Elasticsearch has native integrations with the industry-leading Gen AI tools and providers. Check out our webinars on going Beyond RAG Basics, or building prod-ready apps with the Elastic vector database.
To build the best search solutions for your use case, start a free cloud trial or try Elastic on your local machine now.
In the rapidly advancing world of artificial intelligence, one of the most intriguing and transformative developments is generative artificial intelligence (GAI). GAI represents a significant leap forward in AI capabilities, enabling machines to generate original and creative content across various domains including conversations, stories, images, videos, and music. Enterprises seek not only top-performing infrastructure, but also a secure platform to harness the power of GAI without compromising their sensitive data and intellectual property. Large language models (LLMs) strive to understand and produce text that resembles human language, utilizing the structure, meaning, and context of natural language.
Elastic and Amazon Web Services (AWS) understand this pressing need and have taken the lead in offering cutting-edge solutions to meet these demands. Using Amazon SageMaker JumpStart combined with Elasticsearch’s capabilities, businesses can now confidently explore and adopt the most suitable AI models for their specific use cases while maintaining cost-effectiveness, security, and privacy.
Elasticsearch’s integration with advanced AI models further enhances its capabilities. By leveraging Elasticsearch’s retrieval prowess, LLMs can access the most relevant documents to provide accurate and up-to-date responses. This synergy between Elasticsearch and LLMs ensures that users receive contextually relevant and factual answers to their queries, setting a new standard for information retrieval and AI-powered assistance.
Elasticsearch is a scalable data store and vector database that offers a range of features to ensure exceptional search performance. It supports traditional keyword and text-based search using the BM25 algorithm, as well as AI-ready vector search with exact match and approximate kNN (k-Nearest Neighbor) search capabilities. These advanced features allow Elasticsearch to retrieve highly relevant results for queries expressed in natural language. By combining traditional, vector, or hybrid search approaches, Elasticsearch delivers precise results, making it effortless for users to find the information customers need.
The Elasticsearch platform seamlessly incorporates robust machine learning and artificial intelligence capabilities directly into its solutions, empowering you to create highly sought-after applications and accomplish tasks with remarkable efficiency. By leveraging these advanced technologies, you can harness the full potential of Elasticsearch to deliver exceptional user experiences and expedite your workflow.
Implementing RAG using Elasticsearch and open source LLM available in Amazon SageMaker JumpStart
The solution below explains how to use Retrieval Augmented Generation (RAG) to enable GAI capabilities on domain-specific business data using Elasticsearch, Amazon SageMaker JumpStart, and your choice of open source LLMs.
Solution overview
We will start by reviewing the architecture diagram below. It explains how to get domain-specific responses from an LLM hosted in Amazon SageMaker JumpStart using enterprise data hosted in Elasticsearch using RAG.
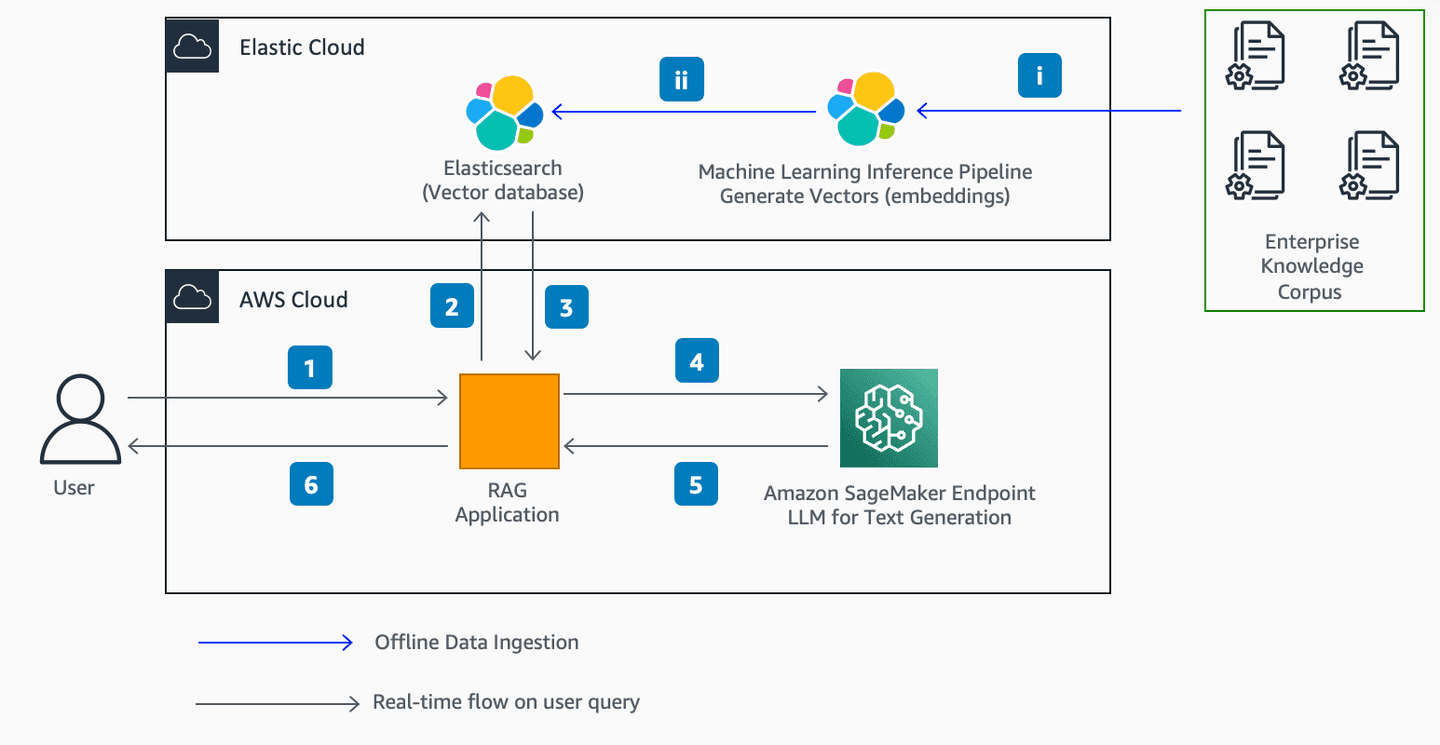
We used the following AWS and third-party services:
- Amazon SageMaker and Amazon SageMaker JumpStart for hosting the open source LLMs from Hugging Face
- Falcon 40B Instruct and Flan-T5 XL LLM from Hugging Face
- Elasticsearch for storing embeddings of the enterprise knowledge corpus and doing similarity search with user questions
- Python, LangChain, and Streamlit for building the RAG application
- Amazon EC2 for hosting the Streamlit application
- AWS Identity and Access Management roles and policies for access management
Step-by-step explanation
Offline data ingestion:
We ingest data from an enterprise knowledge corpus – for example this could be internal web pages, documents describing a company’s process, or corporate financial data.
- The documents are ingested using a web crawler or any other ingestion mechanism.
- The textual content is converted into vectors and stored in a dense_vector field by a sentence transformer type ML model.
Real-time flow on user query:
- The user provides a question via the Retrieval Augmented Generation (RAG) web application.
- The RAG application generates a hybrid search request for Elasticsearch based on the user's question and sends it to Elasticsearch. The hybrid search request does a BM25 match on the text field and kNN search on the dense_vector field.
- Elasticsearch returns the document body and source URL (if applicable) to the RAG application. The RAG application accepts only the top scored document.
- The RAG application passes the top scored document body (context) along with user question (prompt) to the LLM hosted as Amazon SageMaker endpoint.
- The Amazon SageMaker endpoint generates a textual response and sends it back to the RAG application.
- The RAG application performs any required post processing tasks. For example, it adds a source url to the response generated from the LLM. The user views the response in the web application.
Let’s now look at a few setup steps and a few implementation steps to create a working search solution:
Setup steps:
- Sign up for a free trial of an Elasticsearch cluster with Elastic Cloud.
- Create a new deployment on AWS following these steps.
- Add a new machine learning node following the steps below. This will enable you to run machine learning models in your deployment.
- Click on Edit under Deployment Name in the left navigation bar.
- Scroll down to the Machine Learning instances box.
- Click +Add Capacity.
- Under Size per zone, click and select 2GB RAM.
- Click on Save and then Confirm.
- Reset and download the elastic user password following these steps.
- Copy the deployment ID from the Overview page under Deployment name.
- Load an embedding model into Elasticsearch. Here, we have usedall-distilroberta-v1 model hosted in the Hugging Face model hub. You can choose other sentence transformer types based on your case. Import this Python notebook here in Amazon SageMaker and run it. Provide the Cloud Id , Elasticsearch username , and Elasticsearch password when prompted. This will download the model from Hugging Face, chunk it up, load it into Elasticsearch, and deploy the model onto the machine learning node of the Elasticsearch cluster.
- Create an Elasticsearch index by opening Kibana from the Elastic Cloud console and navigating to Enterprise Search - Overview. Click on Create an Elasticsearch Index. Choose Web Crawler as the Ingestion method. Enter a suitable Index name and click Create Index.
- Add an Inference Pipeline by clicking on Pipelines tab > Copy and customizing it in the Ingest Pipeline Box. Click Add Inference Pipeline in the Machine Learning Inference Pipelines box. Enter the Name for the new pipeline. Select the trained Model loaded in step 6 and Select title as source field. Click Continue in two subsequent screens and click Create Pipeline at the Review stage.

- Update the mapping for dense vector by clicking on Dev Tools and running the following code. This will enable you to run kNN search on the title field vectors. From Elasticsearch version 8.8+, this step will be handled automatically.
- Configure web crawler to crawl Elastic Docs (you can replace this with your Enterprise Domain corpus). Click on the relevant index under Available indices. Click on the Manage Domains tab. Click Add domain. Enter https://www.elastic.co/guide/en and click Validate Domain. Click Add domain and then Add Crawl rules. Add the following rules. Click Crawl and then Crawl all domains on this index. This will start Elasticsearch’s web crawler and it will crawl the targeted documents, generate vectors for the title field, and index the document and vector.

The implementation steps for instantiating the solution presented in this post are as follows:
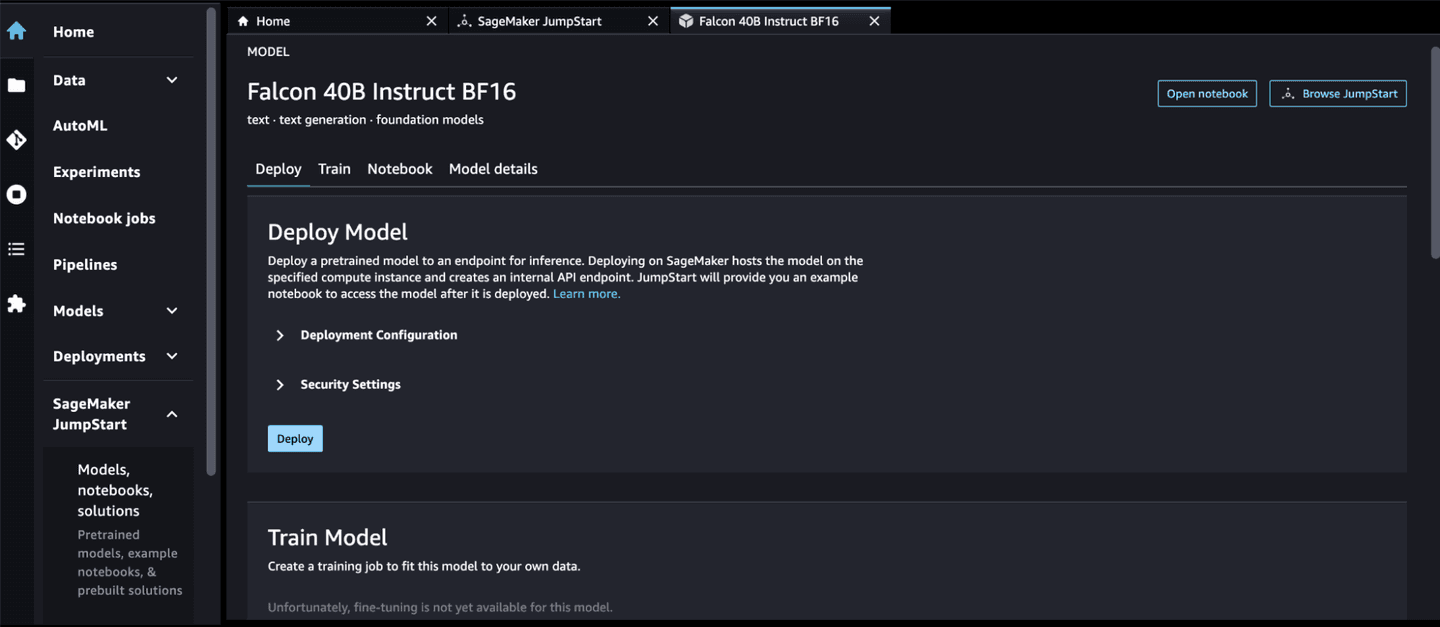
- Choose your LLM. Amazon SageMaker JumpStart offers a wide selection of proprietary and publicly available foundation models from various model providers. Log in to Amazon SageMaker Studio, open Amazon SageMaker JumpStart, and search for your preferred Foundation model. Please find the list of models available for each task here.

- Deploy your LLM. Amazon SageMaker JumpStart studio also provides a no-code interface to deploy the model. You can easily deploy a model with few clicks. After the deployment is successful, copy the Endpoint Name.
- Download and set up the RAG Application. Launch an EC2 instance and clone the code from this GitHub link. Set up a virtual environment following these steps. Install the required Python libraries by running the command pip install -r requirements.txt. Update the config.sh file with the following:
- ES_CLOUD_ID: Elastic Cloud Deployment ID
- ES_USERNAME: Elasticsearch Cluster User
- ES_PASSWORD: Elasticsearch User password
- FLAN_T5_ENDPOINT: Amazon SageMaker Endpoint Name pointing to Flan T5
- FALCON_40B_ENDPOINT: Amazon SageMaker Endpoint Name pointing to Falcon 40B
- AWS_REGION: AWS Region
- Run the application using the command streamlit run rag_elastic_aws.py. This will start a web browser and the url will be printed to the command line.
- Response of LLM without context.

- Response of LLM with context derived from Elasticsearch.

Conclusion
In this post, we showed you how to create a Retrieval Augmented Generation-based search application using a combination of Elasticsearch, Amazon SageMaker JumpStart, open-source LLMs from Hugging Face, and open source Python packages like LangChain and Streamlit.
Learn more by exploring JumpStart, Amazon Titan models, Amazon Bedrock, and Elastic to build a solution using the sample implementation provided in this post and a data set relevant to your business.
Or, start your own 7-day free trial by signing up via AWS Marketplace and quickly spin up a deployment in minutes on any of the Elastic Cloud regions on AWS around the world. Your AWS Marketplace purchase of Elastic will be included in your monthly consolidated billing statement and will draw against your committed spend with AWS.
The release and timing of any features or functionality described in this post remain at Elastic's sole discretion. Any features or functionality not currently available may not be delivered on time or at all.
In this blog post, we may have used or referred to third party generative AI tools, which are owned and operated by their respective owners. Elastic does not have any control over the third party tools and we have no responsibility or liability for their content, operation or use, nor for any loss or damage that may arise from your use of such tools. Please exercise caution when using AI tools with personal, sensitive or confidential information. Any data you submit may be used for AI training or other purposes. There is no guarantee that information you provide will be kept secure or confidential. You should familiarize yourself with the privacy practices and terms of use of any generative AI tools prior to use.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine and associated marks are trademarks, logos or registered trademarks of Elasticsearch N.V. in the United States and other countries. All other company and product names are trademarks, logos or registered trademarks of their respective owners.
Frequently Asked Questions
What is generative artificial intelligence (GAI)?
GAI represents a significant leap forward in AI capabilities, enabling machines to generate original and creative content across various domains including conversations, stories, images, videos, and music.
Related Content

July 7, 2026
Short queries, formal documents: how HyDE improved semantic search precision by 50% in Elasticsearch
HyDE boosts semantic search precision and recall by 50% on short queries. Here's how to implement it in Elasticsearch with the Inference API and semantic_text.

June 24, 2026
Elasticsearch DiskBBQ delivers 7x faster vector search than Qdrant on network-attached storage
Elasticsearch DiskBBQ achieves up to 7x higher vector search throughput than Qdrant at comparable recall on network-attached storage. Explore the benchmark methodology and full results.

July 6, 2026
Who grades the grader? LLM-as-a-Judge inside Elasticsearch Workflows
Find out if your RAG agent is ready to ship. Score it on correctness, faithfulness and retrieval quality using only Elasticsearch Workflows and two Claude models.

June 15, 2026
Your search index is already an agent memory system: Persistent agent memory for Claude Code with Elasticsearch
Give your AI agent persistent cross-session memory using Elasticsearch: Hybrid recall, a knowledge graph, and cross-device handoffs. Three commands to install.

June 15, 2026
Your FAQ bot doesn't need a PhD: LLM query routing with Elastic Workflows
Route LLM queries by complexity using Elasticsearch search metadata: Mistral Small for FAQ questions, Claude Sonnet for multi-source synthesis.