Machine Learning para logs de Nginx: como identificar problemas operacionais com seu site
Nota do editor (3 de agosto de 2021): este post usa recursos obsoletos. Consulte a documentação de mapeamento de regiões customizadas com geocodificação reversa para obter as instruções atuais.
Pode ser complicado obter insights de arquivos de log do nginx. Este post mostra como podemos usar o Machine Learning para extrair automaticamente insights operacionais de grandes volumes de dados de logs de nginx.
Visão geral
A ciência de dados pode ser um processo experimental intrincado, em que é fácil se perder nos dados ou na complexidade das estatísticas. Portanto, um objetivo-chave de projeto para o grupo de Machine Learning da Elastic é desenvolver ferramentas que permitam que uma quantidade maior de usuários obtenha insights a partir dos dados do Elasticsearch.
Isso nos levou a desenvolver recursos como os assistentes de “Single Metric Job” e de “Multiple Metric Job” no X-Pack Machine Learning, e estamos planejando simplificar ainda mais as etapas de análise e configuração nas próximas versões.
Em paralelo a esses assistentes, também está nos nossos planos desenvolver configurações de trabalho predefinidas com base em fontes de dados conhecidas do Beats e do Logstash. Por exemplo, se você estiver coletando dados com o módulo NGINX do Filebeat, poderemos oferecer um conjunto de configurações e painéis predefinidos para ajudar os usuários a aplicar o Machine Learning a seus dados.
As instruções detalhadas para a instalação dessas configurações serão abordadas em outro post. O objetivo deste post é descrever os casos de uso e as configurações.
Observações sobre os casos de uso
As opções de configuração do X-Pack Machine Learning são vastas, e é comum que novos usuários se sintam tentados a começar com configurações complexas e com a seleção de um grande número de atributos e séries. Esses tipos de configurações podem ser muito potentes e expressivos, mas exigem cuidado, pois pode ser difícil interpretar os resultados. Sendo assim, recomendamos que os usuários comecem com casos de uso simples e bem definidos, aumentando a complexidade conforme se familiarizarem mais com o sistema. (Observação: os melhores casos de uso iniciais costumam surgir da detecção automática de anomalias nos gráficos dos principais dashboards das equipes operacionais.)
Descrição dos dados do exemplo
Os dados utilizados nestes exemplos são provenientes de um sistema de produção formado por quatro servidores Web nginx com carga balanceada. Analisamos três meses de dados (em valores aproximados, 29 milhões de eventos, 1,1 milhão de visitantes únicos e 29 GB de dados). Vale frisar que anonimizamos os dados exibidos aqui.
nginx log format:
'"$http_x_forwarded_for" $remote_addr - [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent"';
Exemplo da mensagem de log:
"2021:0eb8:86a3:1000:0000:9b3e:0370:7334 10.225.192.17 10.2.2.121" - - [30/Dec/2016:06:47:09 +0000] "GET /test.html HTTP/1.1" 404 8571 "-" "Mozilla/5.0 (compatible; Facebot 1.0; https://developers.facebook.com/docs/sharing/webmasters/crawler)"
Após o processamento da configuração do módulo NGINX do Filebeat, obtemos o seguinte documento JSON no Elasticsearch:
… { "nginx" : { "access" : { "referrer" : "-", "response_code" : "404", "remote_ip" : "2021:0eb8:86a3:1000:0000:9b3e:0370:7334", "geoip" : { "continent_name" : "Europe", "country_iso_code" : "PT", "location" : { "lon" : -10.23057, "lat" : 34.7245 } }, "method" : "GET", "user_name" : "-", "http_version" : "1.1", "body_sent" : { "bytes" : "8571" }, "remote_ip_list" : [ "2021:0eb8:86a3:1000:0000:9b3e:0370:7334", "10.225.192.17", "10.2.2.121" ], "url" : "/test.html", "user_agent" : { "major" : "1", "minor" : "0", "os" : "Other", "name" : "Facebot", "os_name" : "Other", "device" : "Spider" } } } }...
Caso de uso nº 1: mudanças nos visitantes do site
Do ponto de vista operacional, é comum que mudanças na taxa de visitantes sejam o reflexo de problemas do sistema. Por exemplo, se a taxa de visitantes despenca em um período curto, é provável que o site esteja com algum problema de sistema. Uma forma simples para entender as mudanças na taxa de visitantes é analisar a taxa geral de eventos ou a taxa de visitantes únicos.
Trabalho 1.1: Baixo número de visitantes no site
Esse job pode ser configurado usando simplesmente o assistente de “Single Metric Job”:
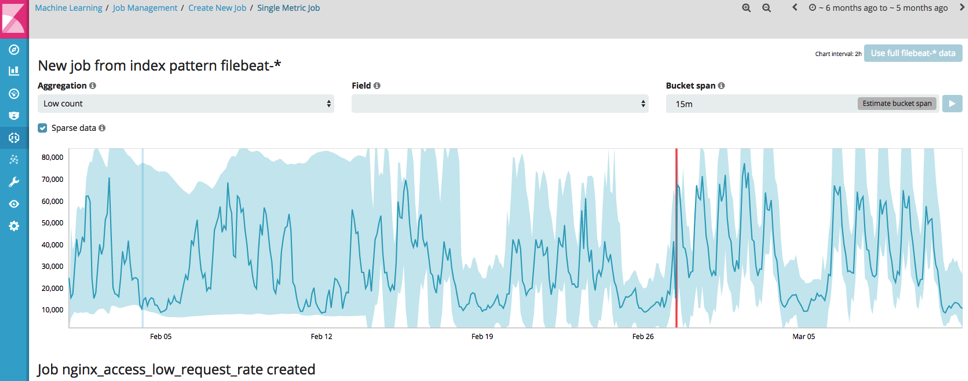
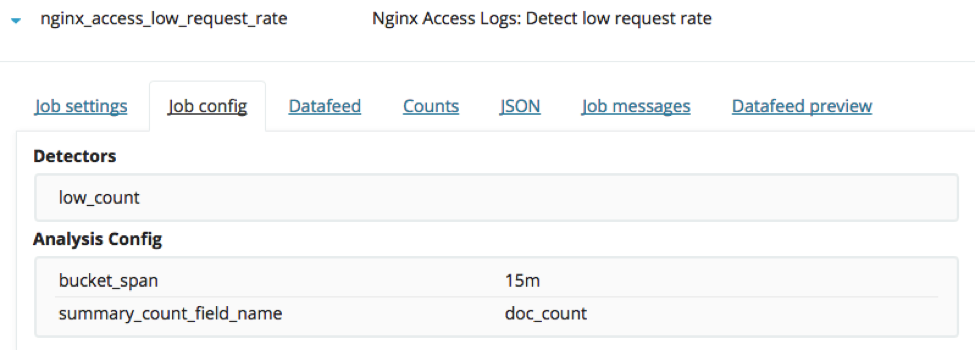
Resumo da configuração do trabalho:
Esta análise mostra uma anomalia significativa ocorrida no dia 27 de fevereiro, quando houve uma grande queda na taxa total de eventos:
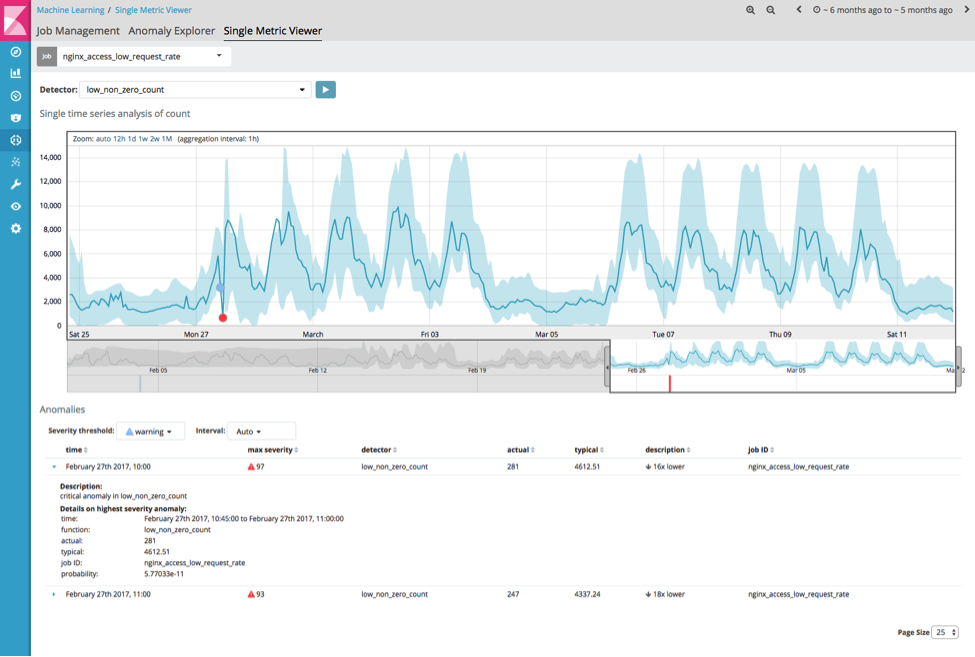
(Observação: essa análise dos 29 milhões de eventos demorou 16 segundos para ser feita em uma instância AWS m4.large)
Trabalho 1.2: Baixo número de visitantes únicos no site
Os números de eventos podem sofrer grande influência de bots ou ataques. Portanto, é necessário que um recurso mais robusto analise a quantidade de visitantes únicos do site. Novamente, esse trabalho pode ser configurado usando simplesmente o assistente de “Single Metric Job”:
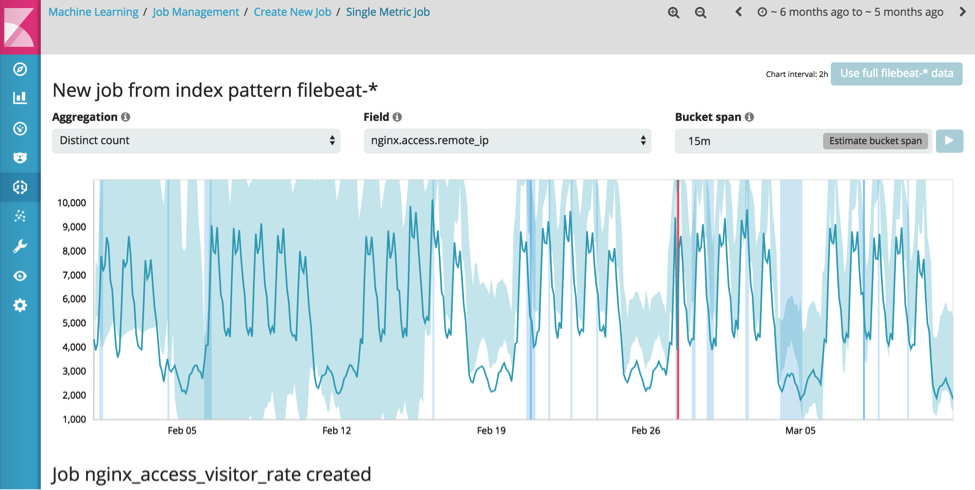
De novo, uma anomalia significativa aconteceu no dia 27 de fevereiro, quando a quantidade de visitantes únicos por 15 minutos teve uma queda brusca, dos normais 1487 para 86:
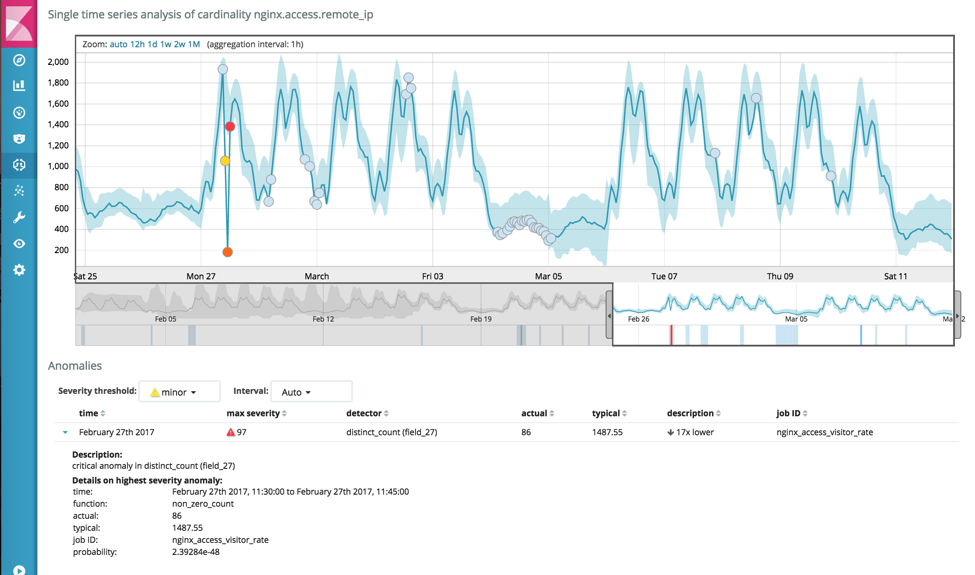
Combinação dos trabalhos 1.1 e 1.2:
Usando o Anomaly Explorer, podemos fazer uma correlação temporal dos resultados desses dois jobs, gerando uma visão geral da anomalia do sistema com base nesses recursos:
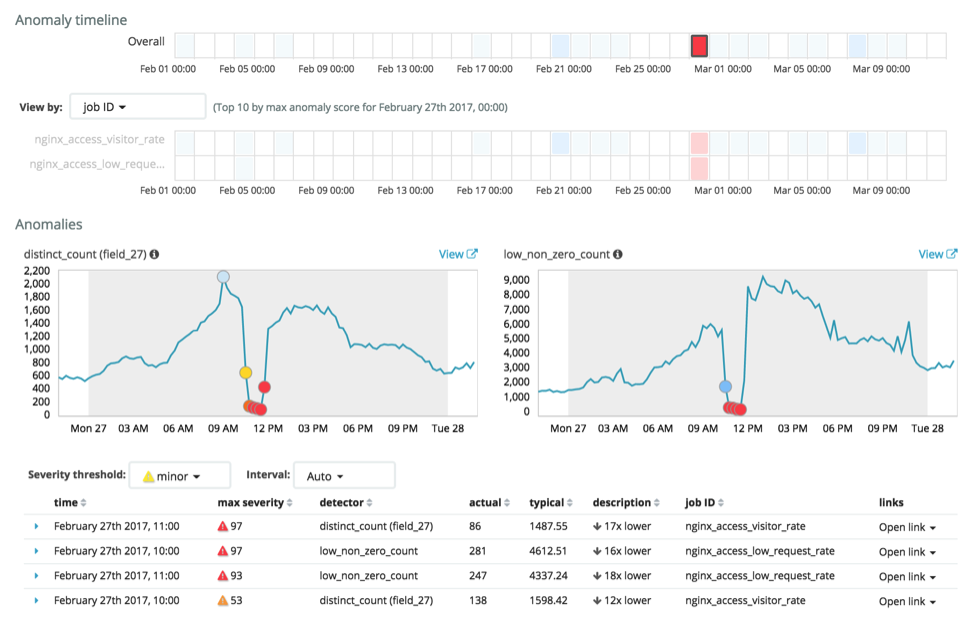
Em uma visão única, vemos claramente que houve uma anomalia significativa no dia 27 de fevereiro entre as 10h e o meio-dia, quando a taxa total de eventos e o número de visitantes únicos caíram.
A equipe operacional confirmou que o site apresentou problemas significativos nesse período após uma alterações de configuração na rede de distribuição de conteúdo (CDN). Infelizmente, eles só detectaram o impacto para os usuários às 11h30 (depois da reclamação de usuários internos pelo Slack). Com o machine learning, o alerta chegaria à equipe às 10h, quando o problema de fato ocorreu.
Essa análise pode ser combinada com alertas para notificar as equipes operacionais sobre alterações no comportamento do sistema.
Caso de uso nº 2: mudanças no comportamento do site
Após a análise de comportamentos simples, os próximos passos geralmente envolvem o uso de recursos mais complexos. Por exemplo, mudanças nas taxas de eventos dos diferentes códigos de status HTTP retornados pelo servidor web podem frequentemente indicar mudanças no comportamento do sistema ou clientes incomuns:
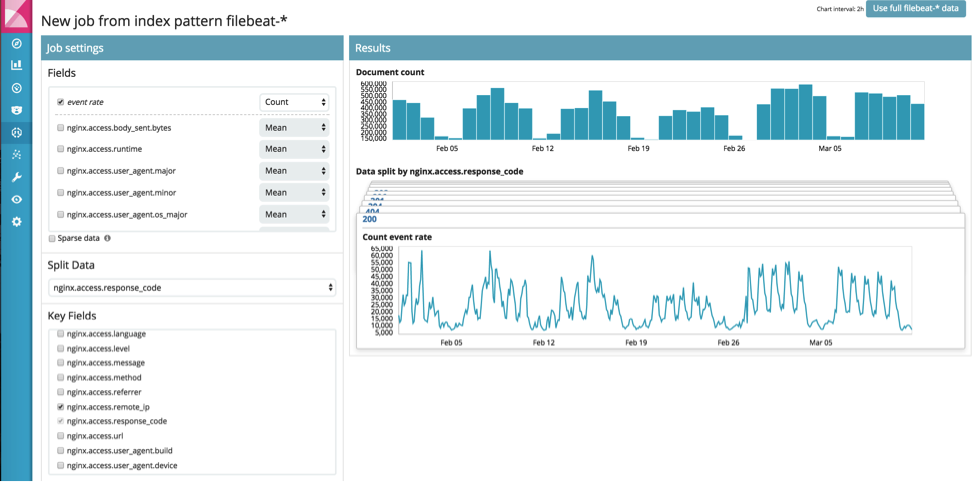
Esse caso de uso é mais complexo, pois envolve a análise de diversas séries simultaneamente, mas, de novo, pode ser simplesmente configurado usando o assistente de “Multiple Metric Job”:
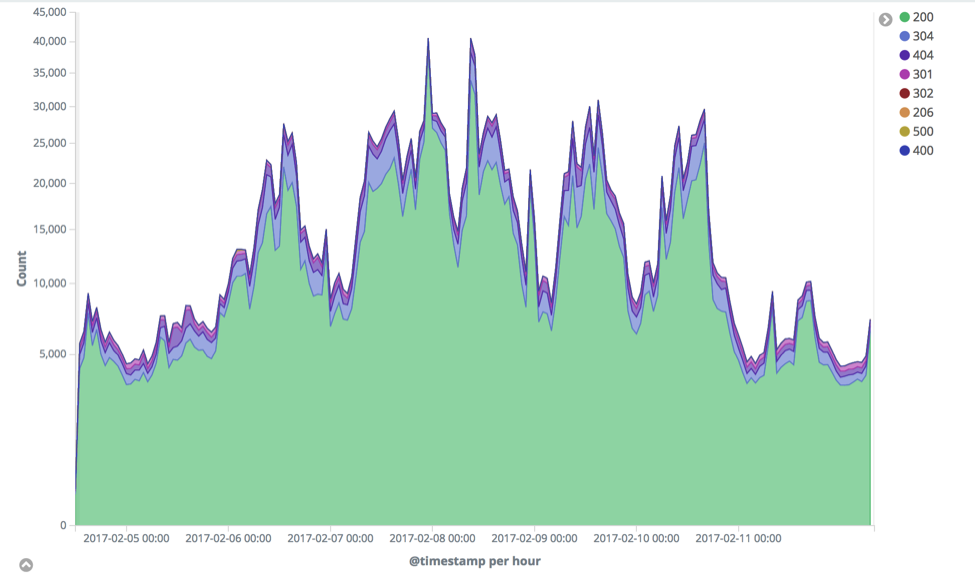
Os resultados mostram algumas mudanças significativas nos diferentes códigos de resposta:
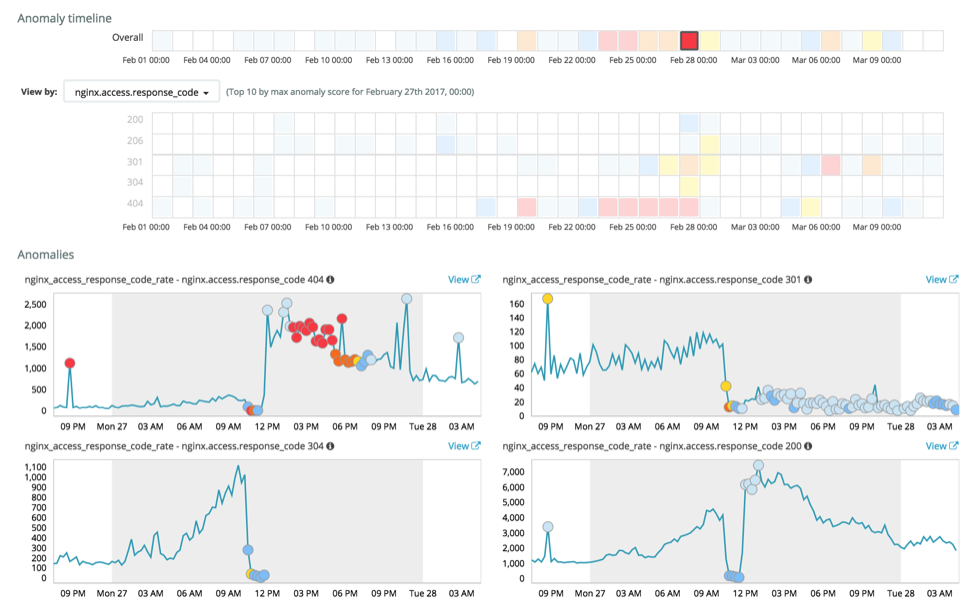
Em particular, de novo no dia 27 de fevereiro, há uma grande mudança no comportamento dos códigos de resposta 404, 301, 306 e 200. Observando os códigos 404 mais de perto, vemos algumas anomalias significativas:
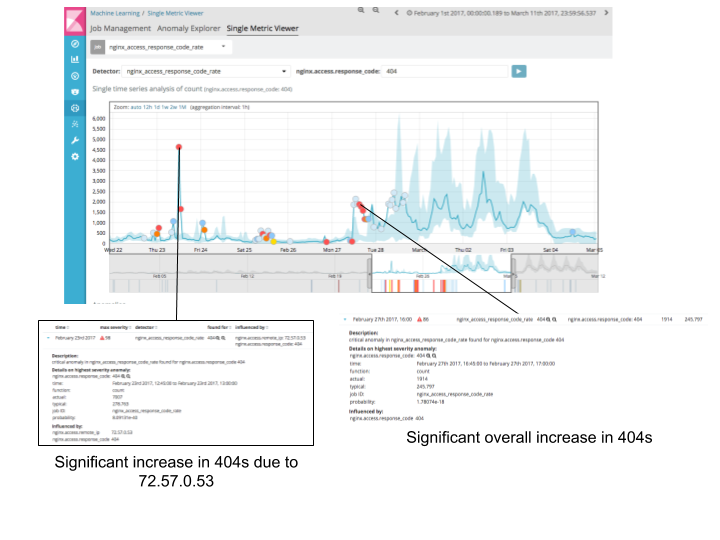
A primeira anomalia destacada é atribuída a um endereço IP específico, já que nginx.access.remote_ip está definido como um influenciador (falaremos mais sobre isso em outro post). Já a segunda anomalia destacada representa uma mudança geral significativa no comportamento do código 404.
O aumento dos códigos 404 no dia 27 de fevereiro foi, mais uma vez, um novo insight para a equipe operacional e representou um grande número de links desfeitos que haviam sido introduzidos pela mudança na configuração.
Caso de uso nº 3: clientes incomuns
Em geral, o tráfego de um site consiste da combinação do uso normal, varredura por bots e tentativas de atividades mal-intencionadas. Supondo que a maioria dos clientes sejam normais, podemos usar population analysis para detectar ataques ou atividades de bots que sejam significativos.
A quantidade de páginas que um usuário normal solicita em um período de 5 minutos pode ser limitada pela velocidade com que ele consegue clicar manualmente para acessar as páginas do site. Processos automatizados são capazes de varrer milhares de páginas por minuto, e os ataques podem simplesmente sobrecarregar um site com múltiplas solicitações.
Poderíamos usar diversos recursos para diferenciar os tipos de tráfego, mas na primeira instância, a taxa de eventos e a taxa de URLs distintos de um cliente podem destacar uma atividade incomum de um cliente.
Neste caso, usamos a configuração avançada de jobs para configurar dois jobs populacionais:
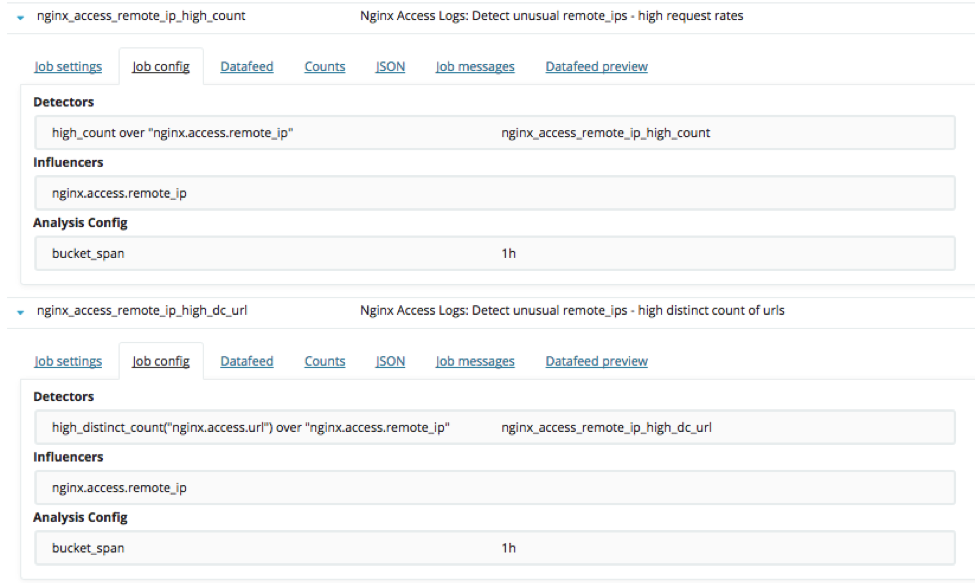
Trabalho 3.1: detectar remote_ips incomum ⎻ altas taxas de solicitação
Observando a taxa de eventos com um volume fora do comum (nginxaccessremoteiphigh_count), temos:
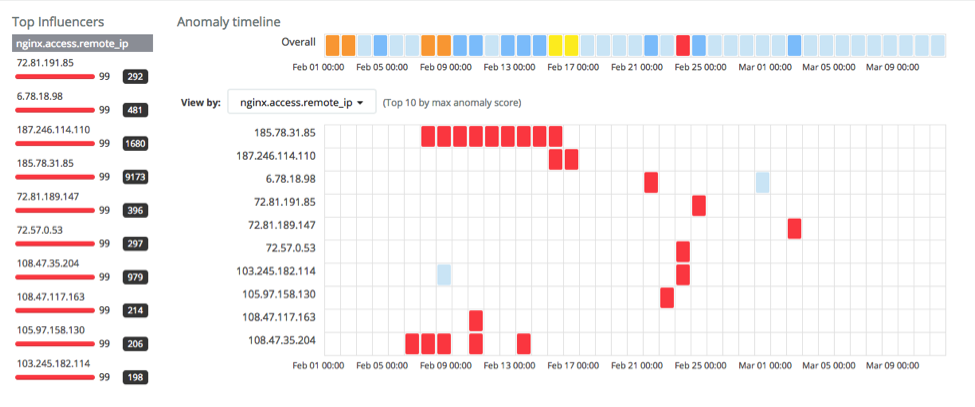
Isso mostra um grande número de clientes anômalos. Por exemplo, 185.78.31.85 parece ser anômalo durante um longo período:
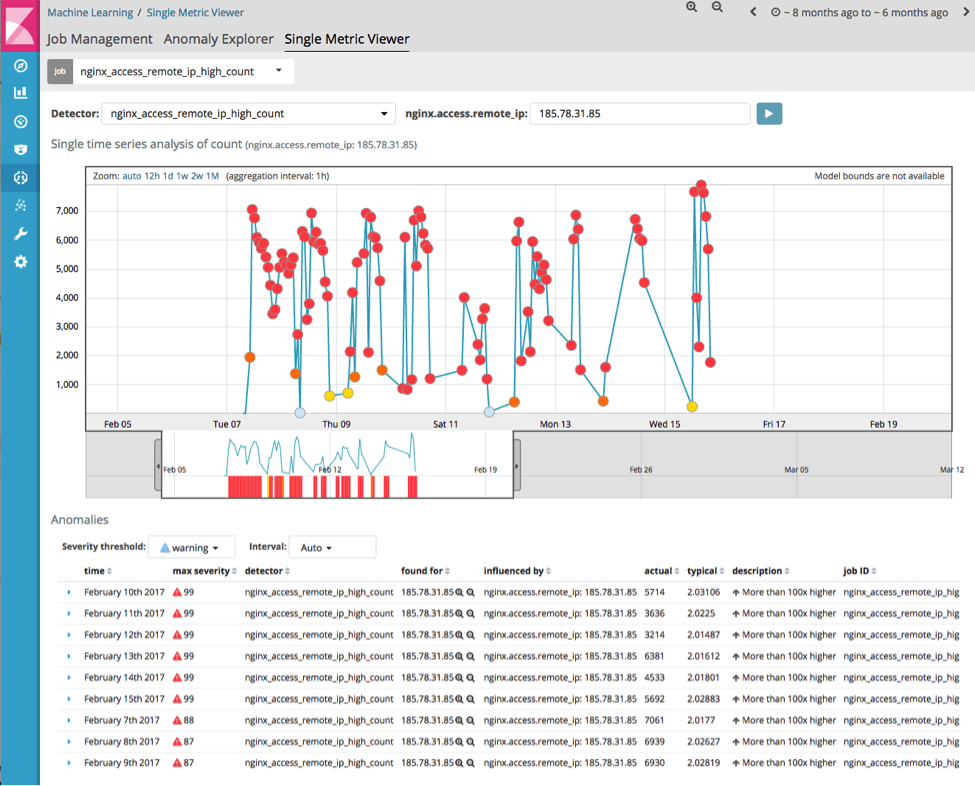
Analisando um painel que resume esta interação, temos:
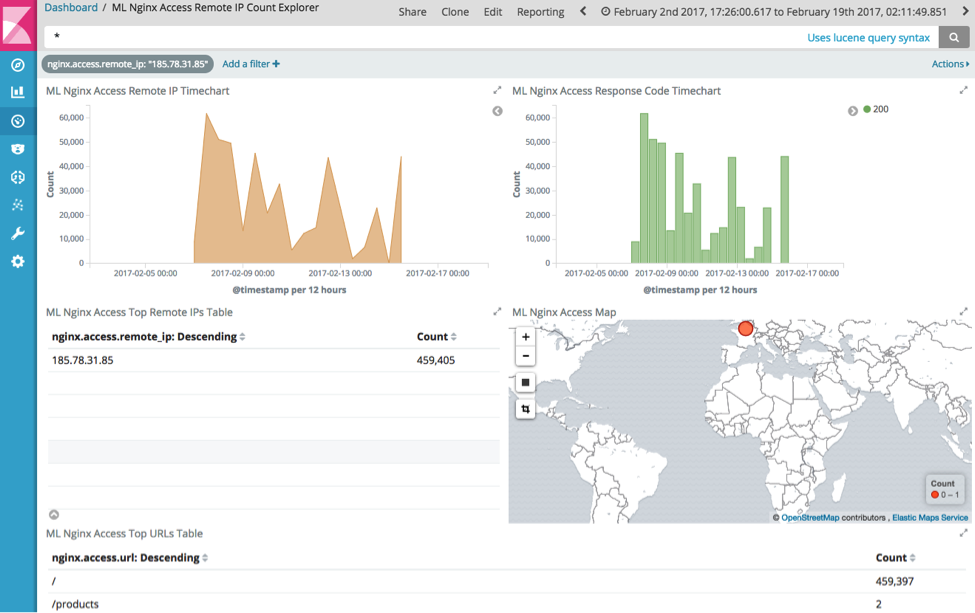
Isso mostra que esse endereço IP acessou repetidamente o URL raiz (/) por uma quantidade de vezes fora do comum em um curto período e que esse comportamento perdura por vários dias.
Trabalho 3.2: detectar remote_ips incomum ⎻ altas taxas de solicitação
Observando a taxa de URLs únicos com um volume fora do comum para um cliente (nginxaccessremoteiphighdcurl), temos:
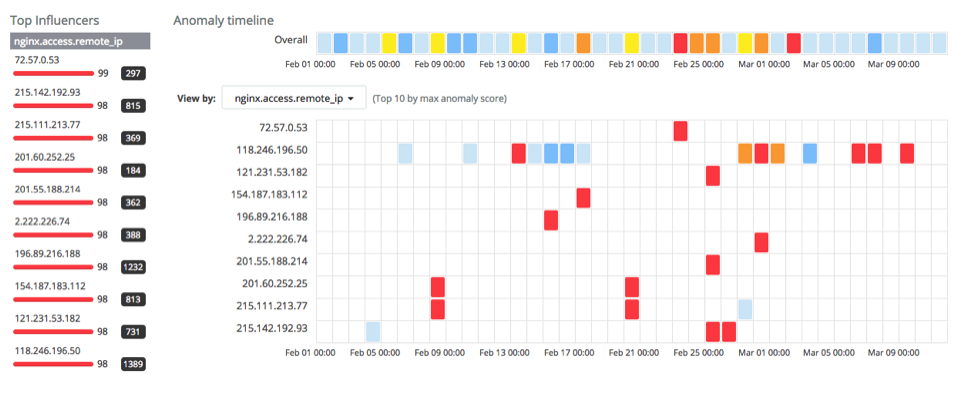
De novo, vemos diversos clientes incomuns. Analisando 72.57.0.53, vemos um cliente que acessou mais de 12 mil URLs diferentes em um curto período.
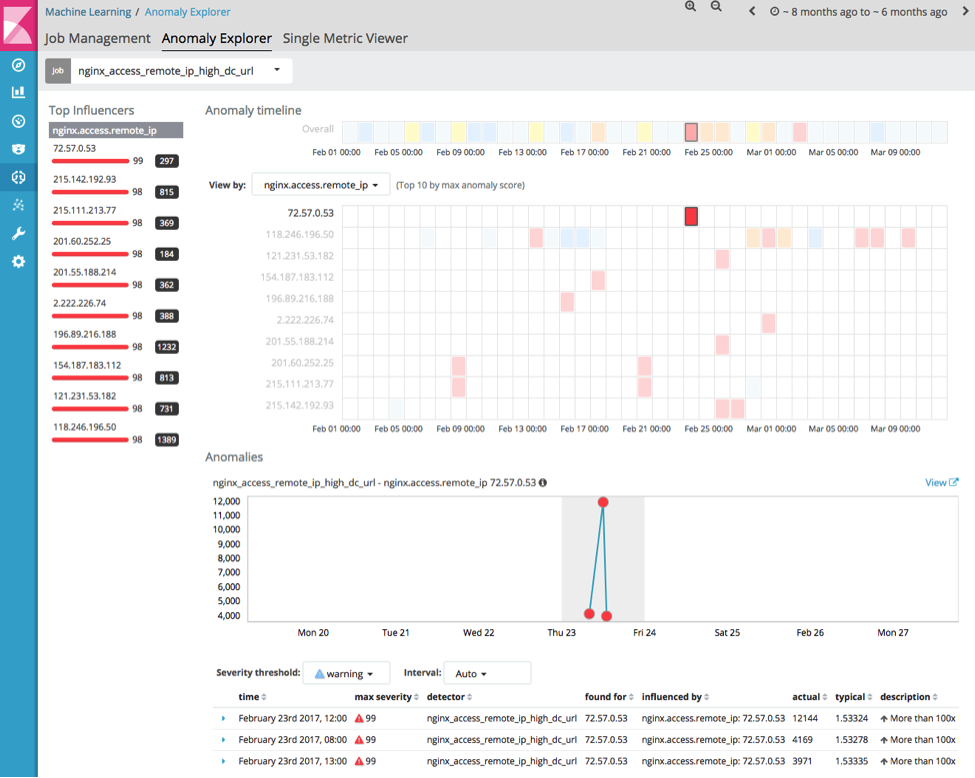
Analisando um painel que resume esta interação, temos:
Isso mostra que esse cliente está tentando acessar uma grande quantidade de URLs incomuns, coincidindo com os tipos de ataque de caminho traversal.
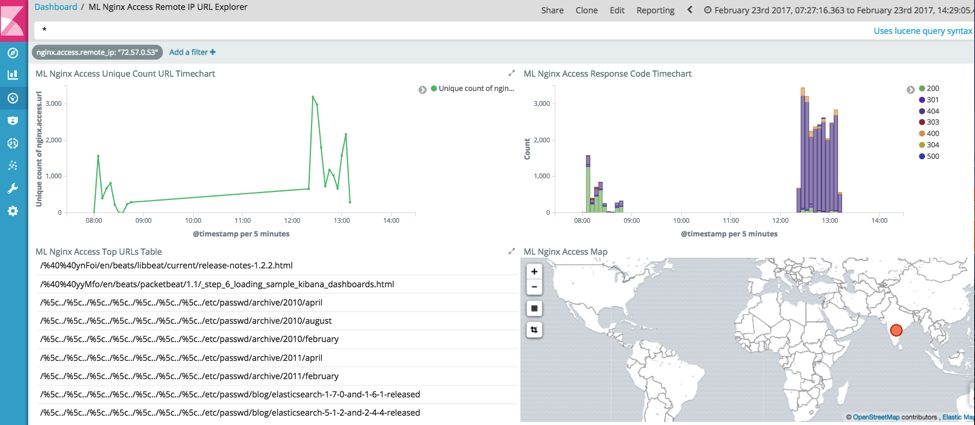
Esses dois trabalhos proporcionam visibilidade em tempo real sobre clientes incomuns que estejam acessando um site. É comum que o tráfego da Web sofra uma distorção provocada por bots e ataques, e diferenciar esses clientes pode ajudar os administradores a entender comportamentos como:
- A que tipos de ataque o site está sujeito
- Se os bots estão acessando todo o site
- Qual é o uso “normal”
Resumo
Este post tenta mostrar como o X-Pack ML pode oferecer insights sobre o comportamento do site. Nas próximas versões do Elastic Stack, esses tipos de configurações e painéis estarão disponíveis para usuários finais como pacotes de fácil instalação. Isso permitirá que os usuários contem com configurações testadas, mostrando também a eles os tipos de configurações recomendados para cópia e expansão.