Kibana Lens让仪表盘的拖放变得非常简单,但当你需要几十个面板时,点击次数就会增加。如果你能勾画出一个仪表盘,截图后让法律硕士为你完成整个过程,那会怎么样?
在本文中,我们将实现这一目标。我们将创建一个应用程序,它可以获取仪表盘的图像,分析映射,然后生成仪表盘,而无需接触 Kibana!
步骤:
后台& 应用程序工作流程
我首先想到的是让 LLM 生成整个 NDJSON 格式的 Kibana保存对象,然后将它们导入 Kibana。
我们尝试了几种型号:
- 双子座 2.5 pro
- GPT o3 / o4-mini-high / 4.1
- 克劳德 4 号十四行诗
- Grok 3
- Deepseek (Deepthink R1)
至于提示语,我们从最简单的开始:
尽管我们看了一些简单的示例,并详细解释了如何建立每种可视化,但我们还是一无所获。如果您对这项实验感兴趣,请点击此处了解详情。
采用这种方法的结果是,在尝试将 LLM 生成的文件上传到 Kibana 时看到了这些信息:


这意味着生成的 JSON 无效或格式不当。最常见的问题是 LLM 生成不完整的 NDJSON、产生参数幻觉,或者返回普通 JSON 而非 NDJSON,无论我们如何努力去执行其他操作。
受这篇文章的启发--搜索模板比 LLM 自由式更有效--我们决定给 LLM 提供模板,而不是要求它生成完整的 NDJSON 文件,然后我们在代码中使用 LLM 给出的参数来创建适当的可视化。
申请工作流程如下:
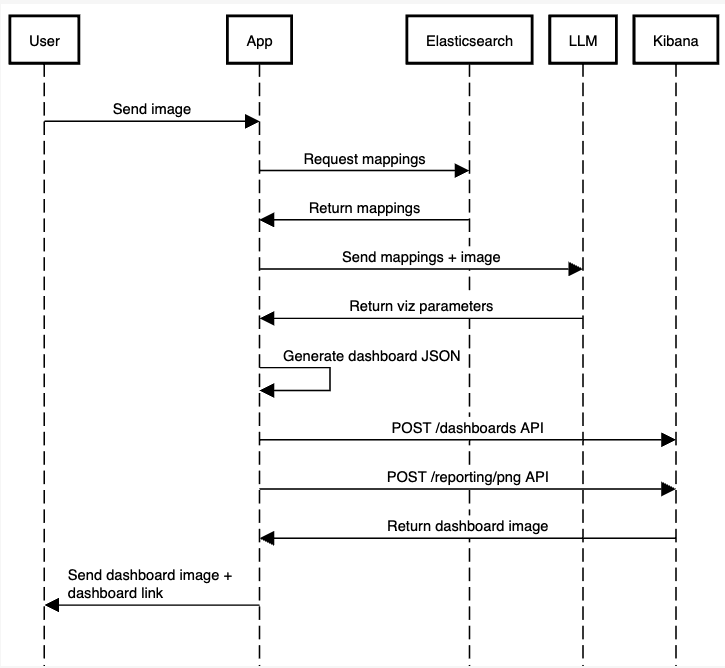
为简单起见,我们将省略一些代码,但您可以在 本 笔记本上找到完整应用程序的工作代码 。
准备工作
在开始开发之前,您需要具备以下条件:
- Python 3.8 或更高版本
- VenvPython 环境
- 运行的 Elasticsearch 实例及其端点和 API 密钥
- 存储在环境变量 OPENAI_API_KEY 下的 OpenAI API 密钥:
准备数据
在数据方面,我们将保持简单,使用 Elastic 样本网络日志。您可以在此了解如何将这些数据导入群集。
每份文档都包含向应用程序发出请求的主机的详细信息,以及请求本身及其响应状态的信息。下面是一个文件示例:
现在,让我们抓取刚刚加载的索引的映射,kibana_sample_data_logs :
我们将把映射与稍后加载的图像一起传递。
LLM 配置
让我们对 LLM 进行配置,使其使用结构化输出来输入图像,并接收包含我们需要传递给函数的信息的 JSON,以生成 JSON 对象。
我们安装依赖项:
Elasticsearch 将帮助我们检索索引映射。Pydantic 允许我们在 Python 中定义模式,然后要求 LLM 遵循这些模式,而LangChain框架则有助于更轻松地调用 LLM 和人工智能工具。
我们将创建一个 Pydantic 模式,以定义我们希望从 LLM 得到的输出。我们需要从图片中了解图表类型、字段、可视化标题和仪表盘标题:
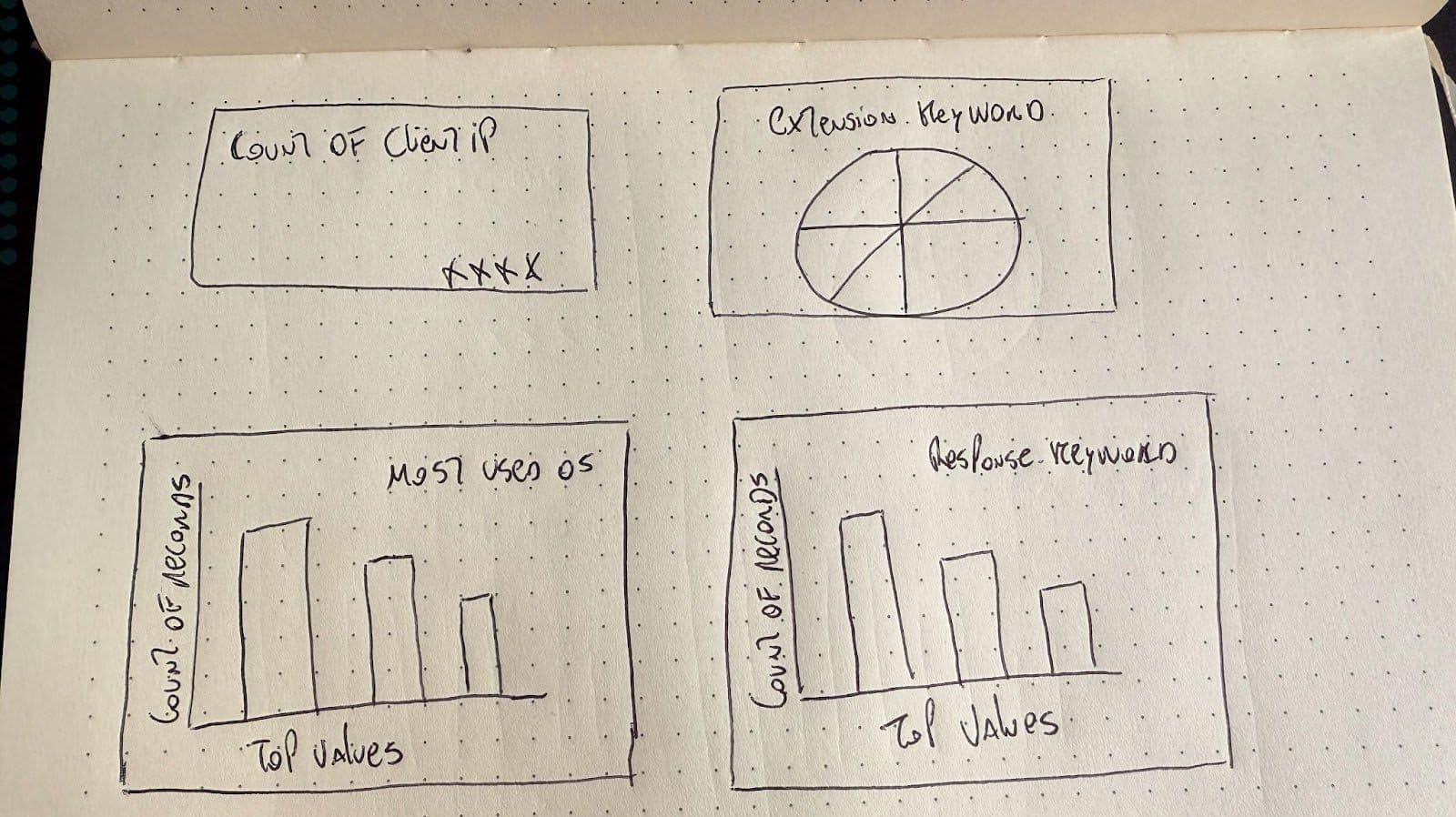
对于图像输入,我们将发送一个我刚刚画好的仪表盘:
现在我们声明 LLM 模型调用和图像加载。该函数将接收 Elasticsearch 索引的映射和我们要生成的仪表盘图像。
通过with_structured_output ,我们可以使用 PydanticDashboard 模式作为 LLM 生成的响应对象。通过Pydantic,我们可以定义带有验证功能的数据模型,从而确保 LLM 输出与预期结构相匹配。
要将图像转换为 base64 并作为输入发送,可以使用在线转换器 或用代码完成。
LLM 已经掌握了 Kibana 面板的上下文,因此我们不需要在提示中解释所有内容,只需提供一些细节,确保它不会忘记自己正在使用 Elasticsearch 和 Kibana。
让我们来分析一下提示:
| 部门 | 原因 |
|---|---|
| 您是根据 Kibana 9.0.0 版本的图像分析 Kibana 仪表板的专家。 | 通过强化 Elasticsearch 和 Elasticsearch 版本,我们降低了 LLM 产生旧参数/无效参数的可能性。 |
| 您将获得一个仪表盘图像和一个 Elasticsearch 索引映射。 | 我们解释说,图片是关于仪表盘的,以避免法律硕士做出任何错误的解释。 |
| 下面是仪表盘所基于的索引的索引映射,使用它可以帮助你理解数据和可用字段。索引映射: {index_mappings} | 提供映射至关重要,这样 LLM 才能动态选择有效字段。否则,我们就可能在这里硬编码映射,这太死板了,或者依靠图像包含正确的字段名,这也不可靠。 |
| 根据图像中可见的内容,只包含与每个可视化相关的字段。 | 我们必须添加这一增强功能,因为有时它会尝试添加与图像无关的字段。 |
这将返回一个包含要显示的可视化数组的对象:
处理 LLM 答复
我们在 上创建了一个 2x2 面板仪表盘示例,然后使用 "获取仪表盘 API "将其导出为 JSON 格式,然后将面板存储为可视化模板(饼状、条状、度量),在这些模板中,我们可以替换部分参数,根据问题创建带有不同字段的新可视化。
您可以在此处查看模板 JSON 文件。请注意我们是如何用 {variable_name} 更改我们稍后要替换的对象值的。

根据 LLM 提供的信息,我们可以决定使用哪个模板,替换哪些值。
fill_template_with_analysis 将接收单个面板的参数,包括可视化的 JSON 模板、标题、字段和可视化在网格上的坐标。
然后,它会替换模板的值,并返回最终的 JSON 可视化。
为了简单起见,我们将为 LLM 决定创建的面板分配静态坐标,并生成如上图所示的 2x2 网格仪表盘。
根据 LLM 决定的可视化类型,我们将选择一个 JSON 文件模板,并使用fill_template_with_analysis 替换相关信息,然后将新面板追加到稍后用于创建仪表盘的数组中。
仪表盘准备就绪后,我们将使用 创建 仪表盘 API 将新的 JSON 文件推送到 Kibana 以生成仪表盘:
要执行脚本并生成仪表盘,请在控制台中运行以下命令:
最终结果将是这样的

仪表板 URL: https://your-kibana-url/app/dashboards#/view/generated-dashboard-id
仪表板 ID: generated-dashboard-id
结论
在将文本转化为代码或将图像转化为代码时,LLM 展示了其强大的视觉能力。仪表盘 API 还能将 JSON 文件转化为仪表盘,而通过 LLM 和一些代码,我们就能将图片转化为 Kibana 仪表盘。
下一步是通过使用不同的网格设置、仪表盘大小和位置来提高仪表盘视觉效果的灵活性。此外,为更复杂的可视化和可视化类型提供支持也是对该应用程序的有益补充。
相关内容

2026年5月22日
Kibana 将仪表板加载时间最多缩短了 25%——以下是其背后的轮询策略
了解 Kibana 如何使用连续轮询和浏览器端 HTTP/2 检测将仪表板加载时间减少多达 25%,并自动回退到 HTTP/1。

用描述代替手动绘制:通过 MCP 和 ES|QL 构建 AI 原生 Kibana 仪表板。
从提示词到仪表板了解如何使用 example-mcp-dashbuilder 通过自然语言构建 Kibana 仪表板:这是一款开源 MCP 应用,能够编写 ES|QL 查询、创建交互式图表,并将功能完整的仪表板直接导出到 Kibana。

2026年5月25日
Kibana 中的 AI Chat 现已原生支持呈现仪表板
Kibana 中的 Elastic AI Chat 现在可根据自然语言构建仪表板,将可视化内容和分析保留在同一对话线程中,并支持将其保存为可重复使用的 Kibana 对象。


使用 Elasticsearch 与 LLM 进行实体解析,第 2 部分:通过 LLM 判断和语义搜索匹配实体
在 Elasticsearch 中使用语义搜索和透明 LLM 判断进行实体解析。