Ensuring semantic precision with minimum score
Improve semantic precision by employing minimum score thresholds. The article includes concrete examples for semantic and hybrid search.
Semantic search has opened up a world of opportunities for search relevance. High-quality sparse and dense models, such as ELSER, E5 and Jina Embedding v4, return relevant results based on the meaning of words, rather than keyword matching. However, semantic search sometimes returns irrelevant results at the tail end or for queries that lack relevant results in the index. This property of sparse and dense models can confuse users or waste precious tokens for large language models (LLMs).
In this article, you’ll learn how you can use the minimum score parameter to increase the precision of your semantic search results. If you’d like to test the examples provided in this blog post, go to the associated Jupyter notebook.
Background: Precision and recall
In search relevance, precision and recall are key concepts. Any reader not already familiar is highly encouraged to read up on them. Following is a summary.
Precision: The fraction of returned search results that are relevant to the user.
Recall: The fraction of all relevant documents in the corpus that are included in the search result set.
Or, in other words, precision is returning only relevant results; and recall is returning all relevant results. As you can imagine, these are often competing requirements. Semantic search tends to have very high recall but can struggle with precision. Keep reading to learn how to get around this property.
Introducing the minimum score parameter
The ‘min_score’ parameter allows us to improve precision by setting a minimum score, which will truncate the result set by removing any matches with a score less than the defined threshold. Following is a simple example:
GET search-movies/_search
{
"retriever": {
"linear": {
"min_score": 4,
"retrievers": [
...
]
}
}
}Normalizing the score
Setting a minimum score is all well and good; however, not all semantic models return a score suitable for a static threshold. ELSER, for example, returns a score that is unbounded. Some dense model scores are densely clustered and only make sense in the context of the specific query.
For most semantic search cases, we recommend using a normalization approach before applying the ‘min_score’. The normalization ensures that the document score is within a defined interval. Elasticsearch retrievers provide two such normalizers, ‘l2_norm’ and ‘minmax’. The most commonly used is ‘minmax’, since it’s easy to understand and works well in many scenarios. Key properties of ‘minmax’ include:
Document scores are distributed between 0–1.
The highest scoring document is always scored as 1.
The lowest scoring document is always scored as 0.
This can make it less suitable for keyword search. See “Hybrid search” section for further discussion.
Following is an example of a normalized semantic query with min_score. Rank window size has been increased to 500 to allow us to return a longer list of search results, starting at 100.
GET search-movies/_search
{
"size": 100,
"_source": [
"title", "overview"
],
"retriever": {
"linear": {
"rank_window_size": 500,
"min_score": 0.25,
"retrievers": [
{
"normalizer": "minmax",
"retriever": {
"standard": {
"query": {
"semantic": {
"field": "overview_vector",
"query": "superhero movie"
}
}
}
}
}
]
}
}
}The size has been set to a higher value than normally seen in production. This is so we can inspect the quality of search results and tune the results.
Hybrid search using the linear retriever
For hybrid search, the simplest approach is to normalize all scores, assign weights, and apply a minimum score. Note that by choosing weights with a sum of 1, you keep the total score within a range of 0–1. This makes it easy to make sense of the final scores and tune min_score. Following is an example:
GET search-movies/_search
{
"size": 100,
"_source": ["title", "overview","keywords"],
"retriever": {
"linear": {
"rank_window_size": 500,
"min_score": 0.25,
"retrievers": [
{
"weight": 0.6,
"normalizer": "minmax",
"retriever": {
"standard": {
"query": {
"semantic": {
"field": "overview_vector",
"query": "superhero movie"
}
}
}
}
},
{
"weight": 0.4,
"normalizer": "minmax",
"retriever": {
"standard": {
"query": {
"multi_match": {
"query": "superhero movie",
"fields": ["overview","keywords", "title"],
"type": "cross_fields",
"minimum_should_match": "2"
}
}
}
}
}
]
}
}
}Hybrid search using RRF
With BM25, we often control precision through other means, such as using the AND operator or minimum_should_match. In addition, queries consisting of single, precise, and rare terms will naturally cause search results with few search results, often all being highly relevant. This can lead to:
Results further back in the result get assigned a low normalized score in the BM25 retriever, even if the absolute BM25 score is close to top scoring hits.
When adding a very low BM25 score to the semantic score, the total can be approximated as the semantic score.
The lack of BM25 score contribution can cause the document to be discarded by the
min_score threshold.
As a solution, we can instead use reciprocal rank fusion (RRF) to combine BM25 and semantic results. RRF gets around the challenge of comparing scores from different search algorithms by instead focusing on the position in each result set. In this scenario, the min_score is only applied to the semantic retriever.
GET search-movies/_search
{
"_source": ["title", "overview","keywords"],
"retriever": {
"rrf": {
"rank_window_size": 500,
"retrievers": [
{
"linear": {
"rank_window_size": 500,
"min_score": 0.25,
"retrievers": [
{
"normalizer": "minmax",
"retriever": {
"standard": {
"query": {
"semantic": {
"field": "overview_vector",
"query": "superhero movie"
}
}
}
}
}
]
}
},
{
"standard": {
"query": {
"multi_match": {
"query": "superhero movie",
"fields": ["overview", "keywords","title"],
"type": "cross_fields",
"minimum_should_match": "2"
}
}
}
}
]
}
}
}Conclusion
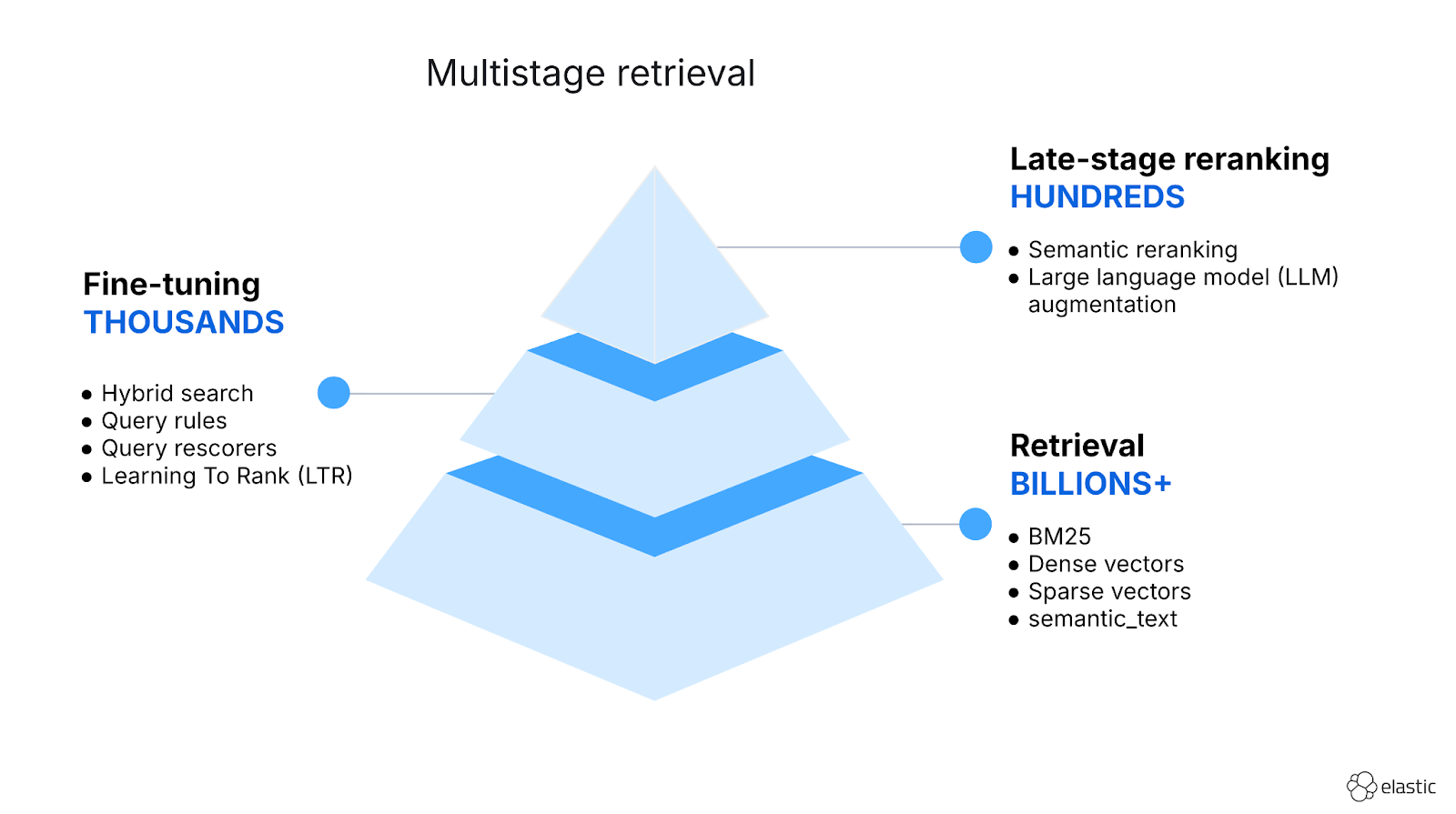
By using min_score, we’ve shown how we can reduce the number of false positives in our result sets caused by the high recall of semantic search algorithms. To learn more about retrievers, please see this blog post and the Elasticsearch documentation.
Related Content