Test Elastic's leading-edge, out-of-the-box capabilities. Dive into our sample notebooks in the Elasticsearch Labs repo, start a free cloud trial, or try Elastic on your local machine now.
The problem: Your old data is expensive (and getting more so)
As legal requirements change and data retention periods grow longer, many Elasticsearch customers have started to wonder: How can I retain my historical data without storage costs breaking the bank?
You've got your ILM policies humming along nicely. Fresh data comes in hot, ages into warm or cold, gets frozen as a searchable snapshot, and eventually—after 180 days, 10 years, or longer, depending on your compliance requirements—gets deleted.
When the delete action runs, it typically deletes the searchable snapshot with it. Sure, you might have regular snapshots elsewhere, but those aren't searchable without a full restore. If someone comes to you six months later asking, "Hey, can we check what happened in Q2 2023?" you're looking at a lengthy restore operation, a manual and time-consuming re-ingestion, or an awkward conversation about data retention policies.
The obvious solution is to just... not delete things, right? Keep those frozen indices around forever! But that creates its own problems:
- Cost creep: Frozen tier storage isn't free, and it adds up
- Cluster clutter: Managing hundreds or thousands of ancient frozen indices gets messy
- Wasted resources: You're paying for data to be "searchable" when you haven't searched it in months
What you really want is something in between: a way to keep the data accessible without drowning in S3 storage costs.
The solution: Deepfreeze makes old data cheap (but not gone)
Deepfreeze is a new repository management solution from Elastic. It allows you to retain searchable snapshots for deleted indices, move them to a cheaper S3 storage tier, and easily restore them if the saved data is needed again. All because Elasticsearch lets you delete an index while keeping its searchable snapshot intact.
When you configure your ILM delete action, there's an often-overlooked option available in the delete phase:
Set that to false, and when the index gets deleted, the snapshot repository keeps the snapshot files in S3. The index is gone from your cluster (no more rent!), but the underlying data is still sitting in your S3 bucket, waiting patiently.
But here's where it gets interesting: if you just leave those snapshots in the same repository, they're still "managed" by Elasticsearch, which means they must remain in a standard access tier. AWS S3 Intelligent-Tiering won't move them to cheaper tiers because, from S3's perspective, Elasticsearch still actively manages that bucket.
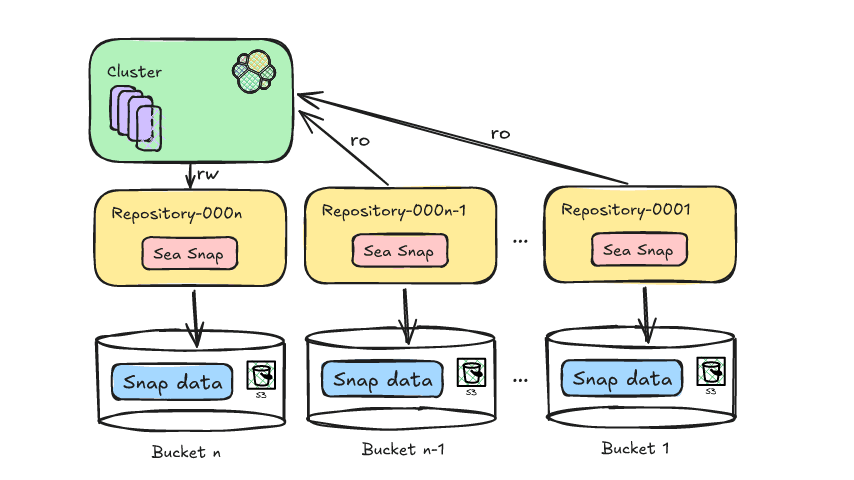
Deepfreeze solves this by rotating snapshot repositories.
Think of it like this: instead of one big filing cabinet where you keep adding folders forever, you start a new filing cabinet every month. Old cabinets get closed, labeled, and moved to cheaper storage. If you need something from an old cabinet, you can always bring it back out and open it up.
Note: Deepfreeze currently supports AWS. Azure and GCP are on the roadmap for future development.
How Deepfreeze works: Four steps to data freedom
Deepfreeze is a Python automation tool that runs periodically (typically via cron) to manage this rotation process. Here's what happens when you execute its monthly rotate action:
Step 1: Create a new S3 bucket
Deepfreeze creates a fresh S3 bucket with a one-up name (like Repository-000002). This bucket is configured with your preferred storage class—by default, this is Standard, but Intelligent Tiering is an option.

Please note that I use the term “bucket” here for ease of discussion. In reality, Deepfreeze creates new base paths inside a bucket to avoid any potential issues with AWS bucket creation limits. For simplicity, I refer to this combination of a bucket and a path as a bucket.
Step 2: Mount the bucket as an Elasticsearch repository
The new S3 bucket gets registered as a snapshot repository in your Elasticsearch cluster. Your ILM policies will now start using this repository for new frozen indices.
Step 3: Update ILM policies to use the new repository
Here's where the magic happens. Deepfreeze automatically:
- Scans all your ILM policies
- Finds any reference to the old repository in their
searchable_snapshotactions - Copies the ILM policies to new ones referencing the new repository
- Updates index templates to use the new policies
You don't have to edit dozens of policies manually. Deepfreeze handles it all.
Step 4: Unmount old repositories (but keep recent ones)
Deepfreeze maintains a sliding window of mounted repositories—by default, it keeps the last 6 months accessible. Older repositories get unmounted from Elasticsearch, but the S3 buckets remain intact.
Once unmounted, those buckets are no longer under active Elasticsearch management, and Deepfreeze can now move them to Glacier.

The benefits: Why you should care
Cost optimization
Elasticsearch's frozen tier storage is cheaper than hot or warm storage, but it still incurs standard S3 storage costs. The S3 Glacier tier can be 95% cheaper than standard S3 storage. Over months and years, this adds up to real money.

Data retention without the guilt
Compliance requirements often mandate keeping data for years. Deepfreeze lets you meet those requirements without constantly explaining to finance why your storage bill keeps growing.
Quick access when needed
Because the searchable snapshots are still in their native format, you can remount them using Elasticsearch's standard _mount API. No lengthy restore process, no reformatting—just point to the old repository and mount the index.
Deepfreeze makes this easier still, by keeping track of the datetime range of every repo it processes, making something like this possible, where the system does all the work of thawing data from the specified range by requesting the buckets from S3, mounting the repos when the data is available, and even mounting the indices that cover the specified dates:
After the duration has passed (30 days, by default), AWS automatically re-freezes the data to Glacier. Deepfreeze checks for this and updates its metadata, repositories, and indices during normal operations.
(AWS doesn’t actually move the data from Glacier to Standard. Instead, it copies the desired data back to Standard and then, when the duration has expired, it deletes it.)
Full automation
Run Deepfreeze on a schedule (the first of every month works for a monthly rotation) and forget about it. It handles all the tedious policy updates, bucket creation, and repository management automatically. Run it from cron or a .service file. Examples are available on GitHub.
Reduced cluster clutter
Your Elasticsearch cluster only needs to track the repositories that are actively mounted. Ancient indices don't show up in your cluster state, monitoring dashboards, or backup routines. Everything stays cleaner.
Configuration: Making Deepfreeze work for you
Deepfreeze is flexible. You can configure it via environment variables, command-line arguments, or both. For example, you can change the default number of mounted repositories by setting the DEEPFREEZE_KEEP environment variable. The default value is 6. Increasing this value gives you access to more data.
The ideal setting for the DEEPFREZE_KEEP value depends on the likelihood that older data is needed. If you rarely look at data older than a year, set the keep value to 12 to ensure your cluster has a full year of data; Deepfreeze will push anything older to glacier storage.
You can also change the AWS Storage Class and use intelligent_tiering (Auto-tiering based on access) instead of the default standard (Full-price, always accessible):
Options for each action are in the GitHub README.
Real-world use case
Whether you’re looking to ingest application logs, security events, IoT sensor data, or something entirely different, cost savings will depend on your ingest rate and retention periods.
For example, if you're ingesting 175GB of application logs per day, but typically only need the last 6 months searchable for troubleshooting. Assume compliance requires 7 years of retention:
Without Deepfreeze:
- Keep 7 years × 60TB = 420TB in frozen tier
- Cost: ~$9,660/month
With Deepfreeze:
- Keep 6 months × 30TB = 30TB in frozen tier: $690/month
- Keep 6.5 years × 390TB in S3 Archive: $1,560/month
- Total: $2,250/month (77% savings)
Technical deep dive: under the hood
For those who want to understand what's really happening, here's a peek at the implementation.
The Deepfreeze process flow
Key implementation details
Smart repository discovery: The tool discovers repositories by prefix matching, ensuring it only manages repositories it created:
Automatic ILM policy updates: No manual policy editing required. Deepfreeze walks the policy structure and updates repository references:
Important considerations
The S3 Intelligent-Tiering question
There's an interesting architectural question worth discussing: How does AWS S3 Intelligent-Tiering classify the temperature of unmounted searchable snapshots?
The idea is that once unmounted from Elasticsearch, the S3 bucket is no longer actively managed, so access patterns drop to zero, and Intelligent-Tiering should move the data through Archive Access tiers down to Deep Archive Access (or even Glacier Instant Retrieval).
Because this relies on everything playing nice and leaving the data untouched and unaccessed for at least 90 days, Deepfreeze defaults to putting repositories in Standard and moving them to Glacier as soon as they’ve been unmounted, rather than waiting for IT to decide it’s time. We ensure that the data moves to Glacier as quickly as possible, but not before.
Initial setup requirements
Before running Deepfreeze, you need:
1. ILM policies configured to retain searchable snapshots:
2. At least one existing repository with your chosen prefix (deepfreeze validates this)
3. AWS credentials configured for S3 access (via environment, IAM role, or credentials file)
4. Elasticsearch authentication with privileges to manage repositories and ILM policies
The setup command runs a comprehensive set of pre-checks to ensure the conditions are right before it starts.
Post-setup tasks
Deepfreeze just creates the environment for managing repositories; it doesn’t help your data get into those repos. We don’t know your business and what data you want preserved for posterity. After the Deepfreeze setup runs, ensure you have at least one ILM policy that uses this repo with snapshot deletion disabled. You will also need to ensure that you have an index template that associates this ILM policy with an index or data stream you want to preserve.
Getting started
Installation
Basic usage
Recommended workflow
- Start small: Test with a single index or low-priority data
- Monitor costs: Watch your AWS bill for the first few months to verify savings
- Verify tiering: Check S3 metrics to ensure Intelligent-Tiering is working as expected if chosen
- Automate gradually: Once confident, add to cron and expand to more indices
The bottom line
Deepfreeze solves a real problem that many Elasticsearch operators face: how do you keep historical data accessible without going broke?
By automating the rotation of snapshot repositories and letting AWS S3's native tiering capabilities do the heavy lifting, you get:
- ✅ Massive cost savings on long-term data retention
- ✅ Full compliance with data retention policies
- ✅ Quick access to recent historical data (6 months by default)
- ✅ On-demand remounting of older data when needed
- ✅ Clean, automated workflow that runs itself
Deepfreeze works with your existing ILM policies and requires minimal configuration. It's not a redesign of your entire data management strategy—it's an optimization that pays for itself almost immediately.
There are costs associated with retrieving data from Glacier, and it does take time (6 hours for Standard retrieval as of this writing). Still, if you anticipate frequently needing your historical data, Deepfreeze may not be a great fit, and keeping your data in frozen tiers might be a better solution.
If you're running Elasticsearch at scale and storing more than a few months of historical data, Deepfreeze is worth a serious look. Your CFO will thank you, and you'll sleep better knowing that you can still fulfill a six-month-old audit request.
Resources & next steps
- Repository: github.com/elastic/deepfreeze
- Documentation: See /
README.mdand thedocs/directory in the repository - Dependencies: Python 3.8+, others as described in
pyproject.toml
Have questions or want to share your deepfreeze success story? Open an issue on GitHub or reach out!
Related Content

July 9, 2026
Why Elasticsearch is becoming a columnar database
Elasticsearch is becoming a first-class columnar database. Columnar Mode ships in 9.5, storing data once alongside the existing modes and cutting storage footprints while speeding up analytical queries.

July 7, 2026
Your compliance posture just got an upgrade: Elasticsearch now supports FIPS 140-3
Elastic 9.4 brings FIPS 140-3 support for Elasticsearch and Kibana to GA. Here's what changes for federal, defense and regulated deployments, and how to migrate from 140-2.

July 2, 2026
A simdvec deep-dive: How Elasticsearch uses neural-net and video-codec CPU instructions for vector search
Four ways Elasticsearch's vector search engine reuses neural-network, video-codec and cryptography CPU instructions for up to 6x speedups; with the math, the failed attempts and the benchmarks.

June 29, 2026
Bringing it together: How we rebuilt Elasticsearch as a columnar metrics engine; 6.6x less storage, 160x faster queries
Elasticsearch metrics in version 9.4 run on a fully columnar engine: 6.6x less storage, 160x faster queries, native PromQL and OTel support.
June 19, 2026
Why your Elasticsearch cluster is hitting disk watermarks: 14 real-world causes explained
Learn how Elasticsearch disk watermarks work, why they trigger, and how to diagnose 14 of the most common scenarios Support encounters, from index bloat to ILM stalls.