Try out vector search for yourself using this self-paced hands-on learning for Search AI. You can start a free cloud trial or try Elastic on your local machine now.
We’re improving the ingestion speed of vectors in Elasticsearch. Now, in Elastic Cloud Serverless and in v9.3, you can send your vectors to Elasticsearch encoded as Base64 strings, which will provide immediate benefits to your ingestion pipeline.
This change reduces the overhead of parsing vectors in JSON by an order of magnitude, which translates to almost a 100% improvement on indexing throughput for DiskBBQ and around 20% improvement for hierarchical navigable small world (HNSW) workloads. In this blog, we’ll take a closer look at Base64-encoded strings and the improvements it brings to vector ingestion.
What’s the problem?
At Elastic, we’re always looking for ways to improve our vector search capabilities, whether that’s enhancing existing storage formats or introducing new ones. Recently, for example, we added a new disk-friendly storage format called DiskBBQ and enabled vector indexing with NVIDIA cuVS.
In both cases, we expected to see major gains in ingestion speed. However, once these changes were fully integrated into Elasticsearch, the improvements weren’t as large as we had hoped. A flamegraph of the ingestion process made the issue clear: JSON parsing had become one of the main bottlenecks.

Parsing JSON requires walking through every element in the arrays and converting numbers from text format into 32-bit floating-point values, which is very expensive.
Why Base64-encoded strings?
The most efficient way to parse vectors is directly from their binary representation, where each element uses a 32-bit floating-point value. However, JSON is a text-based format, and the way to include binary data in it is by using Base64-encoded strings. Base64 is just a binary-to-text encoding schema.
We can now send vectors encoded as Base64 strings:
Is it worth it? Our benchmarks suggest yes. When parsing 1,000 JSON documents, using Base64 encoded strings instead of float arrays resulted in performance improvements of more than an order of magnitude, at the cost of a small encode/decode trade-off (client-side Base64 encoding and a temporary byte array on the server for decoding) in exchange for eliminating expensive per-element numeric parsing.
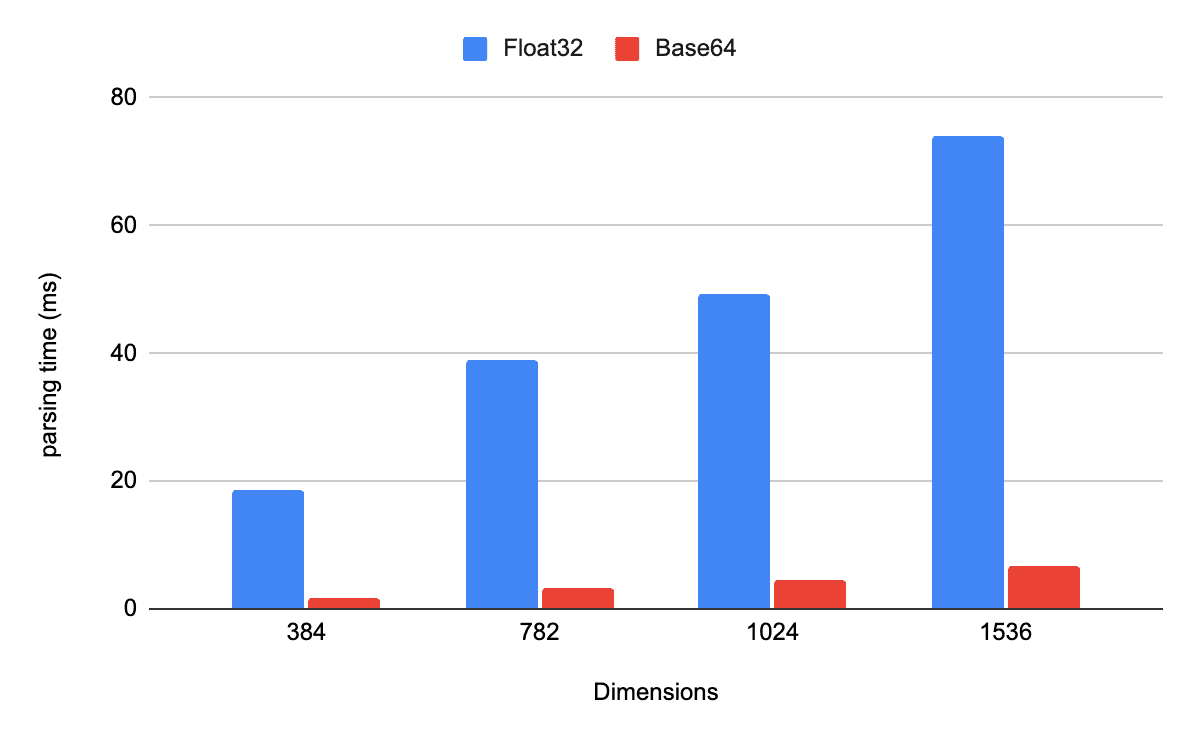
Give me some ingestion numbers
We can see these improvements in practice when running the so_vector rally track with the different approaches. The actual gains depend on how fast indexing is for each storage format. For bbq_disk, indexing throughput increases by about 100%, while for bbq_hnsw, the improvement is closer to 20%, since indexing is inherently slower there.
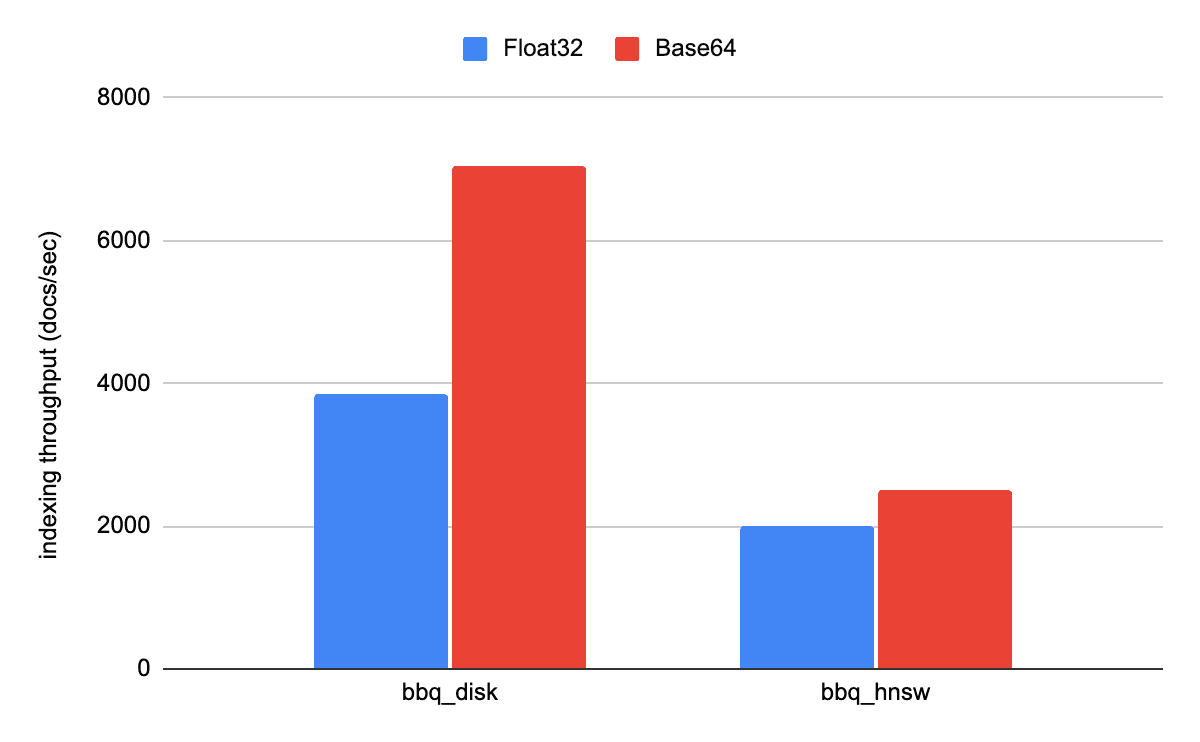
Starting with Elasticsearch v9.2, vectors are excluded from _source by default and are stored internally as 32-bit floating-point values. This behavior also applies to Base64-encoded vectors, making the choice of indexing format completely transparent at search time.
Client support
Adding a new format for indexing vectors might require changes on ingestion pipelines. To help this effort, in v9.3, Elasticsearch official clients can transform vectors with 32-bit floating-point values into Base64-encoded strings and the other way around. You might need to check the client documentation for the specific implementation.
For example, here’s a snippet for implementing bulk loading using the Python client:
The only difference from a bulk ingest using floats is that the embedding is wrapped with the pack_dense_vector() auxiliary function.
Conclusion
By switching from JSON float arrays to Base64-encoded vectors, we remove one of the largest remaining bottlenecks in Elasticsearch’s vector ingestion pipeline: numeric parsing. The result is a simple change with outsized impact: up to 2× higher throughput for DiskBBQ workloads and meaningful gains even for slower indexing strategies, like HNSW.
Because vectors are already stored internally in a binary format and excluded from _source by default, this improvement is completely transparent at search time. With official client support landing in v9.3, adopting Base64 encoding requires only minimal changes to existing ingestion code, while delivering immediate performance benefits.
If you’re indexing large volumes of embeddings, especially in high-throughput or serverless environments, Base64-encoded vectors are now the fastest and most efficient way to get your data into Elasticsearch.Those interested in the implementation details can follow the related Elasticsearch issues and pull requests: #111281 and #135943.
Zugehörige Inhalte

16. Juli 2026
A picture is worth 1.5x the words: What we learned benchmarking product search embeddings
We benchmarked two embedding models on 5,000 real products and found that combining image and text beats either alone by up to 50%. Here's the data and the model that won.

13. Juli 2026
The disk that never woke up: what actually decided our Qdrant vector search benchmark rematch
On the same hardware, Elasticsearch and Qdrant land in the same range at 56 QPS. The io_uring disk scorer and memory claims turned out to be the two things that mattered least.

10. Juli 2026
How BBQ shrinks Jina v5 embeddings by 29x without losing recall in Elasticsearch
A hands-on test comparing BBQ and float32 vector indices in Elasticsearch, measuring memory, disk and recall@10 across five languages.

9. Juli 2026
Why Elasticsearch is becoming a columnar database
Elasticsearch is becoming a first-class columnar database. Columnar Mode ships in 9.5, storing data once alongside the existing modes and cutting storage footprints while speeding up analytical queries.

7. Juli 2026
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.