Check out the different ways to ingest data into Elasticsearch and dive into practical examples to try something new.
Elasticsearch is packed with new features to help you build the best search solutions for your use case. Start a free cloud trial or try Elastic on your local machine now.
Data ingestion into Elasticsearch using Apache Camel is a process that combines the robustness of a search engine with the flexibility of an integration framework. In this article, we will explore how Apache Camel can simplify and optimize data ingestion into Elasticsearch. To illustrate this functionality, we will implement an introductory application that demonstrates, step by step, how to configure and use Apache Camel to send data to Elasticsearch.
What is Apache Camel?
Apache Camel is an open-source integration framework that simplifies connecting diverse systems, allowing developers to focus on business logic without worrying about the complexities of system communication. The central concept in Camel is "routes," which define the path a message follows from origin to destination, potentially including intermediate steps such as transformations, validations, and filtering.
Apache Camel architecture

Camel uses "components" to connect to different systems and protocols, such as databases and messaging services, and "endpoints" to represent the entry and exit points of messages. These concepts provide a modular and flexible design, making it easier to configure and manage complex integrations efficiently and scalably.
Using Elasticsearch and Apache Camel
We will demonstrate how to configure a simple Java application that uses Apache Camel to ingest data into an Elasticsearch cluster. The processes of creating, updating, and deleting data in Elasticsearch using routes defined in Apache Camel will also be covered.
1. Adding dependencies
The first step in configuring this integration is to add the necessary dependencies to your project's pom.xml file. This will include the Apache Camel and Elasticsearch libraries. We will be using the new Java API Client library, so we must import the camel-elasticsearch component and the version must be the same as the camel-core library.
If you want to use the Java Low level Rest Client, you must use the Elasticsearch Low level Rest Client component.
2. Configuring and running the Camel Context
The configuration begins by creating a new Camel context using the DefaultCamelContext class, which serves as the base for defining and executing routes. Next, we configure the Elasticsearch component, which will allow Apache Camel to interact with an Elasticsearch cluster. The ESlasticsearchComponent instance is configured to connect to the address localhost:9200, which is the default address for a local Elasticsearch cluster. For an environment setup that requires authentication, you should read the documentation on how to configure the component and enable basic authentication, referred to as "Configure the component and enable basic authentication".
This component is then added to the Camel context, enabling the defined routes to use this component to perform operations in Elasticsearch.
Afterward, the routes are added to the context. We will create routes for bulk indexing, updating, and deleting documents.
3. Configuring Camel routes
Data indexing
The first route we will configure is for data indexing. We will use a JSON file containing a movie catalog. The route will be configured to read the file located at src/main/resources/movies.json, deserialize the JSON content into Java objects, and then apply an aggregation strategy to combine multiple messages into one, allowing batch operations in Elasticsearch. The size of 500 items per message was configured, that is, the bulk will index 500 films at a time.
Route Elasticsearch Operation Bulk
The batch of documents will be sent to Elasticsearch's bulk operation endpoint. This approach ensures efficiency and speed when handling large volumes of data.
Data update
The next route will be to update documents. We indexed some movies in the previous step and now we will create new routes to search for a document by reference code and then update the rating field.
We set up a Camel context (DefaultCamelContext), where an Elasticsearch component is registered and a custom route IngestionRoute is added. The operation starts by sending the document code through the ProducerTemplate, which starts the route from the direct:update-ingestion endpoint.
Next, we have the IngestionRoute, which is the input endpoint for this flow. The route performs several pipelined operations. First, a search in Elasticsearch is done to locate the document by code (direct:search-by-id), where the SearchByCodeProcessor assembles the query based on the code. Then, the retrieved document is processed by the UpdateRatingProcessor, which converts the result into Movie objects, updates the movie rating to a specific value, and prepares the updated document to be sent back to Elasticsearch for updating.
The SearchByCodeProcessor processor was configured only to execute the search query:
The UpdateRatingProcessor processor is responsible for updating the rating field.
Data deletion
Finally, the route for deleting documents is configured. Here, we will delete a document using its ID. In Elasticsearch, to delete a document we need to know the document identifier, the index where the document is stored and execute a Delete request. In Apache Camel we will perform this operation by creating a new route as shown below.
The route starts from the direct:op-delete endpoint, which serves as the entry point. When a document needs to be deleted, its identifier (_id) is received in the body of the message. The route then sets the indexId header with the value of this identifier using simple("${body}"), which extracts the _id from the body of the message.
Finally, the message is directed to the endpoint specified by URI_DELETE_OPERATION, which connects to Elasticsearch to perform the document removal operation in the corresponding index.
Now that we have created the route, we can create a Camel context (DefaultCamelContext), which is configured to include the Elasticsearch component.
Next, the delete route, defined by the OperationDeleteRoute class, is added to the context. With the context initialized, a ProducerTemplate is used to pass the identifier of the document that should be deleted to the direct:op-delete endpoint, which triggers the delete route.
Conclusion
The integration between Apache Camel and Elasticsearch allows for robust and efficient data ingestion, leveraging Camel's flexibility to define routes that can handle different data manipulation scenarios, such as indexing, updating, and deleting. With this setup, you can orchestrate and automate complex processes in a scalable manner, ensuring that your data is managed efficiently in Elasticsearch. This example demonstrated how these tools can be used together to create an efficient and adaptable solution for data ingestion.
References
Frequently Asked Questions
What is Apache Camel?
Apache Camel is an open-source integration framework that simplifies connecting diverse systems, allowing developers to focus on business logic without worrying about the complexities of system communication.
Related Content
June 19, 2026
Why your Elasticsearch cluster is hitting disk watermarks: 14 real-world causes explained
Learn how Elasticsearch disk watermarks work, why they trigger, and how to diagnose 14 of the most common scenarios Support encounters, from index bloat to ILM stalls.
June 12, 2026
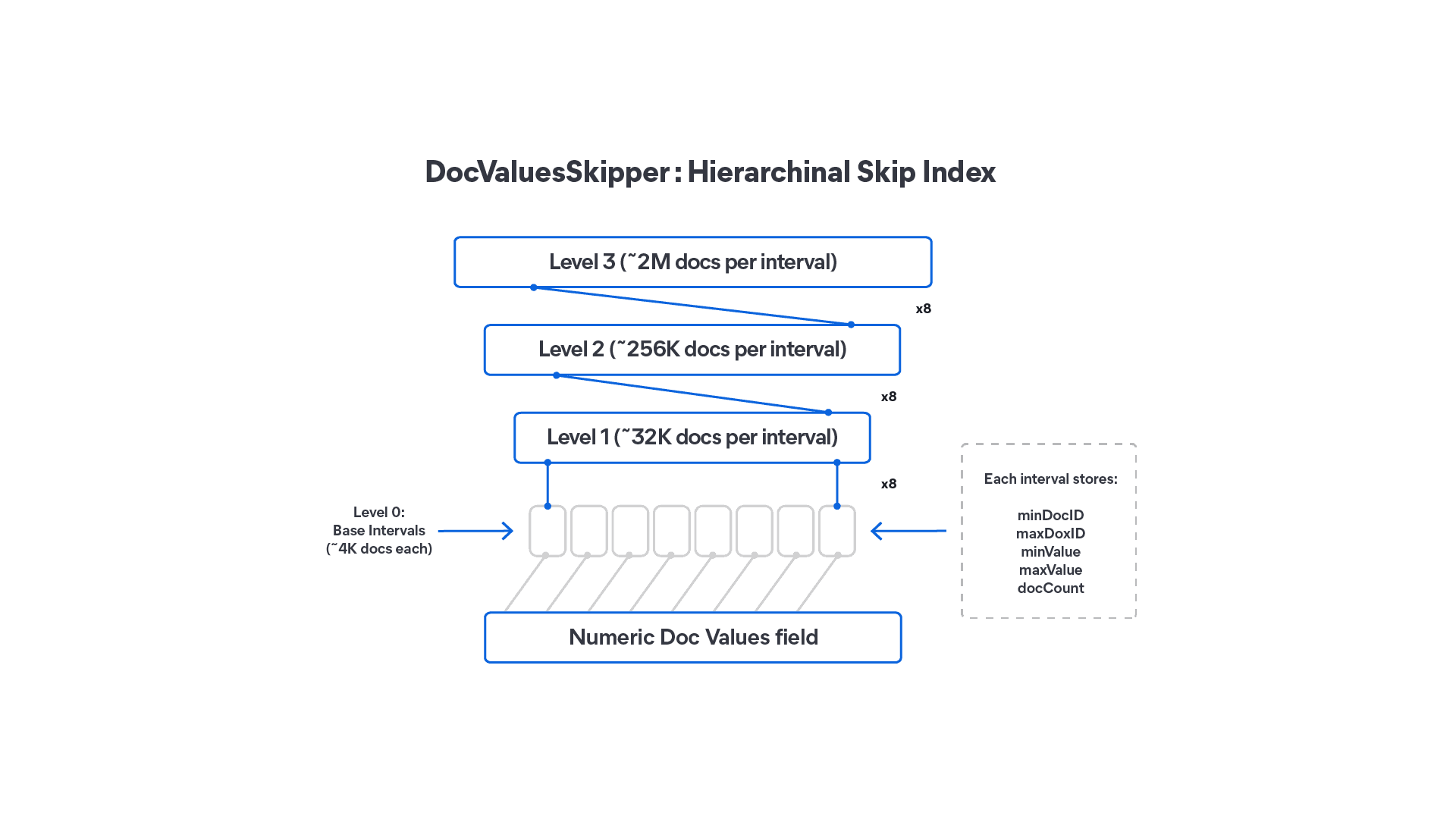
How DocValuesSkippers in Lucene 10 make range queries faster without doubling your storage
DocValuesSkippers add block-level skipping to Lucene DocValues fields, speeding up range queries on sorted or insert-ordered indexes with less than 0.1% storage overhead.

June 2, 2026
Elasticsearch reindex now relocates across nodes automatically: zero user intervention, no lost progress
Elasticsearch reindex now survives node shutdowns, uses Point in Time for more efficient source iteration, and ships with dedicated management APIs. Reindex-from-remote is GA in Serverless.

May 20, 2026
Elasticsearch downsampling methods: last-value vs. aggregate sampling
Elasticsearch downsampling now gives you a choice: last-value sampling for maximum storage savings or aggregate sampling for precise rate calculations and counter resets, both fully queryable in ES|QL.

April 2, 2026
When TSDS meets ILM: Designing time series data streams that don't reject late data
How TSDS time bounds interact with ILM phases; and how to design policies that tolerate late-arriving metrics.