Tutorial de observabilidade do Kubernetes: monitoramento e análise de log
O Kubernetes emergiu como a tecnologia de orquestração de containers na prática e uma tecnologia integral no movimento nativo da nuvem. Ser nativo da nuvem confere velocidade, elasticidade e agilidade ao desenvolvimento do software, mas também aumenta a complexidade, com centenas de microsserviços em milhares (ou milhões) de containers, sendo executados em pods efêmeros e descartáveis. Monitorar um sistema tão complexo, distribuído e transiente é desafiador e, ao mesmo tempo, muito crítico. Felizmente, com a Elastic, é mais fácil trazer observabilidade ao seu ambiente do Kubernetes.
Nesta série de tutoriais de observabilidade do Kubernetes, exploraremos como você pode monitorar todos os aspectos das suas aplicações em execução no Kubernetes, incluindo:
- Ingestão e análise de logs
- Coleta de métricas de desempenho e integridade
- Monitoramento de performance de aplicação com o Elastic APM
No final deste tutorial, você terá um exemplo funcional de uma aplicação que envia todos os dados de observabilidade para o Elastic Stack para monitoramento e análise.
Por que escolher o Elastic Observability para o Kubernetes?
A observabilidade depende de três pilares de dados: logs, métricas e monitoramento de performance de aplicação ou APM, pelas iniciais em inglês. Não faltam artigos que mapeiam diferentes ferramentas e fornecedores para reunir o “melhor” monitoramento para o Kubernetes, fazendo um combo estilo Frankenstein com três a seis ferramentas, fornecedores e tecnologias diferentes...
Não tema. Com a Elastic não há problema. O Elastic Observability combina seus logs, métricas e dados de APM para proporcionar visibilidade e análise unificadas usando uma única ferramenta. Comece a resolução de problemas com base em uma anomalia de latência voltada para o usuário nos dados de APM (detectada por machine learning), volte-se para as métricas de um pod do Kubernetes específico, observe os logs gerados por esse pod e correlacione-os com métricas e logs que descrevem os eventos que ocorrem no host e na rede — tudo na mesma interface de usuário. Isso é que é observabilidade bem feita!
E embora ele deixe tudo mais simples para os usuários, há muita coisa acontecendo em segundo plano porque...
Os logs do Kubernetes são alvos móveis
O Kubernetes realiza a orquestração implantando containers nos hosts disponíveis. Os componentes da aplicação são distribuídos nativamente entre hosts diferentes, tornando impossível saber antecipadamente onde o componente vai parar.
Os containers em execução nos pods do Kubernetes produzem logs como stdout ou stderr. Esses logs são gravados em um local conhecido pelo kubelet como arquivos com o nome do id do pod. Para vincular os logs ao componente ou pod que os produziu, os usuários precisam descobrir quais pods de componentes estão em execução no host atual e quais são seus ids.
Para complicar um pouco mais, o Kubernetes pode decidir ampliar ou reduzir a aplicação e, como resultado, a contagem de pods que representa o componente da aplicação pode mudar.
Felizmente, o Filebeat adora um alvo móvel
Tudo o que precisamos para coletar logs dos pods é o Filebeat em execução como DaemonSet no nosso cluster do Kubernetes. O Filebeat pode ser configurado para se comunicar com a API do kubelet local, obter a lista de pods em execução no host atual e coletar os logs que os pods estão produzindo. Esses logs são anotados com todos os metadados relevantes do Kubernetes, como id do pod, nome do container, rótulos e anotações do container, e assim por diante.
O Filebeat usa essas anotações para descobrir quais tipos de componentes estão em execução no pod e pode decidir qual módulo de logging aplicar aos logs que está processando. Olha mãe, sem as mãos! Ingerir logs do Kubernetes com o Filebeat é muito fácil. OK, estamos prestes a começar, mas uma nota rápida (e grande) antes disso:
| Antes de começar: para o tutorial a seguir, é necessário ter um ambiente do Kubernetes configurado. Criamos um post suplementar que mostra o processo de configuração de um ambiente do Minikube de nó único com uma aplicação de demonstração para executar o restante das atividades. |
Coletar logs do Kubernetes com o Filebeat
Usaremos o Elasticsearch Service no Elastic Cloud. No entanto, tudo o que está descrito aqui pode funcionar com clusters da Elastic implantados na sua própria infraestrutura, quer você faça o autogerenciamento ou use sistemas de orquestração como o Elastic Cloud Enterprise (ECE) ou o Elastic Cloud on Kubernetes (ECK). O código para este tutorial está disponível no seguinte repositório do GitHub: http://github.com/michaelhyatt/k8s-o11y-workshop
Implantação do Filebeat como um DaemonSet
Apenas uma instância do Filebeat deve ser implantada por host do Kubernetes. Depois de implantado, o Filebeat se comunica com o host por meio da API do kubelet para recuperar informações sobre os pods em execução, todas as anotações dos metadados e também a localização dos arquivos de log.
A configuração de implantação do DaemonSet é definida no arquivo $HOME/k8s-o11y-workshop/filebeat/filebeat.yml. Vamos dar uma olhada mais de perto na parte do descritor da implantação que representa a configuração do Filebeat.
Essa parte aumenta o número geral de campos possíveis de 1.000 (o padrão) para 5.000. As implantações do Kubernetes podem introduzir um grande número de rótulos e anotações, resultando em campos de esquema que podem exceder o padrão de 1.000.
setup.template.settings:
index.mapping.total_fields.limit: 5000
As configurações do mecanismo de descoberta automática instruem o Filebeat a usar a descoberta automática do Kubernetes e a contar com a descoberta automática orientada por dicas que funciona com base nas anotações.
filebeat.autodiscover:
providers:
- type: kubernetes
host: ${NODE_NAME}
hints.enabled: true
A próxima sessão define a cadeia do processador que será aplicada a todos os logs capturados por essa instância do Filebeat. Primeiro, ela enriquecerá o evento com os metadados provenientes do Docker, do Kubernetes, do host e dos provedores de serviços em nuvem. Em seguida, há uma seção drop_event que filtra as mensagens com base no conteúdo e em alguns dos campos de metadados criados por processadores anteriores. Isso é útil quando há um tipo de evento ruidoso que continua dominando os logs. Observe como o and e o or lógicos estão sendo usados para construir a condição de correspondência.
processors:
- add_cloud_metadata:
- add_host_metadata:
- add_docker_metadata:
- add_kubernetes_metadata:
- drop_event:
when:
or:
- contains:
message: "OpenAPI AggregationController: Processing item k8s_internal_local_delegation_chain"
- and:
- equals:
kubernetes.container.name: "metricbeat"
- contains:
message: "INFO"
- contains:
message: "Non-zero metrics in the last"
- and:
- equals:
kubernetes.container.name: "packetbeat"
- contains:
message: "INFO"
- contains:
message: "Non-zero metrics in the last"
- contains:
message: "get services heapster"
- contains:
kubernetes.container.name: "kube-addon-manager"
- contains:
kubernetes.container.name: "dashboard-metrics-scraper"
Módulos do Filebeat e descoberta automática usando anotações
Vimos acima como a descoberta automática fará o módulo apropriado ser aplicado ao stdout/stderr para analisá-los como um formato específico do módulo. Saiba mais sobre descoberta automática na documentação do Filebeat.
Agora, vamos ver como diferentes componentes na nossa aplicação de amostra são configurados para funcionar com a descoberta automática baseada em dicas do Kubernetes.
Exemplo do NGINX
Aqui está o snippet de código de $HOME/k8s-o11y-workshop/nginx/nginx.yml que instrui o Filebeat a tratar os logs desse pod como logs do NGINX, nos quais stdout representa o log de acesso e stderr representa o log de erros:
annotations:
co.elastic.logs/module: nginx
co.elastic.logs/fileset.stdout: access
co.elastic.logs/fileset.stderr: error
Como lidar com logs de aplicação com múltiplas linhas
Outro exemplo de descoberta automática baseada em dica é configurar o Filebeat para tratar as entradas do log com múltiplas linhas do petclinic como um único evento de log. Isso é útil quando os componentes registram mensagens com múltiplas linhas, como traces de stack do Java que representam um único evento, mas serão, por padrão, tratados como um único evento por linha, delimitado pelo final da linha.
Aqui está um snippet de $HOME/k8s-o11y-workshop/petclinic/petclinic.yml que representa a configuração de tratamento de eventos com múltiplas linhas que é entendida pelo Filebeat usando descoberta automática com base em dicas:
annotations:
co.elastic.logs/multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
co.elastic.logs/multiline.negate: "true"
co.elastic.logs/multiline.match: "after"
Saiba mais sobre o tratamento de eventos com múltiplas linhas na documentação do Filebeat.
Análise de logs do Kubernetes no Elastic Stack
Agora que os logs foram ingeridos no Elasticsearch, é hora de colocá-los em uso.
Uso do app do Logs no Kibana
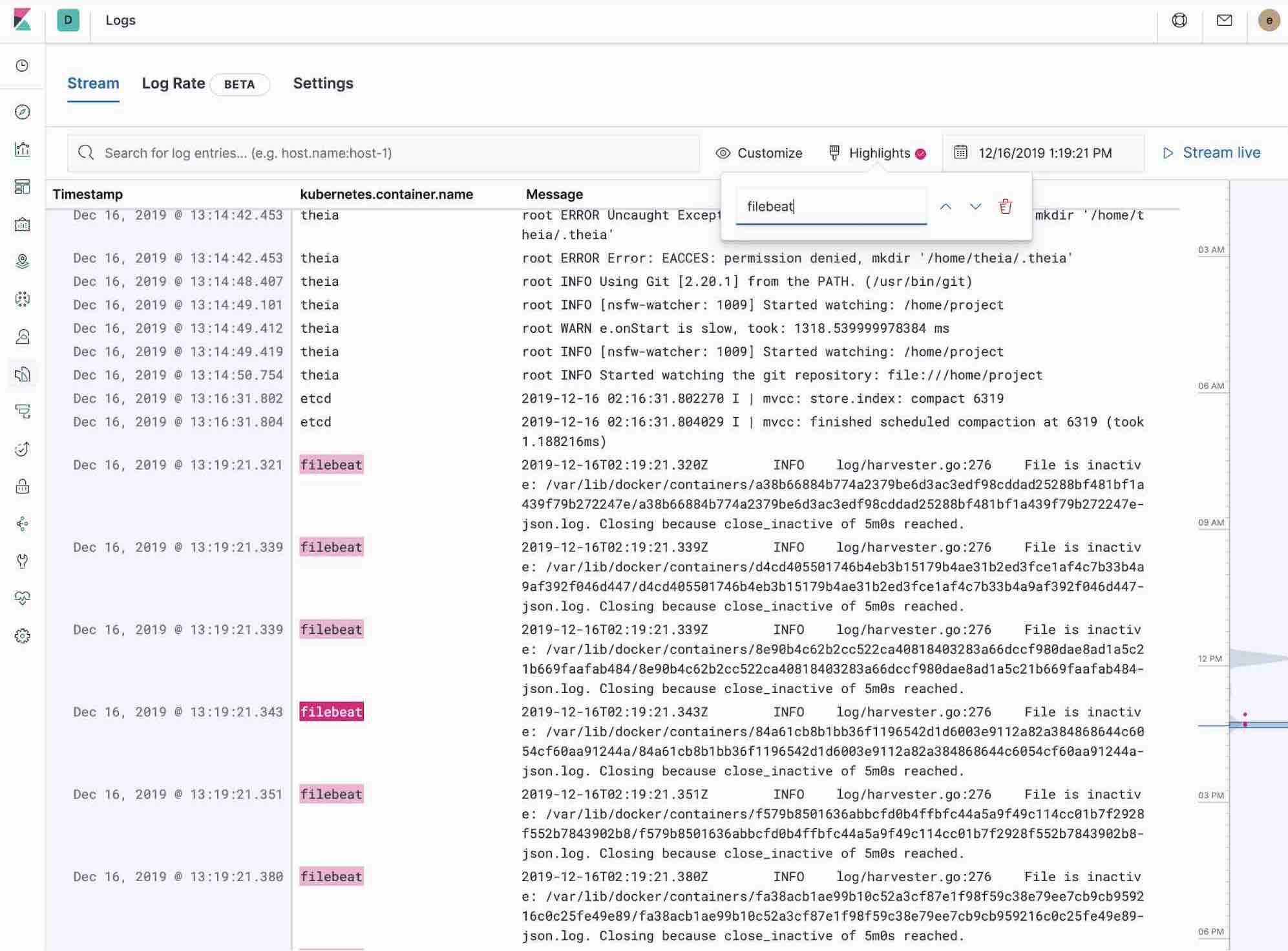
O app do Logs no Kibana permite buscar, filtrar e fazer tailing de todos os logs coletados no Elastic Stack. Em vez de ter de fazer ssh em servidores diferentes, ter de entrar no diretório e fazer tailing de arquivos individuais, todos os logs estão disponíveis em uma única ferramenta no app do Logs.
- Verifique os logs de filtragem usando a busca de palavra-chave ou de texto simples.
- Você pode se deslocar para frente e para trás no tempo usando o seletor de data e hora ou a visualização da linha do tempo na lateral.
- Se quiser apenas ver os logs serem atualizados na sua frente no estilo tail -f, clique no botão Streaming e use o destaque para acentuar essa parte importante da informação que você está esperando para ver.
Visualizações do Kibana prontas para uso
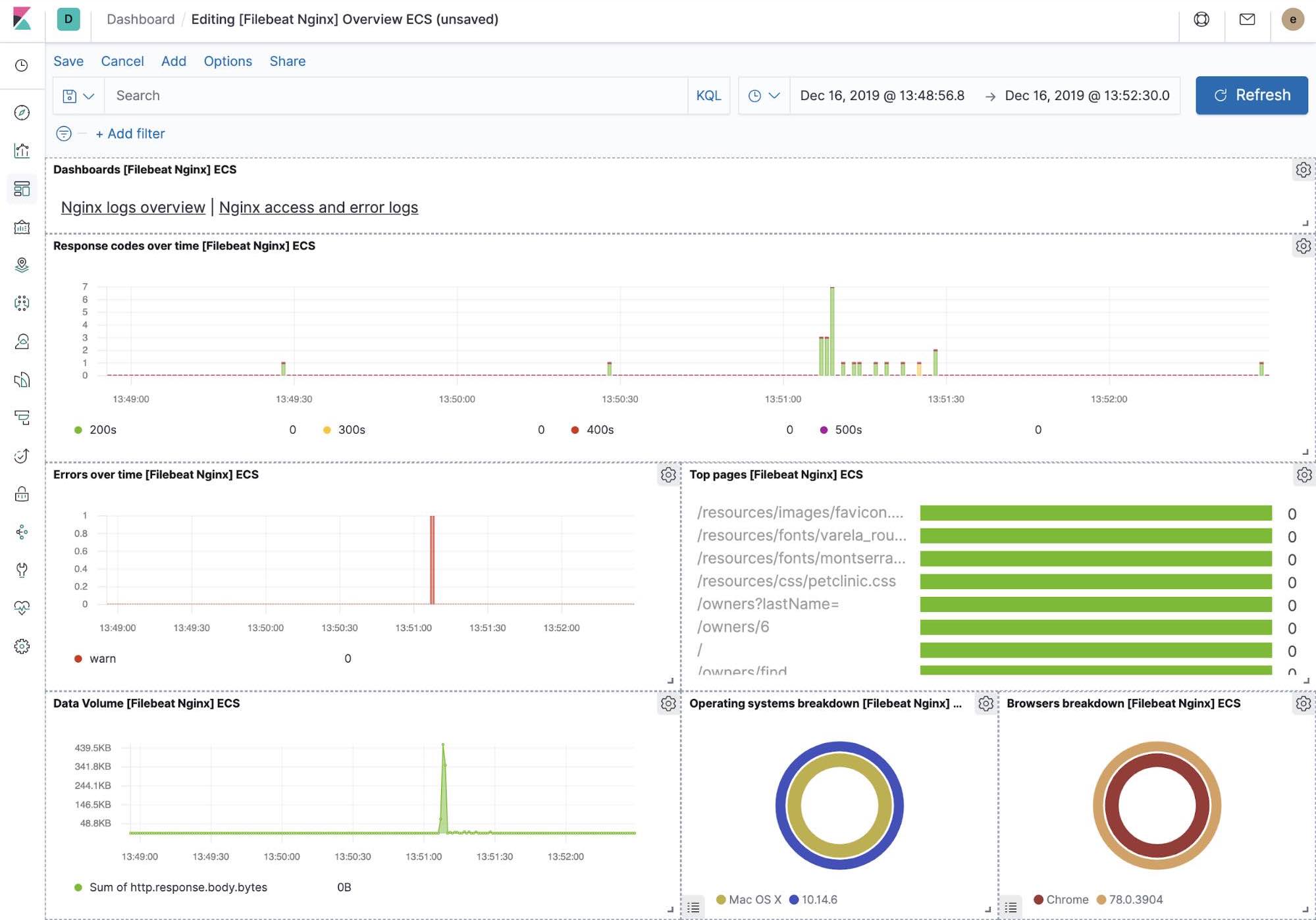
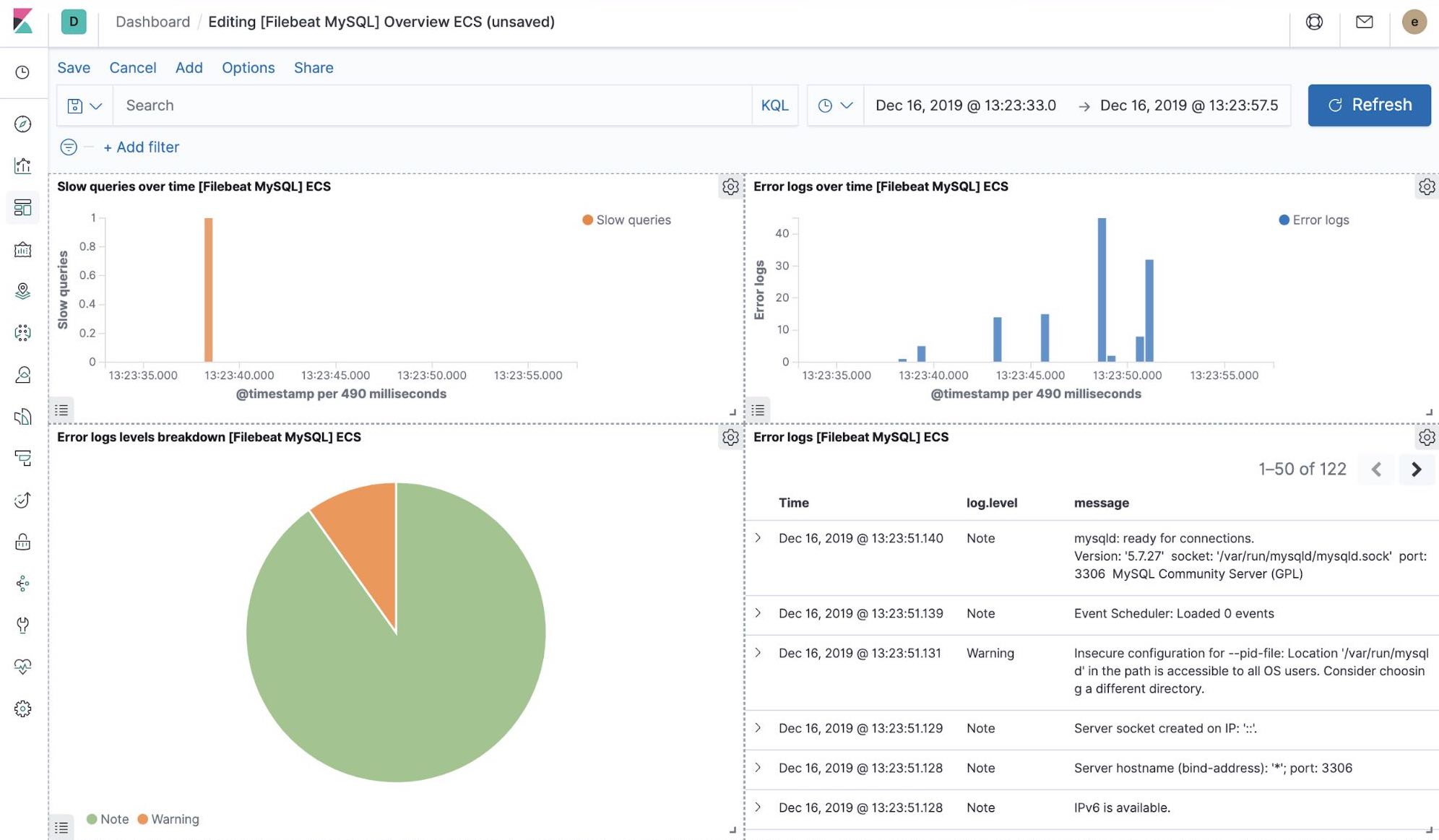
Quando executamos o trabalho filebeat-setup, entre outras coisas, ele pré-criou um conjunto de dashboards prontos para uso no Kibana. Uma vez que nossa aplicação petclinic de amostra esteja finalmente implantada, poderemos navegar para os dashboards prontos para uso do Filebeat para MySQL e NGINX, e ver que os módulos do Filebeat não apenas capturam logs, mas podem também capturar métricas que os componentes registram. Para habilitar essas visualizações, é necessário executar componentes do MySQL e do NGINX da aplicação de exemplo.
Machine learning e detecção de anomalias de logging
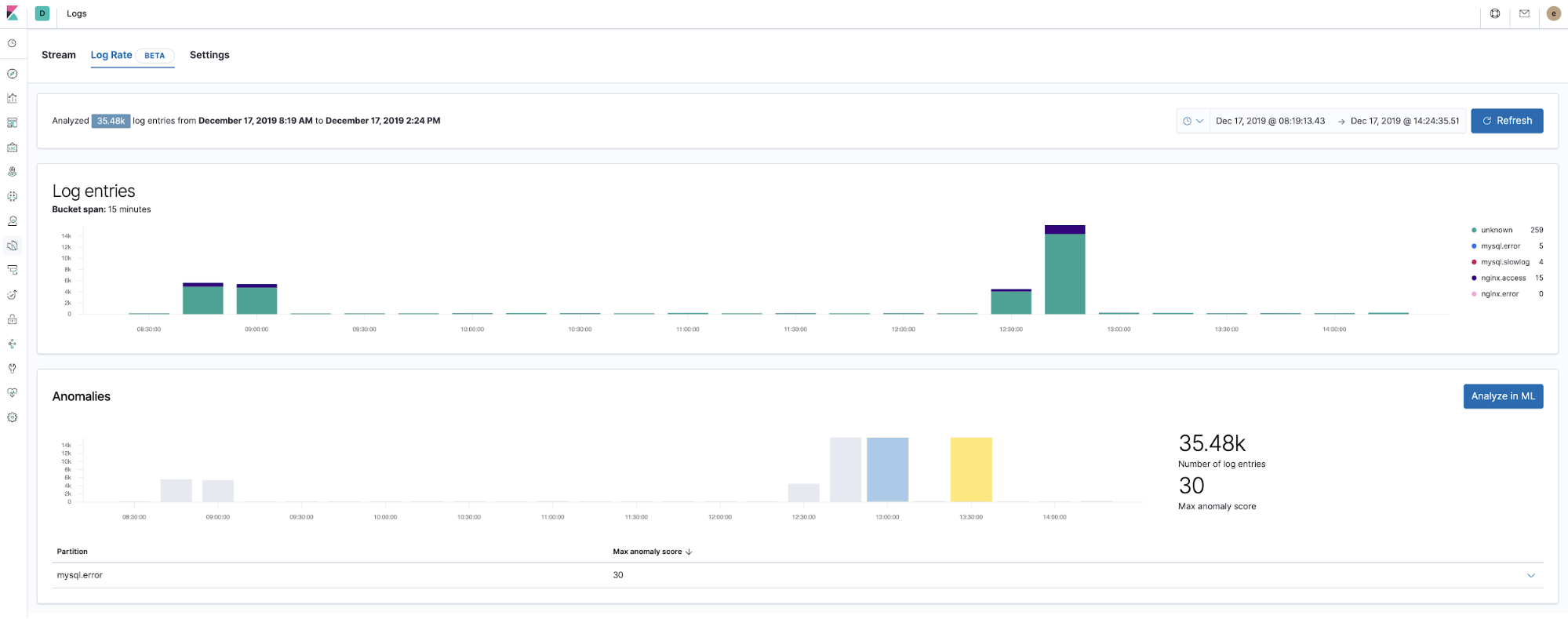
A partir da versão 7.5, o Elastic Stack pode detectar anomalias na taxa de log dos componentes da aplicação. Isso pode ser usado para detectar eventos como os seguintes:
- Uma nova aplicação ou fonte de log acabou de ser integrado(a)
- A atividade de logging aumentou repentinamente devido a uma promoção (ou ataque!)
- O envio de logs parou repentinamente, talvez devido a um agente ou ao mau funcionamento do pipeline de ingestão
O recurso de anomalias na taxa de log, introduzido diretamente no app do Logs, permite que os operadores obtenham respostas instantâneas para os eventos acima. Habilite-o com um único clique no app do Logs.
Detecção de eventos anteriormente desconhecidos com classificação de entradas de log
Outra aplicação útil de machine learning relacionada aos logs é a detecção de novas entradas de tipo de log que não foram observadas antes. De forma geral, o machine learning remove todas as partes numéricas e variáveis das entradas do log, como registros de data/hora, valores numéricos e outros, captura o que resta e realiza a categorização das partes fixas das entradas do log. Em seguida, tenta agrupá-los em buckets e continua a sinalizar novos buckets que aparecem como anomalias, representando as entradas do log que não foram vistas antes.

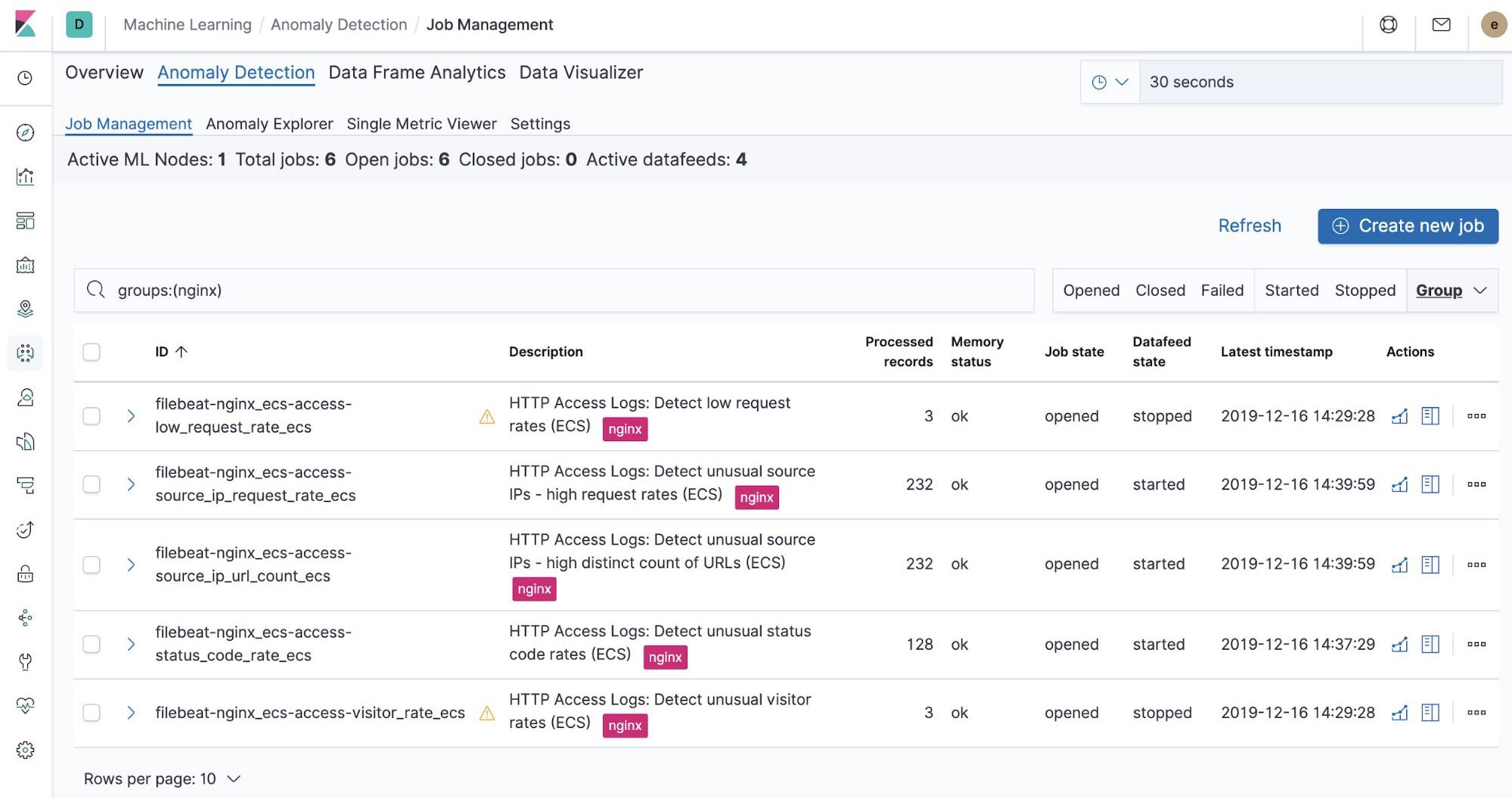
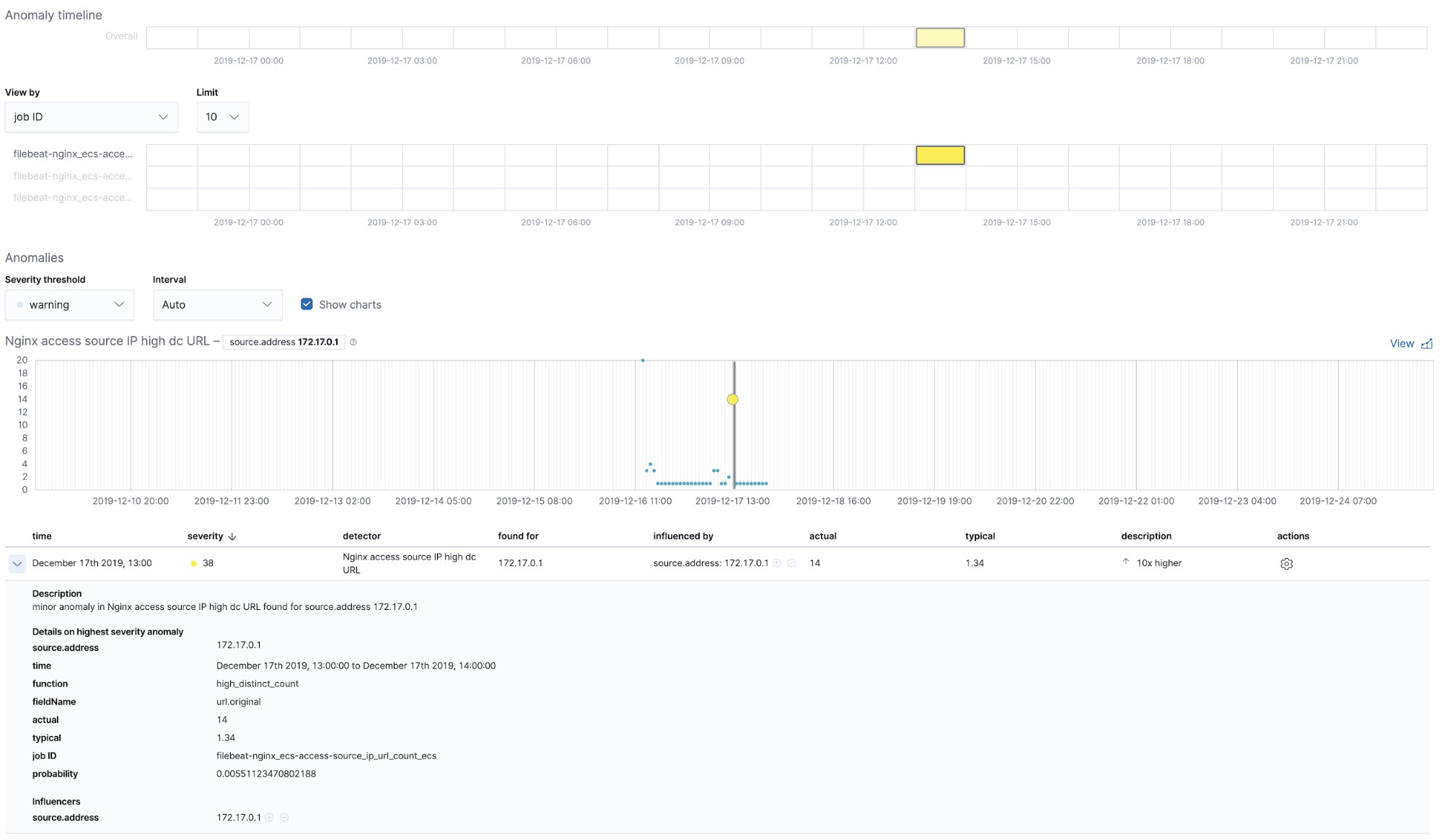
Trabalhos de machine learning prontos para uso — NGINX
No momento em que executamos o trabalho filebeat-setup, ele pré-criou os trabalhos de machine learning prontos para uso. Se ativados, eles podem começar a detectar anomalias nos dados de stdout e stderr do NGINX ingeridos do Filebeat.
Resumo
Nesta parte, fizemos a ingestão dos logs do Kubernetes no Elastic Stack usando o Filebeat e seus módulos. Você pode começar a monitorar seus sistemas e infraestrutura hoje mesmo, inscrevendo-se para fazer uma avaliação gratuita do Elasticsearch Service no Elastic Cloud ou baixando o Elastic Stack e hospedando-o você mesmo(a). Quando ele estiver em funcionamento, monitore a disponibilidade dos seus hosts com o Elastic Uptime e instrumente as aplicações em execução nos seus hosts com o Elastic APM. Você estará no caminho certo para ter um sistema totalmente observável, completamente integrado com seu novo cluster de métricas. Se encontrar obstáculos ou tiver dúvidas, vá para os nossos fóruns de discussão — estamos aqui para ajudar.