Get hands-on with Elasticsearch: Dive into our sample notebooks in the Elasticsearch Labs repo, start a free cloud trial, or try Elastic on your local machine now.
Elasticsearch Query Language (ES|QL) now has schema-on-read. Add one line: SET unmapped_fields="load", and every unmapped field in _source becomes queryable. No reindex. No pipeline change. Works retroactively against data you ingested months ago.
Add JSON_EXTRACT for surgical extraction from raw JSON strings: flattened fields, embedded payloads, OTel resource attributes (60+ semantic conventions that standard mappings don't index individually). Together, these turn schema from a gate into a spectrum: indexed fields for speed, _source fallback for everything else. See also our companion posts on ES|QL views and ES|QL subqueries.
The mapping cliff edge
Elasticsearch mappings define how fields are indexed. When a mapping is complete, queries are fast; they hit inverted indices, doc values, and all the performance structures Elasticsearch builds at index time. But when a field was never mapped (missed during onboarding, added by a new integration, or simply not anticipated), it's invisible. Queries that reference it fail. The traditional fix: Update the mapping, reindex the data. For a multi-terabyte index, that means hours of reprocessing and doubled storage during the reindex window.
ES|QL schema-on-read changes the contract. The mapping is no longer a cliff edge where "mapped" means queryable and "unmapped" means invisible. Instead, it's a spectrum:
- Mapped fields → fast path. Queries hit indexed structures. This is still the preferred mode for production workloads.
- Unmapped fields with
SET unmapped_fields="load"→ queryable from_sourceat query time. Slower than the indexed path (no inverted index to accelerate filters), but the data is accessible in seconds instead of not at all: immediately, retroactively, against historical indices.
You can discover and query first and then decide later whether a field is worth mapping for performance.
Unmapped field access: The strategic abstraction
SET directives are query-level settings that appear at the top of an ES|QL query, before the FROM clause. They configure how the query engine behaves for that specific query without affecting anything else. The unmapped_fields directive controls what happens when a query references a field that doesn't exist in the mapping.
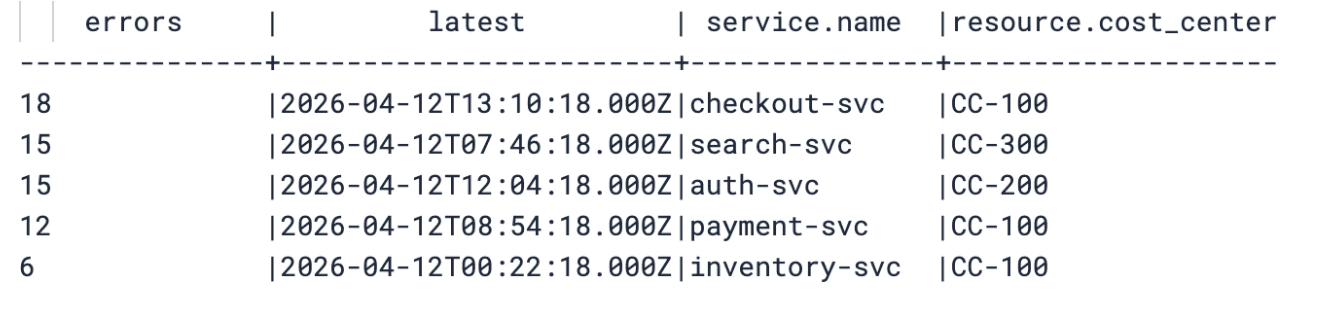
Consider an OTel logs index where resource.cost_center was never mapped. Without SET unmapped_fields, referencing it produces an error:

Add one line and the query works:
The field is loaded from _source at query time. No mapping change. No reindex. Works against data that was ingested weeks or months ago.
| Mode | Behavior | Use when |
|---|---|---|
| `default` | Unmapped fields are invisible; queries that reference them error (pre-9.4 behavior). | You want strict schema enforcement. |
| `nullify` | Unmapped fields appear as columns with `null` values. | You want the column shape without loading data, or you need compatibility with subqueries and views. |
| `load` | Unmapped fields are loaded from `_source` at query time. | You need to filter, aggregate, or inspect the actual values. |
nullify is useful when you want queries to succeed even if some indices in a wildcard pattern don't have a particular field mapped. load is the mode you reach for when you actually need the data.

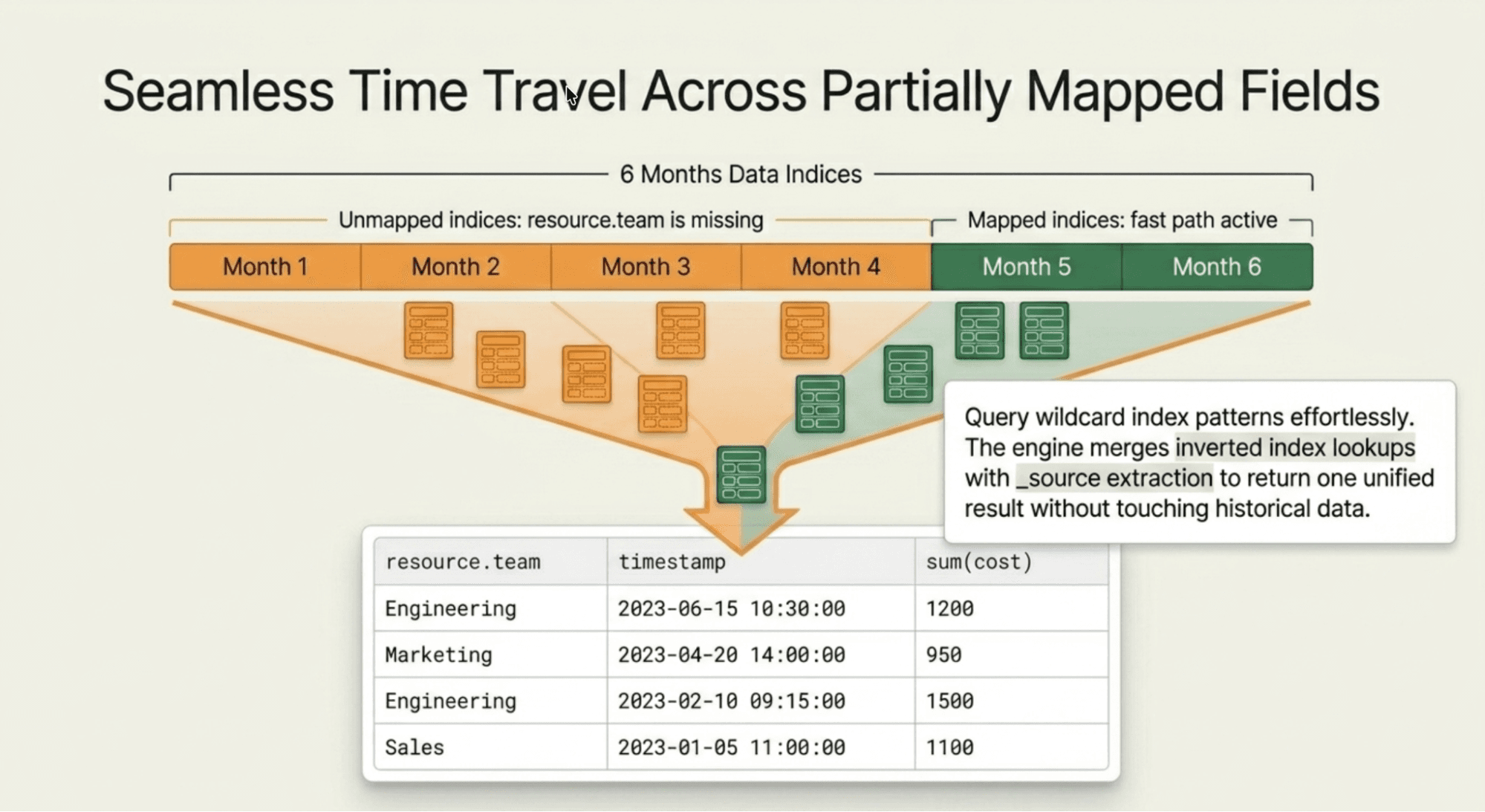
Partially mapped fields
The power of unmapped_fields really shows with wildcard index patterns where a field exists in some indices but not others. Suppose resource.team was mapped in recent indices but not in older ones:
For indices where resource.team is mapped, values come from the fast indexed path. For indices where it isn't, values are loaded from _source. The query returns a unified result across the entire time range; no reindexing of historical data required.
JSON_EXTRACT: The lower-level tool
SET unmapped_fields is the right answer for fields that exist in _source under predictable names. But some data requires more surgical extraction, reaching into a JSON string stored in a text field or navigating nested objects inside a flattened field type where dot notation can't reach subkeys.
JSON_EXTRACT is the lower-level escape hatch. It takes a source field and a JSON path expression and returns the value at that path:
Extracting from string fields
Payment services often store structured error details as a JSON string in a response body field. JSON_EXTRACT reaches into that string at query time:
No ingest pipeline needed to extract error_code from the response body. The schema can evolve without reindexing.

Extracting from _source: Flattened fields and OTel data
For fields mapped as flattened, such as resource.attributes in many OTel indices, which can contain 20–30 nested keys per document, the entire JSON object is stored as an opaque token. Elasticsearch indexes the leaf values as flat keywords for filtering, but doesn't decompose them into separate mapped fields, so dot notation has nothing to resolve against. JSON_EXTRACT on _source follows the actual nesting in the stored document:
Use dot notation for the nested structure and then bracket notation for leaf keys that contain dots (like service.version as a single key name). This is a common pattern for OpenTelemetry data.
What to use when
| Scenario | Tool | Why |
|---|---|---|
| Field was never mapped | `SET unmapped_fields="load"` | The strategic solution for schema evolution. One-line directive, works retroactively. |
| Need to extract a key from a raw JSON string | `JSON_EXTRACT` | Surgical extraction from string fields. Path notation gives precise control. |
| Field is inside a flattened type | `JSON_EXTRACT` on `_source` | Bridge solution. Native flattened field support in ES|QL is planned. |
| Query needs to work with subqueries or views | `SET unmapped_fields="nullify"` | `load` mode is incompatible with subqueries and views in the current release. `nullify` works everywhere. |
SET unmapped_fields is the abstraction most users should reach for first. JSON_EXTRACT is the tool for cases that need direct JSON manipulation or for data patterns like flattened fields that aren't natively handled yet.
How this compares
"Schema on read" is Splunk's founding narrative; the idea that you index everything as raw text and decide the schema at search time. ES|QL takes a fundamentally different position: You get both. Here's how that plays out in practice.
Splunk SPL extracts fields at search time using search commands like spath, rex, search-time field extractions, and calculated fields. The benefit is flexibility; you never need to declare a schema up front. The cost: field-value searches scan raw event data. Splunk's TSIDX files index metadata (host, source, sourcetype) and index-time fields, but user-defined search-time fields hit raw events on every query. A query that touches a billion events scans a billion events. Splunk compensates with summary indexing and data models, but those are manual, preconfigured accelerations that trade flexibility back for performance; the same trade-off Elasticsearch mappings make, just with extra steps. ES|QL's SET unmapped_fields gives you the same "query fields you never declared" flexibility, but mapped fields still hit Elasticsearch's indexed structures at full speed. You pay the _source scan cost only for the specific fields that aren't mapped, not for every field in the query.
Elasticsearch Query DSL has runtime fields and OpenSearch has derived fields — both extract from _source at query time without reindexing. But both require per-field configuration: Runtime fields need a Painless script and type declaration per field, either at the index mapping level or in each query; derived fields require index-level or cluster-level configuration. You have to know the field name and define the extraction logic before you can query it. SET unmapped_fields="load" is a per-query directive that skips all of that; one line, and every unmapped field in the index becomes queryable. No per-field definitions, no index settings changes, no scripts.
ClickHouse requires a strict schema for standard columns; adding one means ALTER TABLE. However, ClickHouse's JSON type (GA in 25.3) automatically creates typed dynamic subcolumns for every path encountered at insert time, with no per-field declaration needed. The limitation is retroactive access; data already ingested into a String column requires JSONExtract* functions for field access, similar to ES|QL's JSON_EXTRACT, and cannot be retroactively migrated to a JSON column without a data pipeline change. There's no equivalent to SET unmapped_fields that makes arbitrary historical fields queryable without touching the schema or re-ingesting.
| Capability | Splunk SPL | ES|QL | OpenSearch / Query DSL | ClickHouse |
|---|---|---|---|---|
| Schema model | Schema-on-read (extract at search time) | Both (indexed fast path + `_source` fallback) | Schema-on-write + per-field query-time extraction | Schema-on-write; JSON type auto-creates subcolumns |
| Unmapped field access | Always available (all fields extracted at search time) | `SET unmapped_fields="load"`; per-query, zero config | Runtime fields / derived fields; per-field config required | JSON type: automatic. String columns: `JSONExtract*` only |
| JSON extraction | `spath` | `JSON_EXTRACT` with JSONPath subset | Painless scripting | `JSONExtract*` functions |
| Performance on mapped fields | Full scan (no indexed structures) | Inverted index + doc values + columnar | Inverted index + doc values | Columnar + primary index |
| Retroactive access to old data | Yes (always raw) | Yes (via `_source`) | Yes (via runtime / derived fields, per-field setup) | No; string columns can't be migrated to JSON retroactively |
| Cost of flexibility | Every query pays the scan cost | Only unmapped fields pay the scan cost | Per-field Painless script or index-level config | Must choose JSON type at table creation time |
The key difference: Splunk makes you choose between flexibility and performance at the platform level. ES|QL lets you choose per field, per query. Mapped fields are fast. Unmapped fields are accessible. You don't have to pick one model for your entire dataset.
Current constraints
SET unmapped_fields="load" is incompatible with subqueries and views in the current release; use nullify mode instead when composing queries. See the SET documentation for details.
What's next
Schema-on-read is a strategy, not just two features. The direction is to make more data queryable at query time without requiring a perfect schema at ingest time:
- Native flattened field support is next; dot notation directly into flattened fields without the
JSON_EXTRACTon_sourceworkaround. This eliminates the most common reason users needJSON_EXTRACTtoday and is planned. - Lifting the
loadmode restriction for subqueries and views will let you combine schema-on-read with the composition primitives from our views and subqueries posts.
The long-term goal: SET unmapped_fields becomes the primary way users handle schema evolution, with JSON_EXTRACT reserved for truly surgical JSON manipulation.
Try it
Unmapped field access and JSON_EXTRACT are available as Tech Preview features. Try them in Kibana Dev Tools or Discover. We'd love your feedback; file a GitHub issue with the ES|QL label.
ES|QL unmapped field access and JSON_EXTRACT are Tech Preview features. Tech Preview features are subject to change and are not covered by the support SLA of GA features. The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Contenido relacionado

How to build search analytics on Elastic using OpenTelemetry, no extra pipeline required
How to instrument your search application to use modern Open Telemetry standard to drive insights in to your search and users.
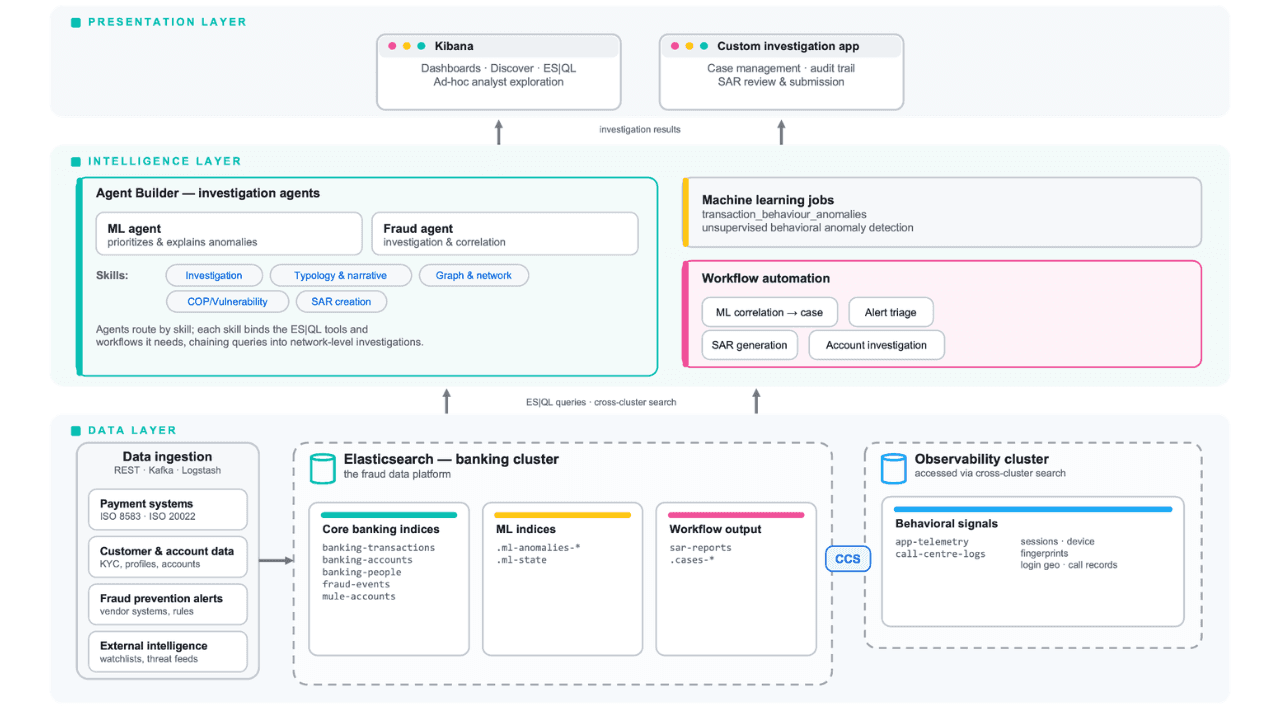
Follow the money: tracing laundering networks with ES|QL and cross-cluster search
The data model, cross-cluster architecture and five ES|QL queries that power mule detection and laundering network tracing, built from infrastructure most financial institutions already run.

1 de julio de 2026
One command. Natural language. Your Elasticsearch data, straight to the terminal.
Query your Elasticsearch data from the terminal in plain English. The official Elastic GitHub Copilot CLI plugin generates and runs ES|QL queries against your cluster. No Kibana, no manual syntax.

30 de junio de 2026
Building a multilingual voice agent with Elastic Agent Builder & Sarvam AI
A working demo combining Sarvam AI speech with Elastic Agent Builder: identity verification, per-customer ES|QL queries, and mid-call language switching across 22 Indian languages without multilingual indices.

29 de junio de 2026
Bringing it together: How we rebuilt Elasticsearch as a columnar metrics engine; 6.6x less storage, 160x faster queries
Elasticsearch metrics in version 9.4 run on a fully columnar engine: 6.6x less storage, 160x faster queries, native PromQL and OTel support.