Get hands-on with Elasticsearch: Dive into our sample notebooks in the Elasticsearch Labs repo, start a free cloud trial, or try Elastic on your local machine now.
ES|QL adds three capabilities in this release that change how you model and query data: logical views let you define a query once and reference it by name across any dashboard or alert; subqueries in FROM let you combine indices with incompatible schemas in a single pipeline; schema-on-read lets you query fields that were never mapped, against data already indexed, without touching the mapping or reindexing. Alongside these: timezone support graduates to GA, LIMIT BY adds grouped top-N natively, and lookup joins get faster through Lucene structure reuse. Each headline feature has its own deep dive linked below.
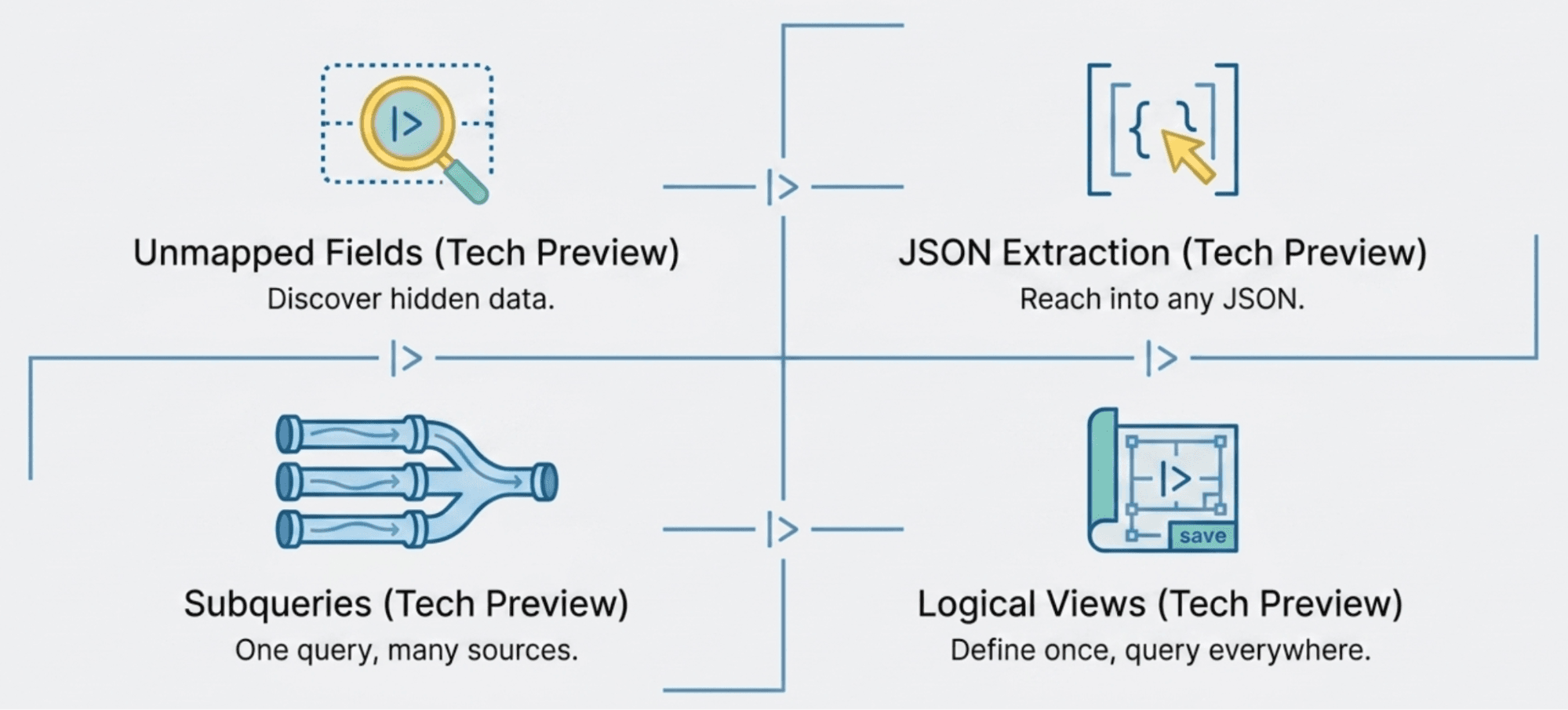
How ES|QL views, subqueries and schema-on-read compose
Views, subqueries, and schema-on-read are designed to layer together. A subquery gives each index its own pipeline. A view wraps that subquery so consumers reference one name. Schema-on-read lets those pipelines access fields that were never in the mapping. The result: one FROM view_name query that combines multiple services, normalizes their schemas, and surfaces fields you forgot to map at ingest time. Each capability has its own deep dive linked in the sections that follow.
Logical views (Tech Preview)
Logical views are virtual indices: query definitions stored at the Elasticsearch cluster level that you reference by name in any FROM clause, exactly like a real index. Define a view once via the _query/view REST API. Every dashboard, alert, and ad-hoc query using the view picks up definition changes automatically. Views support nesting, cross-cluster search, and dedicated RBAC privileges.
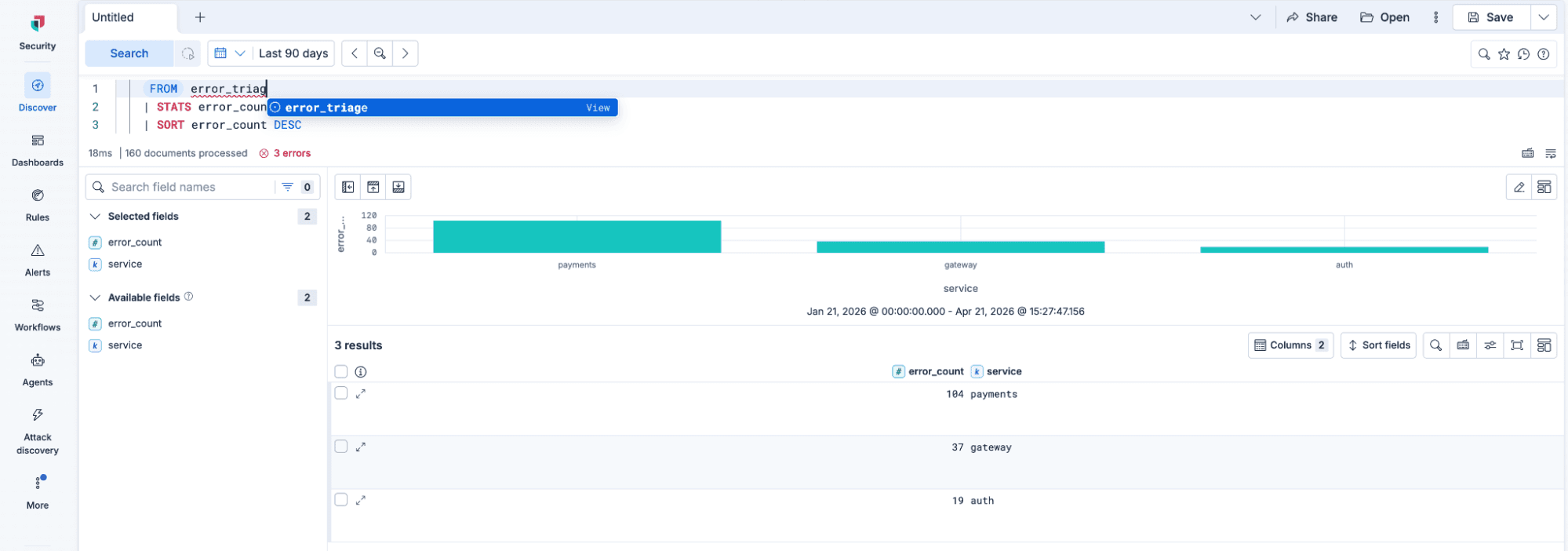
Read the full deep dive: Elasticsearch ES|QL Views: One Query to Rule Twelve Dashboards
Subqueries in FROM (Tech Preview)
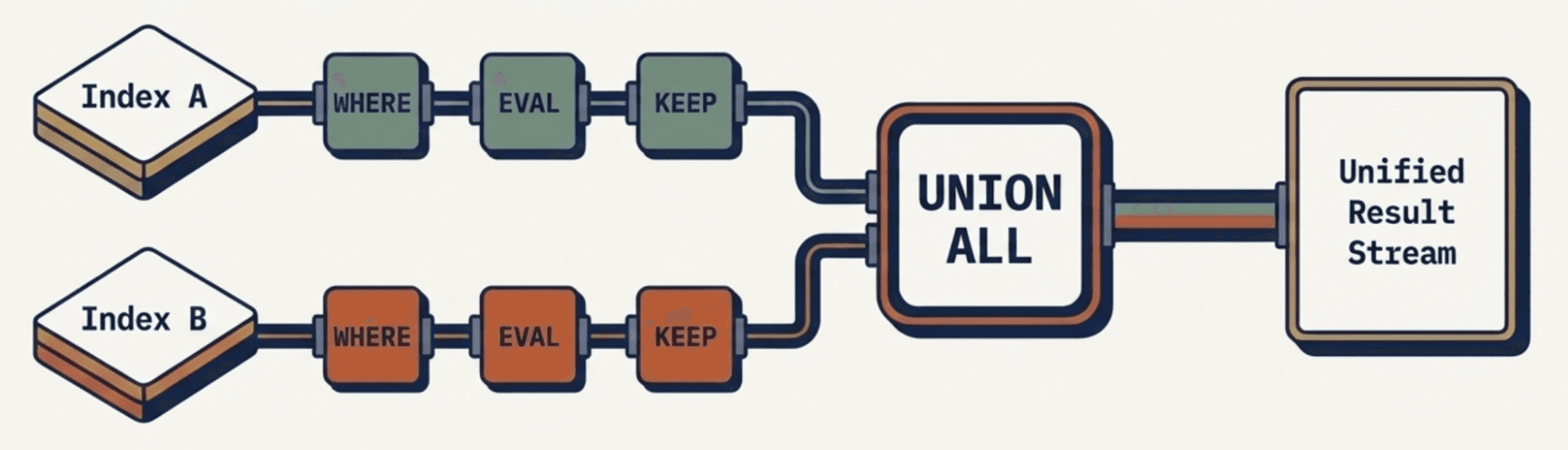
Subqueries give you the composition primitive: combine data from multiple indices, each with different schemas, in a single query. Each branch gets its own WHERE, EVAL, KEEP, and the optimizer pushes filters independently into each index. Results combine with UNION ALL semantics.
Read the full deep dive: Three Indices Walk Into a FROM Clause: ES|QL Subqueries in Elasticsearch
Schema-on-read: unmapped fields + JSON extraction (Tech Preview)
Unmapped field access lets you query fields that were never declared in the mapping, against data already in the index, without reindexing. SET unmapped_fields="load" is the strategic abstraction: one line, and fields missed at ingest time become queryable from _source. JSON_EXTRACT is the lower-level tool for surgical extraction from raw JSON strings and flattened fields.

Read the full deep dive: Elasticsearch ES|QL "Schema on Read": Your Unmapped Fields Were There All Along
Timezone support (GA)
SET time_zone is now generally available, bringing timezone-aware date/time operations to every ES|QL query. Set it once at the query level and all DATE_TRUNC, date aggregations and timestamp output reflect the local timezone, with no post-processing needed. It accepts any IANA timezone string.
Output timestamps include the timezone offset (e.g., 2026-04-09T11:00:00.000-07:00 instead of ...T18:00:00.000Z). There is no per-function timezone argument; SET time_zone is the mechanism. In Kibana, ES|QL dashboard panels and Discover queries can now produce timezone-aware results by local business hours without any post-processing.
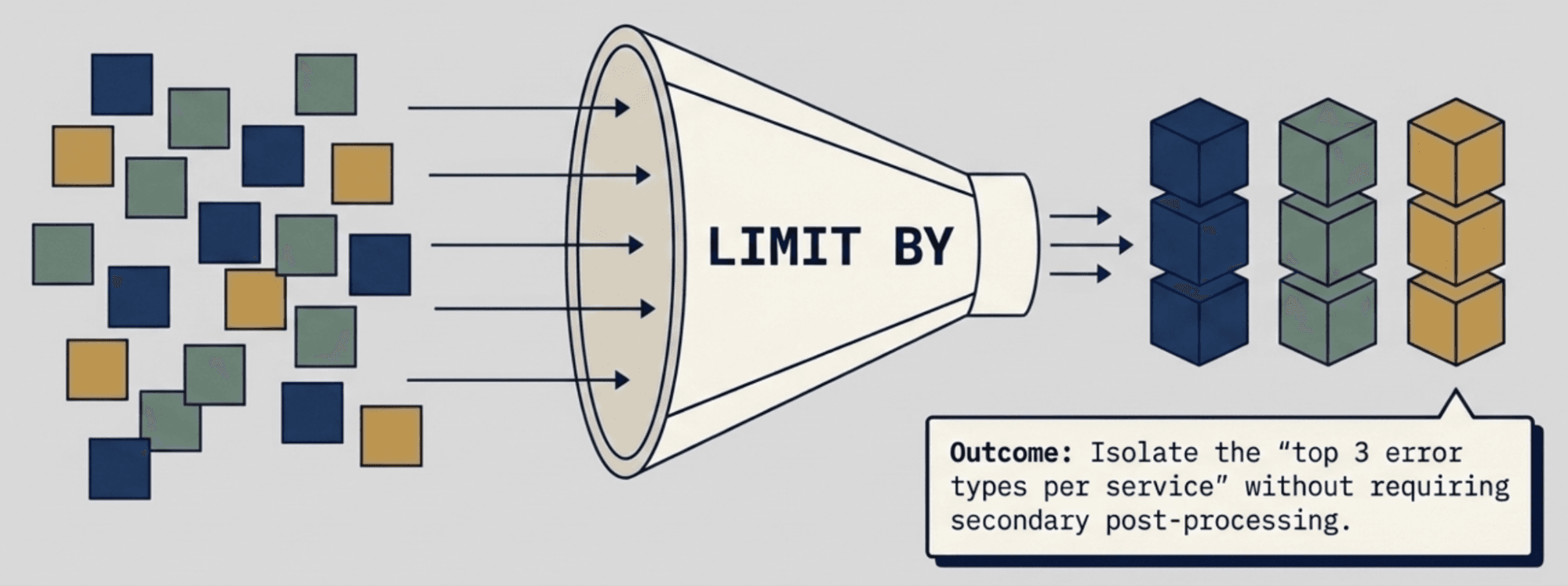
LIMIT BY: grouped top-N (Tech Preview)
"Show me the top 3 error types per service" previously required post-processing because SORT and LIMIT applied globally, giving you the top N overall rather than the top N per group. LIMIT BY solves this natively:
Returns the top 3 rows for each distinct service value. The number comes before BY.
ES|QL FIRST, LAST, EARLIEST and LATEST aggregation functions
FIRST, LAST, EARLIEST, LATEST (GA) return the value associated with the min or max of a sort field:
FIRST and LAST take two arguments: the value field and the sort field. EARLIEST and LATEST are single-argument aliases that implicitly sort by @timestamp, useful for retrieving which value appeared first or last in a time series.
ES|QL URI_PARTS, USER_AGENT and REGISTERED_DOMAIN commands
URI_PARTS, USER_AGENT, REGISTERED_DOMAIN are three new pipe commands that expand a single field into multiple structured output columns:
ES|QL lookup join optimizations and GA promotions
Several features graduate to generally available, and lookup joins get faster.
- VALUES (GA): returns all distinct values within a group as a multivalue field.
- MV_EXPAND (GA): expands multivalue fields into separate rows.
- FORK (GA): parallel execution branches from the same input, now generally available after previewing since 9.1.
- SPARKLINE (Tech Preview): inline sparkline visualizations in query results.
- MV_UNION, MV_DIFFERENCE, MV_INTERSECTS (Tech Preview): set operations on multivalue fields.
_sizemetadata: access document size viaMETADATA _sizein theFROMclause.
Lookup join optimizations
Lookup joins, introduced in 9.1, get two significant optimizations:
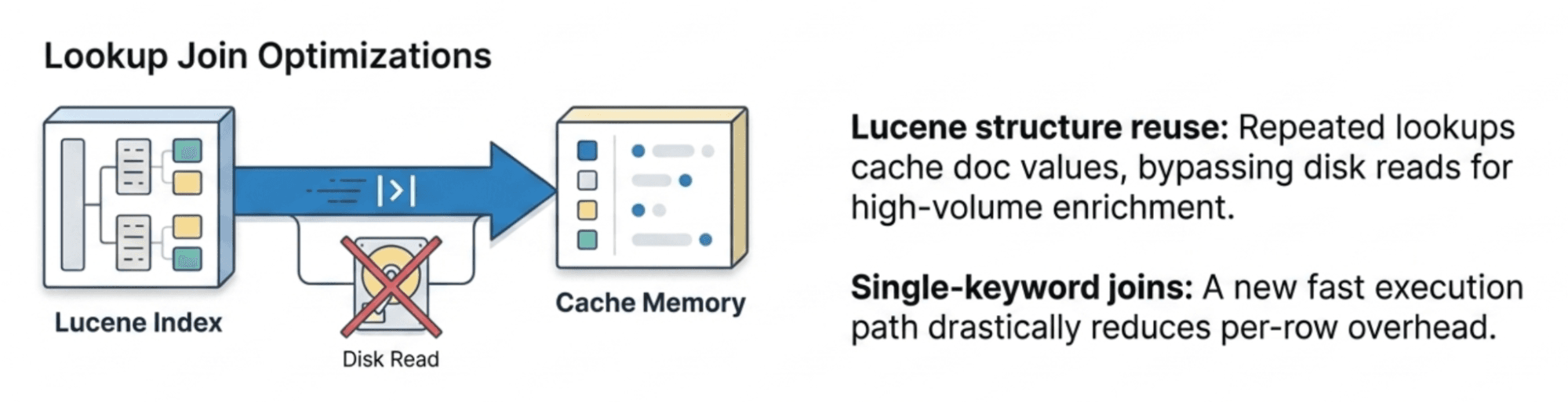
- Lucene structure reuse. Repeated lookups against the same index now cache low-level Lucene structures (doc values and TermsEnum) across queries, avoiding repeated disk reads. This matters most for the typical enrichment pattern: many rows joined against a small lookup index. The improvement comes from reusing these structures rather than rebuilding them per query.
- Single-keyword join optimization. Lookup joins on a single
keywordfield (the most common join key type) now use a faster execution path that reduces overhead per joined row.
Together, these make lookup joins more practical for high-volume enrichment workloads.
ES|QL time-series support and approximate queries
This post focuses on the query language and data access features. ES|QL also gains time-series support at GA (including the TS command, PromQL-style functions, and rate/changes/cumulative_sum) and approximate queries for faster exploratory analysis on large datasets, covered in their own posts.
ES|QL roadmap: materialized views, WHERE subqueries, Kibana CRUD UI
ES|QL development continues at pace. On the roadmap:
- Materialized views: pre-compute once, read instantly. For expensive aggregations where millisecond freshness isn't required, materialized views will trade recency for speed.
- WHERE subqueries:
WHERE field IN (FROM other_index | ...)and other correlated forms, extending the composition model from FROM into filtering. - Kibana CRUD UI for views: a "Save as View" experience in Discover, bringing view management out of Dev Tools.
- Native flattened field support: eliminating the
JSON_EXTRACTon_sourceworkaround for the most common schema-on-read use case.
Try it
All headline features are available in Elasticsearch as Tech Preview (views are not yet available in Serverless). Timezone support, FIRST/LAST/EARLIEST/LATEST, VALUES, MV_EXPAND, and FORK are generally available. Try them in Kibana Dev Tools or Discover.
We'd love your feedback. If you hit an issue or have a feature request, file a GitHub issue with the ES|QL label.
ES|QL subqueries, logical views, JSON extraction, unmapped field access, LIMIT BY, SPARKLINE, MV_UNION, MV_DIFFERENCE, and MV_INTERSECTS are Tech Preview features. Tech Preview features are subject to change and are not covered by the support SLA of GA features. The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
Zugehörige Inhalte

9. Juli 2026
Why Elasticsearch is becoming a columnar database
Elasticsearch is becoming a first-class columnar database. Columnar Mode ships in 9.5, storing data once alongside the existing modes and cutting storage footprints while speeding up analytical queries.

How to build search analytics on Elastic using OpenTelemetry, no extra pipeline required
How to instrument your search application to use modern Open Telemetry standard to drive insights in to your search and users.
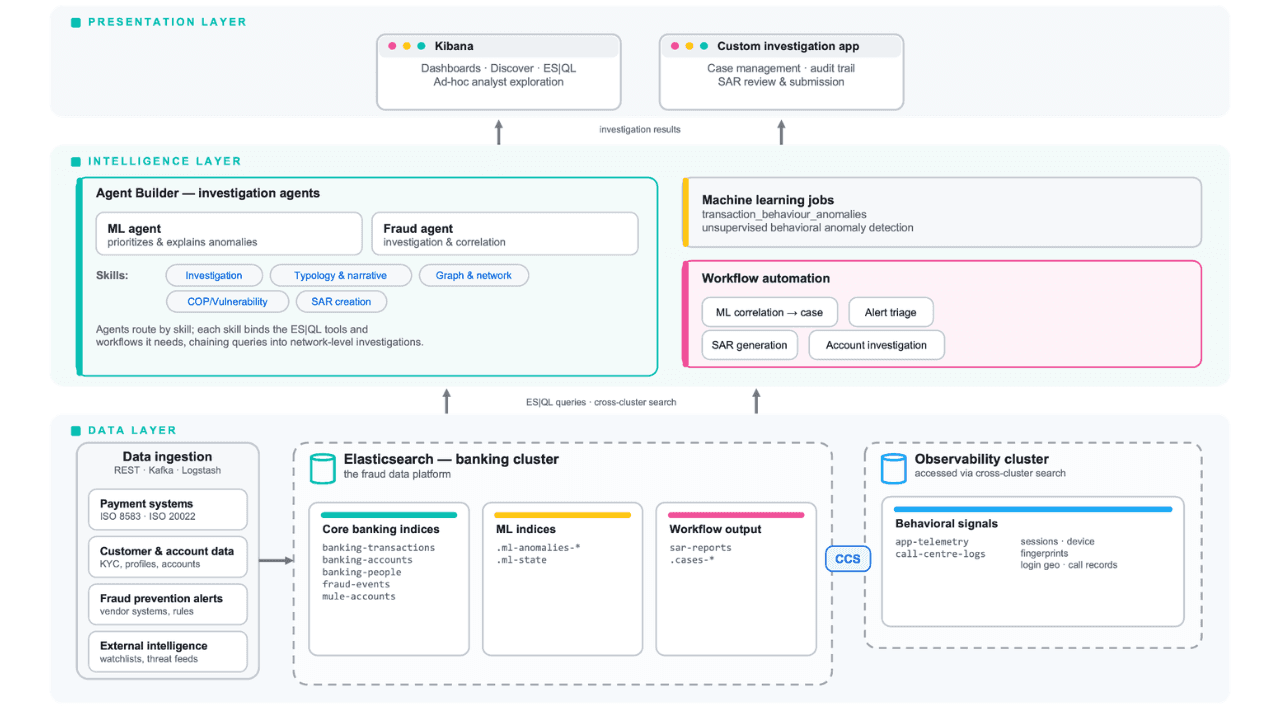
Follow the money: tracing laundering networks with ES|QL and cross-cluster search
The data model, cross-cluster architecture and five ES|QL queries that power mule detection and laundering network tracing, built from infrastructure most financial institutions already run.

1. Juli 2026
One command. Natural language. Your Elasticsearch data, straight to the terminal.
Query your Elasticsearch data from the terminal in plain English. The official Elastic GitHub Copilot CLI plugin generates and runs ES|QL queries against your cluster. No Kibana, no manual syntax.

30. Juni 2026
Building a multilingual voice agent with Elastic Agent Builder & Sarvam AI
A working demo combining Sarvam AI speech with Elastic Agent Builder: identity verification, per-customer ES|QL queries, and mid-call language switching across 22 Indian languages without multilingual indices.