Wir stellen AutoOps für selbstverwaltete Elasticsearch-Umgebungen (On-Prem oder privat gehostet) vor, das die Verwaltung von Elasticsearch vereinfacht. Anstelle einer traditionellen technischen Funktionsübersicht zeigt dieser Blog den Mehrwert, die Einrichtung und die damit verbundenen Erkenntnisse aus der Perspektive eines DevOps-Ingenieurs auf, da sich der wahre Wert von AutoOps am besten im Rahmen des Tagesgeschäfts beim Verwalten von Elasticsearch im großen Maßstab zeigt.
Kapitel 1: Hintergrund – Die Komplexität der Selbstverwaltung im großen Maßstab
Der Betrieb einer groß angelegten, selbstverwalteten Datenplattform kann komplex sein.
Einen Moment lang werden die Anfragen blitzschnell beantwortet. Im nächsten Schritt kommt es zu Verzögerungen bei der Datenaufnahme und zu einem sprunghaften Anstieg der Lagerkosten. Es ist im Grunde wie die Leitung eines Zoos, nur dass die Tiere dich um 3 Uhr morgens anrufen können.
Meine Umgebung ist nicht anders: mehrere Cluster, intensive clusterübergreifende Suche (CCS) und Hunderte von Benutzern aus verschiedenen Abteilungen.
Wir nutzen Stack Monitoring für den täglichen Betrieb. Es liefert zwar Grafiken und Kennzahlen, aber es bedarf immer noch viel Fachwissen und Zeit, um die Zusammenhänge herzustellen. Die Diagnose von Engpässen oder die Entscheidung, wann Shard-Strategien angepasst werden müssen, ist nach wie vor ein manueller und fehleranfälliger Prozess. In vielen Fällen bleiben Probleme unbemerkt, bis sie zu einem Ausfall, einem Leistungsabfall oder einem unerwarteten Anstieg des Speicherbedarfs führen.
Kapitel 2: AutoOps entdecken
Dann kam die Ankündigung: AutoOps ist jetzt auch für selbstverwaltete Cluster verfügbar – sowohl für On-Premise- als auch für privat gehostete Umgebungen.
AutoOps unterstützt Benutzer von Elastic Cloud seit langem bei der effizienteren Verwaltung von Deployments. Nun stehen dieselben Vorteile auch selbstverwalteten Clustern (ECK, ECE oder eigenständig) zur Verfügung, die in lokalen oder privaten Cloud-Umgebungen ausgeführt werden – kostenlos und unabhängig von Ihrer Lizenzstufe.
Das Angebot von AutoOps ist verlockend:
- Echtzeit-Problemerkennung für Engpässe bei der Datenerfassung, unausgeglichene Shards, langsame Abfragen und mehr
- Konkrete Handlungsempfehlungen, die auf die Konfiguration Ihres Clusters zugeschnitten sind
- Erkenntnisse zur Ressourcenoptimierung zur Steigerung der Effizienz und Reduzierung von Verschwendung
- Einfache Einrichtung durch Installation eines schlanken Agenten – keine zusätzliche Infrastruktur erforderlich
Ehrlich gesagt, alles, was „keine zusätzliche Infrastruktur“ versprach, hatte meine volle Aufmerksamkeit.
Kapitel 3: Einrichtung in 5 Minuten (ja, wirklich)
Ich habe mir den Nachmittag freigehalten, mich mit Kaffee eingedeckt und mich auf einen langen Aufbau eingestellt. Zu meiner Überraschung dauerte es nur fünf Minuten:
- Ich habe mich in mein Elastic Cloud-Kontoeingeloggt.
- Entscheidung über die Ausführungsmethode der Agenten: Elastic Cloud Kubernetes (ECK), Kubernetes, Docker oder Linux.
- Die Cluster-URL wurde eingegeben.
- Es musste nur ein einziger Befehl ausgeführt werden, der einen schlanken Metricbeat-Agenten installierte.
Das war’s. Mein Cluster war verbunden.
Es müssen keine dedizierten Überwachungscluster bereitgestellt werden. Und vor allem sendet AutoOps nur Metriken, was bedeutet, dass die Daten meines Unternehmens in meiner selbstverwalteten Umgebung verbleiben.

Schritt 1: Registrieren Sie sich bei Elastic Cloud
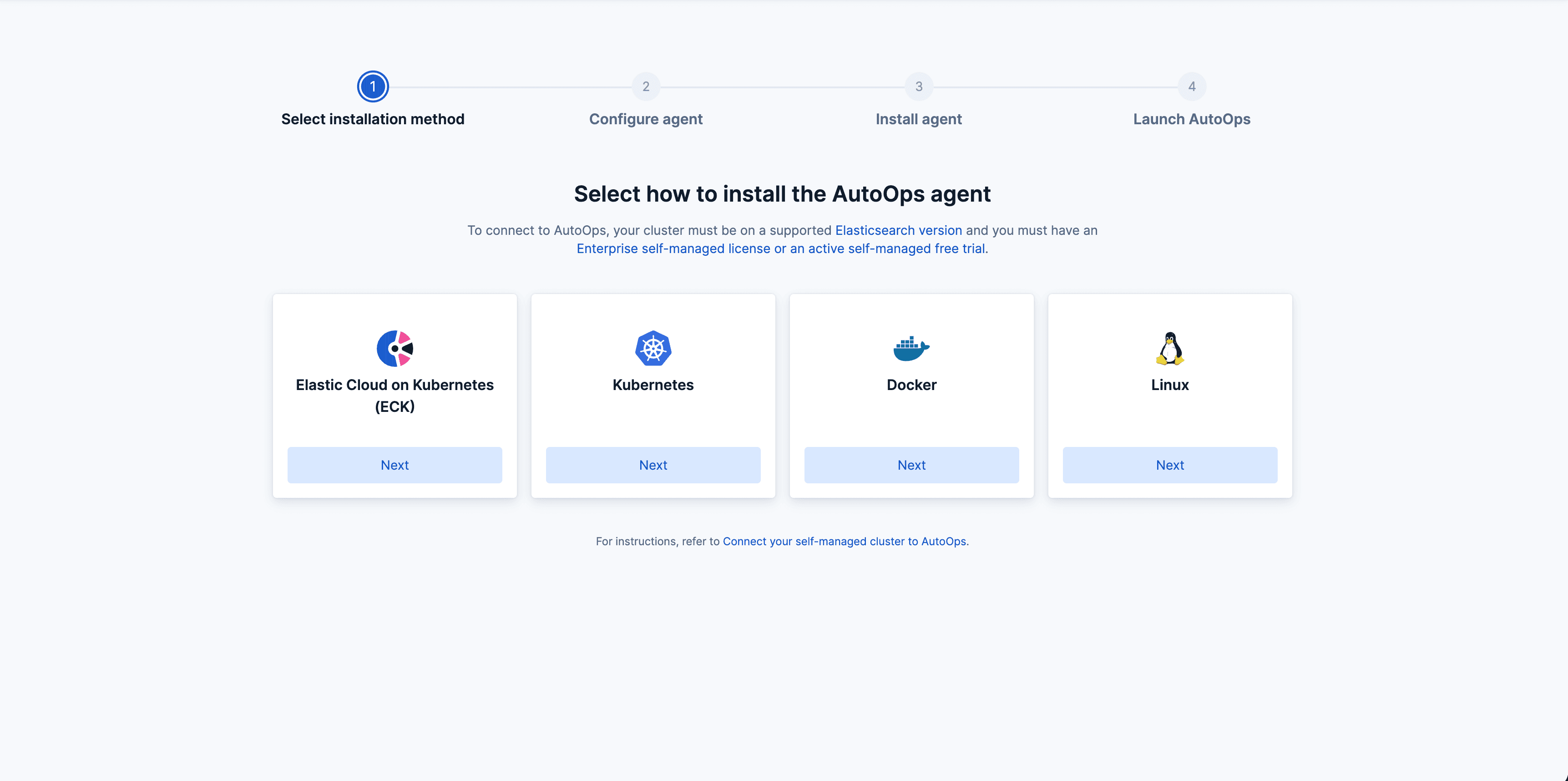
Schritt 2: Wählen Sie aus, wo der Agent ausgeführt werden soll.
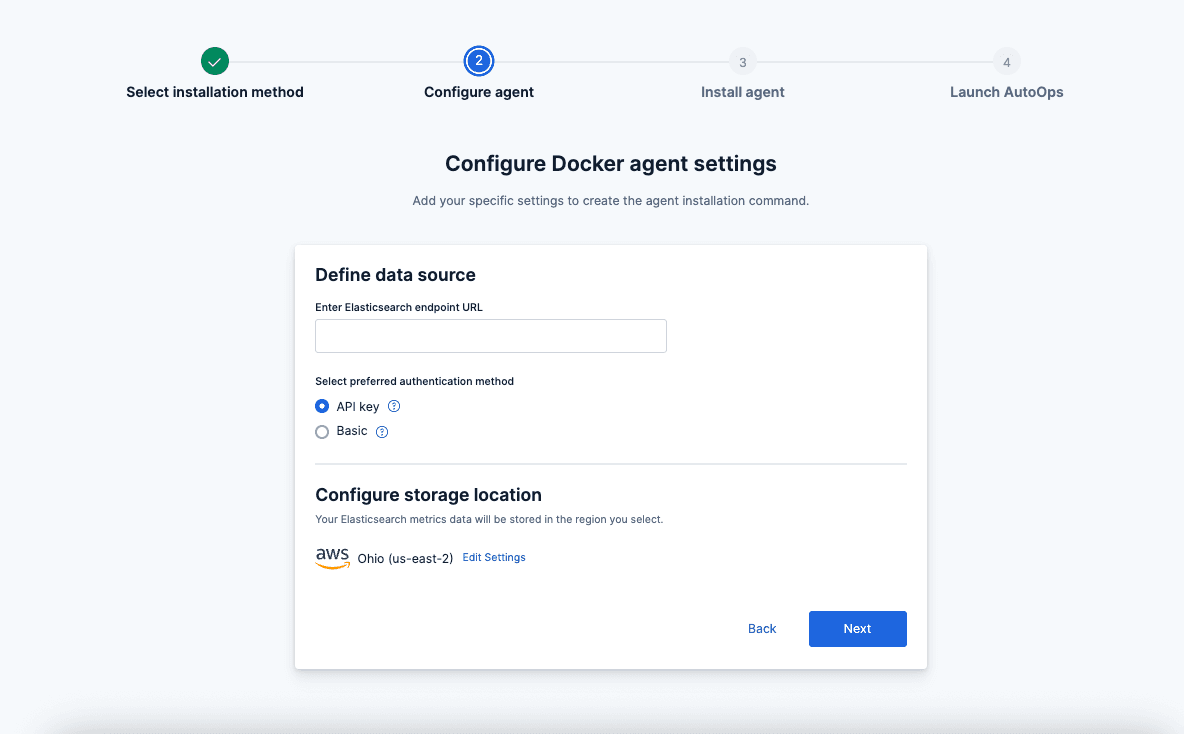
Schritt 3: Geben Sie Ihren Elasticsearch-Endpunkt und die Authentifizierungsmethode ein.
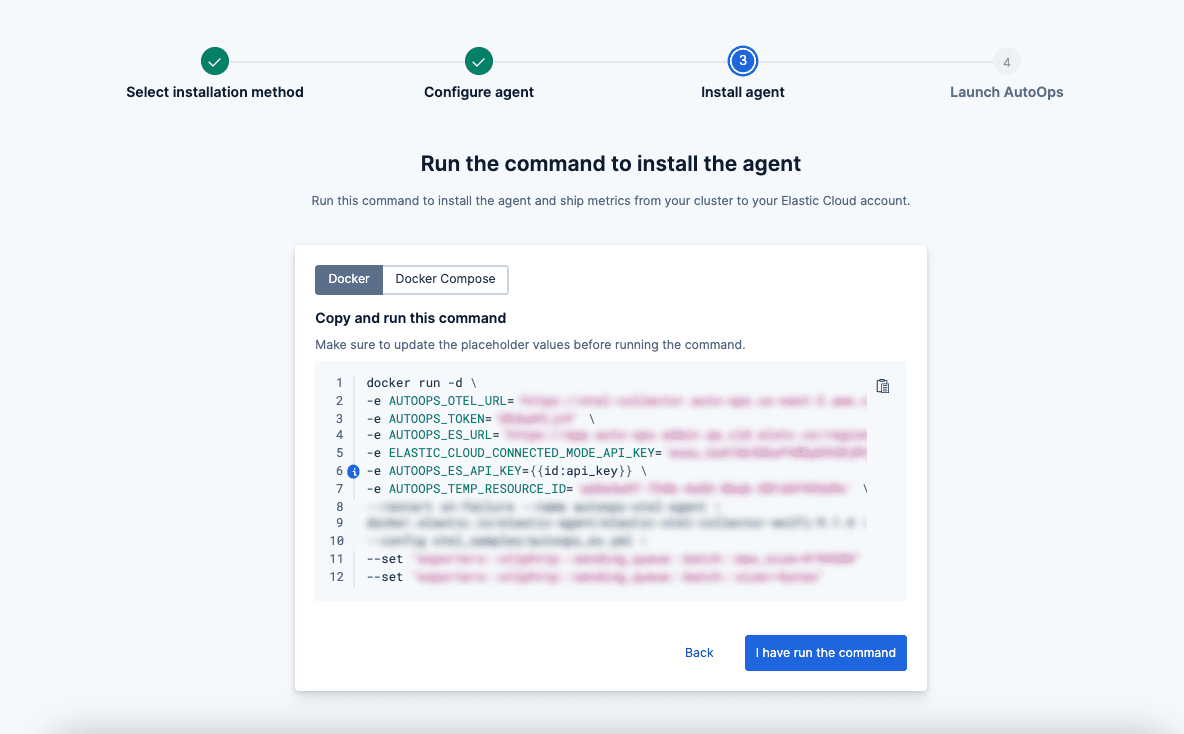
Schritt 4: Einfacher Befehl zur Installation des Agenten
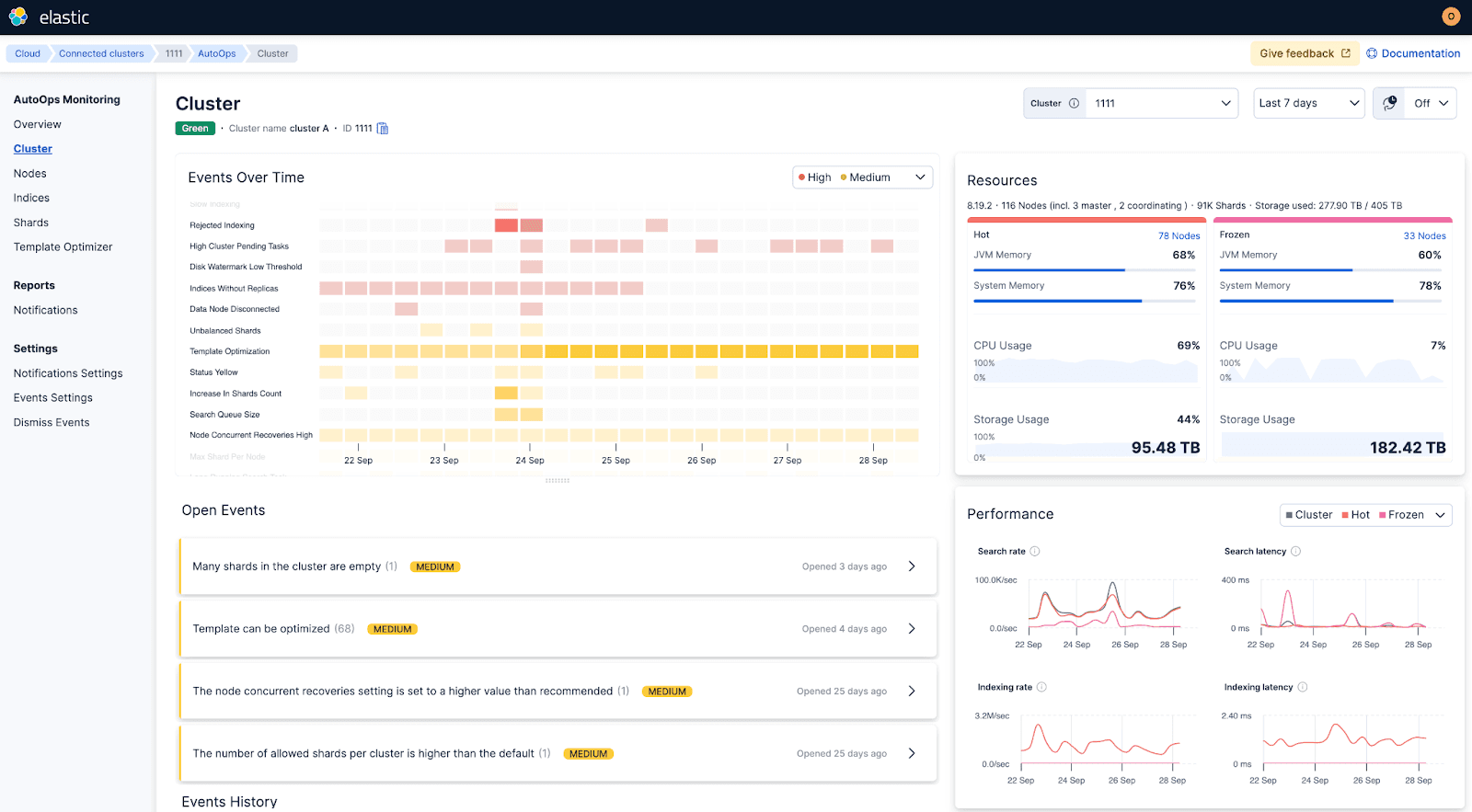
Das war's: Nach wenigen Minuten zeigt AutoOps erste Erkenntnisse an.
Weitere Einzelheiten finden Sie in der AutoOps-Onboarding-Dokumentation und in den FAQ.
Kapitel 4: Erste Erkenntnisse, erste Erfolge
Innerhalb weniger Minuten lieferte AutoOps erste Erkenntnisse, analysierte die Ursachen und gab klare Anweisungen zur Behebung der Probleme.
Zu den Höhepunkten der ersten Woche gehörten:
- Gekennzeichnete Indizes, die keiner ILM-Richtlinie zugeordnet sind und zu groß geworden sind
- Ein Cluster wies drei leere Knoten auf, die von einem früheren Wartungsauftrag übrig geblieben waren.
- Einige Knoten überschritten Wasserzeichen, und bei einigen Indizes fehlten Replikate.
- Ich habe eine fehlerhaft konfigurierte Vorlage erwischt.
- Eine langwierige Suche wurde lokalisiert und der genaue Abbruchbefehl vorgeschlagen.
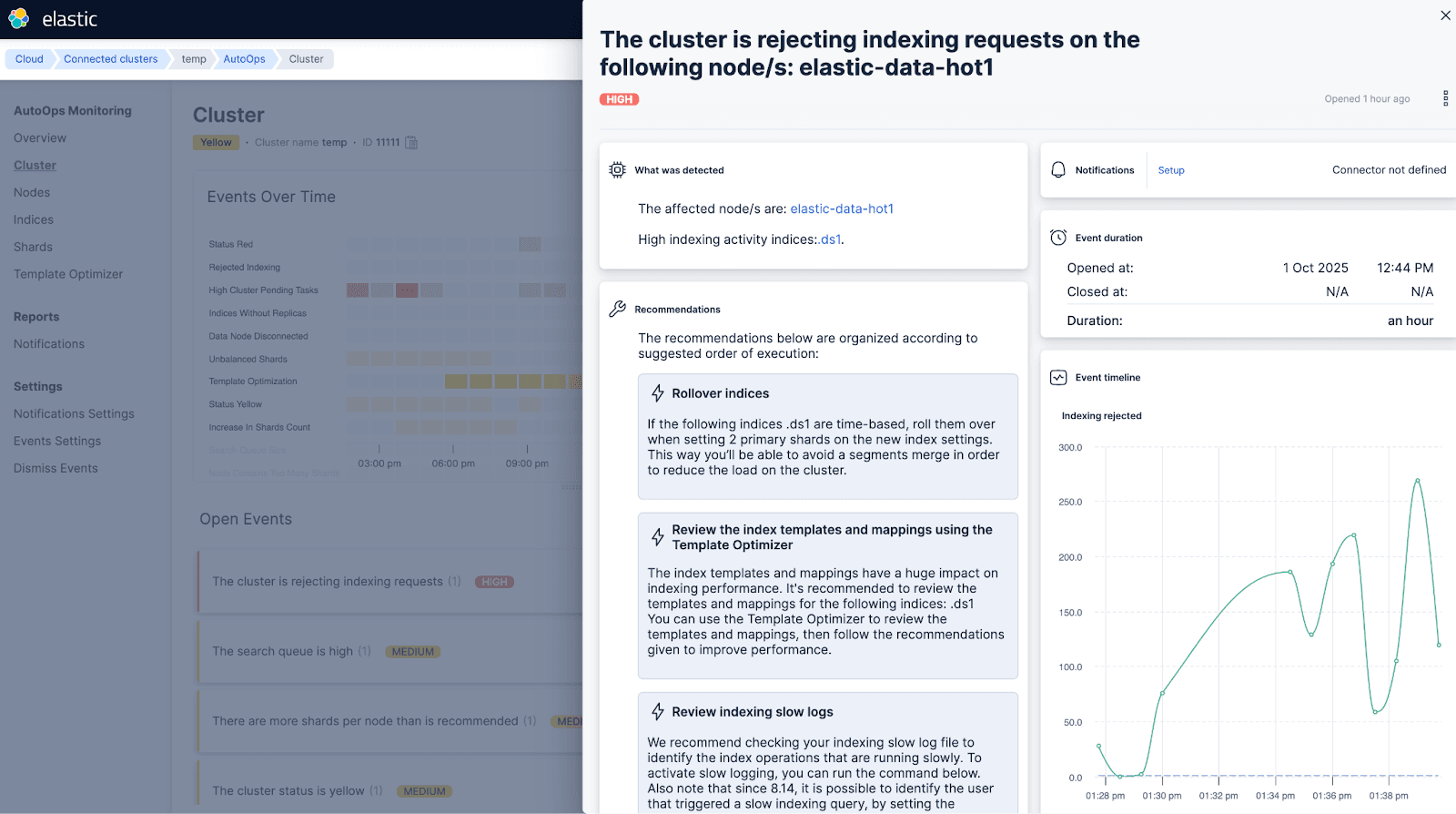
AutoOps hat festgestellt, dass der Cluster die Indizierung ablehnt.
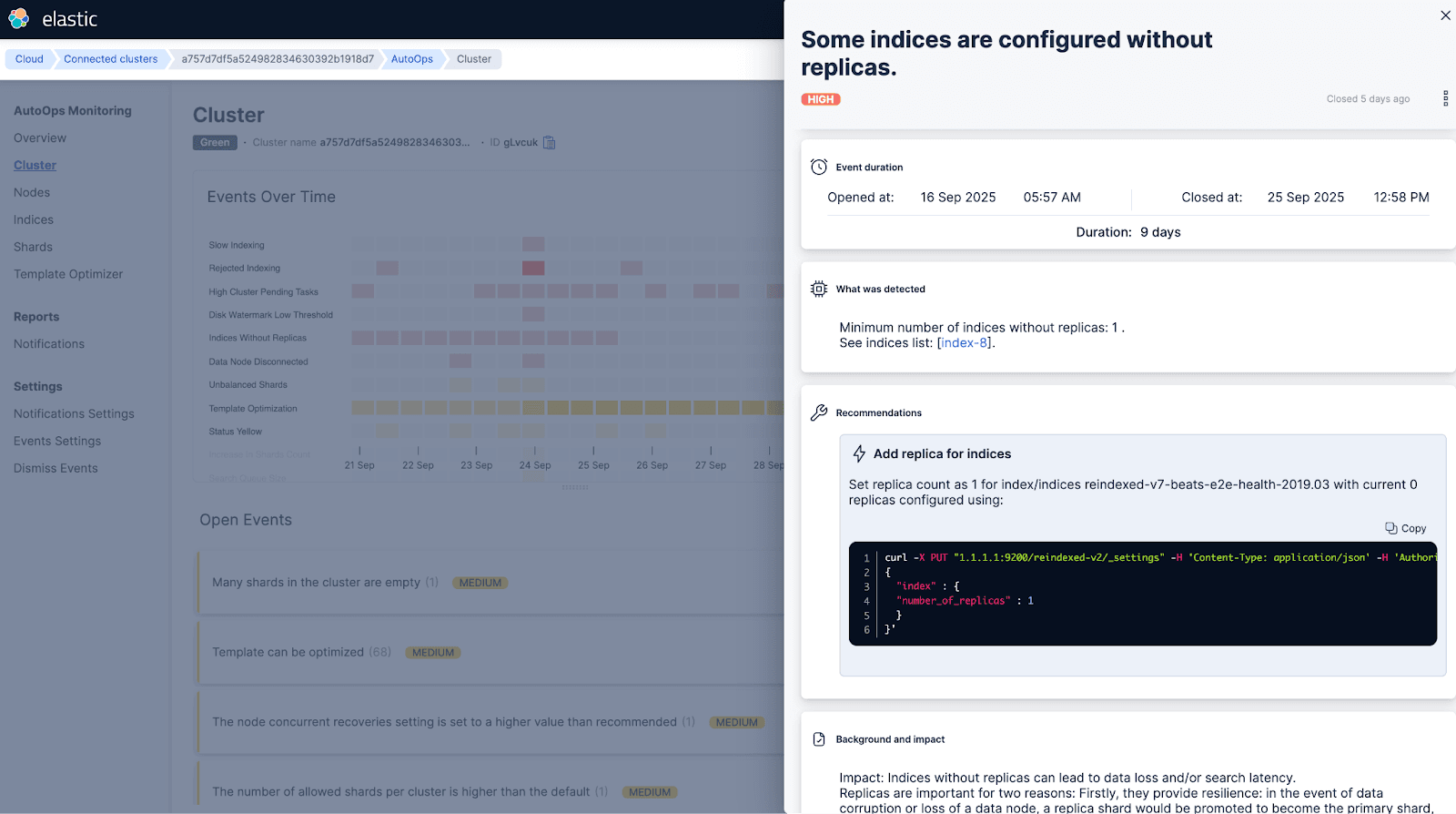
AutoOps hat festgestellt, dass einige Indizes ohne Replik konfiguriert sind.
Vor AutoOps hätten wir diese Probleme mit noch mehr Hardware gelöst. Stattdessen wies AutoOps direkt auf die Ursache hin, und die Behebung dauerte nur wenige Minuten.
Ausnahmsweise zeigte mir ein Überwachungssystem nicht nur Diagramme an, sondern erklärte mir auch, wie ich das Problem lösen konnte. Ich fragte mich, ob AutoOps auch mein Heim-WLAN diagnostizieren und mich endlich von der Rolle der IT-Abteilung für meine Familie befreien könnte…
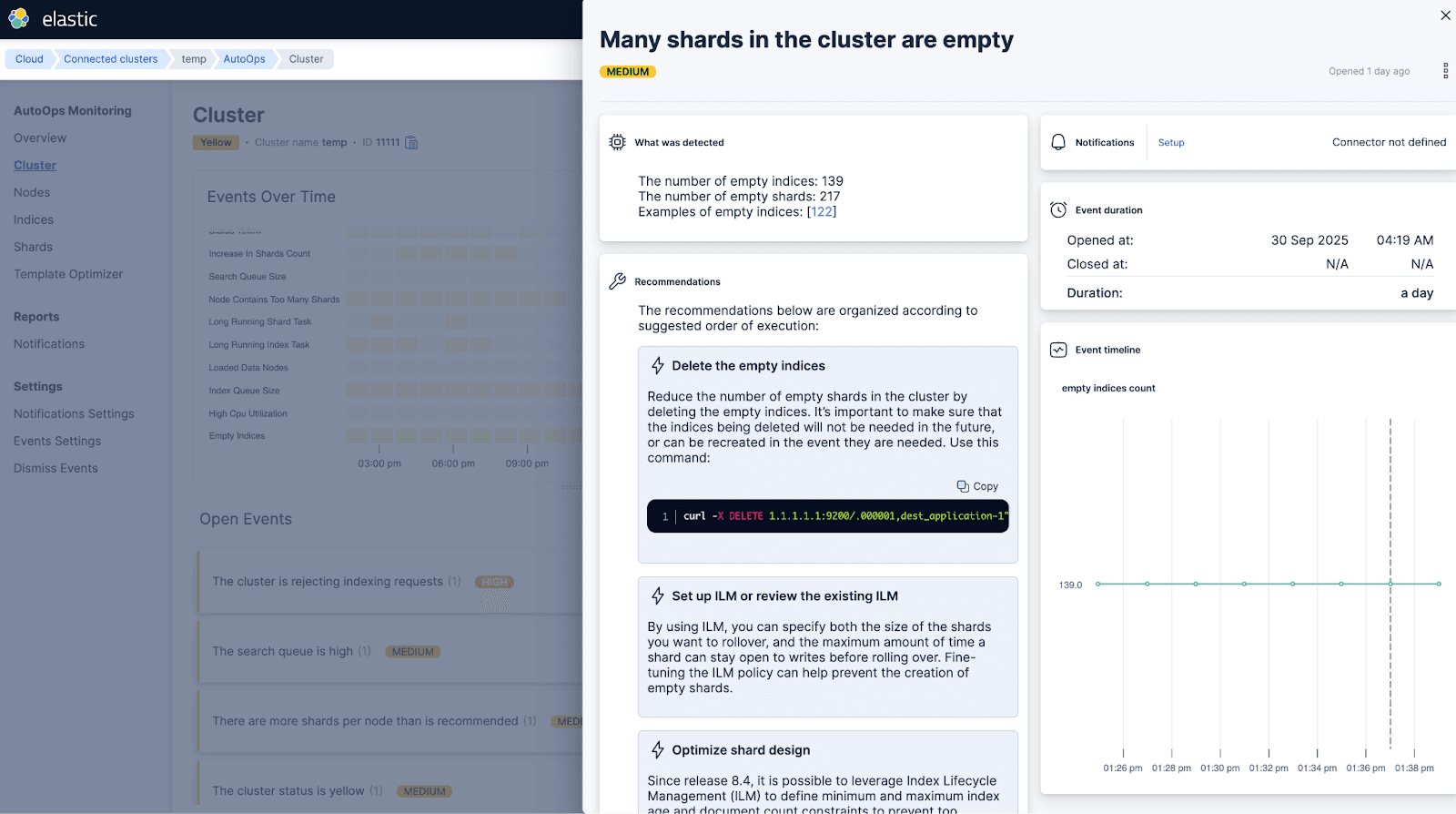
AutoOps überwachte die Shard-Größen und gab eine Warnung aus, wenn viele Shards leer waren.
Kapitel 5: Unterstützung, die sieht, was ich sehe
Als ich zum ersten Mal einen Supportfall eröffnete, erkannte ich einen weiteren Vorteil: Die Support-Ingenieure von Elastic konnten genau dieselben Daten und Empfehlungen sehen, die ich mir ansah.
Es wandelte die Unterstützung in eine Zusammenarbeit. Statt eines ständigen Hin und Her mit Support-Tickets fühlte es sich an, als würde man mit einem Teamkollegen zusammenarbeiten, der Elasticsearch in- und auswendig kennt.
Kapitel 6: Betrieb im großen Maßstab
Vor AutoOps fühlte sich die Skalierung von Elasticsearch wie eine Mischung aus Wissenschaft, Instinkt und Erfahrungswissen an.
Jetzt ist es datengesteuert, mit klarer Transparenz und Handlungsempfehlungen:
- Transparenz der Ressourcennutzung zur Vermeidung von Überdimensionierung
- Intelligentere Shard-Zuweisung und Tiering-Empfehlungen für eine ausgewogene Leistung
- Erkenntnisse zur Indexgrößenbestimmung, die unnötigen Speicherplatz und Hardwarekosten reduzieren
- Schnellere Ursachenanalyse über mehrere Cluster hinweg
Kapitel 7: Der erste von vielen Cloud-verbundenen Diensten
AutoOps ist mehr als ein eigenständiges Tool. Es handelt sich um den ersten Dienst einer neuen Reihe von Cloud Connected Services für selbstverwaltete Kunden. Cloud Connect ermöglicht es selbstverwalteten Clustern, Elastic Cloud-Dienste zu nutzen, ohne den operativen Aufwand für die Installation und Verwaltung dieser Dienste in ihrer eigenen Umgebung tragen zu müssen. Die Funktionen werden automatisch ausgerollt, sodass Teams schneller von Verbesserungen profitieren und die Infrastruktur weniger komplex ist.
Als Nächstes: Elastic Inference Service (EIS).
Abschließende Gedanken
Die Verwaltung groß angelegter, selbstverwalteter Implementierungen muss nicht überfordernd sein.
Und wenn Sie die Abläufe noch einfacher gestalten möchten, können Sie jederzeit einige Workloads in die Elastic Cloud verlagern, egal ob Hosted oder Serverless, um Elasticsearch auf einfachste Weise auszuführen.
Wenn Sie weiterhin selbstverwaltet arbeiten möchten, verbinden Sie einen beliebigen selbstverwalteten Cluster mit AutoOps in Elastic Cloud – für alle Elastic-Lizenzen kostenlos.
TLDR
Der Betrieb großer, selbstverwalteter Elasticsearch-Cluster ist komplex und zeitaufwändig. AutoOps bietet Echtzeit-Problemerkennung, umsetzbare Handlungsempfehlungen und gemeinsame Transparenz mit Elastic Support – ohne dass zusätzliche Infrastruktur verwaltet werden muss. Die Einrichtung dauert nur wenige Minuten, und die Erkenntnisse werden sofort angezeigt.
Zugehörige Inhalte

22. Mai 2026
Kibana reduziert die Dashboard-Ladezeit um bis zu 25 % – hier ist die Polling-Strategie dahinter
Erfahren Sie, wie Kibana durch kontinuierliches Polling und browserseitige HTTP/2-Erkennung die Ladezeiten des Dashboards um bis zu 25 % verkürzt und dabei automatisch auf HTTP/1 zurückgreift.

Beschreiben statt zeichnen: KI-native Kibana-Dashboards über MCP und ES|QL
Vom Prompt zum Dashboard. Erfahren Sie, wie Sie Kibana-Dashboards in natürlicher Sprache mit example-mcp-dashbuilder erstellen: eine Open-Source-MCP-Anwendung, die ES|QL-Abfragen schreibt, interaktive Diagramme erstellt und voll funktionsfähige Dashboards direkt in Kibana exportiert.
18. Mai 2026
Eine Abfrage, mehrere Elasticsearch Serverless-Projekte: Einführung der projektübergreifenden Suche
Die projektübergreifende Suche in Elastic Cloud Serverless ermöglicht es Ihnen, Daten aus isolierten Projekten mit einer einzigen Elasticsearch- oder ES|QL-Anfrage abzufragen: keine Duplizierung, kein Netzwerk-Peering und keine Kosten für ausgehende Daten durch das Kopieren von Protokollen.

18. Mai 2026
Agentische KI-Suche mit deterministischen Leitplanken in Elasticsearch zur sicheren Ausführung von Abfragen
Agentische KI-Suchsysteme versagen häufig, wenn LLMs Abfragen direkt generieren. Erfahren Sie, wie deterministische Leitplanken und eine Steuerungsebenenarchitektur eine sichere, zuverlässige und kontrollierte Abfrageausführung mit Elasticsearch ermöglichen.

15. Mai 2026
Elastic Cloud on Kubernetes, vereinfacht: Zonenbewusstsein, Neustarts und mTLS
ECK 3.4 reduziert zonenbewusste Hochverfügbarkeit von 40 Zeilen YAML auf ein Feld, fügt deklarative rollierende Neustarts über Annotation hinzu und verbindet Kibana-Elasticsearch mTLS automatisch.