsqueda de "base para piel seca":
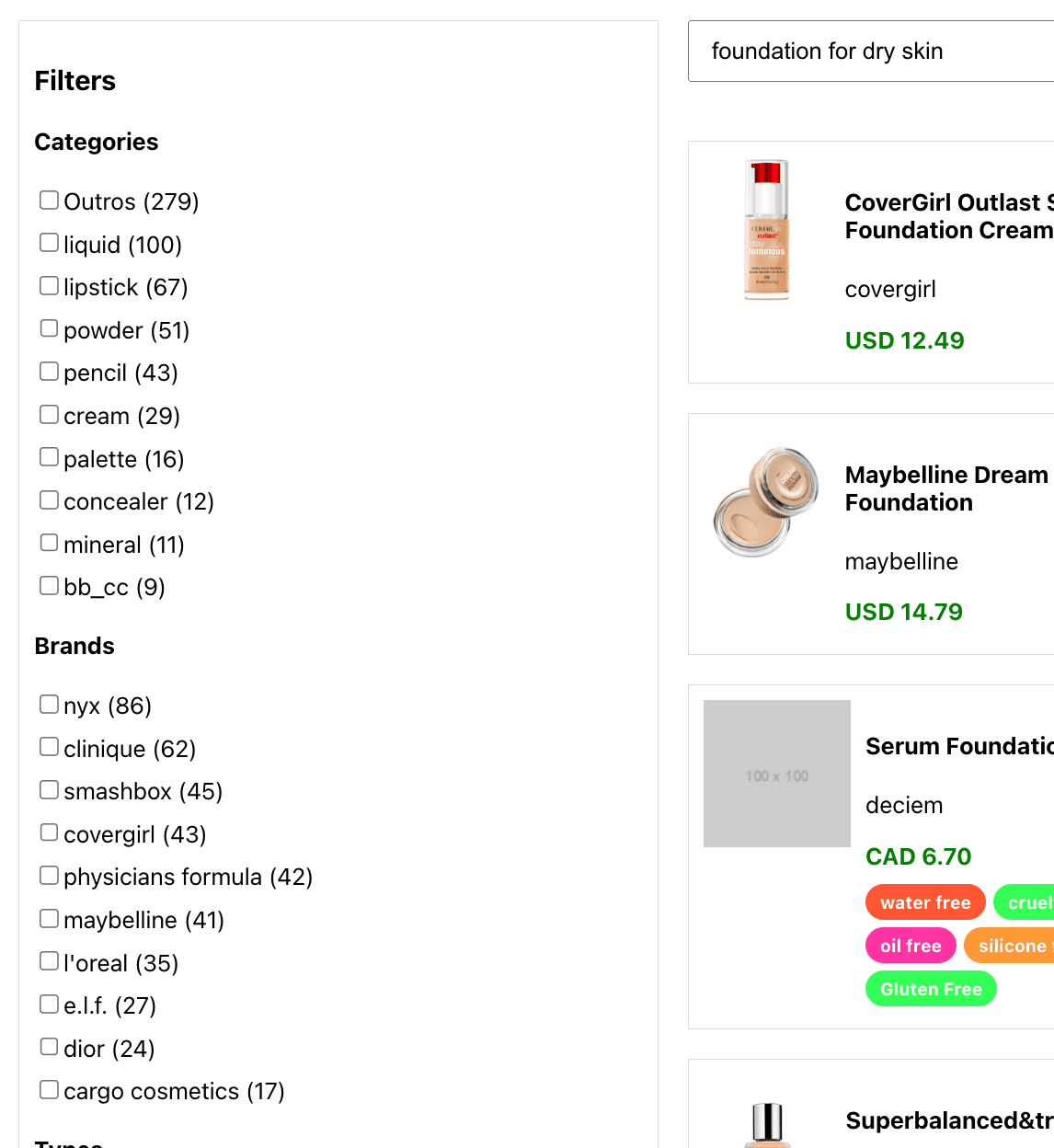
Personalización de resultados: consultas fijadas
En algunos casos, puede ser beneficioso promocionar ciertos productos en los resultados de búsqueda. Para esto, usamos Consultas Fijadas, que permiten que productos específicos aparezcan en la parte superior de los resultados. A continuación, realizaremos una búsqueda del término "Fundación" sin promocionar ningún producto:

En nuestro ejemplo, podemos promocionar productos que lleven la etiqueta "Sin gluten". Al emplear los identificadores de producto, nos cercioramos de que se prioricen en los resultados de búsqueda. En concreto, promocionaremos los siguientes productos: Serum Foundation (ID: 1043), Coverage Foundation (ID: 1042) y Realist Invisible Setting Powder (ID: 1039).
Empleamos identificadores de producto específicos para cerciorarnos de que se prioricen en los resultados de la consulta. La estructura de la consulta incluye una lista de IDs de producto que deben estar "fijados" en la parte superior (en este caso, IDs 1043, 1042 y 1039), mientras que los resultados restantes siguen el flujo orgánico de la búsqueda, usando una combinación de condiciones como la consulta de texto en los campos "nombre", "categoría", y "descripción". De este modo, es posible promocionar los elementos de forma controlada, cerciorando su visibilidad, mientras que el resto de la búsqueda se basa en la relevancia habitual.
A continuación, puedes ver el resultado de la ejecución de la consulta con los productos promovidos:

El código completo de la consulta se puede encontrar aquí.
Análisis del comportamiento de búsqueda con análisis conductual
Hasta ahora, ya agregamos funcionalidades para mejorar la relevancia de los resultados de búsqueda y facilitar la descubribilidad del producto. Ahora, finalizaremos nuestra solución de búsqueda incluyendo una función que nos ayudará a analizar el comportamiento de búsqueda de los usuarios, identificando patrones como consultas con o sin resultados y clics en los resultados. Para ello, emplearemos la función de Análisis de Comportamiento proporcionada por Elastic. Con él, en solo unos pocos pasos, podemos monitorizar y analizar el comportamiento de búsqueda de los usuarios, obteniendo información valiosa para optimizar la experiencia de búsqueda.
Creación de la colección de análisis de comportamiento
Nuestra primera acción será crear una colección que será responsable de recibir todos los eventos de análisis de conducta. Para crear la colección, accede a la interfaz Kibana en Search > Behavioral Analytics. En el ejemplo siguiente, creamos la colección llamada tracking-search.

Integración del análisis de comportamiento en la interfaz
Nuestra aplicación front-end fue desarrollada en JavaScript y, para integrar Behavioral Analytics, seguiremos los pasos descritos en la documentación oficial de Elastic para instalar el Behavioral Analytics JavaScript Tracker.
Implementación del rastreador JavaScript
Ahora, importaremos el cliente tracker a nuestra aplicación y usaremos los métodos trackPageView, trackSearchy trackSearchClick para capturar las interacciones del usuario.
Aviso legal: Aunque estamos empleando una herramienta para recopilar datos de interacción de usuarios, es esencial garantizar el cumplimiento del RGPD. Esto significa informar claramente a los usuarios sobre qué datos se están recopilando, cómo se emplearán y ofrecer la opción de optar por no participar en el seguimiento. Además, debemos implementar medidas de seguridad estables para proteger la información recopilada y respetar los derechos de los usuarios, como el acceso y la eliminación de datos, cerciorando que todos los pasos cumplan con los principios del RGPD.
Paso 1: Creación de la instancia del rastreador
Primero, crearemos la instancia tracker que monitorizará las interacciones. En esta configuración, definimos el punto final objetivo, el nombre de la colección y la clave API:
Paso 2: Captura de vistas de página
Para registrar las visualizaciones de página, podemos configurar el evento trackPageView :
Para más detalles sobre el evento trackPageView , puedes consultar esta documentación.
Paso 3: Captura de consultas de búsqueda
Para monitorizar las acciones de búsqueda de los usuarios, emplearemos el método trackSearch :
Aquí estamos recopilando el término de búsqueda y los resultados de la búsqueda.
Paso 4: Seguimiento de clics en los resultados de búsqueda
Por último, para capturar clics en los resultados de búsqueda, emplearemos el método trackSearchClick :
Recopilamos información sobre el ID del documento al que se hace clic, así como el término de búsqueda y los resultados.
Análisis de los datos en Kibana
Ahora que se están capturando eventos de interacción de usuarios, podemos obtener datos valiosos sobre las acciones de búsqueda. Kibana emplea la herramienta de Análisis del Comportamiento para visualizar y analizar estos datos conductuales. Para ver los resultados, simplemente navega a Búsqueda > Análisis de Comportamiento > Mi Colección, donde se mostrará un resumen de los eventos capturados.
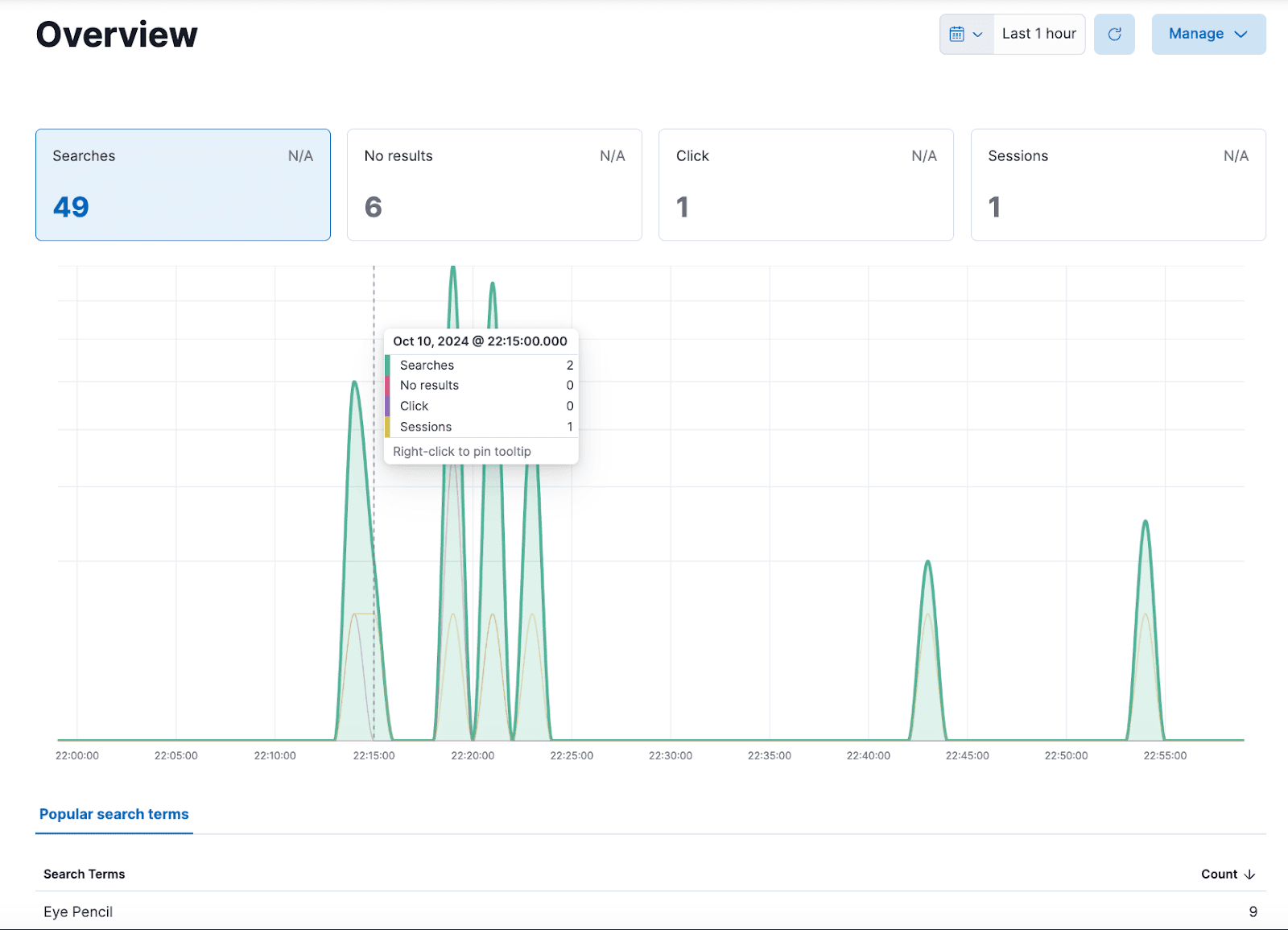
En esta visión general, obtenemos una visión general de los eventos capturados para cada acción integrada en nuestra interfaz. A partir de esta información, podemos obtener información valiosa sobre el comportamiento de búsqueda de los usuarios. Sin embargo, si quieres crear paneles personalizados con métricas más relevantes para tu escenario específico, Kibana ofrece herramientas poderosas para crear paneles, permitiéndote crear diversas visualizaciones de tus métricas.
A continuación, creé algunas visualizaciones y gráficos para monitorizar, por ejemplo, los términos más buscados a lo largo del tiempo, consultas que no devolvieron resultados, una nube de palabras que resalta los términos más buscados y, finalmente, una visualización geográfica para identificar de dónde proviene el acceso a las búsquedas.

Conclusión
En este artículo, implementamos una solución de búsqueda híbrida que combina búsqueda por palabras clave y vectorial, ofreciendo resultados más precisos y relevantes para los usuarios. También exploramos cómo emplear funciones adicionales, como facetas y personalización de resultados con Consultas Fijadas, para crear una experiencia de búsqueda más completa y eficiente.
Además, integramos el Análisis Conductual de Elastic para capturar y analizar el comportamiento del usuario durante sus interacciones con el motor de búsqueda. Empleando métodos como trackPageView, trackSearchy trackSearchClick, pudimos monitorizar consultas de búsqueda, clics en los resultados y vistas de página, generando información valiosa sobre el comportamiento de búsqueda.
Referencias
Conjunto de datos
https://www.kaggle.com/datasets/shivd24coder/cosmetic-brand-products-dataset
Transformador
https://huggingface.co/sentence-transformers/all-minilm-l6-v2
Fusión recíproca de rangos
https://www.elastic.co/guide/en/elasticsearch/reference/current/rrf.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/retriever.html#rrf-retriever
Consulta Knn
https://www.elastic.co/guide/en/elasticsearch/reference/current/knn-search.html
Consulta fijada
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-pinned-query.html
APIs de Análisis de Comportamiento
https://www.elastic.co/guide/en/elasticsearch/reference/current/behavioral-analytics-apis.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/behavioral-analytics-overview.html
Contenido relacionado

23 de abril de 2026
Cómo creamos Elasticsearch simdvec para hacer una de las búsquedas vectoriales más rápidas del mundo
Cómo construimos Elasticsearch SIMDvec, la biblioteca del kernel SIMD ajustada a mano detrás de cada consulta de búsqueda vectorial en Elasticsearch.

4 de mayo de 2026
Cómo medir y mejorar la recuperación de búsqueda de Elasticsearch: de 0,43 a 0,75 con búsqueda híbrida
Aprende a medir y mejorar la recuperación de búsqueda en Elasticsearch combinando la búsqueda léxica BM25 con incrustaciones vectoriales de Jina AI, usando la API rank_eval para validar la mejora con cifras reales.

10 de abril de 2026
Agrupación no supervisada de documentos con Elasticsearch + incrustaciones de Jina
Un enfoque práctico y reproducible para la agrupación no supervisada de documentos con Elasticsearch y embeddings de Jina.

2 de abril de 2026
Cuando TSDS se une a ILM: diseñar flujos de datos temporales que no rechazan los datos tardíos
Cómo los límites de tiempo de TSDS interactúan con las fases de ILM; y cómo diseñar políticas que toleren métricas tardías.

1 de abril de 2026
LINQ a Elasticsearch ES|QL: escribir en C#, buscar en Elasticsearch
Explorar el nuevo proveedor de LINQ a Elasticsearch ES|QL en el cliente .NET de Elasticsearch, que te permite escribir código en C# que se traduce automáticamente en búsquedas ES|QL.