您想要获得 Elastic 认证吗?了解下一次 Elasticsearch 工程师培训何时开始!您可以开始免费云服务试用,或立即在您的本地计算机上试用 Elastic。
做好准备:
这个博客与往常不同。这不是对新功能的解释,也不是教程。这就是花了三天时间编写的一行代码。我们将修复一个潜在的 Apache Lucene 索引损坏问题。我希望你们能有一些收获:
- 只要有足够的时间和合适的工具,所有缺陷测试都是可重复的
- 多层测试是实现稳健系统的关键。然而,测试级别越高,调试和重现的难度就越大。
- 睡眠是一个出色的调试器
Elasticsearch 如何测试
在 Elastic,我们有大量针对 Elasticsearch 代码库运行的测试。有些是简单而集中的功能测试,有些是单节点 "快乐路径 "集成测试,还有一些则试图破坏集群,以确保在故障情况下一切正常。当测试持续失败时,工程师或工具自动化会创建一个 github 问题并标记出来,以便特定团队进行调查。这个特殊的错误是在最后一种测试中发现的。这些测试非常棘手,有时只能在多次运行后才能重复。
这项测试究竟在测试什么?
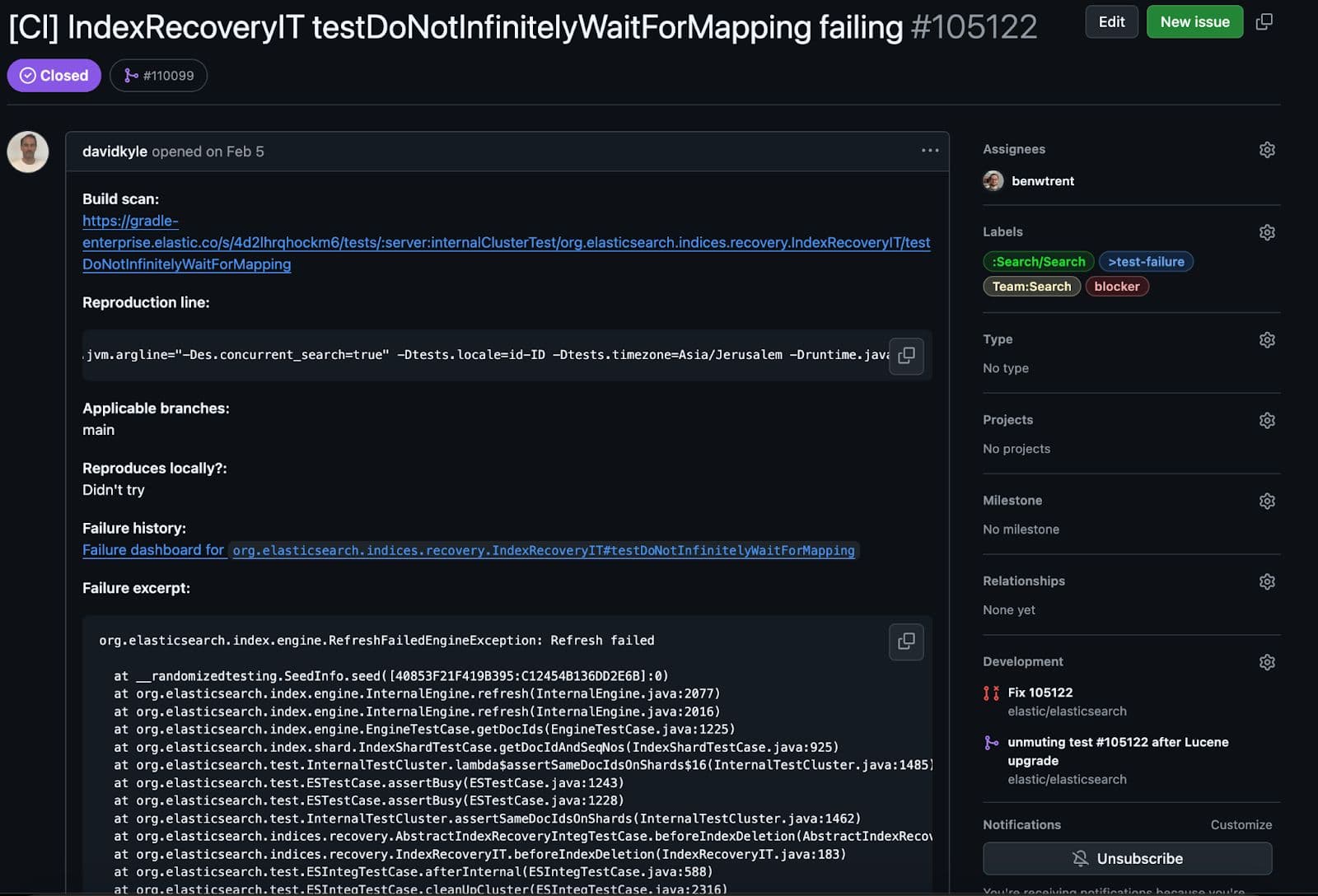
这个测试很有意思。它会创建一个特定映射,并将其应用于主分区。然后尝试创建副本。关键区别在于,当副本尝试解析文档时,测试会注入一个异常,从而导致恢复以一种令人惊讶(但在意料之中)的方式失败。
然而,一切都在按预期进行,但有一个重要的问题。在测试清理过程中,我们对一致性进行了验证,在此,测试遇到了一个障碍。
该测试未能以预期方式失败。在一致性检查过程中,我们将验证所有复制的 Lucene 段文件和主文件是否一致。意思是,未被破坏和完全复制。部分数据或损坏的数据比完全故障更糟糕。以下是故障的可怕简短堆栈跟踪。
不知何故,在强制复制失败期间,复制的分片最终损坏了!让我用通俗易懂的语言解释一下错误的关键部分。
Lucene 是一种基于段的架构,这意味着每个段都知道并管理自己的只读文件。正在通过其SegmentCoreReaders验证这一特定网段,以确保一切正常。每个核心阅读器都存储有元数据,可显示特定段落存在哪些字段类型和文件。但是,在验证Lucene90PointsFormat 时,某些预期文件丢失了。有了_0.cfs 文件段,我们预计会有一个名为kdi 的点格式文件。cfs 代表"复合文件系统" ,Lucene 有时会将所有字段类型和所有小文件合并为一个较大的文件,以提高复制效率和资源利用率。事实上,所有三个点文件扩展名都不见了:kdd、kdi 和kdm 都不见了。我们怎么会出现 Lucene 片段期望找到一个点文件,但它却不见了的情况呢?这似乎是一个可怕的损坏错误!
每个错误修复的第一步是复制它
复制这个特殊错误的失败极其痛苦。在利用 Elasticsearch 中的随机值测试的同时,我们确保为每个故障提供一个(希望是)可重现的随机种子,以确保可以对所有故障进行调查。除了由竞赛条件引起的故障外,这对所有故障都非常有效。
无论我尝试多少次,这颗特殊的种子都没有在本地重复失败。但是,有一些方法可以对测试进行锻炼,使失败的重复性更高。
我们的测试套件允许通过-Dtests.iters 参数在同一命令中多次运行指定测试。但这还不够,我还需要确保执行线程在切换,从而增加发生竞赛条件的可能性。系统中的另一个问题是测试运行时间太长,测试运行器会超时。最后,我使用下面的噩梦 bash 来重复运行测试:
压力来了这样,您就可以快速启动一个进程,让 CPU 内核成为您的午餐。在运行失败测试的无数次迭代过程中,随机发送 stress-ng 垃圾邮件,最终让我复制了失败。更近一步要对系统施加压力,只需打开另一个终端窗口并运行
揭示错误
现在,揭示错误的测试失败大多是可重复的,是时候尝试找出原因了。这个特殊测试的奇怪之处在于,Lucene 会抛出问题,因为它期望得到点值,但测试却没有直接添加任何点值。只有文本值。这促使我考虑研究我们的乐观并发控制字段最近的变化:_seq_no 和_primary_term 。这两者都作为点索引,存在于每个 Elasticsearch 文档中。
事实上,我们的_seq_no 映射器确实在提交后发生了变化!是的!这一定是原因!但是,我的兴奋是短暂的。这只是改变了字段添加到文档的顺序。在这一更改之前,_seq_no 字段是最后添加到文档中的。之后,他们先加入。向 Lucene 文档添加字段的顺序不可能导致此故障...
没错,更改字段添加顺序导致了故障。这令人惊讶,原来是 Lucene 本身的一个错误!更改字段解析顺序不应改变文档解析行为。
Lucene 中的错误
事实上,Lucene 中的错误主要集中在以下条件上:
- 为点值字段建立索引(例如
_seq_no) - 在分析过程中尝试为文本字段抛出的问题建立索引
- 在这种奇怪的状态下,我们会打开一个来自作者的近实时阅读器,体验文本索引分析异常
但无论我尝试多少种方法,都无法完全复制。我在整个 Lucene 代码库中直接添加了用于调试的暂停点。我尝试在异常路径中随机打开读者。我甚至打印了数百万兆字节的日志,试图找到发生故障的确切路径。我就是做不到。我花了一整天的时间去战斗,结果却输了。
然后我就睡了。
第二天,我重新阅读了原始堆栈跟踪,发现了下面一行:
在我所有的娱乐尝试中,我从未专门设置过保留合并策略。Elasticsearch 使用SoftDeletesRetentionMergePolicy,这样我们就能在副本中准确地复制删除,并确保我们的所有并发控制都能控制文档的实际删除时间。否则,Lucene 将完全控制并在任何合并时删除它们。
一旦我添加了这个策略,并复制了上述最基本的步骤,故障就立即复制了。
我从来没有像现在这样高兴地打开 Lucene 中的 一个 bug 。
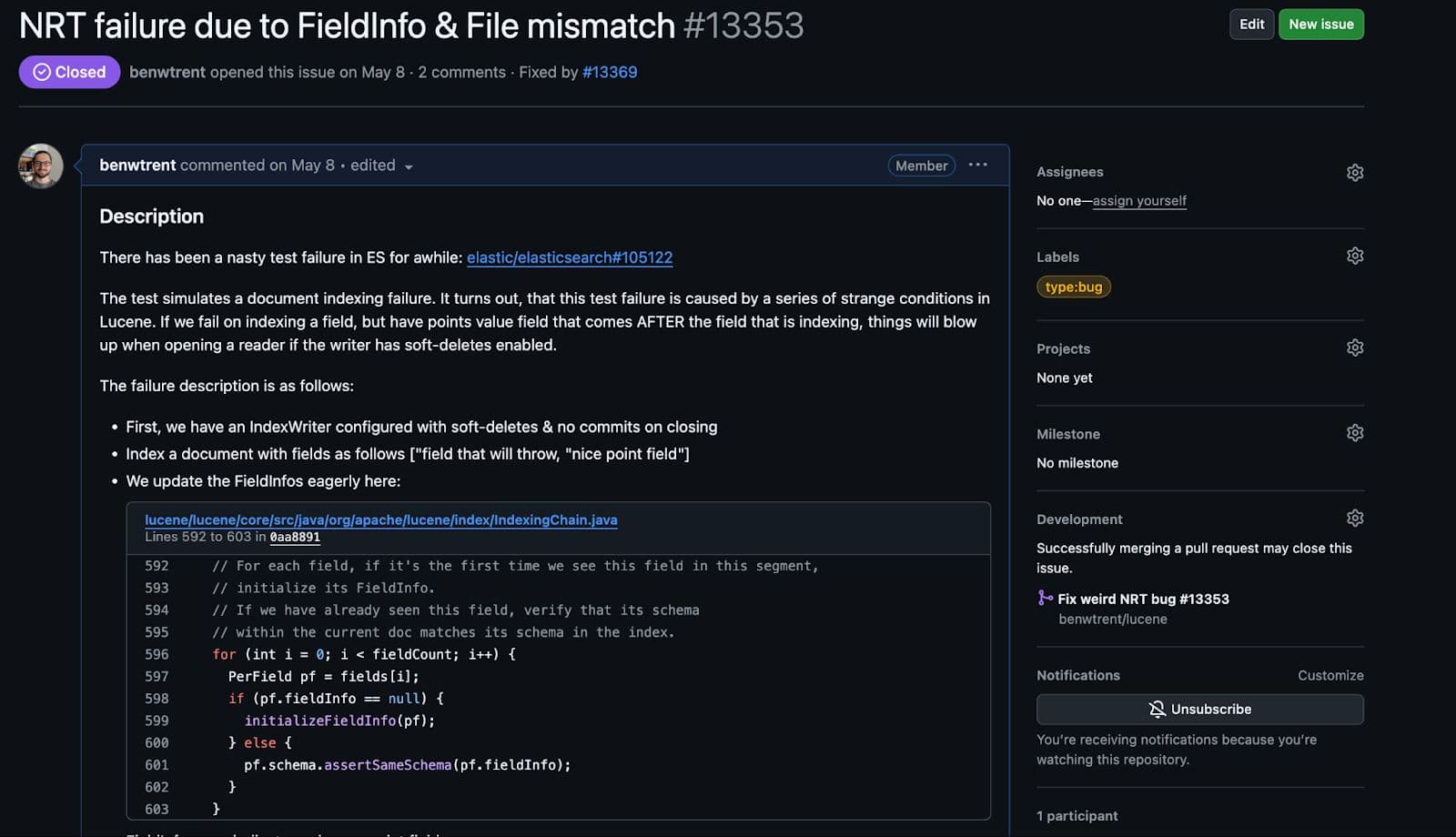
虽然在 Elasticsearch 中它本身是一个竞赛条件,但一旦所有条件都得到满足,在 Lucene 中编写一个可重复失败的测试也很简单。
最后,像所有好的 bug 一样,只用一行代码就修复了。多天的工作,只为一行代码。
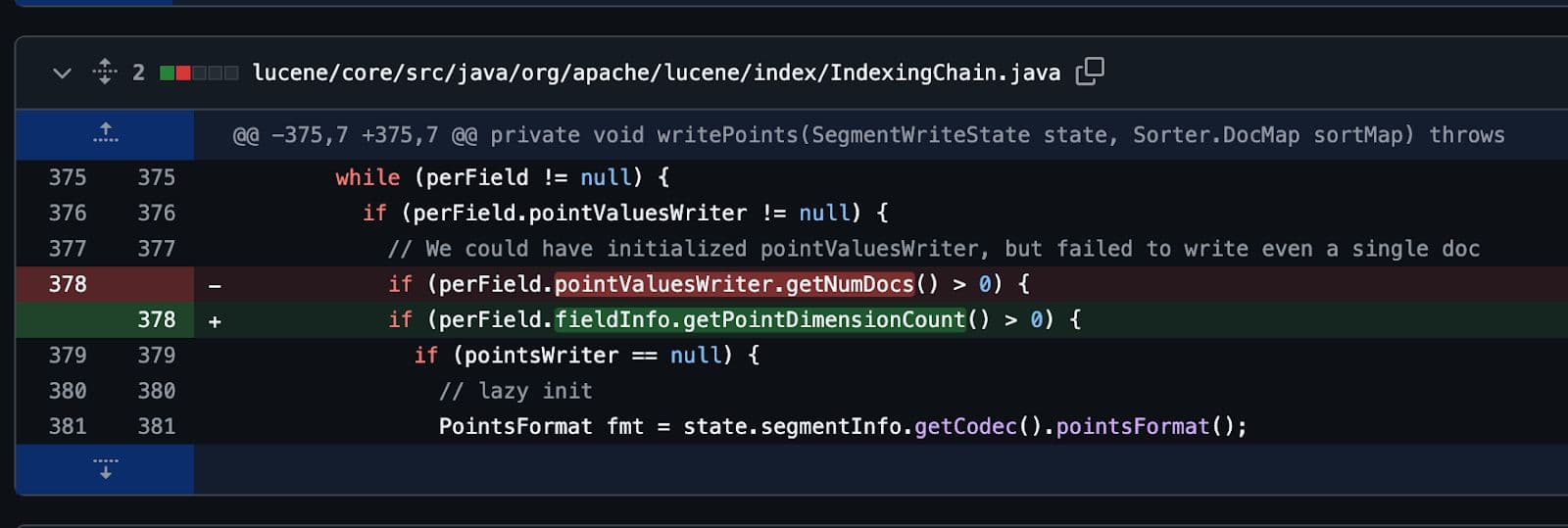
但这是值得的。
不是终点
希望您喜欢和我一起经历这次狂野之旅!编写软件,尤其是像 Elasticsearch 和 Apache Lucene 这样应用广泛且复杂的软件,是一件很有成就感的事情。然而,有时却令人异常沮丧。我对软件既爱又恨。错误修复永远不会结束!
相关内容

矢量搜索过滤:保持相关性
仅靠矢量搜索来查找与查询最相似的结果是不够的。要缩小搜索结果的范围,通常需要进行筛选。本文介绍了在 Elasticsearch 和 Apache Lucene 中如何对矢量搜索进行过滤。




Elasticsearch 与 OpenSearch:向量搜索性能比较
Elasticsearch 开箱即用,在向量搜索方面比 OpenSearch 快 2 倍至 12 倍