Elasticsearch 与行业领先的生成式 AI 工具和提供商实现了原生集成。请观看我们的网络研讨会,了解如何超越 RAG 基础功能,或使用 Elastic 向量数据库构建生产就绪型应用。
LangGraph 检索代理模板是 LangChain 开发的一个启动项目,目的是方便在 LangGraph Studio 中使用 LangGraph 创建基于检索的问题解答系统。该模板经过预配置,可与 Elasticsearch 无缝集成,使开发人员能够快速构建可高效索引和检索文档的代理。
本博客主要介绍如何使用 LangGraph Studio 和 LangGraph CLI 运行和定制 LangChain 检索代理模板。该模板为利用 Elasticsearch 等各种检索后端构建检索增强生成 (RAG) 应用程序提供了一个框架。
我们将指导您设置、配置环境,并使用 Elastic 高效执行模板,同时定制代理流程。
准备工作
在继续之前,请确保已安装以下设备:
- Elasticsearch 云部署或内部部署(或在 Elastic Cloud 上创建 14 天免费试用版 )- 版本 8.0.0 或更高
- Python 3.9+
- 访问 LLM 提供商,如Cohere(本指南中使用)、OpenAI 或Anthropic/Claude
创建 LangGraph 应用程序
1.安装 LangGraph CLI
2.根据检索代理模板创建 LangGraph 应用程序
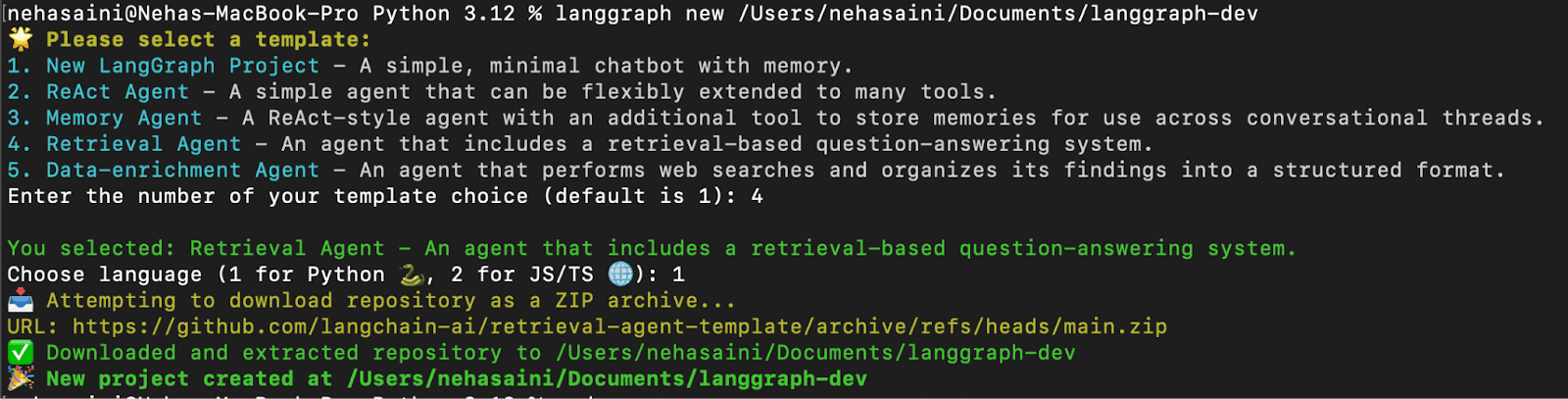
您将看到一个交互式菜单,可以从可用模板列表中进行选择。 为检索代理选择 4,为 Python 选择 1,如下图所示:
- 故障排除:如果遇到以下错误:"urllib.error.URLError:<urlopen error [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1000)>"
请运行 Python 的安装证书命令来解决问题,如下所示。

3.安装依赖项
在新 LangGraph 应用程序的根目录下创建虚拟环境,并以edit 模式安装依赖项,这样服务器就会使用本地更改:
设置环境
1.创建 .环境文件
.env 文件包含 API 密钥和配置,因此应用程序可以连接到您选择的 LLM 和检索提供商。复制示例配置,生成新的.env 文件:
2.配置 .env文件
.env 文件带有一组默认配置。您可以根据设置添加必要的 API 密钥和值来更新它。任何与使用案例无关的键都可以保持不变或删除。
.env文件示例(使用弹性云和 Cohere)
下面是.env 配置示例,用于将Elastic Cloud用作检索提供商,将Cohere用作 LLM,本博客对此进行了演示:
注:本指南使用 Cohere 进行响应生成和嵌入,您也可以 根据自己的使用情况使用 其他 LLM 提供商,如 OpenAI、 Claude,甚至本地 LLM 模型。请确保您打算使用的每个密钥都已存在,并在 .env 文件中正确设置 。
3.更新配置文件 -configuration.py
使用适当的 API 密钥设置.env 文件后,下一步就是更新应用程序的默认模型配置。更新配置可确保系统使用您在.env 文件中指定的服务和模型。
导航至配置文件:
configuration.py 文件包含检索代理用于三项主要任务的默认模型设置:
- 嵌入模型--将文件转换为矢量表示
- 查询模型- 将用户的查询转化为矢量
- 响应模型- 生成最终响应
默认情况下,代码使用OpenAI(如openai/text-embedding-3-small )和Anthropic(如anthropic/claude-3-5-sonnet-20240620 and anthropic/claude-3-haiku-20240307 )的模型。在本博客中,我们将改用 Cohere 模型。如果您已经在使用 OpenAI 或 Anthropic,则无需更改。
更改示例(使用 Cohere):
打开configuration.py 并修改模型默认值,如下图所示:
使用 LangGraph CLI 运行检索代理
1.启动 LangGraph 服务器
这将在本地启动 LangGraph API 服务器。如果运行成功,你应该会看到类似的内容:
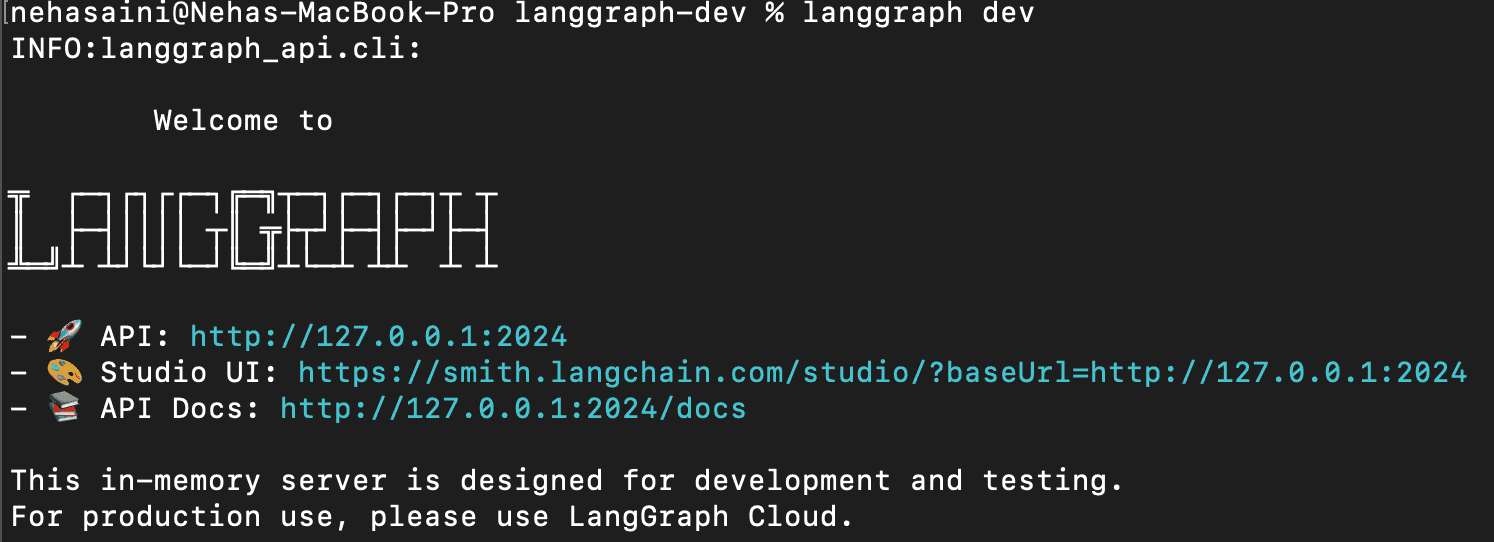
开放工作室用户界面 URL。
有两种图表可供选择:
- 检索图:从 Elasticsearch 中检索数据,并使用 LLM 响应查询。
- 索引图:将文档索引到 Elasticsearch,并使用 LLM 生成嵌入。

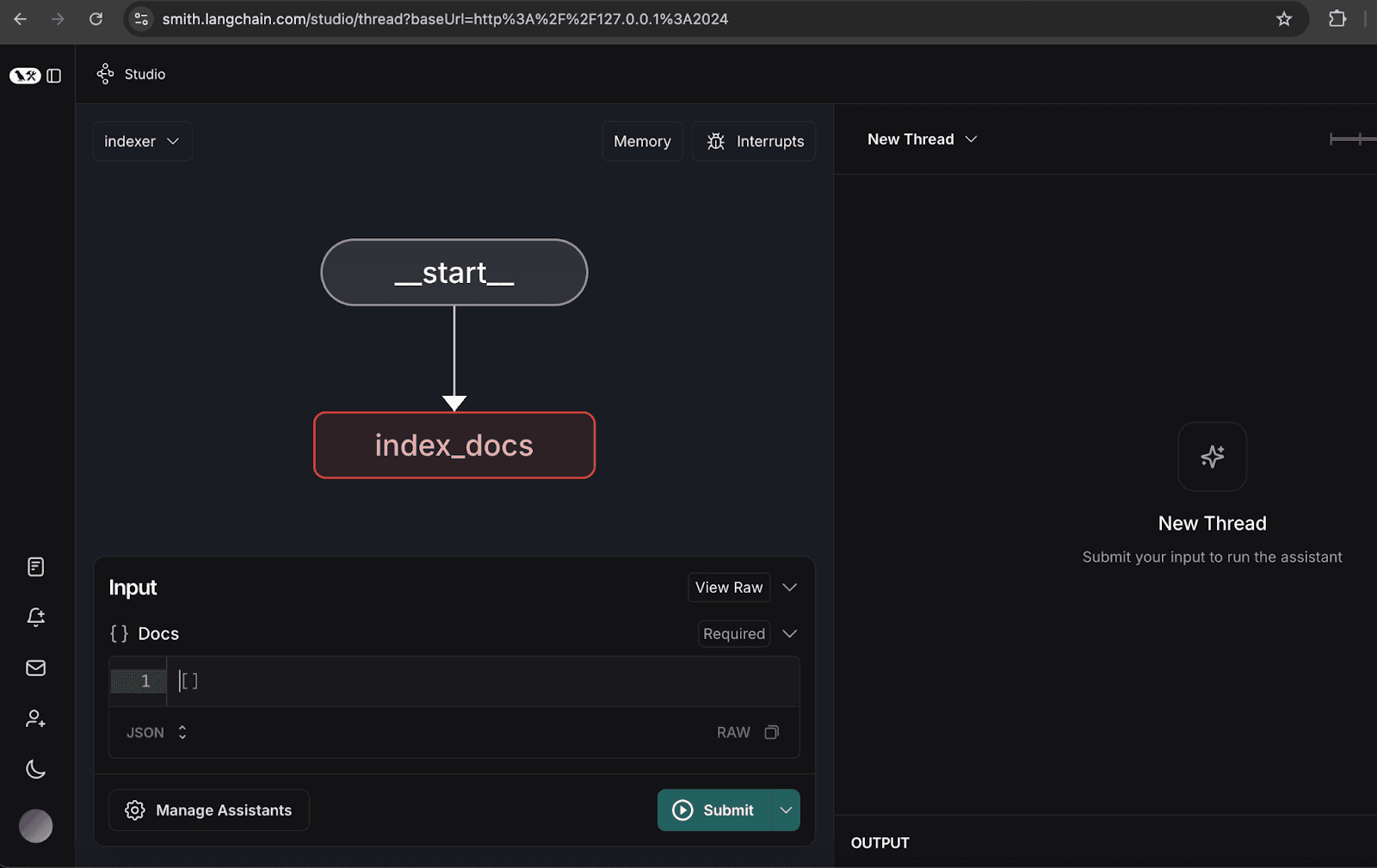
2.配置索引图
- 打开索引图。
- 单击管理助手。
- 点击"添加新助手",输入指定的用户详细信息,然后关闭窗口。


3.为样本文件编制索引
- 为以下样本文件编制索引,这些文件是消费与工业专用技术公司的假设季度报告:
文件索引完成后,你会在线程中看到一条删除信息,如下图所示。

4.运行检索图
- 切换到检索图。
- 输入以下搜索查询:

系统将返回相关文件,并根据索引数据提供准确答案。
自定义检索代理
为了提升用户体验,我们在检索图中引入了一个定制步骤,以预测用户可能提出的下三个问题。这一预测的依据是
- 从检索到的文件中获取上下文
- 以前的用户互动
- 最后一次用户查询
实施查询预测功能需要更改以下代码:
1.更新 graph.py
- 添加
predict_query功能:
- 修改
respond函数,以返回response对象,而不是消息:
- 更新图结构,为 predict_query 添加新节点和边:
2.更新 prompts.py
- 在
prompts.py中进行guery预测的工艺提示:
3.更新 configuration.py
- 添加
predict_next_question_prompt:
4.更新 state.py
- 添加以下属性
5.重新运行检索图
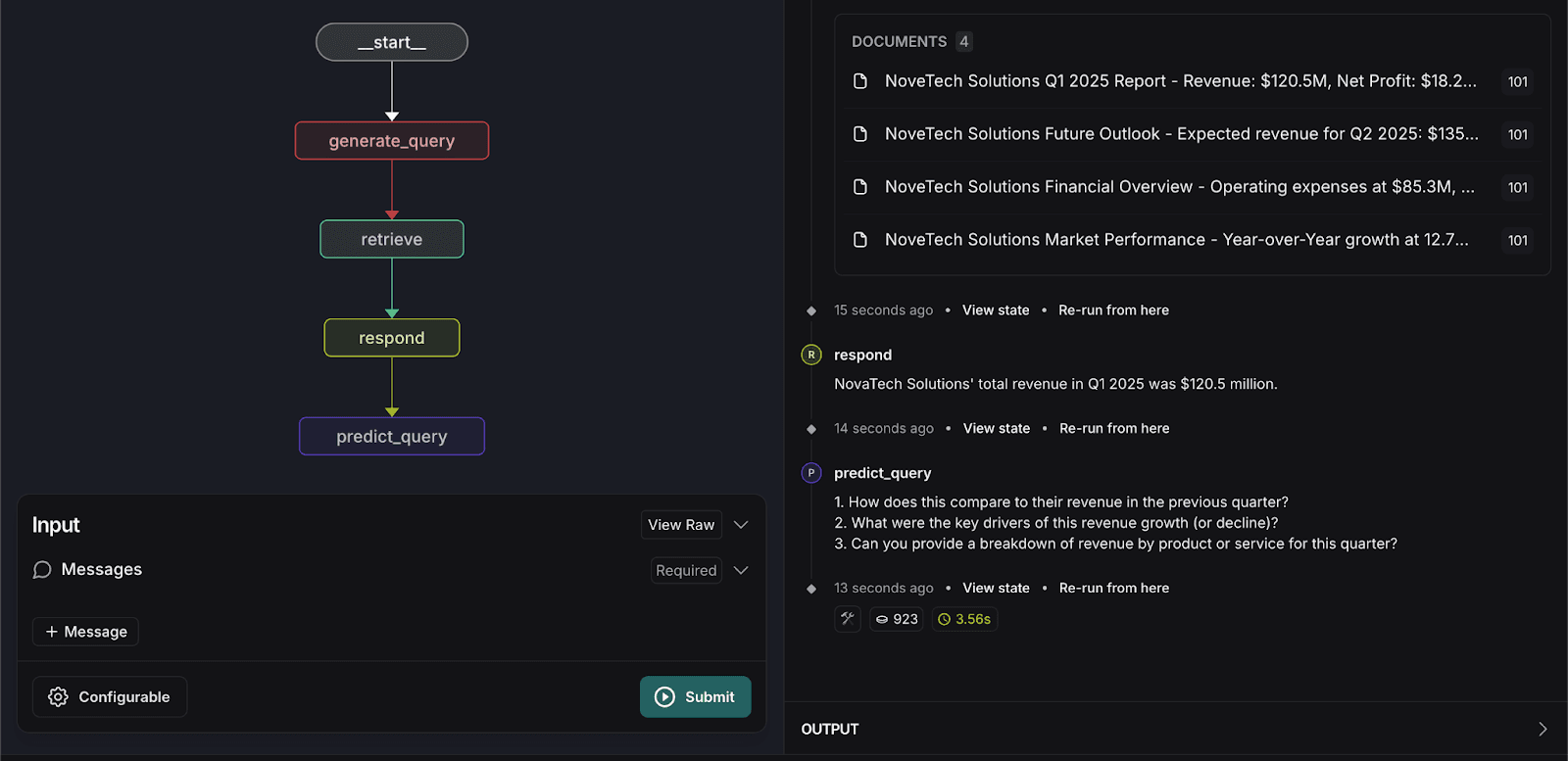
- 再次输入以下搜索查询:
系统将处理输入信息,并预测用户可能提出的三个相关问题,如下图所示。
结论
在 LangGraph Studio 和 CLI 中集成检索代理模板有几个主要好处:
- 加速开发:模板和可视化工具简化了检索工作流的创建和调试,缩短了开发时间。
- 无缝部署:对 API 和自动扩展的内置支持可确保跨环境的顺利部署。
- 易于更新:修改工作流程、添加新功能和集成其他节点都很简单,从而更容易扩展和增强检索流程。
- 持久记忆:系统保留代理状态和知识,提高一致性和可靠性。
- 灵活的工作流程建模:开发人员可针对特定用例定制检索逻辑和通信规则。
- 实时交互和调试:通过与运行中的代理互动,可以高效地进行测试和解决问题。
利用这些功能,企业可以建立强大、高效和可扩展的检索系统,从而提高数据的可访问性和用户体验。
该项目的完整源代码可在GitHub 上获取。
常见问题
什么是 RAG 工作流程?
RAG(Retrieval-Augmented Generation,检索-增强生成)工作流程是一种让人工智能模型访问您的私人数据的方法,这样它就能提供准确的、基于事实的答案,而不是"幻觉。"
为什么使用 Elasticsearch 作为 LangGraph 代理的数据库?
Elasticsearch 充当代理的"长期内存" 。与标准数据库不同,它是为混合搜索(Hybrid Search)而建--将矢量搜索(理解含义)与关键词搜索(查找精确术语)相结合。这样,无论您询问"Q1 收入" 还是"财务增长," Elasticsearch 都能提供最相关的文档供 LangGraph 处理。
能否使用 LangGraph 检索代理模板构建多用户系统?
是的。文章通过索引器图配置使用 user_id 进行了演示(如"101" )。这样,您就可以给文档加上特定所有者的标签,使检索代理只能查找特定用户有权查看的信息。
相关内容

用描述代替手动绘制:通过 MCP 和 ES|QL 构建 AI 原生 Kibana 仪表板。
从提示词到仪表板了解如何使用 example-mcp-dashbuilder 通过自然语言构建 Kibana 仪表板:这是一款开源 MCP 应用,能够编写 ES|QL 查询、创建交互式图表,并将功能完整的仪表板直接导出到 Kibana。


使用 Elasticsearch 与 LLM 进行实体解析,第 2 部分:通过 LLM 判断和语义搜索匹配实体
在 Elasticsearch 中使用语义搜索和透明 LLM 判断进行实体解析。

借助 LangGraph 与 Elasticsearch 打造具人机协作功能的智能体
了解如何借助 LangGraph 与 Elasticsearch 打造具人机协作功能的智能体,让人类参与决策流程,从而填补情境信息缺口,并在工具调用执行前进行审核。

在 Streams 中利用机器学习自动化日志解析
了解一种混合 ML 方法如何在 Streams 中结合日志格式指纹开展自动化实验,实现 94% 的日志解析准确率和 91% 的日志分区准确率。