Get hands-on with Elasticsearch: Dive into our sample notebooks in the Elasticsearch Labs repo, start a free cloud trial, or try Elastic on your local machine now.
Elasticsearch Query Language (ES|QL) now has subqueries in FROM. Three indices, different schemas, one query; each source gets its own pipeline with its own filters and transforms. No more CASE chains. No more client-side stitching. Add a fourth source? Add a fourth branch; zero changes to the existing three.
The problem: Heterogeneous data, one query
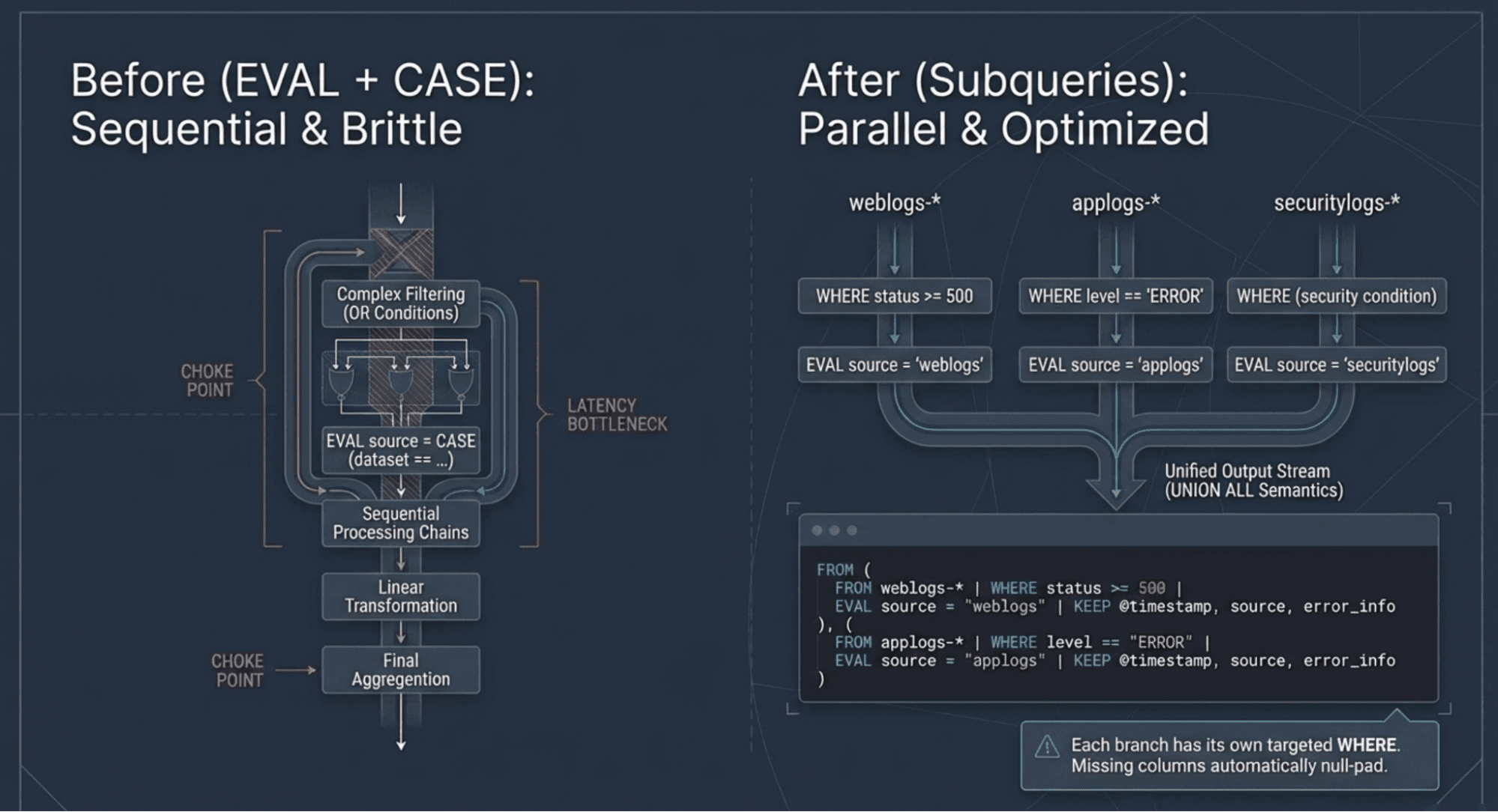
Consider a production incident investigation. Errors are spread across three microservices: an API gateway, a payments service, and an auth service, each with different field names and different conventions. Before subqueries, combining them in a single ES|QL query meant cramming everything into one FROM with CASE chains:
This is brittle and slow. The disjunctive OR prevents predicate pushdown; every index scans every condition. Every CASE chain grows with every source. Copy it into five dashboards and three alert rules, and you have eight places to update when anything changes.
The fix: Independent pipelines
Subqueries replace the monolithic FROM + CASE pattern. Each data source gets its own complete pipeline:
The gateway branch only scans for HTTP 500s. The payments branch only looks at transaction statuses. The auth branch only checks login failures. Because each branch has its own WHERE, the optimizer pushes filters independently into each index, restoring the predicate pushdown that a single FROM with OR conditions prevents. Fields that exist in one branch but not another are filled with null.
Adding a fourth service means adding a fourth branch. Existing branches don't change.
Save it as a view
This is where subqueries and logical views combine. Wrap the subquery above in a named view, with one API call:
Now consumers just write FROM error_triage | STATS error_count = COUNT(*) BY service. Three indices, three pipelines, one name. If you have 10 dashboards and five alert rules consuming this pattern, that's 15 copies of the same logic today; with a view, it's one definition and zero consumer-side edits when you add a fourth service. See Elasticsearch ES|QL Views for the full views deep dive.
What you can do inside a branch
Each branch supports the full ES|QL pipeline: WHERE, EVAL, STATS, LOOKUP JOIN, ENRICH, and more. See the subquery documentation for the complete list.
Aggregate different metrics, and then combine
Each branch can compute its own summary before results are merged. This is useful when different indices track the same concept under different field names:
Both branches produce avg_latency and hour, but each computes it from a different source field. The combined result is a single table you can chart or alert on, without normalizing field names at ingest time. This pattern is impossible with a single FROM; you can't compute different aggregations per index without subqueries.
Subqueries vs. FORK
ES|QL also has FORK (now generally available), which creates parallel execution branches from the same input. The distinction:
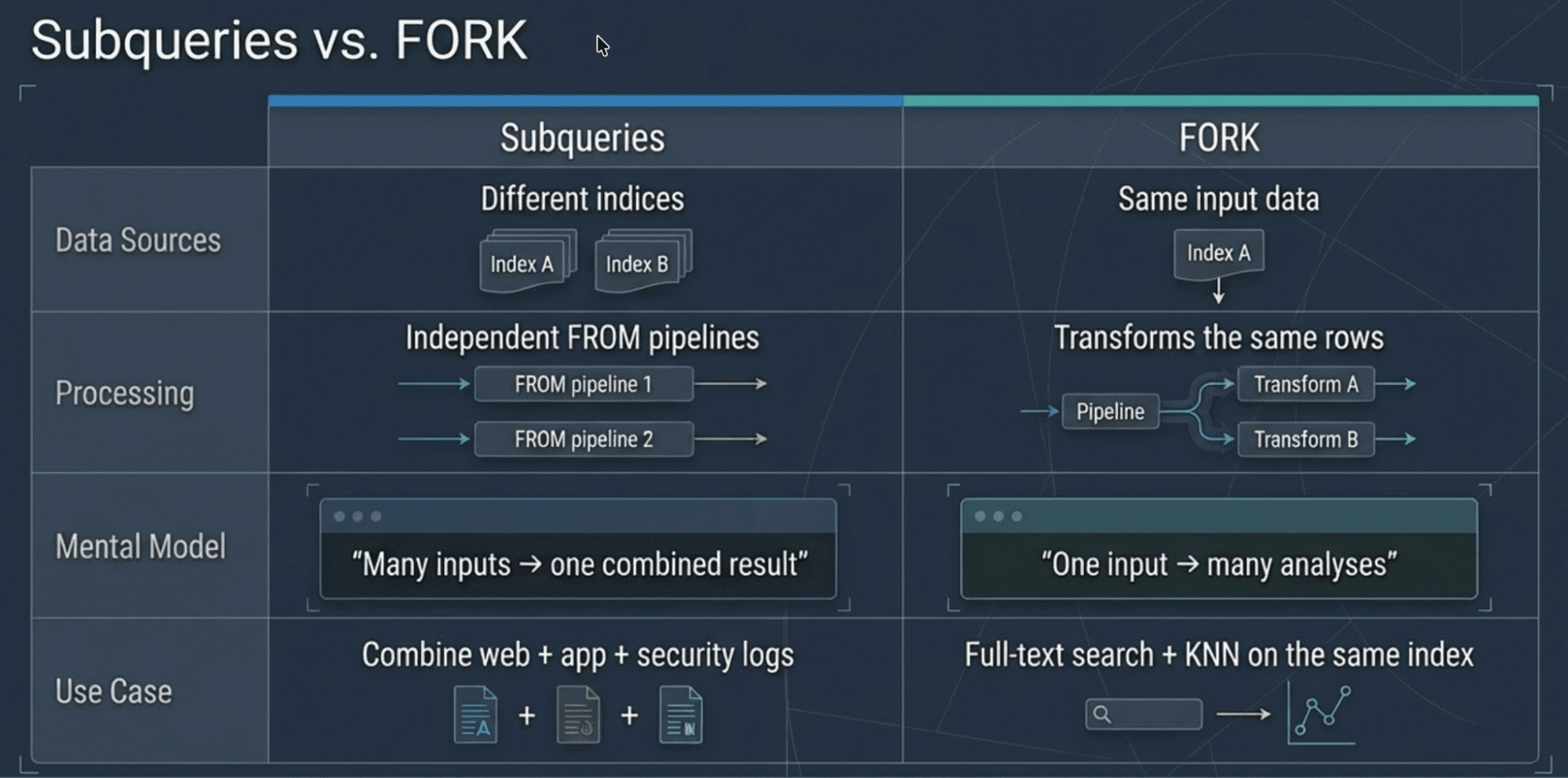
Different indices → subqueries. Same data, different analyses → FORK.
How this compares
If you're coming from other query languages, here's how ES|QL subqueries stack up at the time of writing:
Splunk SPL/SPL2 has append and multisearch in classic SPL, and SPL2 adds a union command that merges events from multiple datasets (the closest analogue to ES|QL subqueries). Federated Search extends this across remote Splunk deployments (analogous to CCS). The differences are in how the engine handles each branch: ES|QL subqueries give each branch independent predicate pushdown, meaning filters are pushed into each index's shard-level structures separately. SPL2 union merges datasets but optimization across branches is limited to what the search scheduler can parallelize. Wrapping ES|QL subqueries in a view gives you engine-level encapsulation with role-based access control (RBAC); Splunk's equivalent is saved searches and macros, which are text substitution expanded at parse time.
SQL databases have UNION ALL, which is the closest analog. The difference is that SQL UNION ALL typically requires matching column counts and types at parse time. ES|QL subqueries are more forgiving; columns that exist in one branch but not another get null-padded automatically, which matters when your sources have different schemas (the norm in observability data). SQL views solve the reuse problem similarly, but ES|QL views are cluster-level objects, not database-scoped; they work across cross-cluster search boundaries.
Grafana / Datadog / other dashboarding tools handle multisource composition at the visualization layer: Run separate queries, merge in the panel. This works for display but breaks for alerting, downstream queries, and anything that needs a single result set programmatically. ES|QL subqueries push the composition into the engine, so alerts, views, and API consumers all get the same unified result.
| Capability | Splunk SPL/SPL2 | SQL UNION ALL | Dashboard-layer merge | ES|QL subqueries |
|---|---|---|---|---|
| Independent filters per source | SPL2 `union` merges datasets; optimization is scheduler-level | Yes | N/A (separate queries) | Yes; parallel with pushdown |
| Schema mismatch handling | Manual field normalization | Strict column matching | Manual in panel config | Automatic null-padding |
| Engine-level reuse | Text macros (parse-time expansion) | Database-scoped views | Dashboard variables | Cluster-level views with RBAC |
| Works for alerts + API | Limited (summary indexing) | Yes | No; display only | Yes |
| Add a source | Edit every macro/saved search | Add a UNION branch | Add a panel query | Add a branch; existing branches unchanged |
Current constraints
In the Tech Preview release, subqueries are non-correlated; branches run independently and can't reference the outer query. They're supported in FROM only (not TS), and FORK can't be used inside or after subqueries. See the subquery documentation for details.
What's next for subqueries
WHERE subqueries — WHERE field IN (FROM other_index | ...) and other correlated forms — will extend the composition model from FROM into filtering. This brings the familiar SQL pattern of nested filtering to ES|QL.
Try it
Subqueries in FROM are available as a Tech Preview. Try them in Kibana Dev Tools or Discover. We'd love your feedback; file a GitHub issue with the ES|QL label.
ES|QL subqueries in FROM are a Tech Preview feature. Tech Preview features are subject to change and are not covered by the support SLA of GA features. The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Related Content
How to instrument your search API with OpenTelemetry and query it with ES|QL
Add custom attributes to OpenTelemetry spans and run six ES|QL queries that reveal your top searches, zero-result rate and slowest queries.

How to build search analytics on Elastic using OpenTelemetry, no extra pipeline required
How to instrument your search application to use modern Open Telemetry standard to drive insights in to your search and users.
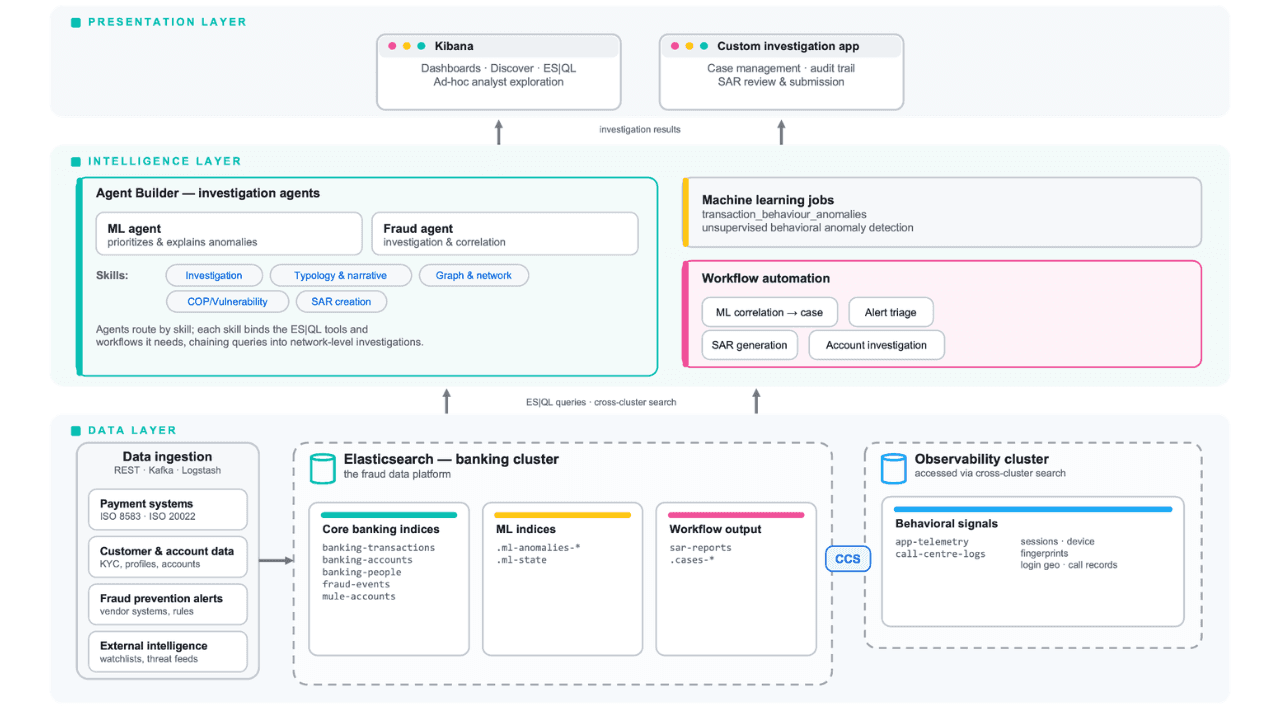
Follow the money: tracing laundering networks with ES|QL and cross-cluster search
The data model, cross-cluster architecture and five ES|QL queries that power mule detection and laundering network tracing, built from infrastructure most financial institutions already run.

July 1, 2026
One command. Natural language. Your Elasticsearch data, straight to the terminal.
Query your Elasticsearch data from the terminal in plain English. The official Elastic GitHub Copilot CLI plugin generates and runs ES|QL queries against your cluster. No Kibana, no manual syntax.

June 30, 2026
Building a multilingual voice agent with Elastic Agent Builder & Sarvam AI
A working demo combining Sarvam AI speech with Elastic Agent Builder: identity verification, per-customer ES|QL queries, and mid-call language switching across 22 Indian languages without multilingual indices.