Desde la búsqueda vectorial hasta las potentes API REST, Elasticsearch ofrece a los desarrolladores el conjunto de herramientas de búsqueda más completo. Explora nuestros cuadernos de muestra en el repositorio de Elasticsearch Labs para probar algo nuevo. También puedes iniciar tu prueba gratuita o ejecutar Elasticsearch localmente hoy mismo.
Todo el código puede encontrar en el repositorio Searchlabs, en la rama advanced-rag-techniques.
¡Bienvenidos a la Parte 2 de nuestro artículo sobre Técnicas Avanzadas de RAG! En la parte 1 de este serial, establecimos, discutimos e implementamos los componentes de procesamiento de datos de la avanzada tubería RAG:
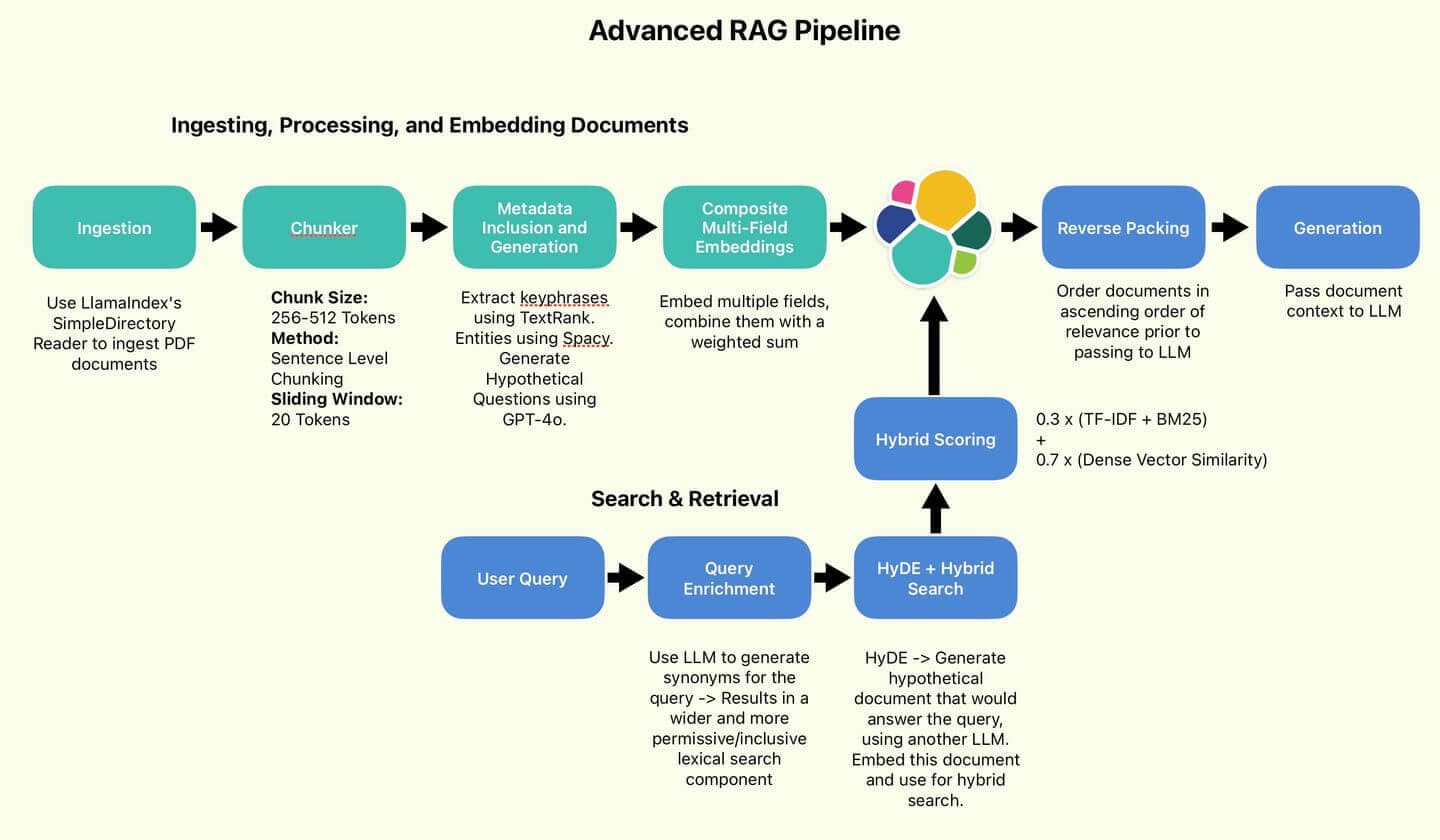
La tubería RAG empleada por el autor.
En esta parte, vamos a proceder con la consulta y la prueba de nuestra implementación. ¡Vamos al grano!
Índice
- Búsqueda y recuperación, generando respuestas
- Experimentos
- Conclusión
- Apéndice
Búsqueda y recuperación, generando respuestas
Hagamos nuestra primera pregunta, idealmente alguna información que se encuentre principalmente en el reporte anual. ¿Qué tal esto:
Ahora, apliquemos algunas de nuestras técnicas para mejorar la consulta.
Enriqueciendo consultas con sinónimos
Primero, mejoremos la diversidad de la redacción de la consulta y convirtiéramos en un formulario que pueda procesar fácilmente en una consulta de Elasticsearch. Aplicar la ayuda de GPT-4o para convertir la consulta en una lista de cláusulas OR. Vamos a escribir este prompt:
Cuando se aplica a nuestra consulta, GPT-4o genera sinónimos de la consulta base y el vocabulario relacionado.
En la clase ESQueryMaker , definí una función para dividir la consulta:
Su función es tomar esta cadena de cláusulas OR y dividirlas en una lista de términos, permitiéndonos hacer una coincidencia múltiple en nuestros campos clave del documento:
Por fin terminando con esta pregunta:
Esto cubre muchas más bases que la consulta original, con suerte reduciendo el riesgo de perder un resultado de búsqueda porque olvidamos un sinónimo. Pero podemos hacer más.
HyDE (Incrustación de Documentos Hipotéticos)
Vamos a reclutar de nuevo GPT-4o, esta vez para implementar HyDE.
La premisa básica de HyDE es generar un documento hipotético: el tipo de documento que probablemente contenga la respuesta a la consulta original. La veracidad o exactitud del documento no es un problema. Con eso en mente, escribamos el siguiente prompt:
Dado que la búsqueda vectorial suele operar sobre similitud vectorial coseno, la premisa de HyDE es que podemos obtener mejores resultados emparejando documentos con documentos en lugar de consultas con documentos.
Lo que nos importa es la estructura, el flujo y la terminología. No tanto la factualidad. GPT-4o genera un documento HyDE así:
Parece bastante creíble, como el candidato ideal para los tipos de documentos que queremos indexar. Vamos a incrustar esto y usarlo para búsqueda híbrida.
Búsqueda híbrida
Esta es la base de nuestra lógica de búsqueda. Nuestro componente de búsqueda léxica serán las cadenas de cláusulas OR generadas. Nuestro componente vectorial denso será el documento HyDE embebido (también conocido como el vector de búsqueda). Empleamos KNN para identificar eficientemente varios documentos candidatos más cercanos a nuestro vector de búsqueda. Por defecto, llamamos a nuestro componente de búsqueda léxico Puntaje con TF-IDF y BM25 . Finalmente, los puntajes léxicos y vectoriales densas se combinarán usando la proporción 30/70 recomendada por Wang et al.
Finalmente, podemos reconstruir una función RAG. Nuestro RAG, desde la consulta hasta la respuesta, seguirá este flujo:
- Convertir la consulta en cláusulas OR.
- Genera un documento HyDE e incrustalo.
- Pásame ambos como entradas a la búsqueda híbrida.
- Recuperar los resultados top-n, invertirlos para que el puntaje más relevante sea la "más reciente" en la memoria contextual del LLM (Empaquetado inverso) Ejemplo de empaquetado inverso: Consulta: "Técnicas de optimización de consultas Elasticsearch" Documentos recuperados (ordenados por relevancia): Orden invertido para el contexto del LLM: Al invertir el orden, la información más relevante (1) aparece al final en el contexto, Potencialmente recibiendo más atención del LLM durante la generación de respuestas.
- "Emplea consultas bool para combinar múltiples criterios de búsqueda de forma eficiente."
- "Implementar estrategias de caché para mejorar los tiempos de respuesta a las consultas."
- "Optimizar los mapeos de índice para un rendimiento de búsqueda más rápido."
- "Optimizar los mapeos de índice para un rendimiento de búsqueda más rápido."
- "Implementar estrategias de caché para mejorar los tiempos de respuesta a las consultas."
- "Emplea consultas bool para combinar múltiples criterios de búsqueda de forma eficiente."
- Pasa el contexto al LLM para que genere.
Vamos a hacer nuestra consulta y obtener nuestra respuesta:
Muy bien. Así es.
Experimentos
Hay una pregunta importante que responder ahora. ¿Qué obtuvimos invirtiendo tanto esfuerzo y complejidad adicional en estas implementaciones?
Hagamos una pequeña comparación. La pipeline RAG que implementamos frente a la búsqueda híbrida base, sin ninguna de las mejoras que hicimos. Haremos un pequeño serial de pruebas para ver si notamos diferencias sustanciales. Nos referiremos al RAG que acabamos de implementar como AdvancedRAG, y al pipeline básico como SimpleRAG.

Pipeline RAG simple sin adornos ni adornos
Resumen de resultados
Esta tabla resume los resultados de cinco pruebas de ambas tuberías RAG. Juzgué la superioridad relativa de cada método basándome en el detalle y la calidad de las respuestas, pero este es un juicio totalmente subjetivo. Las respuestas reales se reproducen a continuación de esta tabla para que lo consideres. Dicho esto, ¡echemos cómo les fue!
SimpleRAG no pudo responder a las preguntas 1 y 5. AdvancedRAG también profundizó mucho más en las preguntas 2, 3 y 4. Basándome en el mayor detalle, evalué mejor la calidad de las respuestas de AdvancedRAG.
| Prueba | Pregunta | Rendimiento avanzado de RAG | Rendimiento de SimpleRAG | Latencia de AdvancedRAG | Latencia de SimpleRAG | Ganador |
|---|---|---|---|---|---|---|
| 1 | ¿Quién audita Elastic? | Identificó correctamente a PwC como contralor. | No se identificó al contralor. | 11,6 | 4,4 | AdvancedRAG |
| 2 | ¿Cuál fue el total de ingresos en 2023? | Proporcionó la cifra correcta de ingresos. Incluyó contexto adicional sobre ingresos de años anteriores. | Proporcionó la cifra correcta de ingresos. | 13,3s | 2,8 | AdvancedRAG |
| 3 | ¿De qué producto depende principalmente el crecimiento? ¿Cuánto? | Identificamos correctamente a Elastic Cloud como el motor clave. Incluyó el contexto general de ingresos y mayor detalle. | Identificamos correctamente a Elastic Cloud como el motor clave. | 14.1 | 12,8 | AdvancedRAG |
| 4 | Describe el plan de beneficios para empleados | Ofreció una descripción completa de los planes de jubilación, programas de salud y otros beneficios. Incluyó cantidades específicas de contribución para distintos años. | Ofreció una buena visión general de los beneficios, incluyendo compensación, planes de jubilación, entorno laboral y el programa Elastic Cares. | 26,6 | 11,6 | AdvancedRAG |
| 5 | ¿Qué compañías adquirió Elastic? | Listé correctamente las adquisiciones recientes mencionadas en el reporte (CmdWatch, Build Security, Optimyze). Proporcioné algunas fechas de adquisición y precios de compra. | No se consiguió recuperar la información relevante del contexto proporcionado. | 11,9 | 2,7 | AdvancedRAG |
Prueba 1: ¿Quién audita a Elastic?
AdvancedRAG
SimpleRAG
Resumen: SimpleRAG no identificó a PWC como contralor
Vale, eso en realidad es bastante sorprendente. Eso parece un fallo de búsqueda por parte de SimpleRAG. No se recuperaron documentos relacionados con la auditoría. Bajemos un poco la dificultad con la siguiente prueba.
Test 2: ingresos totales 2023
AdvancedRAG
SimpleRAG
Resumen: Ambos RAG obtuvieron la respuesta correcta: 1.068.989.000 dólares de ingresos totales en 2023
Ambos estaban justo aquí. ¿Parece que AdvancedRAG adquirió una gama más amplia de documentos? Sin duda, la respuesta es más detallada e incorpora información de años anteriores. Eso es de esperar dadas las mejoras que hicimos, pero es demasiado pronto para decidir.
Subamos la dificultad.
Prueba 3: ¿De qué producto depende principalmente el crecimiento? ¿Cuánto?
AdvancedRAG
SimpleRAG
Resumen: Ambos RAGs identificaron correctamente a Elastic Cloud como el principal motor de crecimiento. Sin embargo, AdvancedRAG incluye más detalles, teniendo en cuenta los ingresos por subscripción y el crecimiento de clientes, y menciona explícitamente otras ofertas de Elastic.
Prueba 4: Describe el plan de beneficios para empleados
AdvancedRAG
SimpleRAG
Resumen: AdvancedRAG entra en mucho más detalle y profundidad, mencionando el plan 401K para empleados con base en EE. UU., así como definiendo planes de contribución fuera de EE. UU. También menciona planes de salud y bienestar, pero no incluye el programa Elastic Cares, que menciona SimpleRAG.
Prueba 5: ¿Qué compañías adquirió Elastic?
AdvancedRAG
SimpleRAG
Resumen: SimpleRAG no recupera ninguna información relevante sobre adquisiciones, lo que lleva a una respuesta fallida. AdvancedRAG lista correctamente CmdWatch, Build Security y Optimyze, que fueron las adquisiciones clave listadas en el reporte.
Conclusión
Según nuestras pruebas, nuestras técnicas avanzadas parecen aumentar el rango y la profundidad de la información presentada, lo que podría mejorar la calidad de las respuestas RAG.
Además, puede haber mejoras en la fiabilidad, ya que preguntas formuladas de forma ambigua como Which companies did Elastic acquire? y Who audits Elastic fueron respondidas correctamente por AdvancedRAG pero no por SimpleRAG.
Sin embargo, conviene tener en cuenta que en 3 de cada 5 casos, la tubería básica de RAG, que incorpora Búsqueda Híbrida pero ninguna otra técnica, logró producir respuestas que capturaron la mayor parte de la información clave.
Cabe señalar que, debido a la incorporación de LLMs en las fases de preparación y consulta de datos, la latencia de AdvancedRAG suele ser entre 2 y 5 veces mayor que la de SimpleRAG. Este es un costo significativo que puede hacer que AdvancedRAG sea adecuado solo para situaciones donde la calidad de la respuesta se prioriza sobre la latencia.
Los importantes costos de latencia pueden aliviar usando un LLM más pequeño y barato como Claude Haiku o GPT-4o-mini en la fase de preparación de datos. Almacena los modelos avanzados para generar respuestas.
Esto está en línea con los hallazgos de Wang et al. Como muestran sus resultados, cualquier mejora realizada es relativamente incremental. En resumen, un RAG básico te lleva casi hasta un producto final decente, siendo además más barato y rápido. Para mí, es una conclusión interesante. Para casos de uso donde la velocidad y la eficiencia son clave, SimpleRAG es la opción sensata. Para casos de uso en los que hay que exprimir hasta la última gota de rendimiento, las técnicas incorporadas en AdvancedRAG pueden ofrecer una vía a seguir.

Los resultados del estudio de Wang et al. revelan que el uso de técnicas avanzadas genera mejoras consistentes pero incrementales.
Apéndice
Prompts
Prompt de respuesta a preguntas RAG
Prompt para que el LLM genere respuestas basadas en la consulta y el contexto.
Prompt generador de consultas elástico
Prompt para enriquecer consultas con sinónimos y convertirlas al formato OR.
Prompt generador de preguntas potenciales
Prompt para generar posibles preguntas, enriquecer metadatos del documento.
Prompt generador de HyDE
Prompt para generar documentos hipotéticos usando HyDE
Consulta de búsqueda híbrida de ejemplo
Contenido relacionado

Descríbelo, no lo dibujes: dashboard de Kibana con IA integrada a través de MCP y ES|QL
De la indicación al dashboard. Aprende a construir dashboards de Kibana con lenguaje natural a través de example-mcp-dashbuilder: una aplicación MCP open source que escribe consultas ES|QL, crea gráficos interactivos y exporta dashboards completamente funcionales directamente a Kibana.

23 de abril de 2026
Cómo creamos Elasticsearch simdvec para hacer una de las búsquedas vectoriales más rápidas del mundo
Cómo construimos Elasticsearch SIMDvec, la biblioteca del kernel SIMD ajustada a mano detrás de cada consulta de búsqueda vectorial en Elasticsearch.

4 de mayo de 2026
Cómo medir y mejorar la recuperación de búsqueda de Elasticsearch: de 0,43 a 0,75 con búsqueda híbrida
Aprende a medir y mejorar la recuperación de búsqueda en Elasticsearch combinando la búsqueda léxica BM25 con incrustaciones vectoriales de Jina AI, usando la API rank_eval para validar la mejora con cifras reales.

10 de abril de 2026
Agrupación no supervisada de documentos con Elasticsearch + incrustaciones de Jina
Un enfoque práctico y reproducible para la agrupación no supervisada de documentos con Elasticsearch y embeddings de Jina.

2 de abril de 2026
Cuando TSDS se une a ILM: diseñar flujos de datos temporales que no rechazan los datos tardíos
Cómo los límites de tiempo de TSDS interactúan con las fases de ILM; y cómo diseñar políticas que toleren métricas tardías.