Try out vector search for yourself using this self-paced hands-on learning for Search AI. You can start a free cloud trial or try Elastic on your local machine now.
We've brought simdvec, Elasticsearch's native single instruction, multiple data (SIMD) vector scoring engine, to serverless. Search throughput nearly doubled under concurrent load, and p99.9 tail latency dropped from 237 ms to 30 ms. By giving simdvec direct access to the blob cache's memory-mapped regions, serverless now runs the same zero-copy SIMD kernels as stateful, with identical recall and zero heap overhead. And because serverless gives us control over the entire storage layer, we believe it's where vector search will be fastest. Here's how we got there.
Vector Search on Elasticsearch Serverless
Elasticsearch Serverless is built on Stateless Elasticsearch, a fully decoupled compute and storage architecture where index data lives in remote object storage and search nodes maintain only a local cache. For vector search to be fast on this architecture, the scoring engine needs to work directly with the local cache, not copy it to the heap first.
Elasticsearch simdvec is the engine behind every vector distance computation in Elasticsearch. It provides hand-tuned AVX-512 and NEON kernels, bulk scoring with explicit prefetching, and off-heap memory access that keeps data flowing from storage straight to CPU registers. On stateful Elasticsearch, simdvec has always had a direct fuel line: Memory-mapped files feed native pointers straight into SIMD intrinsics. On serverless, the data was sitting right there in the blob cache's memory-mapped regions, in exactly the right form, but there was no path connecting it to the scoring engine.
We've now built that path. simdvec runs on Serverless with the same off-heap, native SIMD scoring as stateful. And because serverless gives us control over the entire storage layer, this is just the beginning.
Premium fuel only: why simdvec requires off-heap memory for vector scoring
simdvec's speed comes from working directly with off-heap memory. It takes a native pointer to memory-mapped data and passes it straight to C++ SIMD intrinsics. No intermediate copies, no heap allocations. The data flows from storage straight to CPU registers. This matters more than it sounds: simdvec's kernels process vectors faster than the data can be copied, so any copy in the path becomes the bottleneck, not the scoring itself.
On stateful Elasticsearch, this just works. Lucene memory-maps index files from local disk, and the scorer extracts a native pointer directly from the mapped region. This is the path that delivers the benchmark numbers we've published, and it's what we wanted to bring to serverless. To see how, we first need to understand how serverless stores and accesses data.
The serverless blob cache: how Elasticsearch stores vector data
In the stateless architecture, the primary copy of all index data lives in remote object storage, such as S3. Each search node maintains a local cache (called the blob cache) that keeps recently and frequently accessed portions of the index data on local SSD. The frozen tier on stateful Elasticsearch uses the same architecture: Searchable snapshots are backed by a similar blob cache that memory-maps regions from remote storage onto local disk. When a search hits cached data, it's served from fast local storage. When it misses, the blob cache fetches the data from the remote store and caches it for future queries.
The blob cache is organized into fixed-size memory-mapped regions, 16MB by default. It manages its own lifecycle: tracking which regions are in use, applying a least-frequently-used eviction policy when the cache is full, and reference counting to ensure regions aren't evicted while being read. The regions are still memory-mapped through the OS, but the blob cache controls which regions exist, which are populated, and when they're reclaimed. On stateful, those decisions are left entirely to the OS.
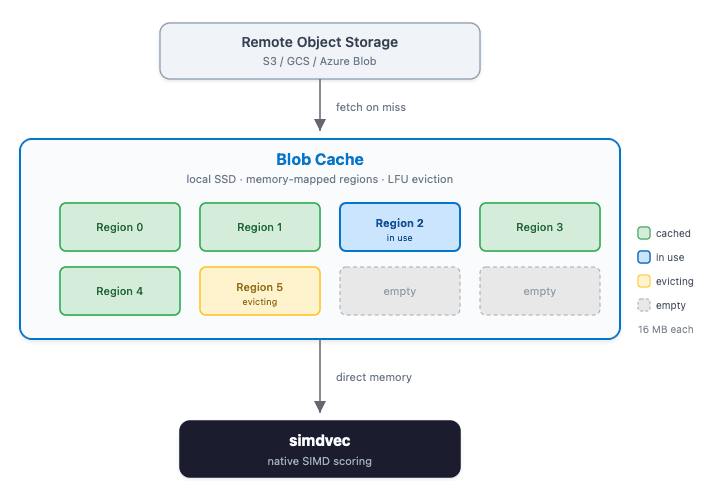
Crucially, because each region is memory-mapped, the blob cache already holds vector data in exactly the form simdvec needs. But before we built the connection, there was no way to get at it. Every vector comparison was copied into a heap array and handed to a slower scorer. No direct memory pointers, no SIMD, and garbage collection pressure on every call.
Unified scoring: one SIMD path for all storage tiers
We introduced a new abstraction that lets the scorer safely borrow direct memory from whatever storage layer is underneath, just long enough to run the SIMD computation. If the data is available as direct memory, simdvec's native kernels run. If not (data not yet cached or spanning a region boundary), the scorer falls back to a heap copy. In practice, the fallback is rare.
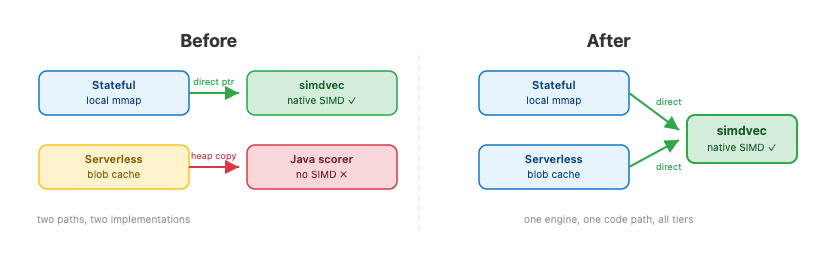
This gave us a single scoring entry point across all tiers:
- Stateful (local disk): The scorer extracts a native pointer from the OS memory map.
- Blob cache (serverless, frozen tier): The scorer borrows a direct memory slice from a cache region.
- Fallback: The scorer copies bytes to the heap. Rare in practice.
The scorer doesn't know which tier it's running on, and it doesn't need to. It also means we no longer maintain separate scoring implementations; previously, there was a fast native path for stateful and a slower path for everything else. Now every improvement to simdvec benefits all tiers automatically, including its most powerful capability: bulk scoring.
Bulk vector scoring across blob cache regions
A single query may score thousands of candidate vectors. simdvec's bulk scoring processes these in batches with multi-accumulator inner loops, query amortization, and cache-line prefetching, up to 4x faster than single-vector alternatives when data exceeds CPU cache.
Search over an Inverted file (IVF) index is where bulk scoring has the most impact. The query selects a set of candidate posting lists and sweeps through the quantized vectors, scoring them in large batches against the query vector. On stateful, those vectors live in one contiguous memory-mapped file, so bulk scoring resolves them with straightforward pointer arithmetic and scores a batch in a single native call.
On serverless, a sweep through a posting list may cross blob cache region boundaries. We extended the direct memory abstraction with a bulk access method that resolves multiple vector offsets to their respective cache regions in a single call. If all vectors in the batch are cached and none cross a region boundary, the scorer gets a direct memory slice and passes the whole batch to simdvec's native bulk kernel with the same prefetching and pipelining as stateful. When a vector does cross a boundary, the system falls back to per-vector scoring: still zero-copy, just without the batching benefit. With 16MB regions and 1024-byte vectors, that happens roughly once every 16,000 vectors.
simdvec's bulk scoring architecture, the key differentiator highlighted in the simdvec benchmarks, now operates on serverless with the same characteristics that make it fast on stateful. So how does it perform in practice?
simdvec on Elasticsearch Serverless: vector search lap times
We benchmarked with an 18 million vector MSMARCO dataset at 1024 dimensions, using IVF with Better Binary Quantization (BBQ) 1-bit quantization. All results are on a warm blob cache with the full dataset resident in local cache regions, so we're measuring the scoring path rather than remote fetch latency.
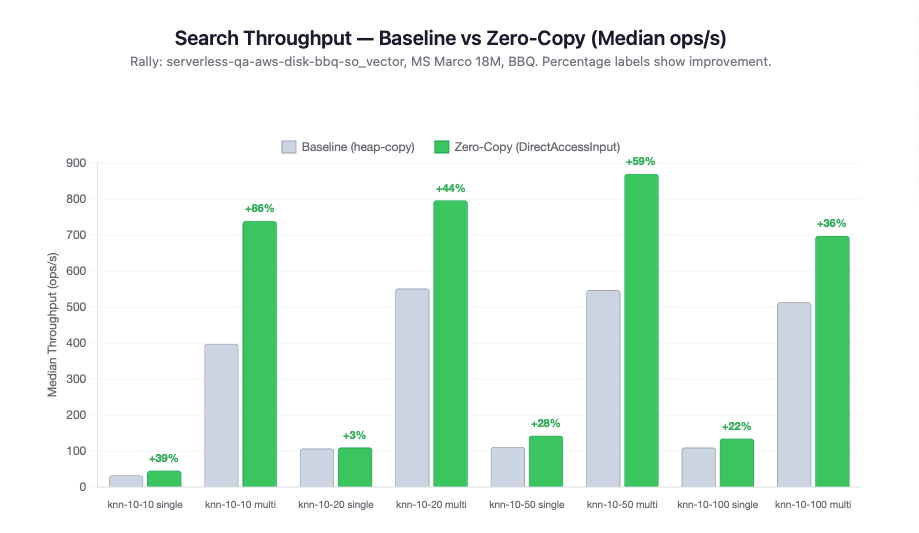
Throughput. Under concurrent load, search throughput nearly doubled, jumping from 398 to 739 ops/s. Single-client gains were 23-39%, but the real difference shows up under concurrency: The improvement was 2-3x larger because eliminating heap copies removes the GC pressure and allocation contention that previously throttled concurrent scoring.
Tail latency. The direct memory path transformed tail latency under load:
- p99.9 dropped from 237 ms to 30 ms (87% reduction).
- p99.99 dropped from 9.1 seconds to 55 ms (99.4% reduction).
p100 dropped from 11.4 seconds to under 100 ms.
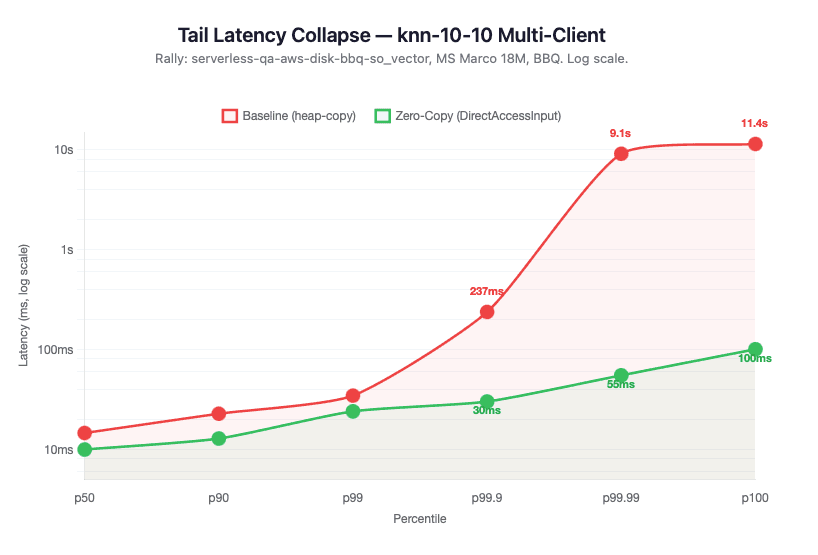
The worst-case outliers that previously took seconds now complete in tens of milliseconds. The heap-copy-induced queueing that caused latency spikes is gone.
Recall is identical. The same vectors are scored, producing the same results. And we're just getting started.
Beyond parity: what Elasticsearch Serverless can do for vector search that stateful can't
Reaching parity with stateful was the goal. But the more interesting realization is what the stateless architecture lets us do that stateful can’t.
On stateful, the OS controls memory-mapped file behavior: which pages stay resident, when to evict, how aggressively to read ahead. The application can offer hints, but they apply to entire file mappings, and the kernel may ignore them. Worse, search and indexing happen concurrently on the same node, so a hint that benefits one access pattern can hurt another. In practice, to balance different needs, you have to be conservative.
On serverless, two things are fundamentally different. The blob cache manages its own memory-mapped regions with full application-level control. And serverless separates indexing and search onto dedicated tiers: Search nodes never merge, indexing nodes never serve queries. No conflicting access patterns means we can be aggressive with memory advice. Here’s what we’re working on:
- Per-region memory advice. The blob cache knows what type of data each region holds. It can issue random-access hints for rescoring regions, where raw float32 vectors are read in unpredictable order and the kernel’s default readahead would waste memory on pages that will never be used. It can apply sequential readahead for scans through quantized vectors. On the indexing tier, merges read data sequentially, so aggressive readahead brings pages in before they're needed, with no risk of harming concurrent random reads that simply aren't happening on that node.
- Cache-aware prefetching. simdvec already prefetches at the CPU cache-line level. On serverless, we can coordinate this with the blob cache's knowledge of region residency, prefetching at multiple levels: remote store to cache, OS pages to RAM, and cache lines to CPU. The blob cache can tell the scorer which regions are resident before scoring begins, avoiding work on data that would trigger a remote fetch.
- Workload-aware eviction. The blob cache can prioritize retaining data that vector search depends on: IVF centroid indexes that are checked on every query or quantized vectors that are scored in bulk, over data that's accessed infrequently. The OS page cache evicts based on generic heuristics with no understanding of what the data represents. On serverless, eviction policy can be tuned to the workload.
The blob cache gives us a level of control over the memory hierarchy that the OS page cache simply can’t. This is why we see serverless as the most promising platform for the next generation of vector search performance work. Not just matching stateful, but surpassing it. And vectors are just the beginning.
Vector search on Elasticsearch Serverless: what we shipped and what's next
simdvec now runs everywhere Elasticsearch runs (stateful, serverless, and frozen tier) with the same native SIMD scoring, the same bulk scoring, and the same off-heap efficiency. The abstraction we built is general-purpose and already wired through every layer in the storage chain, so the same approach could benefit term lookups, aggregations, sorting, and stored field retrieval in the future.
Elasticsearch Serverless is where we're investing most heavily in vector search performance. Every improvement to simdvec, every optimization to the blob cache, and every new storage-level improvement lands here first. If you're choosing where to run your vector workloads, serverless is the platform that keeps getting faster. You can get started with a free Elastic Cloud trial.
Zugehörige Inhalte

16. Juli 2026
A picture is worth 1.5x the words: What we learned benchmarking product search embeddings
We benchmarked two embedding models on 5,000 real products and found that combining image and text beats either alone by up to 50%. Here's the data and the model that won.

13. Juli 2026
The disk that never woke up: what actually decided our Qdrant vector search benchmark rematch
On the same hardware, Elasticsearch and Qdrant land in the same range at 56 QPS. The io_uring disk scorer and memory claims turned out to be the two things that mattered least.

21. Juli 2026
4 NVIDIA AI tasks, 1 Elasticsearch API: Embeddings, chat, completion, and rerank
Set up NVIDIA hosted models in Elasticsearch with one API key and a model ID. No custom integration code needed.

10. Juli 2026
How BBQ shrinks Jina v5 embeddings by 29x without losing recall in Elasticsearch
A hands-on test comparing BBQ and float32 vector indices in Elasticsearch, measuring memory, disk and recall@10 across five languages.

9. Juli 2026
Why Elasticsearch is becoming a columnar database
Elasticsearch is becoming a first-class columnar database. Columnar Mode ships in 9.5, storing data once alongside the existing modes and cutting storage footprints while speeding up analytical queries.