从向量搜索到强大的 REST API,Elasticsearch 为开发者提供了最全面的搜索工具包。请访问Elasticsearch Labs 仓库中的示例笔记本,尝试新事物。您也可以立即开始免费试用或在本地运行 Elasticsearch。
矢量搜索为实现文本的语义搜索或图像、视频或音频的相似性搜索提供了基础。在矢量搜索中,矢量是数据的数学表示,可能非常庞大,有时也会比较迟钝。更好的二进制量化(以下简称 BBQ)是一种矢量压缩方法。它可以让你找到正确的匹配,同时缩小矢量,使搜索和处理速度更快。本文将介绍 BBQ 和 rescore_vector,这是一个仅适用于量化索引的字段,可自动对向量重新评分。
本文中提到的所有完整查询和输出都可以在我们的Elasticsearch Labs 代码库中找到。
为什么要在使用案例中实施更好的二进制量化 (BBQ)?
注:要深入了解 BBQ 背后的数学原理,请查看下面的"进一步学习 "部分。就本博客而言,重点是实施。
数学知识固然耐人寻味,但要想完全掌握矢量搜索保持精确的原因,这一点至关重要。归根结底,这一切都与压缩有关,因为事实证明,目前的矢量搜索算法受到数据读取速度的限制。因此,如果能将所有数据都存储到内存中,那么与从存储设备中读取数据相比,速度将得到显著提升 (内存的 读取 速度约为固态硬盘的 200 倍 )。
有几点需要注意:
- 基于图形的索引,如HNSW(层次导航小世界),对于向量检索来说是最快的。
- HNSW:一种近似近邻搜索算法,可构建多层图结构,从而实现高效的高维相似性搜索。
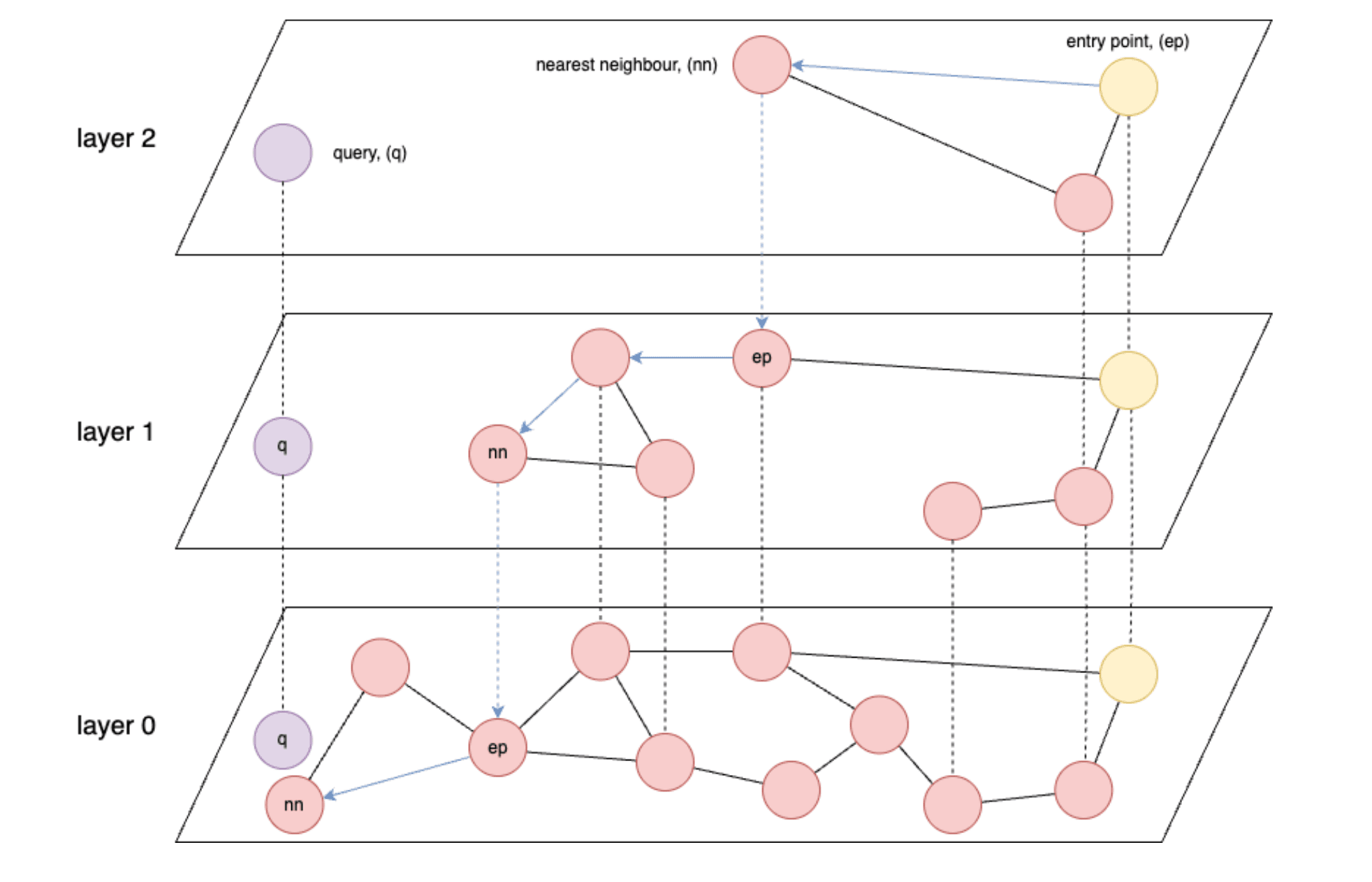
- 从根本上说,HNSW 的速度受限于从内存读取数据的速度,或者在最糟糕的情况下,受限于从存储器读取数据的速度。
- 理想情况下,您希望能够将所有存储的向量加载到内存中。
- 嵌入模型通常以 float32 的精度生成向量,每个浮点数 4 个字节。
- 最后,根据向量和/或维数的多少,内存很快就会不够存放所有向量。
如果把这看作是理所当然的,那么一旦你开始摄入数百万甚至数十亿的向量,每个向量都可能有数百甚至数千个维度,你就会发现问题很快就出现了。题为 "压缩比近似值"的部分提供了一些粗略的数字。
开始需要什么?
要开始使用,您需要具备以下条件:
- 如果使用 Elastic Cloud 或内部部署,则需要高于 8.18 的 Elasticsearch 版本。虽然 BBQ 是在 8.16 中引入的,但在本文中,您将使用
vector_rescore,它是在 8.18 中引入的。 - 此外,您还需要确保集群中有一个机器学习(ML)节点。(注意:加载模型需要至少 4GB 的 ML 节点,但如果要完成生产工作负载,可能需要更大的节点)。
- 如果使用的是无服务器,则需要选择针对向量进行了优化的实例。
- 您还需要具备矢量数据库方面的基础知识。如果您还不熟悉 Elastic 中的矢量搜索概念,可能需要先查看以下资源:
更好的二进制量化 (BBQ) 实现
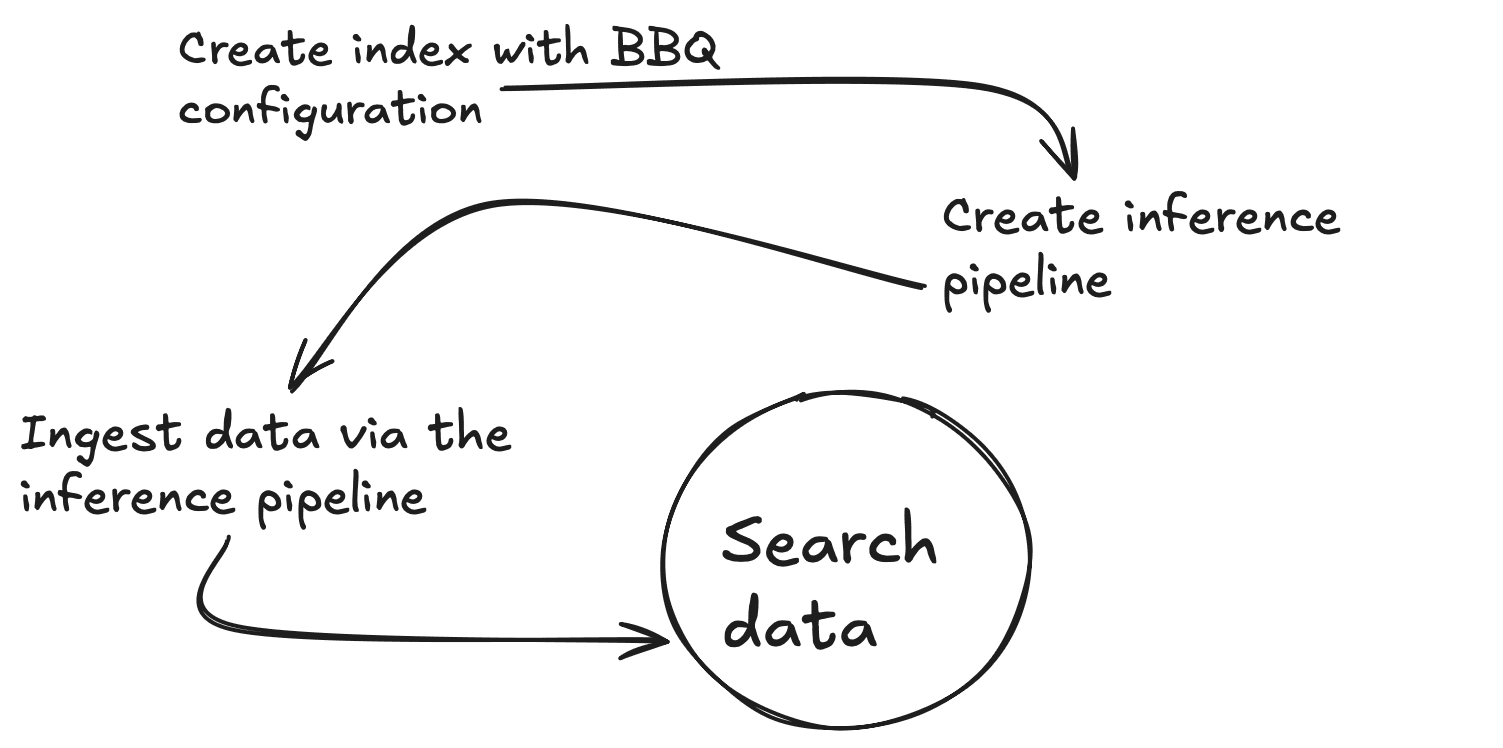
为了使本博客简单明了,您将在可用时使用内置函数。在这种情况下,.multilingual-e5-small 向量嵌入模型将直接在 Elasticsearch 内部的机器学习节点上运行。请注意,您可以用自己选择的嵌入器(OpenAI、Google AI Studio、Cohere等)替换text_embedding 模型。如果您喜欢的模型尚未集成,您也可以自带密集向量嵌入模型)。
首先,您需要创建一个推理端点,为给定文本生成向量。您将从 KibanaDev Tools 控制台运行所有这些命令。该命令将下载.multilingual-e5-small.如果端点还不存在,它将为您设置端点;这可能需要一分钟的时间。你可以在 Outputs 文件夹中的01-create-an-inference-endpoint-output.json文件中看到预期输出。
返回后,模型就设置好了,您可以使用以下命令测试模型是否按预期运行。你可以在 Outputs 文件夹中的02-embed-text-output.json文件中看到预期输出。
如果遇到训练好的模型没有分配到任何节点的问题,可能需要手动启动模型。
现在,让我们创建一个带有 2 个属性的新映射,一个标准文本字段 (my_field) 和一个 384 维的密集矢量字段 (my_vector) ,以匹配嵌入模型的输出。您还可以覆盖index_options.type to bbq_hnsw 。你可以在 Outputs 文件夹中的文件03-create-byte-qauntized-index-output.json中看到预期输出。
要确保 Elasticsearch 生成向量,可以使用Ingest Pipeline。该管道需要三样东西:端点 (model_id)、要为其创建向量的input_field 以及用于存储这些向量的output_field 。下面的第一条命令将创建推理摄取管道,该管道使用推理服务 ,第二条命令将测试管道是否正常工作。你可以在 Outputs 文件夹中的文件04-create and-simulate-ingest-pipeline-output.json中看到预期输出。
现在,您可以使用下面的前 2 个命令添加一些文档,并使用第 3 个命令测试搜索是否有效。你可以在 Outputs 文件夹中的05-bbq-index-output.json文件中查看预期输出。
正如本文章所建议的,当您扩展到非数量级的数据时,建议使用重采样和超采样,因为它们有助于在受益于压缩优势的同时保持较高的召回准确率。从 Elasticsearch 8.18 版开始,您可以使用rescore_vector 这样做。预期输出在 Outputs 文件夹中的06-bbq-search-8-18-output.json文件中。
这些分数与原始数据的分数相比如何?如果您再次进行上述操作,但使用index_options.type: hnsw ,您会发现得分非常接近。你可以在 Outputs 文件夹中的07-raw-vector-output.json文件中看到预期输出。
压缩比的近似值
在使用矢量搜索时,存储和内存需求很快就会成为一项重大挑战。下面的细目说明了不同的量化技术如何显著减少矢量数据的内存占用。
| 向量 (V) | 尺寸(D) | 未加工(V x D x 4) | int8 (V x (D x 1 + 4)) | int4 (V x (D x 0.5 + 4)) | bbq (V x (D x 0.125 + 4)) |
|---|---|---|---|---|---|
| 10,000,000 | 384 | 14.31GB | 3.61GB | 1.83GB | 0.58GB |
| 50,000,000 | 384 | 71.53GB | 18.07GB | 9.13GB | 2.89GB |
| 100,000,000 | 384 | 143.05GB | 36.14GB | 18.25GB | 5.77GB |
结论
BBQ 是一种优化方法,可用于压缩矢量数据而不影响精度。它的工作原理是将向量转换为比特,让您能够有效地搜索数据,并使您能够扩展人工智能工作流程,加快搜索速度并优化数据存储。
进一步学习
如果您想了解有关烧烤的更多信息,请务必查看以下资源:
相关内容

2026年4月23日
我们如何构建 Elasticsearch simdvec,使其成为世界上速度最快的向量搜索之一
我们如何打造 Elasticsearch simdvec——这是 Elasticsearch 中每一次向量搜索查询背后的手动调优 SIMD 内核库。

如何衡量和提升 Elasticsearch 搜索召回率:通过混合搜索将召回率从 0.43 提升至 0.75
了解如何通过将 BM25 词汇搜索与 Jina AI 向量嵌入相结合来测量和提高 Elasticsearch 中的搜索召回率,并使用 rank_eval API 以实际数据验证改进效果。

基于 Elasticsearch + Jina 嵌入的无监督文档集群
一种使用 Elasticsearch 和 Jina 嵌入进行无监督文档集群的实用、可复现方法。


LINQ to Elasticsearch ES|QL:编写 C# 代码,查询 Elasticsearch
探索 Elasticsearch .NET 客户端中全新的 LINQ to Elasticsearch ES|QL 提供程序。借助该程序,您可以编写会自动转换为 ES|QL 查询的 C# 代码。