Teste da nova camada cold de snapshots buscáveis do Elasticsearch em escala
A camada cold de snapshots buscáveis, que anteriormente estava em beta no Elasticsearch 7.10, agora está com disponibilidade geral no Elasticsearch 7.11. Essa nova camada de dados reduz o armazenamento do cluster em até 50% em relação à camada warm, mantendo o mesmo nível de confiabilidade e redundância das camadas hot e warm.
Neste post do blog, daremos uma olhada nos cenários que exploramos para garantir que a camada cold funcione perfeitamente em escala, destacando a importância que damos à qualidade e à confiabilidade das nossas soluções.
Para lembrar o que é a camada cold
A camada cold reduz os custos do cluster ao manter apenas os shards principais no armazenamento local, eliminando a necessidade de shards de réplica e contando com snapshots (mantidos em armazenamentos de objetos como AWS S3, Google Storage ou Microsoft Azure Storage) para fornecer a resiliência necessária. O armazenamento local atua essencialmente como uma versão em cache dos dados do snapshot no repositório.
No caso de um nó cold ou armazenamento local tornar-se não íntegro, os snapshots buscáveis recuperarão e rebalancearão automaticamente os shards em outros nós.
No caso de reinicializações do cluster completo ou contínuas (ou reinicializações do nó), o armazenamento local é persistente, e os dados disponíveis localmente não serão baixados novamente dos snapshots, minimizando o tempo necessário para o cluster voltar a ficar íntegro (status verde), além de evitar custos de rede desnecessários.
Para garantir que tudo isso funcione conforme o esperado em escala, concentramos nossos esforços de validação em três cenários, todos usando:
- Cinco nós do Elasticsearch (heap de 16 GB)
- Seis discos magnéticos de 2 TB na configuração RAID-0
- Um snapshot de 5 TB de dados de logging, espalhados por 10 índices com cinco shards cada, mesclado à força em um único segmento (a mesclagem forçada otimiza o índice para acesso de leitura e reduz o número de arquivos que precisam ser restaurados em caso de um evento de falha)
Cenário 1: reinicialização do cluster completo
O primeiro cenário que validamos foi o de reinicializações do cluster completo. Para verificar isso, passamos pelas seguintes etapas:
- Montar o snapshot buscável de 5 TB e aguardar até que o cache local esteja totalmente preaquecido (Fase 0).
- Executar uma reinicialização do cluster completo de acordo com as diretrizes para reinicialização do cluster completo.
- Após reabilitar a alocação, mensurar quanto tempo leva para o cluster:
- Ficar íntegro (verde).
- Concluir todos os downloads em segundo plano para preaquecer os caches.
- Garantir não haja nenhum rebalanceamento de shard adicional após a etapa 3.
Graças à camada de persistência que foi recentemente introduzida no Elasticsearch 7.11, após a inicialização de todos os nós e a reabilitação da alocação, o cluster ficou verde imediatamente e nenhum download em segundo plano ocorreu.
Abaixo, podemos ver o tráfego de rede cumulativo durante a montagem (Fase 0) e após uma reinicialização do cluster completo e a reabilitação da alocação (Fase 1, sem tráfego de rede adicional):

Cenário 2: reinicialização contínua
O segundo cenário que validamos foi o caso comum de reinicializações contínuas do cluster.
O experimento foi semelhante à reinicialização do cluster completo:
- Montar o snapshot buscável de 5 TB e aguardar até que o cache local esteja totalmente preaquecido.
- Executar o procedimento de reinicialização contínua para o primeiro nó, desabilitando a alocação dos shards antes de parar cada nó.
- Iniciar o nó e, depois de reabilitar a alocação dos shards, mensurar o tempo que levaria para o cluster ficar verde. Esperávamos que isso fosse rápido devido ao cache persistente. Também garantimos que nenhum download desnecessário em segundo plano ocorresse após cada reinicialização.
- Repetir as etapas 2 e 3 para todos os outros nós do cluster.
Esse experimento também foi um sucesso e, graças ao cache persistente, introduzido no Elasticsearch 7.11, o cluster chegou ao status verde de forma praticamente instantânea e não ocorreu nenhum download em segundo plano adicional do snapshot.
Cenário 3: falha do nó
Por fim, queríamos garantir o comportamento correto na falha de um nó. Fizemos o seguinte experimento:
- Montar o snapshot buscável de 5 TB e aguardar até que o cache local esteja totalmente preaquecido (Fase 0).
- Dos cinco nós, matar um nó do Elasticsearch (nó-1, usando
SIGKILL) e esperar até que o cluster fique verde novamente (Fase 1).- Garantir que os downloads em segundo plano estejam relacionados ao recebimento de dados de shards hospedados pelo nó morto.
- Depois de chegar ao status verde, nenhum rebalanceamento adicional deve ocorrer.
- Iniciar o nó com falha novamente (Fase 2):
- Apenas a recuperação de iguais deve ocorrer (uma vez que todos os dados existem nos quatro nós restantes) para rebalancear os shards.
- O cluster deve ficar verde.
Novamente, esse experimento foi bem-sucedido. Depois que o nó-1 morreu, os nós restantes restauraram automaticamente os shards (a partir de snapshots buscáveis) hospedados pelo nó ausente.
Nenhum rebalanceamento adicional aconteceu depois que o cluster ficou verde, como pode ser visto no gráfico abaixo visualizando o tráfego de rede por nó:
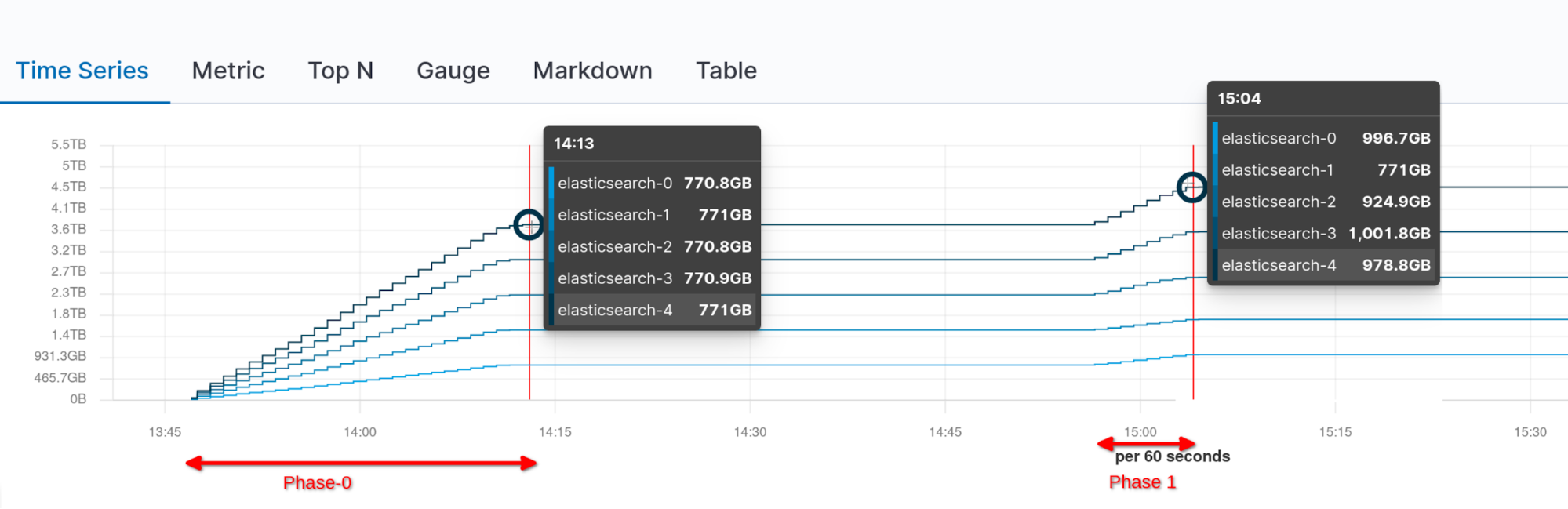
Após trazermos de volta o nó ausente, a recuperação de iguais foi iniciada, e o nó-1 acabou hospedando novamente a quantidade necessária de shards para ter um cluster uniformemente distribuído.

Comece hoje mesmo
Esperamos que essa jornada de validação de recursos tenha sido tão interessante para você quanto foi empolgante para nós!
Para começar a usar os snapshots buscáveis e armazenar dados na camada cold, prepare um cluster no Elastic Cloud ou instale a versão mais recente do Elastic Stack. Já tem o Elasticsearch em execução? Basta atualizar seus clusters para a versão 7.11 e experimentar. Se quiser saber mais, leia a documentação sobre camadas de dados e snapshots buscáveis.