Como maximizar o desempenho do Elasticsearch ao adicionar nós a um cluster


 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
Adicionar nós a um cluster do Elasticsearch permite a expansão para cargas de trabalho gigantescas. É fundamental compreender as formas ideais de expandir o cluster do Elasticsearch para não prejudicar o desempenho.
O Elasticsearch é uma tecnologia de busca rápida e poderosa. À medida que seus dados forem crescendo, você precisará aproveitar sua impressionante escalabilidade. Adicionar mais nós a um cluster não apenas aumenta a quantidade de dados que o cluster pode conter, mas também oferece uma melhoria no número de solicitações que ele processa de uma vez e (normalmente) reduz o tempo necessário para retornar resultados.
Tentar descobrir por que a adição de nós ao cluster do Elasticsearch causou instabilidade, tempo de inatividade, uma frustração cada vez maior e perda de receita acaba com o humor de qualquer um. Por isso, vamos comentar algumas configurações comuns nas quais a expansão do cluster pode provocar gargalos de desempenho significativos.
Temos um excelente webinar chamado Dimensionamento e planejamento de capacidade no Elasticsearch. Ele define quatro recursos principais de hardware em um cluster:
- Computação: CPU, a rapidez com que o cluster pode realizar o trabalho.
- Armazenamento: unidades de disco rígido (HDD) ou de estado sólido (SSD), a quantidade de dados que o cluster pode armazenar no longo prazo.
- Memória: memória RAM, a quantidade de trabalho que o cluster pode realizar de uma vez.
- Rede: largura de banda, a rapidez com que os nós transferem dados entre si.
Os dois gargalos de desempenho mais comuns estão na computação e no armazenamento. Quando esses recursos são escassos, afetam profundamente os nós de dados do cluster. Outras funções dos nós, como master, de ingestão ou de transformação, são assunto para outra hora.
Observação: para simplificar, este artigo se concentra na ampliação de um único cluster do Elasticsearch. A execução de vários clusters em hardware compartilhado acrescenta outra camada de complexidade.
Os recursos de hardware são alocados de forma diferente com base na plataforma. Por exemplo: os nós são sistemas de hardware, máquina virtual ou container?
Quando o acréscimo de nós do Elasticsearch significa o acréscimo de capacidade
Acréscimo de nós de hardware dedicados
A maneira mais previsível de aumentar o desempenho do cluster é adicionar novo hardware. Ao adicionar um novo hardware dedicado, você aumenta todos os quatro recursos principais. Com uma exceção principal (que será abordada mais adiante), adicionar novos nós de hardware melhora o desempenho do cluster.
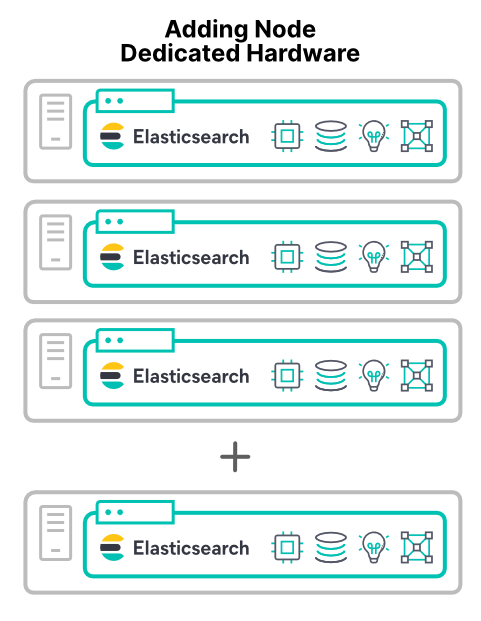
Acréscimo de nós em máquinas virtuais ou containers em novos hosts
O acréscimo de nós como máquinas virtuais (VMs) ou containers já é outra conversa. A alocação de novos nós em novos hosts ao cluster concede mais recursos de hardware. Mais núcleos de CPU, mais RAM, mais armazenamento e mais largura de banda total.
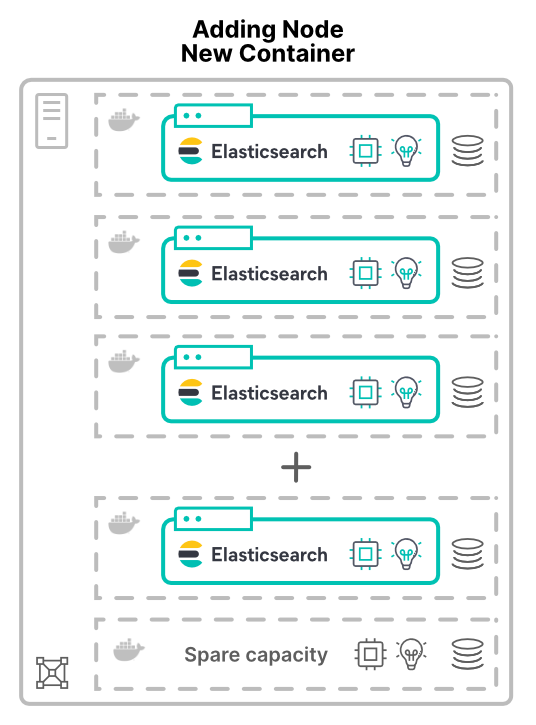
Um motivo para virtualizar (ou containerizar) aplicações é melhorar a utilização do hardware. Aqui, adicionar nós apenas aumentará a quantidade de hardware disponível para o cluster. O aumento de desempenho resultante depende dos limites dos recursos compartilhados.
Quando o acréscimo de nós significa dividir a capacidade
Seja dividindo hardware pelo uso de VMs ou containers, os nós do Elasticsearch acabam compartilhando o hardware. Estas considerações aplicam-se a todos os modelos de implantação, incluindo o Elastic Cloud Enterprise (ECE) e o Elastic Cloud on Kubernetes (ECK).
Criação de um gargalo computacional
O uso de máquinas virtuais para alocar CPUs costuma ser previsível: você atribui a cada VM a quantidade de núcleos a serem usados. Usando containers, os compartilhamentos de CPU são menos diretos.
Sistemas de containers como o Kubernetes podem medir os recursos da CPU em milésimos de CPU ou milicores. Há uma diferença significativa entre as solicitações e os limites. Definir apenas a CPU solicitada permite que o container use até 100% da CPU do host. Porém, limitar demais a CPU deixa recursos caros ociosos.
> Dica: os threadpools usam núcleos de CPU como ponto de partida. Com containers, é bom verificar se a configuração do threadpool funciona conforme o esperado.
No Kubernetes, os limites totais de CPU dos containers podem exceder o total de hardware disponível. Isso pressupõe que todos os containers não estarão com utilização total da CPU ao mesmo tempo.
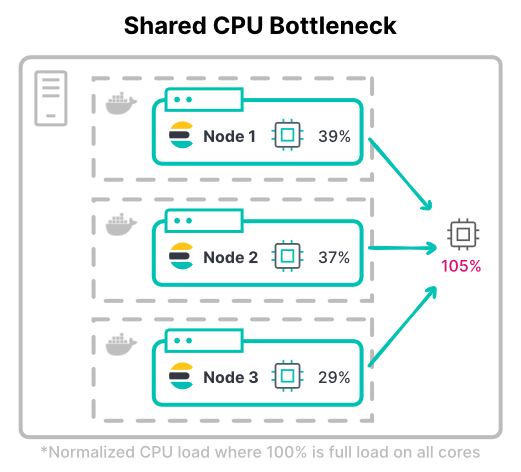
Considere o throughput máximo de um cluster. Em cargas de trabalho com uso intensivo de computação, os nós geralmente precisam de todos os limites de CPU atribuídos para a indexação. A carga de trabalho pesada de índice mais comum é um cluster de logging de alto volume.
> Dica: considere o uso máximo e típico ao determinar os limites da CPU. Considere também o quanto a aceleração (throttling) da CPU é aceitável.
Criação de um gargalo de armazenamento
Gargalos de armazenamento podem ser difíceis de prevenir porque o armazenamento é alocado por espaço e não por throughput. Quando um nó do Elasticsearch fica sem espaço de armazenamento, ele atinge a marca d'água de pouco espaço em disco e interrompe a alocação de shards.
Seja VM ou container, a maioria das plataformas não tem uma maneira fácil de limitar a utilização dos dispositivos de armazenamento. A maioria dos ambientes não tem limites configuráveis nas operações de entrada/saída por segundo (IOPS) ou no throughput de leitura/gravação. Até mesmo o sistema de arquivos XFS recomendado permite apenas cotas de disco com base no espaço em disco.
Sem limites, qualquer container com uma carga de trabalho com uso intensivo de armazenamento pode saturar o hardware de armazenamento. Assim, faltam recursos para outros nós que compartilham esse hardware. Implantações de larga escala podem dar errado com seus diretórios /pt/data. Quando vários nós montam seu diretório /pt/data no mesmo hardware de rede de área de armazenamento (SAN), o throughput total de todos os nós pode sobrecarregar o dispositivo.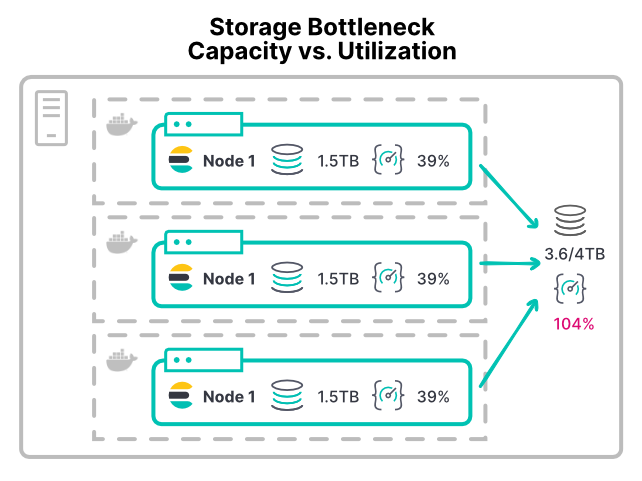
Com uma configuração de container como essa, o acréscimo de nós aloca mais CPU e memória ao cluster. No entanto, divide ainda mais o throughput do armazenamento existente. Isso faz com que as operações de disco demorem mais, e o desempenho fica pior com o acréscimo de nós.
> Dica: quando os nós carecem de throughput de armazenamento, um sinal de alerta precoce é o tempo de espera de E/S da CPU acima de 10%. Você encontra isso em hosts de VM ou container, pois containers individuais não relatam essa métrica.
Quando o acréscimo de nós tem efeito neutro para a rede
Há uma última pegadinha para você pode ampliar com eficácia. Esse gargalo de configuração ocorre mesmo quando se adiciona hardware físico.
Limitação do throughput do índice com shards insuficientes
O acréscimo de nós, independentemente do método, não altera o número de shards em um índice. Se um índice tiver dois shards principais e um conjunto de réplicas, haverá um total de quatro shards. Em um cluster de quatro nós, ter apenas um shard por nó é uma excelente maneira de maximizar o throughput da indexação.
À medida que o volume de dados de entrada aumenta, adicionamos outros dois nós ao cluster. Esse é um aumento de 50% nos recursos totais do cluster, mas podemos ver exatamente 0% de melhoria na taxa de ingestão. Por quê?
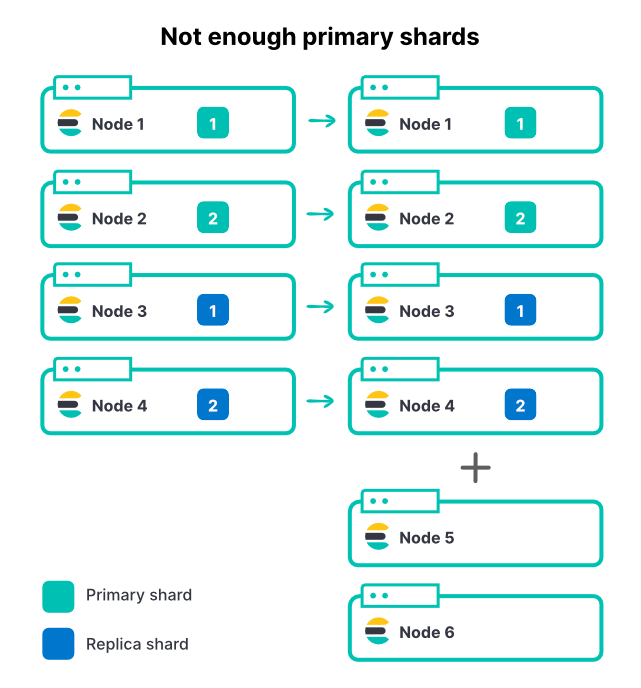
Aqui, os novos nós não podem contribuir para a indexação, pois todos os shards já estão atribuídos. Para que um índice tire proveito do aumento na quantidade de nós, o número de shards principais também precisa aumentar. Se você tiver muitos índices ativos em um cluster (o que é comum), adicionar nós aumentará o throughput total do cluster, mas o índice mais ativo ainda poderá ser restrito devido à quantidade limitada de shards principais. Selecionar um bom número de shards para o Elasticsearch é uma parte importante do planejamento de capacidade.
Portanto, no exemplo acima, aumentar de dois para três shards principais, mais uma réplica por shard, perfaz um total de seis shards para alocar nos seis nós.
> Dica: definir index.routing.allocation.total_shards_per_node [consulte a documentação aqui] pode ser uma medida de contingência. No entanto, definir esse limite muito baixo pode deixar shards presos sem atribuição.
Conclusão
Adicionar nós a um cluster do Elasticsearch melhorará seu desempenho? Depende. Se os nós compartilharem o hardware, você precisará estar atento a gargalos de recursos compartilhados. Dois gargalos comuns são a utilização excessiva de CPU e armazenamento. O planejamento cuidadoso e uma boa estratégia de uso de shards garantirão que o acréscimo de nós aumentará o desempenho.
Um dos muitos benefícios da execução da implantação no Elastic Cloud é o trabalho da nossa equipe para identificar e resolver exatamente esses tipos de preocupações relacionadas ao desempenho com recursos compartilhados. Não hesite em iniciar uma avaliação na nuvem hoje mesmo: https://www.elastic.co/pt/cloud/
Além disso, assista ao webinar Dimensionamento e planejamento de capacidade no Elasticsearch para aprofundar sua compreensão do desempenho do Elasticsearch.
Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir