您想要获得 Elastic 认证吗?了解下一次 Elasticsearch 工程师培训何时开始!您可以开始免费云服务试用,或立即在您的本地计算机上试用 Elastic。
Lucene 中的自动字节量化
虽然 HNSW 是一种强大而灵活的矢量存储和搜索方式,但要快速运行,它确实需要大量内存。例如,查询 1MM float32 向量维)大约需要1,000,000 * 4 * (768 + 12) = 3120000000 字节(约 3GB内存)。一旦开始搜索大量向量,成本就会变得很高。减少使用约内存的一种方法是通过字节量化。Lucene 以及 Elasticsearch 支持矢量索引已有一段时间,但建立这些矢量一直是用户的责任。这种情况即将改变,因为我们在 Lucene 中引入了标量量化。
标量量化 101
所有量化技术都被视为原始数据的有损转换。这意味着,为了节省篇幅,有些信息会丢失。有关标量量化的深入解释,请参阅:标量量化 101在高层次上,标量量化是一种有损压缩技术。通过一些简单的计算,可以节省大量空间,而对召回的影响却很小。
探索建筑
习惯于使用 Elasticsearch 的人可能已经熟悉了这些概念,但这里还是要简要介绍一下搜索文档的分布情况。
每个 Elasticsearch 索引都由多个分片组成。虽然每个分片只能分配给一个节点,但每个索引有多个分片,可以跨节点并行计算。
每个分区都由一个Lucene 索引组成。Lucene 索引由多个只读段组成。在索引过程中,文件会被缓冲并定期刷新到只读段中。当满足某些条件时,这些片段可以在后台合并成一个更大的片段。所有这些都是可配置的,也有其自身的复杂性。但是,当我们谈到分段和合并时,我们指的是只读的 Lucene 分段以及这些分段的自动定期合并。下面我们将深入探讨分段合并和设计决策。
Lucene 中每个分段的量化
Lucene 中的每个分段都存储了以下内容:单个向量、HNSW 图表指数、量化向量和计算出的量化值。为简洁起见,我们将重点讨论 Lucene 如何存储量化向量和原始向量。对于每个片段,我们在文件中记录原始矢量,在 文件中记录量化矢量和单个校正乘法浮点,在文件中记录量化的元数据。

图 1:原始矢量存储文件的简化布局。由于 数值为 4 字节,因此占用由于我们正在进行量化,因此在 HNSW 搜索时不会加载这些数据。只有在特别要求时才会使用(例如或在段落合并时重新量化。

图 2:的简化布局锉刀占用空间,并将在搜索过程中加载到内存中。字节用于计算校正乘数浮动,以调整评分,提高准确性和召回率。

图 3:元数据文件的简化布局。在这里,我们将跟踪量化和矢量配置,以及计算出的该分段的量化值。
因此,对于每个片段,我们不仅要存储量化向量,还要存储用于制作这些量化向量和原始向量的量化值。但是,我们为什么还要保留原始矢量呢?
与您一起成长的量化
由于 Lucene 会定期刷新到只读分段,因此每个分段只能看到所有数据的一部分。这意味着计算出的量化值仅直接适用于整个数据的样本集。如果样本能充分代表整个语料库,这并不是什么大问题。但 Lucene 允许您以各种方式对索引进行排序。因此,您可以对数据进行索引排序,从而增加每个分段量化计算的偏差。此外,您还可以随时刷新数据!您的样本集可能很小,甚至只有一个矢量。另一个扳手是,您可以控制合并发生的时间。虽然 Elasticsearch 已配置了默认值和定期合并,但你可以通过_force_mergeAPI 随时要求合并。那么,我们如何在提供良好的量化效果的同时,还能保证所有这些灵活性?
Lucene 的向量量化会随时间自动调整。由于 Lucene 采用的是只读分段架构,因此我们可以保证每个分段中的数据没有变化,并在代码中明确规定何时可以更新。这意味着在分段合并过程中,我们可以根据需要调整量化值,并可能重新量化向量。
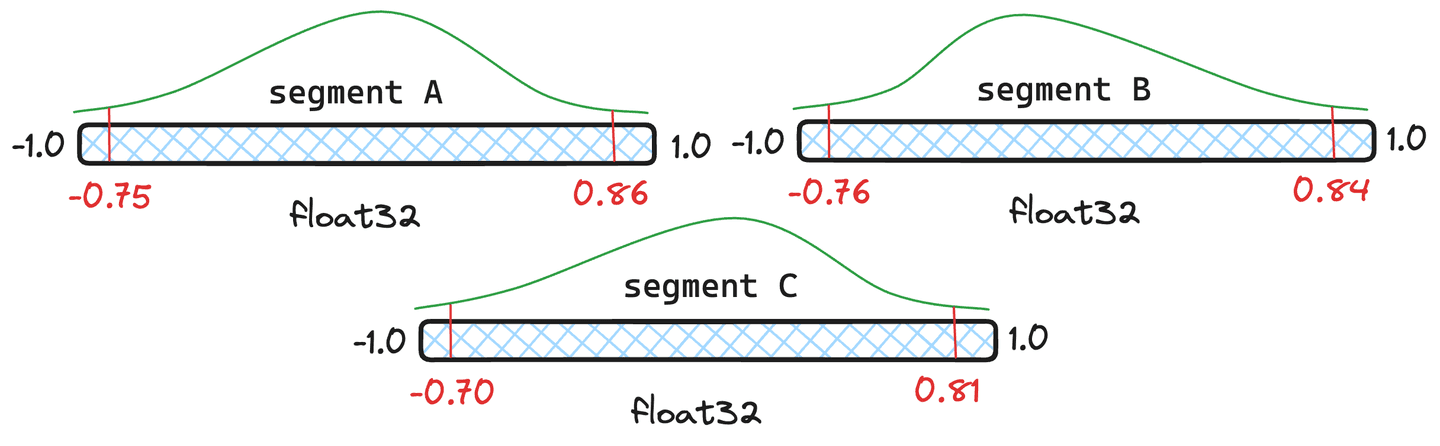
图 4:具有不同量级的三个示例片段。
但重新量化不是很贵吗?它确实有一些开销,但 Lucene 会智能地处理量化,只在必要时进行完全量化。让我们以图 4 中的片段为例。让我们给段和段各提供,段只提供。Lucene 会对量化值进行加权平均,如果合并后的量化值与数据段的原始量化值足够接近,我们就不必重新量化该数据段,而会使用新合并的量化值。
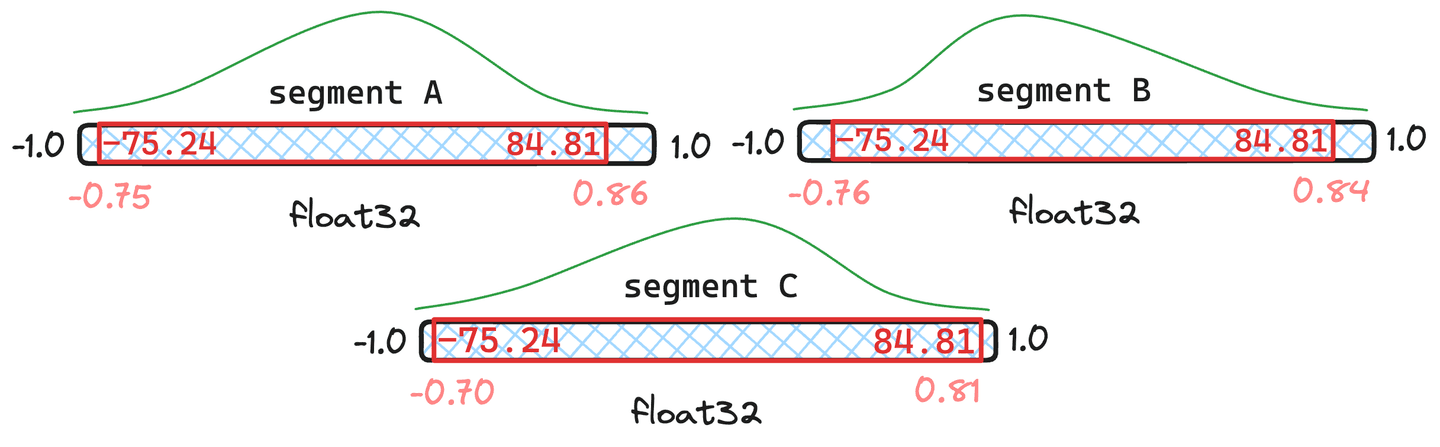
图 5:段和段有,而段只有 份文件的合并量化示例。
在图 5 所示的情况中,我们可以看到合并后的量化值与和 中的原始量化值非常相似。 段,似乎偏差太大。因此,中的向量将根据新合并的量化值重新量化。
在一些极端情况下,合并后的量化值与任何原始量化值的差异都非常大。在这种情况下,我们将从每个分段中抽取一个样本,然后重新计算量化值。
量化性能& 数字
那么,它的速度快吗?以下是在c3-standard-8 GCP 实例上运行实验收集到的数据。为了确保与进行公平的比较,我们使用了一个足够大的实例来在内存中保存原始向量。我们使用最大内积法索引了 Cohere Wiki向量。
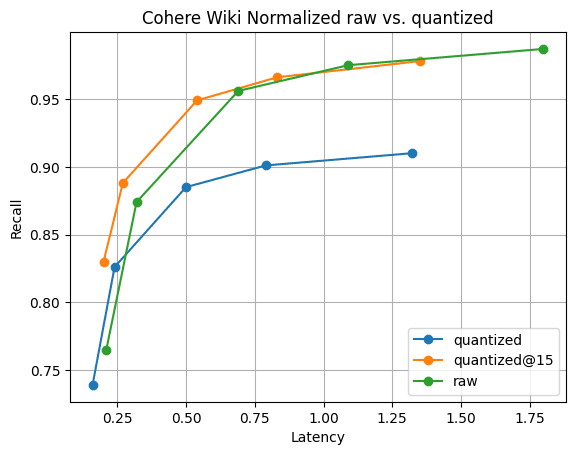
图 6:量化矢量与原始矢量的 Recall@10。量化矢量的搜索性能明显快于原始矢量,只需再收集 5 个矢量就能迅速恢复召回率; 可见一斑。
图 6 展示了这个故事。虽然在召回方面存在差异,这是意料之中的,但差异并不大。而且,只要再收集 5 个矢量,召回率的差异就会消失。所有这一切,段合并速度快,内存仅为向量的 1/4。
结论
Lucene 为难题提供了独特的解决方案。量化不需要 "训练 "或 "优化 "步骤。在 Lucene 中,它可以正常工作。如果数据发生变化,也不必担心需要 "重新训练 "矢量索引。Lucene 会检测重大变化,并在数据生命周期内自动处理这些变化。期待我们将这一功能引入 Elasticsearch!
常见问题
什么是标量量化?
标量量化是一种有损压缩技术。通过一些简单的数学计算,可以节省大量空间,而对召回几乎没有影响。
相关内容

基于 Elasticsearch + Jina 嵌入的无监督文档集群
一种使用 Elasticsearch 和 Jina 嵌入进行无监督文档集群的实用、可复现方法。

在 Streams 中利用机器学习自动化日志解析
了解一种混合 ML 方法如何在 Streams 中结合日志格式指纹开展自动化实验,实现 94% 的日志解析准确率和 91% 的日志分区准确率。

矢量搜索过滤:保持相关性
仅靠矢量搜索来查找与查询最相似的结果是不够的。要缩小搜索结果的范围,通常需要进行筛选。本文介绍了在 Elasticsearch 和 Apache Lucene 中如何对矢量搜索进行过滤。

