Elasticsearch verfügt über native Integrationen mit den branchenführenden Gen-AI-Tools und -Anbietern. Sehen Sie sich unsere Webinare zu den Themen „RAG-Grundlagen“ oder zum „Erstellen produktionsreifer Apps“ mit der Elastic-Vektordatenbank an.
Um die besten Suchlösungen für Ihren Anwendungsfall zu entwickeln, starten Sie jetzt eine kostenlose Cloud-Testversion oder testen Sie Elastic auf Ihrem lokalen Rechner.
Die LangGraph Retrieval Agent-Vorlage ist ein von LangChain entwickeltes Starterprojekt, das die Erstellung abrufbasierter Frage-Antwort-Systeme mit LangGraph in LangGraph Studio erleichtern soll. Diese Vorlage ist für die nahtlose Integration mit Elasticsearch vorkonfiguriert und ermöglicht Entwicklern die schnelle Erstellung von Agenten, die Dokumente effizient indizieren und abrufen können.
In diesem Blog geht es um das Ausführen und Anpassen der LangChain Retrieval Agent-Vorlage mit LangGraph Studio und LangGraph CLI. Die Vorlage bietet ein Framework zum Erstellen von Retrieval-Augmented Generation (RAG)-Anwendungen und nutzt verschiedene Retrieval-Backends wie Elasticsearch.
Wir führen Sie durch die Einrichtung, Konfiguration der Umgebung und effiziente Ausführung der Vorlage mit Elastic, während wir den Agentenfluss anpassen.
Voraussetzungen
Bevor Sie fortfahren, stellen Sie sicher, dass Folgendes installiert ist:
- Elasticsearch Cloud-Bereitstellung oder lokale Elasticsearch-Bereitstellung (oder erstellen Sie eine 14-tägige kostenlose Testversion auf Elastic Cloud) – Version 8.0.0 oder höher
- Python 3.9+
- Zugriff auf einen LLM-Anbieter wie Cohere (in diesem Handbuch verwendet), OpenAI oder Anthropic/Claude
Erstellen der LangGraph-App
1. Installieren Sie die LangGraph CLI
2. Erstellen Sie eine LangGraph-App aus der Retrieval-Agent-Vorlage
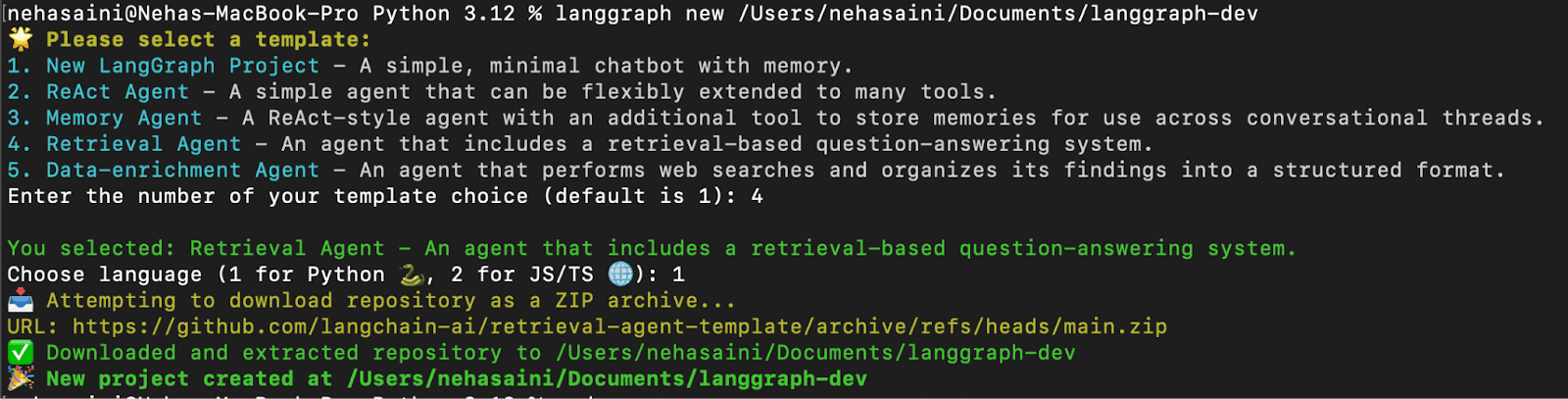
Ihnen wird ein interaktives Menü angezeigt, in dem Sie aus einer Liste verfügbarer Vorlagen auswählen können. Wählen Sie 4 für Retrieval Agent und 1 für Python, wie unten gezeigt:
- Fehlerbehebung: Wenn der Fehler „urllib.error.URLError: <urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1000)>“ auftritt, „
Führen Sie den Python-Befehl „Zertifikat installieren“ aus, um das Problem wie unten gezeigt zu beheben.

3. Abhängigkeiten installieren
Erstellen Sie im Stammverzeichnis Ihrer neuen LangGraph-App eine virtuelle Umgebung und installieren Sie die Abhängigkeiten im Modus edit , damit Ihre lokalen Änderungen vom Server verwendet werden:
Einrichten der Umgebung
1. Erstellen Sie eine .environment-Umgebung Datei
Die Datei .env enthält API-Schlüssel und Konfigurationen, damit die App eine Verbindung mit dem von Ihnen gewählten LLM- und Abrufanbieter herstellen kann. Generieren Sie eine neue .env -Datei, indem Sie die Beispielkonfiguration duplizieren:
2. Konfigurieren Sie die .env-Datei. Datei
Die Datei .env enthält eine Reihe von Standardkonfigurationen. Sie können es aktualisieren, indem Sie basierend auf Ihrem Setup die erforderlichen API-Schlüssel und -Werte hinzufügen. Alle Schlüssel, die für Ihren Anwendungsfall nicht relevant sind, können unverändert bleiben oder entfernt werden.
- Beispieldatei
.env(unter Verwendung von Elastic Cloud und Cohere)
Nachfolgend finden Sie eine Beispielkonfiguration .env für die Verwendung von Elastic Cloud als Abrufanbieter und Cohere als LLM, wie in diesem Blog gezeigt:
Hinweis: In dieser Anleitung wird Cohere sowohl für die Antwortgenerierung als auch für die Einbettung verwendet. Sie können je nach Anwendungsfall jedoch auch andere LLM-Anbieter wie OpenAI, Claude oder sogar ein lokales LLM-Modell verwenden. Stellen Sie sicher, dass alle .env Schlüssel, die Sie verwenden möchten, in der Datei vorhanden und korrekt festgelegt sind.
3. Aktualisieren Sie die Konfigurationsdatei -configuration.py
Nachdem Sie Ihre .env -Datei mit den entsprechenden API-Schlüsseln eingerichtet haben, besteht der nächste Schritt darin, die Standardmodellkonfiguration Ihrer Anwendung zu aktualisieren. Durch die Aktualisierung der Konfiguration wird sichergestellt, dass das System die Dienste und Modelle verwendet, die Sie in Ihrer .env -Datei angegeben haben.
Navigieren Sie zur Konfigurationsdatei:
Die Datei configuration.py enthält die Standardmodelleinstellungen, die vom Abrufagenten für drei Hauptaufgaben verwendet werden:
- Einbettungsmodell – konvertiert Dokumente in Vektordarstellungen
- Abfragemodell – verarbeitet die Abfrage des Benutzers in einen Vektor
- Antwortmodell – generiert die endgültige Antwort
Standardmäßig verwendet der Code Modelle von OpenAI (z. B. openai/text-embedding-3-small) und Anthropic (z. anthropic/claude-3-5-sonnet-20240620 and anthropic/claude-3-haiku-20240307).
In diesem Blog wechseln wir zur Verwendung von Cohere-Modellen. Wenn Sie bereits OpenAI oder Anthropic verwenden, sind keine Änderungen erforderlich.
Beispieländerungen (mit Cohere):
Öffnen Sie configuration.py und ändern Sie die Modellstandards wie unten gezeigt:
Ausführen des Abrufagenten mit der LangGraph-Befehlszeilenschnittstelle
1. Starten Sie den LangGraph-Server
Dadurch wird der LangGraph-API-Server lokal gestartet. Wenn dies erfolgreich ausgeführt wird, sollten Sie etwa Folgendes sehen:
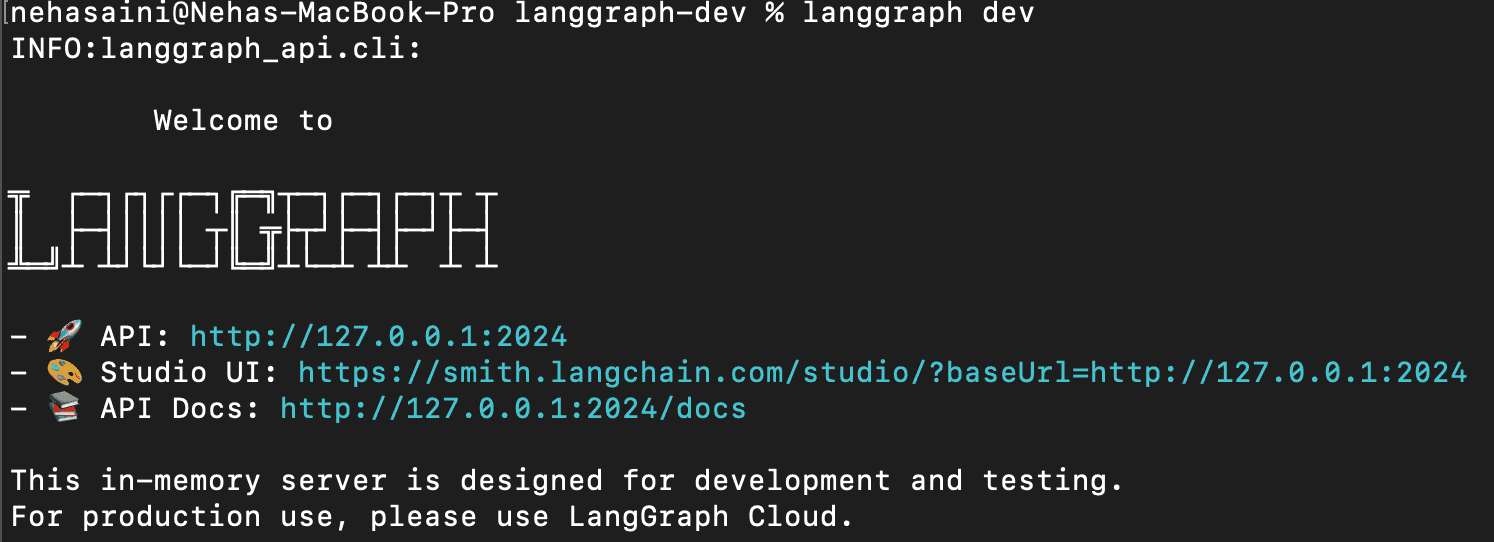
Öffnen Sie die URL der Studio-Benutzeroberfläche.
Es stehen zwei Diagramme zur Verfügung:
- Retrieval-Graph: Ruft Daten aus Elasticsearch ab und beantwortet die Anfrage mithilfe eines LLM.
- Indexer-Graph: Indiziert Dokumente in Elasticsearch und generiert Einbettungen mithilfe eines LLM.

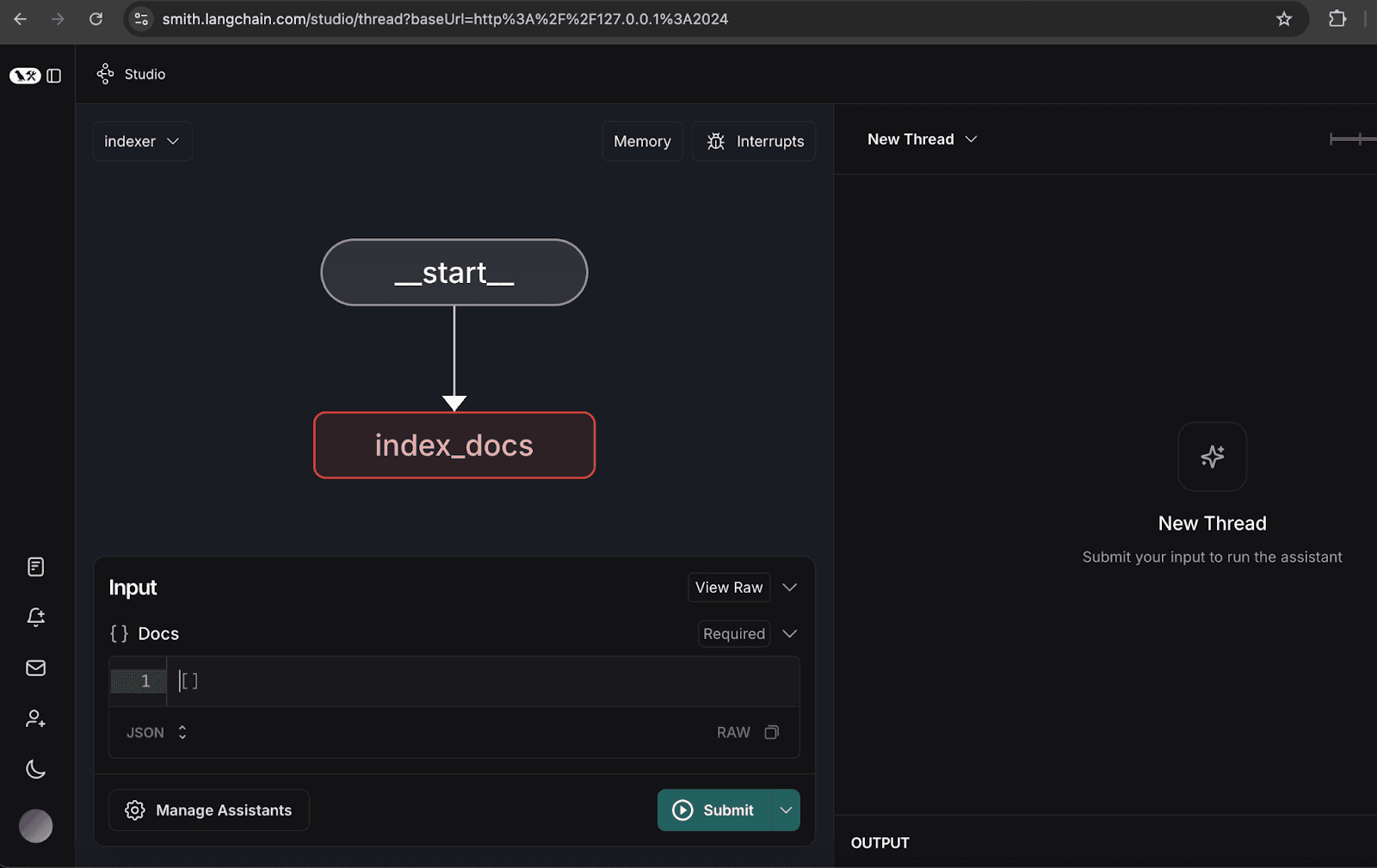
2. Konfigurieren des Indexergraphen
- Öffnen Sie den Indexergraphen.
- Klicken Sie auf „Assistenten verwalten“.
- Klicken Sie auf „Neuen Assistenten hinzufügen“, geben Sie die Benutzerdaten wie angegeben ein und schließen Sie anschließend das Fenster.


3. Beispieldokumente indexieren
- Indizieren Sie die folgenden Beispieldokumente, die einen hypothetischen Quartalsbericht für die Organisation NoveTech darstellen:
Sobald die Dokumente indiziert sind, wird im Thread eine Löschmeldung angezeigt, wie unten dargestellt.

4. Ausführen des Abrufgraphen
- Wechseln Sie zum Abrufgraphen.
- Geben Sie die folgende Suchanfrage ein:

Das System gibt relevante Dokumente zurück und liefert eine genaue Antwort basierend auf den indizierten Daten.
Passen Sie den Abrufagenten an.
Um das Benutzererlebnis zu verbessern, führen wir einen Anpassungsschritt im Abrufgraphen ein, um die nächsten drei Fragen vorherzusagen, die ein Benutzer stellen könnte. Diese Vorhersage basiert auf Folgendem:
- Kontext aus den abgerufenen Dokumenten
- Vorherige Benutzerinteraktionen
- Letzte Benutzerabfrage
Zur Implementierung der Abfragevorhersagefunktion sind die folgenden Codeänderungen erforderlich:
1. Aktualisiere graph.py
- Funktion
predict_queryhinzufügen:
- Ändern Sie die Funktion
respond, um das Objektresponseanstelle der Nachricht zurückzugeben:
- Aktualisieren Sie die Graphstruktur, um einen neuen Knoten und eine neue Kante für predict_query hinzuzufügen:
2. Aktualisiere prompts.py
- Erstelle eine Eingabeaufforderung für eine Vorhersage in
prompts.py:
3. Aktualisieren Sie die Datei configuration.py
- Fügen Sie
predict_next_question_prompthinzu:
4. Aktualisiere state.py
- Fügen Sie die folgenden Attribute hinzu:
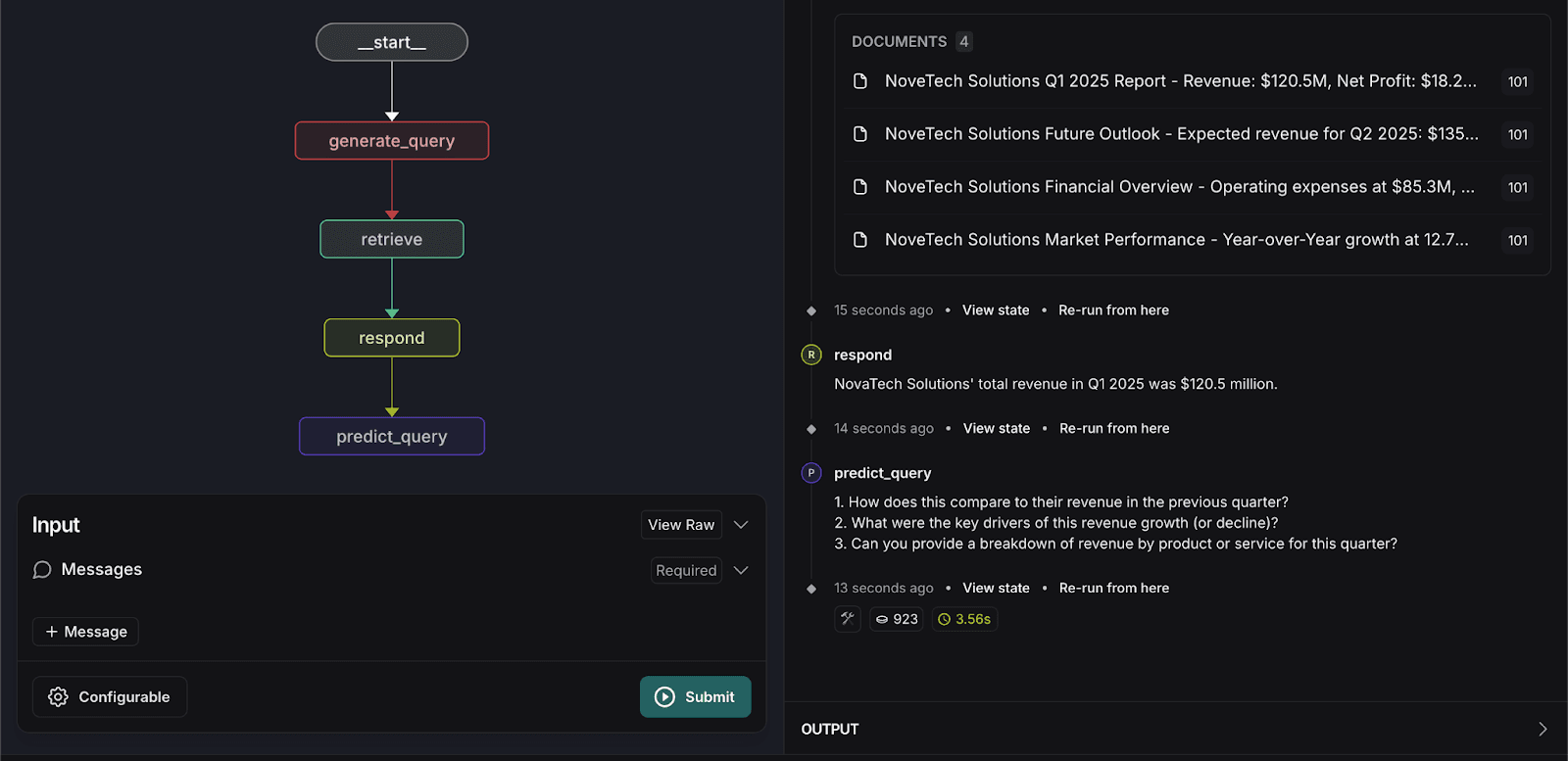
5. Führen Sie den Abrufgraphen erneut aus.
- Geben Sie die folgende Suchanfrage erneut ein:
Das System verarbeitet die Eingabe und sagt drei verwandte Fragen voraus, die Benutzer stellen könnten, wie unten gezeigt.
Fazit
Die Integration der Retrieval Agent-Vorlage in LangGraph Studio und CLI bietet mehrere wichtige Vorteile:
- Beschleunigte Entwicklung: Die Vorlagen- und Visualisierungstools optimieren die Erstellung und das Debuggen von Abruf-Workflows und verkürzen so die Entwicklungszeit.
- Nahtlose Bereitstellung: Integrierte Unterstützung für APIs und automatische Skalierung gewährleistet eine reibungslose Bereitstellung in allen Umgebungen.
- Einfache Updates: Das Ändern von Arbeitsabläufen, das Hinzufügen neuer Funktionen und die Integration zusätzlicher Knoten ist einfach, wodurch der Abrufprozess leichter skaliert und verbessert werden kann.
- Permanenter Speicher: Das System behält Agentenzustände und -wissen bei und verbessert so Konsistenz und Zuverlässigkeit.
- Flexible Workflow-Modellierung: Entwickler können Abruflogik und Kommunikationsregeln für bestimmte Anwendungsfälle anpassen.
- Interaktion und Debugging in Echtzeit: Die Möglichkeit zur Interaktion mit laufenden Agenten ermöglicht effizientes Testen und Problemlösen.
Durch die Nutzung dieser Funktionen können Unternehmen leistungsstarke, effiziente und skalierbare Abrufsysteme erstellen, die die Datenzugänglichkeit und das Benutzererlebnis verbessern.
Der vollständige Quellcode für dieses Projekt ist auf GitHub verfügbar.
Häufige Fragen
Was ist ein RAG-Workflow?
Ein RAG-Workflow (Retrieval-Augmented Generation) ist eine Methode, um einem KI-Modell Zugriff auf Ihre privaten Daten zu gewähren, damit es genaue, faktenbasierte Antworten liefern kann, anstatt „Halluzinationen“ zu erzeugen.
Warum sollte man Elasticsearch als Datenbank für einen LangGraph-Agenten verwenden?
Elasticsearch fungiert als „Langzeitspeicher“ für den Agenten. Anders als eine Standarddatenbank ist sie für die hybride Suche konzipiert – die Kombination von Vektorsuche (Bedeutungserkenntnis) und Stichwortsuche (Auffinden exakter Begriffe). Dadurch wird sichergestellt, dass Elasticsearch, egal ob Sie nach „Q1-Umsatz“ oder „Finanzwachstum“ fragen, die relevantesten Dokumente für LangGraph zur Verarbeitung bereitstellt.
Kann ich mit der LangGraph Retrieval Agent Template ein Mehrbenutzersystem erstellen?
Ja. Der Artikel veranschaulicht dies anhand der Indexer-Graph-Konfiguration unter Verwendung einer Benutzer-ID (wie "101"). Dies ermöglicht es Ihnen, Dokumente bestimmten Eigentümern zuzuordnen, sodass der Abrufagent nur die Informationen findet, zu deren Anzeige ein bestimmter Benutzer berechtigt ist.
Zugehörige Inhalte

Beschreiben statt zeichnen: KI-native Kibana-Dashboards über MCP und ES|QL
Vom Prompt zum Dashboard. Erfahren Sie, wie Sie Kibana-Dashboards in natürlicher Sprache mit example-mcp-dashbuilder erstellen: eine Open-Source-MCP-Anwendung, die ES|QL-Abfragen schreibt, interaktive Diagramme erstellt und voll funktionsfähige Dashboards direkt in Kibana exportiert.

13. März 2026
Entitätsauflösung mit Elasticsearch, Teil 4: Die ultimative Herausforderung
Lösung und Bewertung von Herausforderungen bei der Entitätsauflösung in einem äußerst vielfältigen Datensatz zur „ultimativen Herausforderung“, der entwickelt wurde, um Abkürzungen zu verhindern.

26. Februar 2026
Entitätsauflösung mit Elasticsearch & LLMs, Teil 2: Abgleich von Entitäten mit LLM-Bewertung und semantischer Suche
Verwendung semantischer Suche und transparenter LLM-Bewertung zur Entitätsauflösung in Elasticsearch.

5. Januar 2026
Erstellung von Human-in-the-Loop-Agenten mit LangGraph und Elasticsearch
Erfahren Sie, wie Sie mit LangGraph und Elasticsearch Human-in-the-Loop-Agenten erstellen, die Menschen in den Entscheidungsprozess einbeziehen, um kontextuelle Lücken zu schließen und Tool-Aufrufe vor ihrer Ausführung zu überprüfen.

2. Januar 2026
Automatisierung des Log-Parsing in Streams mit ML
Erfahren Sie, wie ein hybrider ML-Ansatz durch Automatisierungsexperimente mit Log-Format-Fingerprinting in Streams eine Genauigkeit von 94 % beim Log-Parsing und 91 % bei der Log-Partitionierung erreicht hat.