Como monitorar o Kafka em container com o Elastic Observability
Kafka é uma plataforma de streaming de eventos distribuída e altamente disponível que pode ser executada em bare metal, virtualizada, em container ou como um serviço gerenciado. Em sua essência, o Kafka é um sistema de publicação/assinatura (ou pub/sub), que fornece um “broker” para distribuir eventos. Os publishers publicam eventos em tópicos, e os consumidores se inscrevem nos tópicos. Quando um novo evento é enviado para um tópico, os consumidores que se inscreveram no tópico recebem uma notificação de novo evento. Isso permite que vários clientes sejam notificados sobre a atividade sem que o publisher precise saber quem ou o que está consumindo os eventos que ele publica. Por exemplo, quando um novo pedido chega, uma loja da Web pode publicar um evento com os detalhes do pedido, que pode ser usado pelos consumidores (aqui no sentido de consumidores de conteúdo, não consumidores da loja) no departamento de separação de pedidos para que eles saibam o que retirar das prateleiras, pelos consumidores no departamento de expedição para imprimir uma etiqueta ou por qualquer outra parte interessada para realizar uma ação. Dependendo de como você configura grupos de consumidores e partições, é possível controlar quais consumidores recebem novas mensagens.
O Kafka geralmente é implantado junto com o ZooKeeper, que ele usa para armazenar informações de configuração como tópicos, partições e informações de réplica/redundância. Ao monitorar os clusters do Kafka, é igualmente importante monitorar também as instâncias do ZooKeeper associadas, pois se o ZooKeeper tiver problemas, eles se propagarão para o cluster do Kafka.
Há muitas maneiras de usar o Kafka junto com o Elastic Stack. Você pode configurar o Metricbeat ou o Filebeat para enviar dados para tópicos do Kafka, pode enviar dados do Kafka para o Logstash ou do Logstash para o Kafka ou pode usar o Elastic Observability para monitorar o Kafka e o ZooKeeper e ficar de olho no cluster, que é sobre o que falaremos neste post do blog. Lembra-se dos eventos de “detalhes do pedido” mencionados acima? Usando o plugin de entrada do Kafka, o Logstash também pode se inscrever nesses eventos e trazer dados para o seu cluster do Elasticsearch. Ao adicionar dados de negócios (ou quaisquer outros dados de que precisa para realmente entender o que está acontecendo no seu ambiente), você aumenta a observabilidade dos seus sistemas.
O que procurar ao monitorar o Kafka
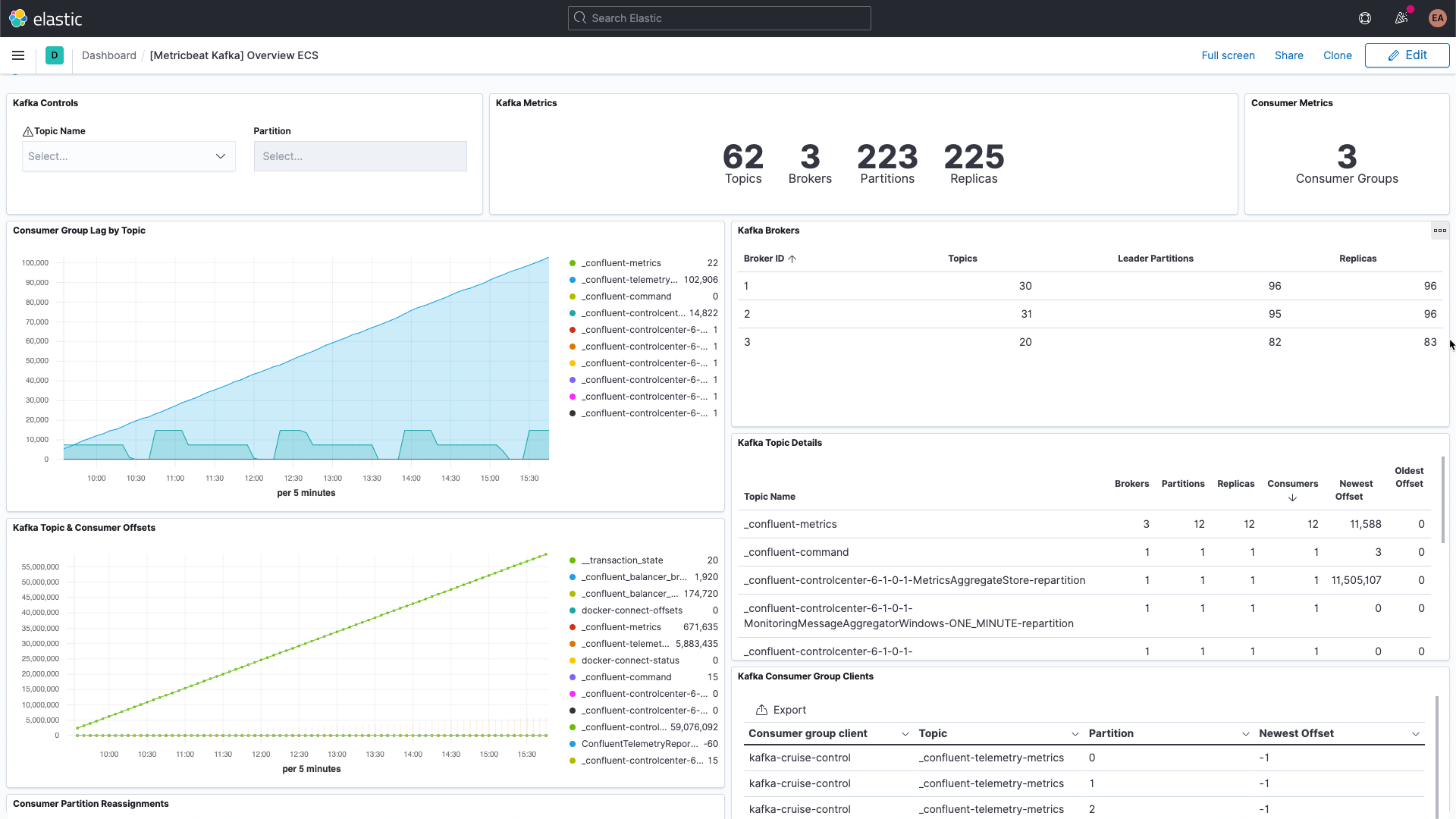
O Kafka tem várias partes móveis: há o próprio serviço, que geralmente consiste em vários brokers e instâncias do ZooKeeper, bem como os clientes que usam o Kafka, os produtores e os consumidores. Existem vários tipos de métricas que o Kafka fornece, alguns por meio dos próprios brokers e outros por meio do JMX. O broker fornece métricas para as partições e os grupos de consumidores. As partições permitem dividir mensagens entre vários brokers, paralelizando o processamento. Os consumidores recebem mensagens da partição de um único tópico e podem ser agrupados para consumir todas as mensagens de um tópico. Esses grupos de consumidores permitem que você divida a carga entre vários trabalhadores.
Cada mensagem do Kafka tem um deslocamento. O deslocamento é basicamente um identificador que indica onde a mensagem está na sequência de mensagens. Os produtores adicionam mensagens aos tópicos, cada uma recebendo um novo deslocamento. O deslocamento mais recente em uma partição mostra o ID mais recente. Os consumidores recebem as mensagens dos tópicos, e a diferença entre o deslocamento mais recente e o deslocamento que o consumidor recebe é a defasagem do consumidor. Invariavelmente, os consumidores ficarão um pouco atrás dos produtores. O que se deve observar é quando a defasagem do consumidor está sempre aumentando, pois isso indica que você provavelmente precisa de mais consumidores para processar a carga.
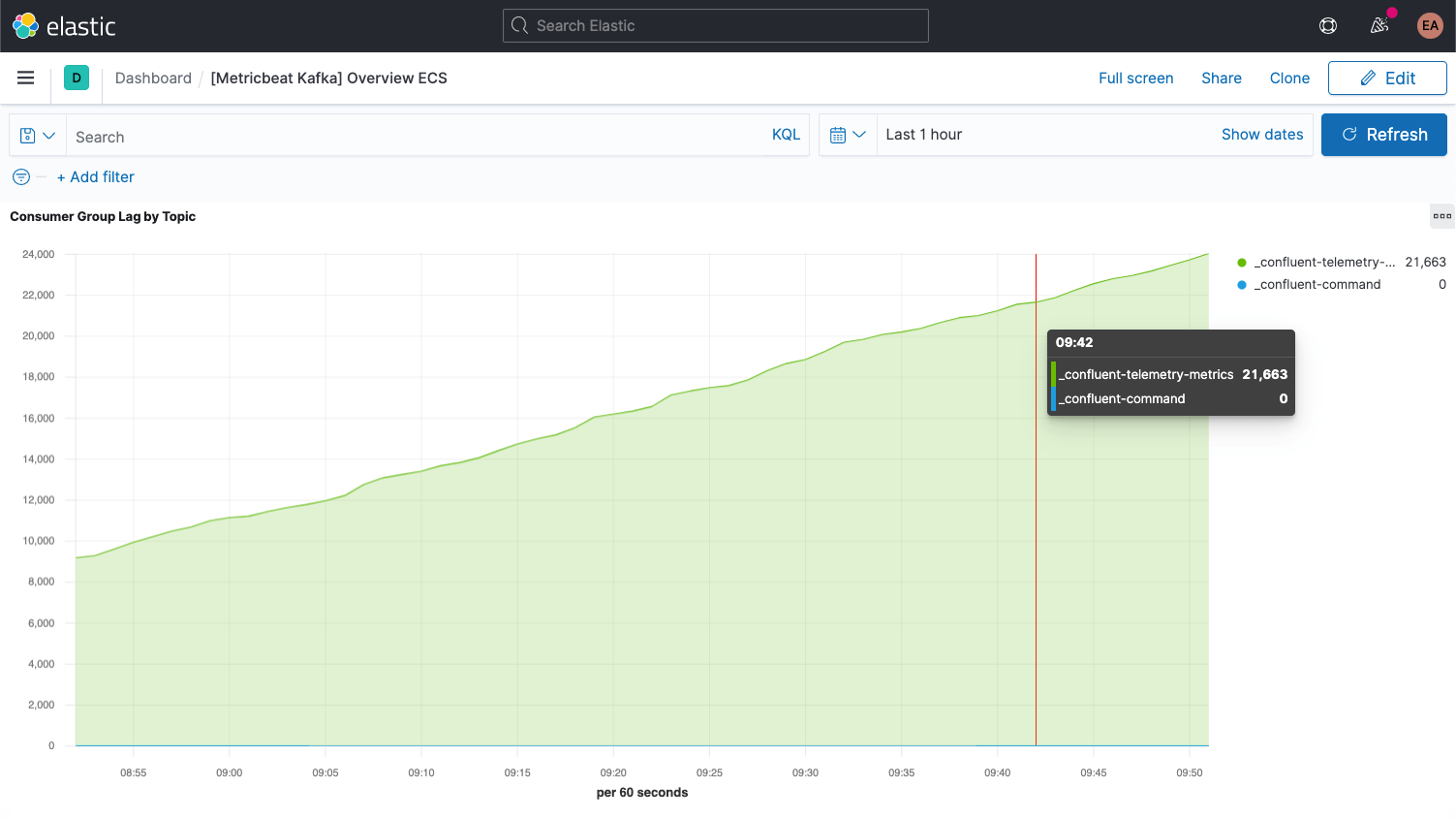
Ao analisar as métricas dos tópicos em si, é importante procurar tópicos que não tenham nenhum consumidor, pois isso pode indicar que algo que deveria estar sendo executado não está.
Examinaremos algumas métricas-chave adicionais para os brokers assim que tivermos tudo configurado.
Configuração do Kafka e do Zookeeper
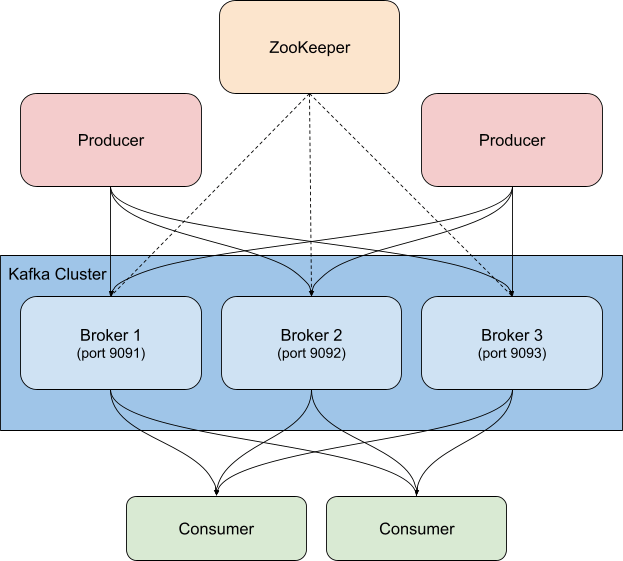
No nosso exemplo, estamos executando um cluster do Kafka em container com base na plataforma do Confluent, aumentado para três brokers do Kafka (imagens cp-server), junto com uma única instância do ZooKeeper. Na prática, você provavelmente também vai querer usar uma configuração mais robusta e altamente disponível para o ZooKeeper.
Clonei a configuração e mudei para o diretório cp-all-in-one:
git clone https://github.com/confluentinc/cp-all-in-one.git cd cp-all-in-one
Todo o resto neste post é feito a partir desse diretório cp-all-in-one.
Na minha configuração, ajustei as portas para ficar mais fácil saber qual porta vai com qual broker (eles precisam de portas diferentes porque cada uma é exposta ao host). Por exemplo, o broker3 está na porta 9093. Também mudei o nome do primeiro broker para broker1 por uma questão de consistência. Você pode ver o arquivo completo, antes da instrumentação, na minha bifurcação do repositório oficial do GitHub.
A configuração para broker1 após o realinhamento das portas ficou assim:
broker1:
image: confluentinc/cp-server:6.1.0
hostname: broker1
container_name: broker1
depends_on:
- zookeeper
ports:
- "9091:9091"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker1:29092,PLAINTEXT_HOST://broker1:9091
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: localhost
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker1:29092
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'
Como você pode ver, também mudei as ocorrências de nome de host de broker para broker1. Obviamente, qualquer outro bloco de configuração no docker-compose.yml que fizer referência ao broker também será alterado para refletir todos os três nós do nosso cluster, por exemplo. E o centro de controle do Confluent agora depende de todos os três brokers:
control-center:
image: confluentinc/cp-enterprise-control-center:6.1.0
hostname: control-center
container_name: control-center
depends_on:
- broker1
- broker2
- broker3
- schema-registry
- connect
- ksqldb-server
(...)
Reunir logs e métricas
Meus serviços do Kafka e do ZooKeeper estão sendo executados em containers, inicialmente com três brokers. Se eu redimensiono isso para mais ou para menos, ou decido deixar o lado do ZooKeeper mais robusto, não quero ter de reconfigurar e reiniciar o meu monitoramento: quero que isso aconteça dinamicamente. Para fazer isso, também executaremos o monitoramento em containers do Docker, junto com o cluster do Kafka, e utilizaremos a descoberta automática baseada em dicas do Elastic Beats.
Descoberta automática baseada em dicas
Para o monitoramento, reuniremos logs e métricas dos nossos brokers do Kafka e da instância do ZooKeeper. Usaremos o Metricbeat para as métricas e o Filebeat para os logs, ambos executados em containers. Para inicializar esse processo, precisamos baixar os arquivos de configuração do Docker para cada um: metricbeat.docker.yml e filebeat.docker.yml. Enviarei esses dados de monitoramento para a minha implantação do Elastic Observability no Elasticsearch Service no Elastic Cloud (se desejar acompanhar, inscreva-se para fazer uma avaliação gratuita). Se preferir gerenciar seu cluster sozinho(a), você poderá baixar o Elastic Stack gratuitamente e executá-lo localmente — eu incluí instruções para os dois cenários.
Independentemente de estar usando uma implantação no Elastic Cloud ou executando um cluster autogerenciado, você precisará especificar como encontrar o cluster — as URLs do Kibana e do Elasticsearch, e as credenciais para fazer login no cluster. O endpoint do Kibana nos permite carregar dashboards padrão e informações de configuração, e o Elasticsearch é para onde os Beats enviam os dados. Com o Elastic Cloud, o Cloud ID agrupa as informações do endpoint:
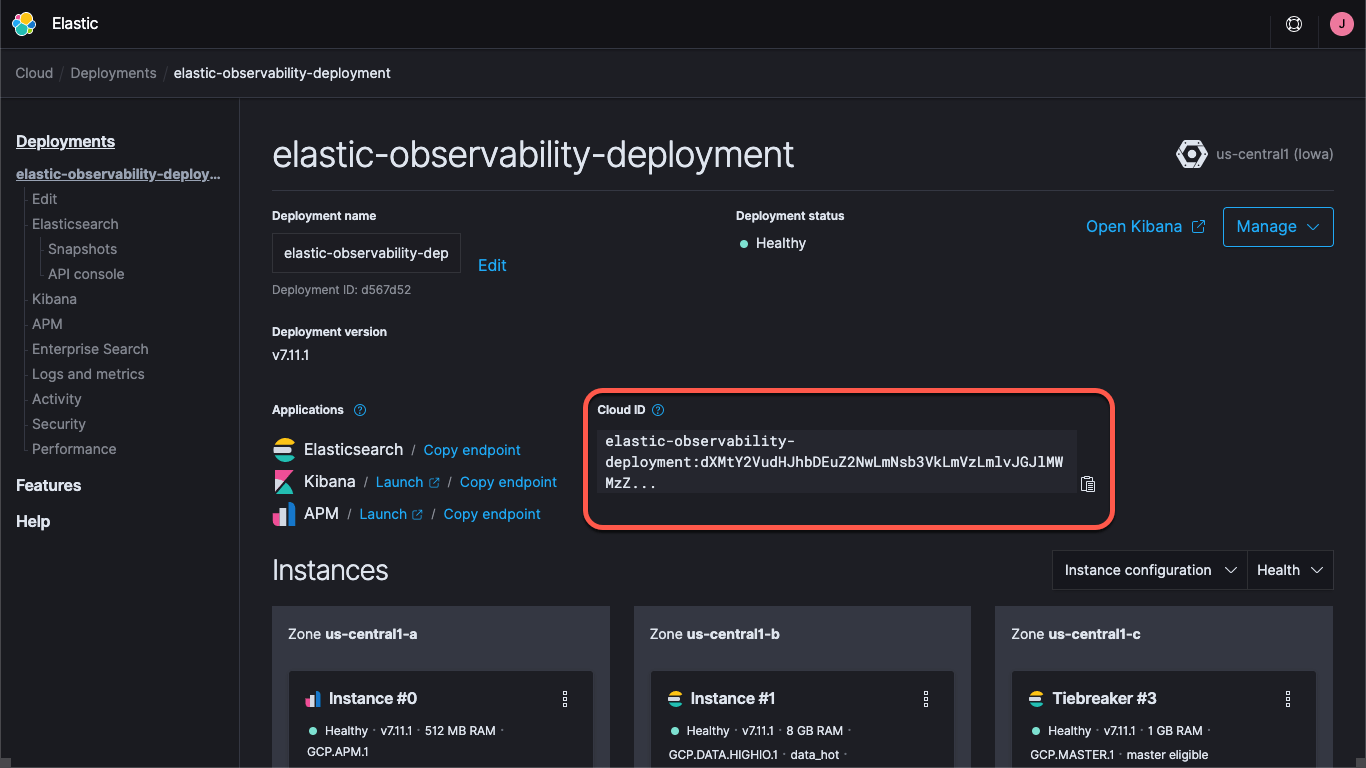
Ao criar uma implantação no Elastic Cloud, você recebe uma senha para o usuário elastic. Neste post do blog, usarei essas credenciais apenas para simplificar, mas a prática recomendada é criar chaves de API ou usuários e funções com o mínimo de privilégios necessários para a tarefa.
Vamos prosseguir e carregar os dashboards padrão para o Metricbeat e o Filebeat. Isso só precisa ser feito uma vez e é parecido para cada Beat. Para carregar o dashboard do Metricbeat, execute:
docker run --rm \
--name=metricbeat-setup \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false \
setup
Esse comando criará um container do Metricbeat (chamado metricbeat-setup), carregará o arquivo metricbeat.docker.yml que baixamos, conectará à instância do Kibana (obtida do campo cloud.id) e executará o comando setup, que carregará os dashboards. Se não estiver usando o Elastic Cloud, você fornecerá as URLs do Kibana e do Elasticsearch por meio dos campos setup.kibana.host e output.elasticsearch.hosts, junto com os campos de credenciais individuais, o que seria mais ou menos assim:
docker run --rm \
--name=metricbeat-setup \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E setup.kibana.host=localhost:5601 \
-E setup.kibana.username=elastic \
-E setup.kibana.password=your-password \
-E output.elasticsearch.hosts=localhost:9200 \
-E output.elasticsearch.username=elastic \
-E output.elasticsearch.password=your-password \
-e -strict.perms=false \
setup
O -e -strict.perms=false ajuda a mitigar um problema inevitável de propriedade/permissão do arquivo do Docker.
Da mesma forma, para configurar o dashboard dos logs, você executaria um comando semelhante para o Filebeat:
docker run --rm \
--name=filebeat-setup \
--volume="$(pwd)/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \
docker.elastic.co/beats/filebeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false \
setup
Por padrão, esses arquivos de configuração são criados para monitorar containers genéricos, reunindo logs e métricas do container. Isso é útil até certo ponto, mas queremos ter certeza de que eles também capturem logs e métricas específicos do serviço. Para fazer isso, configuraremos os nossos containers do Metricbeat e do Filebeat para usar a descoberta automática, conforme mencionado acima. Existem algumas maneiras diferentes de fazer isso. Poderíamos definir as configurações dos Beats para procurar imagens ou nomes específicos, mas isso exige muito conhecimento antecipado. Em vez disso, usaremos a descoberta automática baseada em dicas e permitiremos que os próprios containers instruam os Beats quanto a como monitorá-los.
Com a descoberta automática baseada em dicas, adicionamos rótulos aos containers do Docker. Quando outros containers são inicializados, os containers metricbeat e filebeat (que ainda não iniciamos) recebem uma notificação que lhes permite iniciar o monitoramento. Queremos configurar os containers do broker para que sejam monitorados pelos módulos Metricbeat e Filebeat do Kafka, e também queremos que o Metricbeat use o módulo do ZooKeeper para métricas. O Filebeat coletará os logs do ZooKeeper sem qualquer análise especial.
A configuração do ZooKeeper é mais simples do que a do Kafka, portanto, começaremos por aí. A configuração inicial no nosso docker-compose.yml para o ZooKeeper é assim:
zookeeper:
image: confluentinc/cp-zookeeper:6.1.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
Queremos adicionar um bloco de rótulos ao YAML para especificar o módulo, as informações de conexão e os conjuntos de métricas, que fica assim:
labels:
- co.elastic.metrics/module=zookeeper
- co.elastic.metrics/hosts=zookeeper:2181
- co.elastic.metrics/metricsets=mntr,server
Eles informam ao container metricbeat que ele deve usar o módulo zookeeper para monitorar esse container e que pode acessá-lo por meio do host/porta zookeeper:2181, que é a porta na qual o ZooKeeper está configurado para escutar. Eles informam também que os conjuntos de métricas mntr e server do módulo ZooKeeper devem ser usados. Apenas uma observação: versões recentes do ZooKeeper bloqueiam algumas das chamadas “palavras de quatro letras” (que em inglês são palavrões e palavras ofensivas), portanto, também precisamos adicionar os comandos srvr e mntr à lista aprovada em nossa implantação via KAFKA_OPTS. Assim que fizermos isso, a configuração do ZooKeeper no arquivo de composição ficará assim:
zookeeper:
image: confluentinc/cp-zookeeper:6.1.0
hostname: zookeeper
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
KAFKA_OPTS: "-Dzookeeper.4lw.commands.whitelist=srvr,mntr"
labels:
- co.elastic.metrics/module=zookeeper
- co.elastic.metrics/hosts=zookeeper:2181
- co.elastic.metrics/metricsets=mntr,server
A captura de logs dos brokers é bastante simples; apenas adicionamos um rótulo a cada um deles para o módulo de logging, co.elastic.logs/module=kafka. Já para as métricas, isso é um pouco mais complicado. Existem cinco conjuntos de métricas diferentes no módulo do Kafka do Metricbeat:
- Métricas do grupo de consumidores
- Métricas da partição
- Métricas do broker
- Métricas do consumidor
- Métricas do produtor
Os primeiros dois conjuntos de métricas vêm dos próprios brokers, enquanto os três últimos vêm via JMX. Os dois últimos, consumer e producer, são aplicáveis apenas a consumidores e produtores baseados em Java (os clientes do cluster do Kafka), respectivamente, portanto, não os abordaremos aqui (mas eles seguem os mesmos padrões que veremos). Vamos abordar os dois primeiros, pois são configurados da mesma maneira. A configuração inicial do Kafka no nosso arquivo de composição para broker1 é assim:
broker1:
image: confluentinc/cp-server:6.1.0
hostname: broker1
container_name: broker1
depends_on:
- zookeeper
ports:
- "9091:9091"
- "9101:9101"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker1:29091,PLAINTEXT_HOST://broker1:9091
KAFKA_METRIC_REPORTERS: io.confluent.metrics.reporter.ConfluentMetricsReporter
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_CONFLUENT_LICENSE_TOPIC_REPLICATION_FACTOR: 1
KAFKA_CONFLUENT_BALANCER_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_JMX_PORT: 9101
KAFKA_JMX_HOSTNAME: broker1
KAFKA_CONFLUENT_SCHEMA_REGISTRY_URL: http://schema-registry:8081
CONFLUENT_METRICS_REPORTER_BOOTSTRAP_SERVERS: broker1:29091
CONFLUENT_METRICS_REPORTER_TOPIC_REPLICAS: 1
CONFLUENT_METRICS_ENABLE: 'true'
CONFLUENT_SUPPORT_CUSTOMER_ID: 'anonymous'
De forma semelhante à configuração do ZooKeeper, precisamos adicionar rótulos para informar ao Metricbeat como reunir as métricas do Kafka:
labels:
- co.elastic.logs/module=kafka
- co.elastic.metrics/module=kafka
- co.elastic.metrics/metricsets=partition,consumergroup
- co.elastic.metrics/hosts='$${data.container.name}:9091'
Isso configura os módulos kafka do Metricbeat e do Filebeat para reunir logs do Kafka e as métricas partition e consumergroup do container, broker1 na porta 9091. Observe que usei uma variável, data.container.name (escapada com um cifrão duplo) em vez do nome do host; você pode usar o padrão de sua preferência. Precisamos repetir isso para cada broker, ajustando a porta 9091 para cada um (é por isso que os alinhei no início — usaríamos 9092 e 9093 para os brokers 2 e 3, respectivamente).
Podemos iniciar o cluster do Confluent executando docker-compose up --detach; agora também podemos iniciar o Metricbeat e o Filebeat, e eles começarão a reunir logs e métricas do Kafka.
Depois de ativar o cluster do Kafka cp-all-in-one, ele criará e executará em sua própria rede virtual, cp-all-in-one_default. Como estamos usando nomes de serviço/host em nossos rótulos, o Metricbeat precisa ser executado na mesma rede para que possa resolver os nomes e se conectar corretamente. Para iniciar o Metricbeat, incluímos o nome da rede no comando run:
docker run -d \
--name=metricbeat \
--user=root \
--network cp-all-in-one_default \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false
O comando run do Filebeat é semelhante, mas não requer a rede porque não está se conectando aos outros containers, mas diretamente do host do Docker:
docker run -d \
--name=filebeat \
--user=root \
--volume="$(pwd)/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro" \
--volume="/mnt/data/docker/containers:/var/lib/docker/containers:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/filebeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false
Em cada caso, carregamos o arquivo YAML de configuração, mapeamos o arquivo docker.sock do host para o container e incluímos as informações de conectividade (se estiver executando um cluster autogerenciado, pegue as credenciais que você usou ao carregar o dashboard). Observe que, se estiver executando no Docker Desktop em um Mac, você não terá acesso aos logs, porque eles ficam armazenados dentro da máquina virtual.
Visualização do desempenho e do histórico do Kafka e do ZooKeeper
Agora estamos capturando logs específicos do serviço dos nossos brokers do Kafka, e logs e métricas do Kafka e do ZooKeeper. Se você navegar até os dashboards no Kibana e filtrar, deverá ver os dashboards do Kafka:
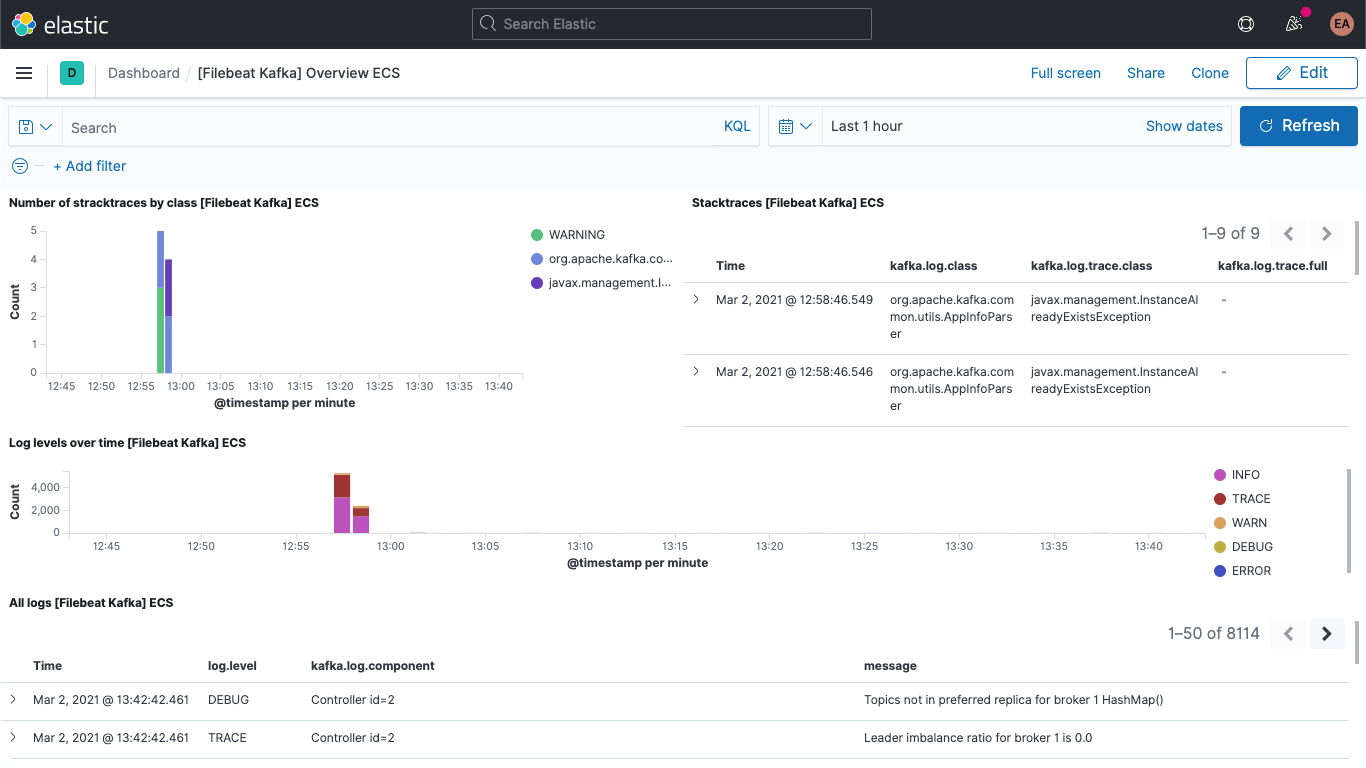
Incluindo o dashboard dos logs do Kafka:
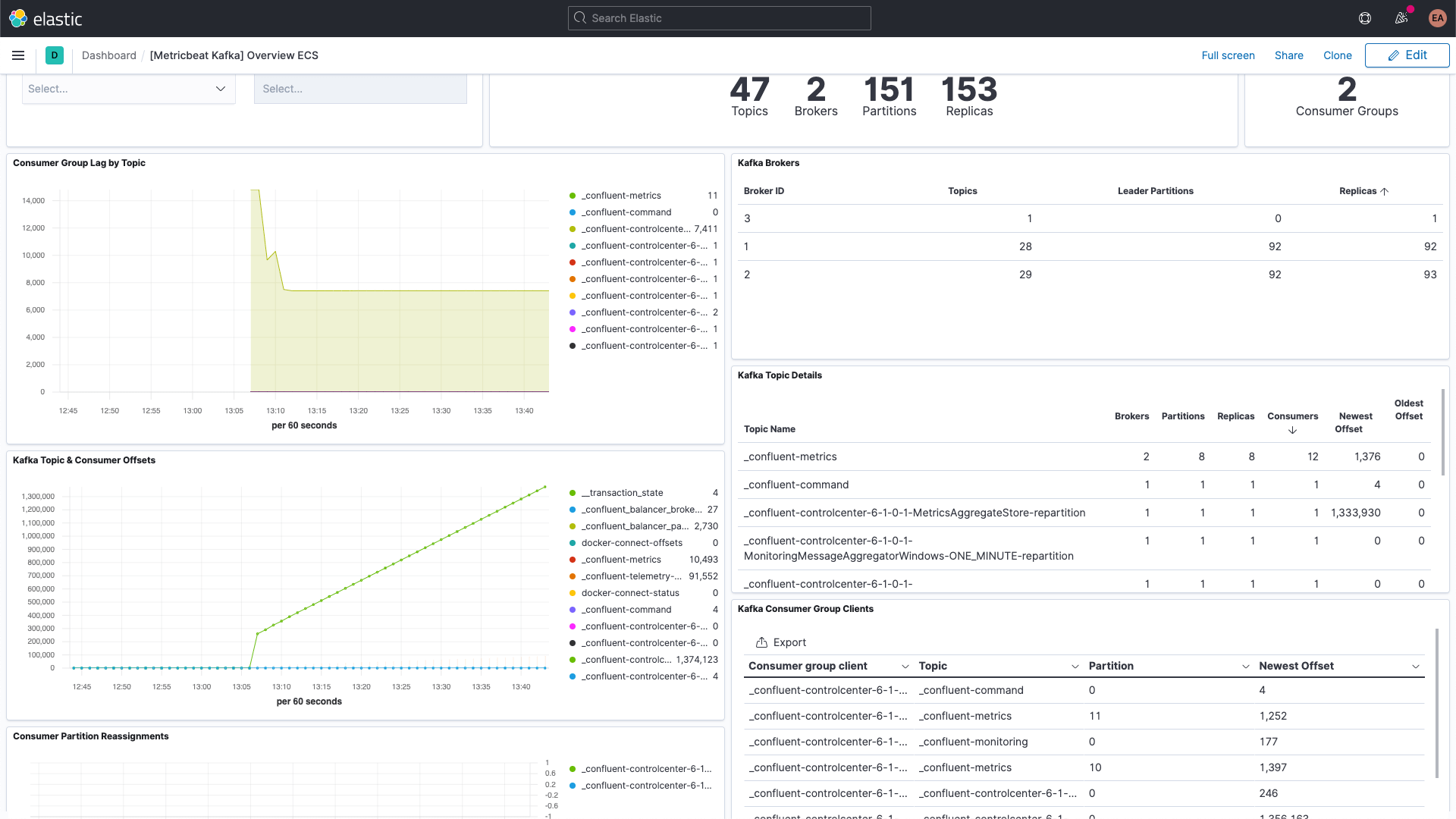
E o dashboard de métricas do Kafka:
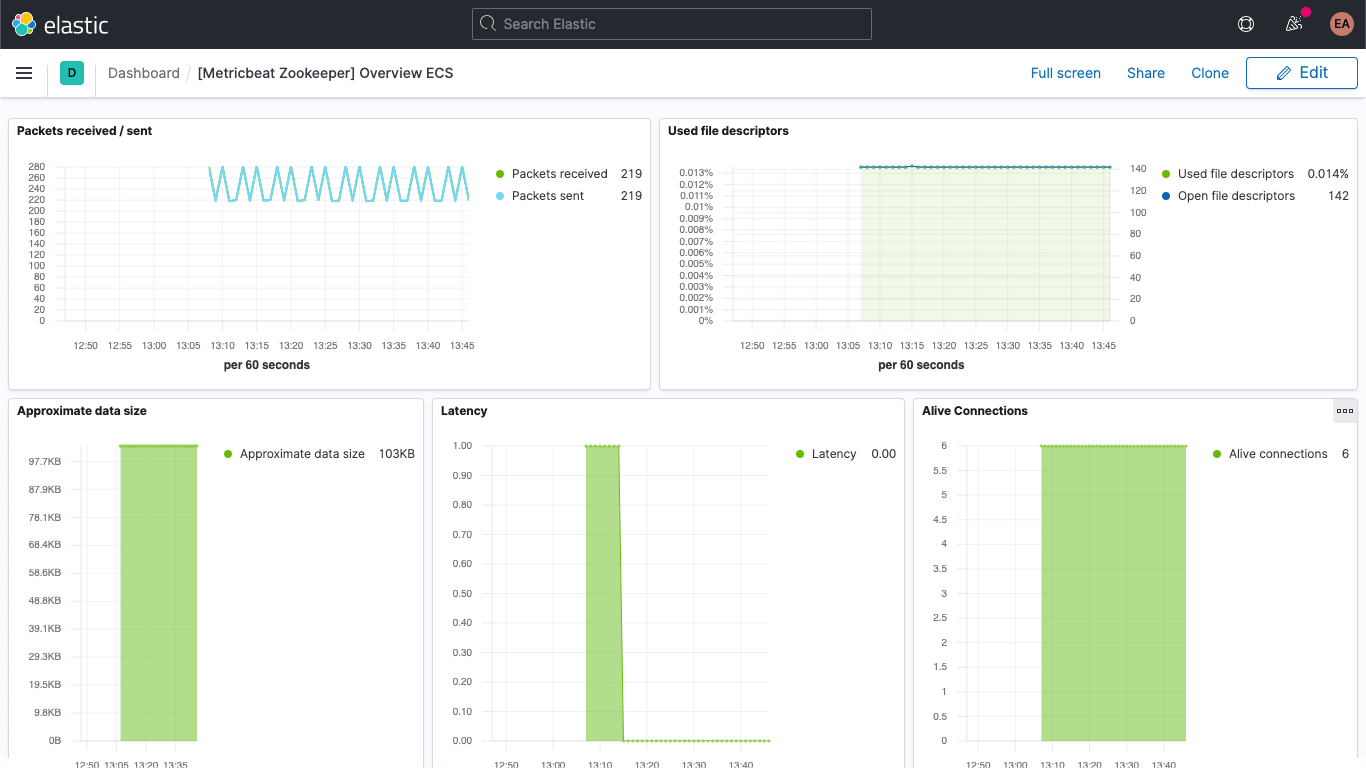
Também há um dashboard para as métricas do ZooKeeper.
Além disso, seus logs do Kafka e do ZooKeeper estão disponíveis no app Logs no Kibana, permitindo filtrar, fazer buscas neles e detalhá-los:
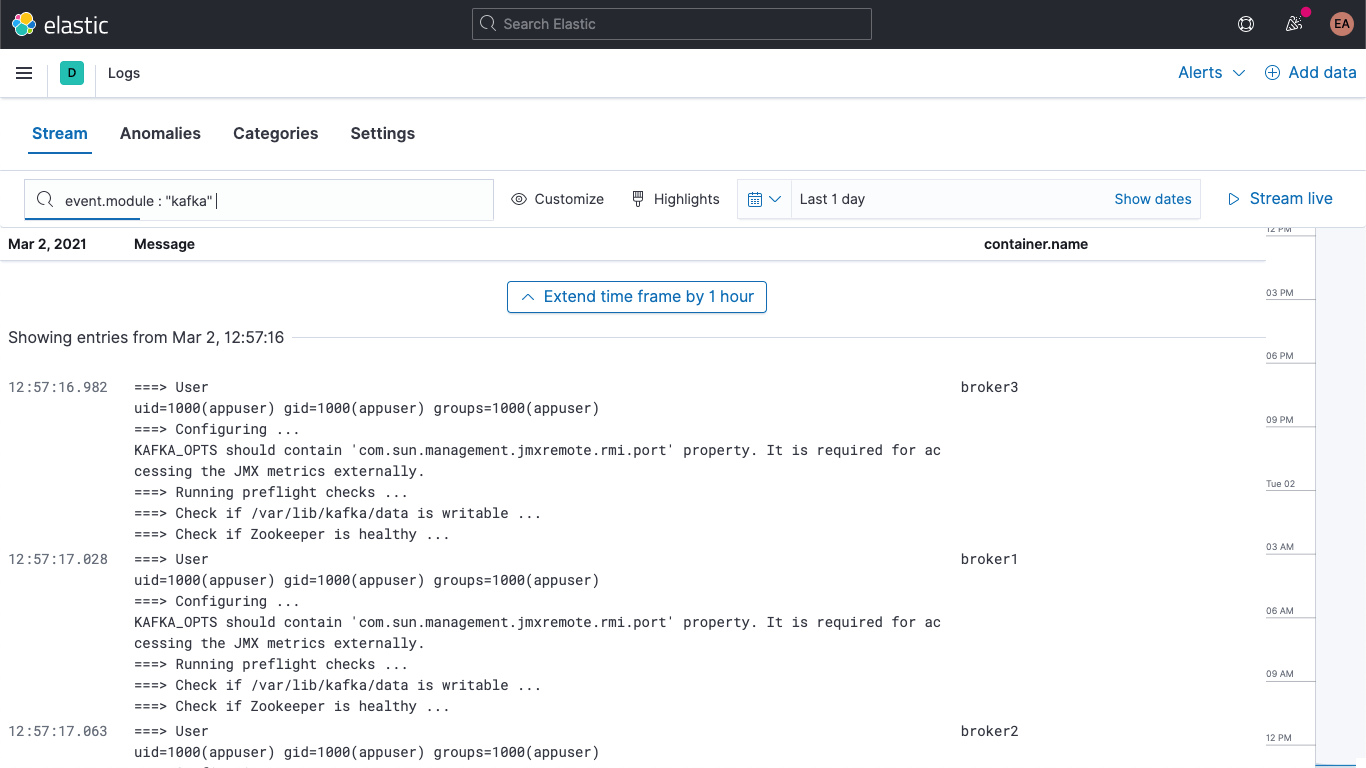
Já as métricas dos containers do Kafka e do ZooKeeper podem ser examinadas usando o app Metrics no Kibana. Elas são mostradas aqui agrupadas por tipo de serviço:
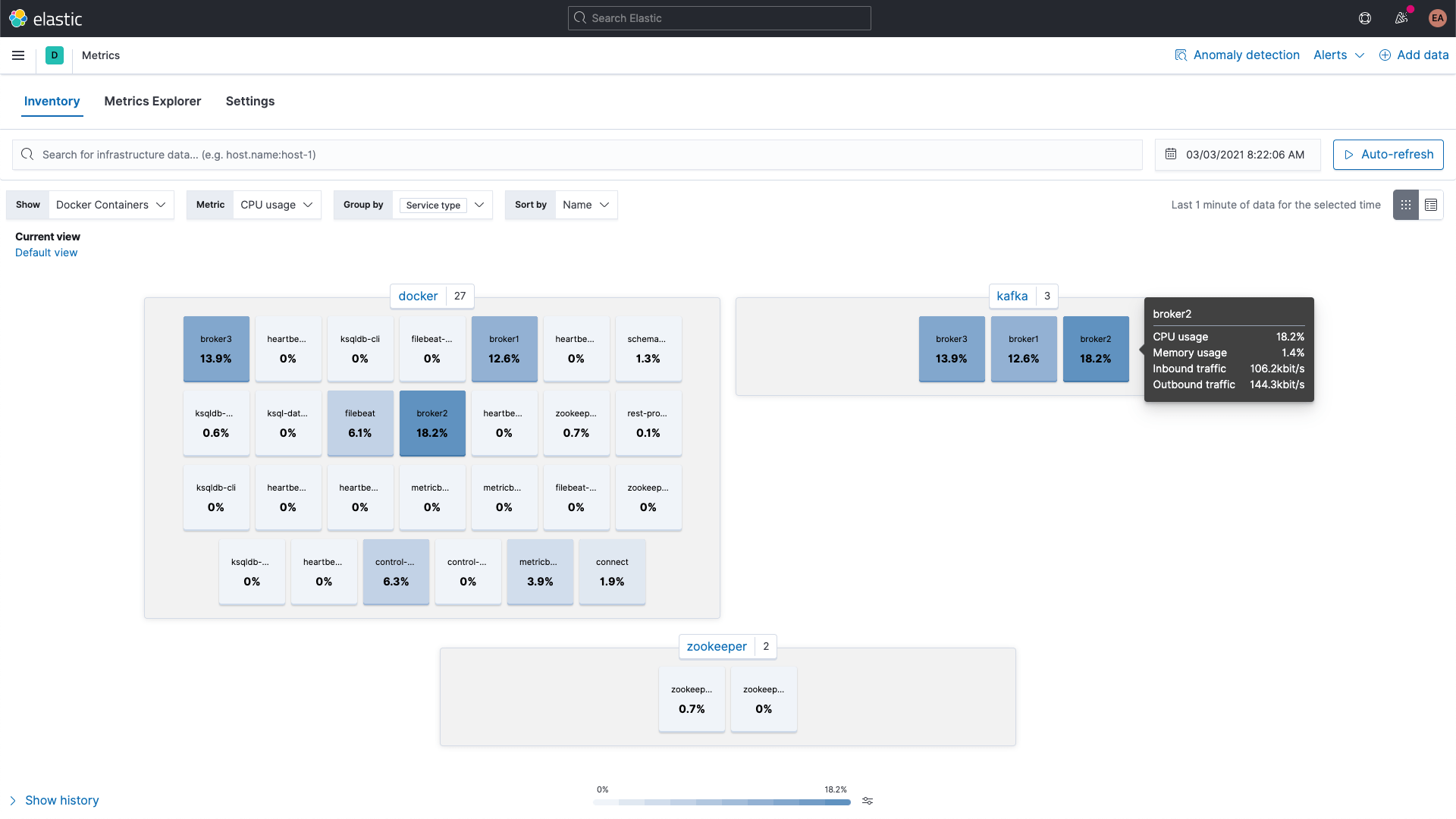
Métricas do broker
Vamos voltar e também reunir métricas do conjunto de métricas broker no módulo kafka. Eu havia mencionado anteriormente que essas métricas são recuperadas do JMX. Os conjuntos de métricas do broker, do produtor e do consumidor utilizam o Jolokia, uma ponte de JMX para HTTP, nos bastidores. O conjunto de métricas broker também faz parte do módulo kafka, mas como usa o JMX, precisa usar uma porta diferente dos conjuntos de métricas consumergroup e partition. Isso significa que precisamos de um novo bloco nos rótulos para nossos brokers, semelhante à configuração de anotação para vários conjuntos de dicas.
Também precisamos incluir o JAR para o Jolokia — vamos adicioná-lo aos containers do broker por meio de um volume e configurá-lo também. De acordo com a página de download, a versão atual do agente JVM do Jolokia é 1.6.2, então vamos pegá-lo (o -OL diz ao cURL para salvar o arquivo como o nome remoto e seguir os redirecionamentos):
curl -OL https://search.maven.org/remotecontent?filepath=org/jolokia/jolokia-jvm/1.6.2/jolokia-jvm-1.6.2-agent.jar
Adicionamos uma seção à configuração para cada um dos brokers para anexar o arquivo JAR aos containers:
volumes:
- ./jolokia-jvm-1.6.2-agent.jar:/home/appuser/jolokia.jar
E especificar o KAFKA_JVM_OPTS para anexar o JAR como um agente Java (observe que as portas são por broker, portanto, é 8771-8773 para os brokers 1, 2 e 3):
KAFKA_JMX_OPTS: '-javaagent:/home/appuser/jolokia.jar=port=8771,host=broker1 -Dcom.sun.management.jmxremote=true -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false'
Não estou usando nenhum tipo de autenticação para isso, então preciso adicionar alguns sinalizadores à execução. Observe que o caminho do arquivo jolokia.jar no KAFKA_JMX_OPTS corresponde ao caminho no volume.
Precisamos fazer mais alguns pequenos ajustes. Como estamos usando o Jolokia, não precisamos mais expor o KAFKA_JMX_PORT na seção ports. Em vez disso, exporemos a porta na qual o Jolokia está escutando, 8771. Também removeremos os valores KAFKA_JMX_* da configuração.
Se reiniciarmos o nosso cluster do Kafka (docker-compose up --detach), começaremos a ver as métricas do broker aparecerem na nossa implantação do Elasticsearch. Se eu for para a aba Discover, selecionar o padrão de indexação metricbeat-* e fazer uma busca por metricset.name : "broker", poderei ver que realmente tenho dados:
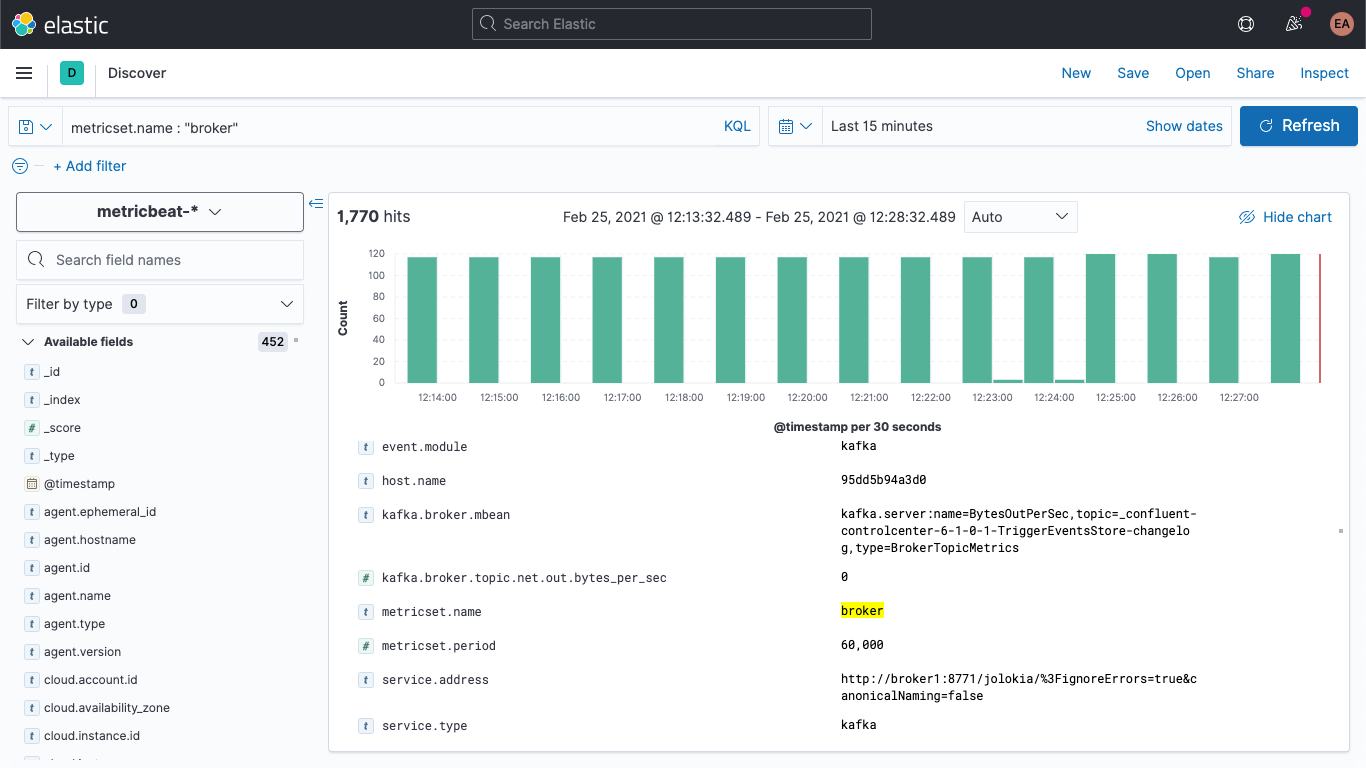
A estrutura das métricas do broker é mais ou menos assim:
kafka
└─ broker
├── address
├── id
├── log
│ └── flush_rate
├── mbean
├── messages_in
├── net
│ ├── in
│ │ └── bytes_per_sec
│ ├── out
│ │ └── bytes_per_sec
│ └── rejected
│ └── bytes_per_sec
├── replication
│ ├── leader_elections
│ └── unclean_leader_elections
└── request
├── channel
│ ├── fetch
│ │ ├── failed
│ │ └── failed_per_second
│ ├── produce
│ │ ├── failed
│ │ └── failed_per_second
│ └── queue
│ └── size
├── session
│ └── zookeeper
│ ├── disconnect
│ ├── expire
│ ├── readonly
│ └── sync
└── topic
├── messages_in
└── net
├── in
│ └── bytes_per_sec
├── out
│ └── bytes_per_sec
└── rejected
└── bytes_per_sec
Essencialmente saindo como pares nome/valor, conforme indicado pelo campo kafka.broker.mbean. Vejamos o campo kafka.broker.mbean de um exemplo de métrica:
kafka.server:name=BytesOutPerSec,topic=_confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelog,type=BrokerTopicMetrics
Isso contém o nome da métrica (BytesOutPerSec), o tópico do Kafka ao qual se refere (_confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelog) e o tipo de métrica (BrokerTopicMetrics). Dependendo do tipo e do nome da métrica, diferentes campos serão definidos. Neste exemplo, apenas o kafka.broker.topic.net.out.bytes_per_sec é preenchido (é 0). Se olharmos para isso de uma maneira razoavelmente colunar, você poderá ver que os dados são muito esparsos:
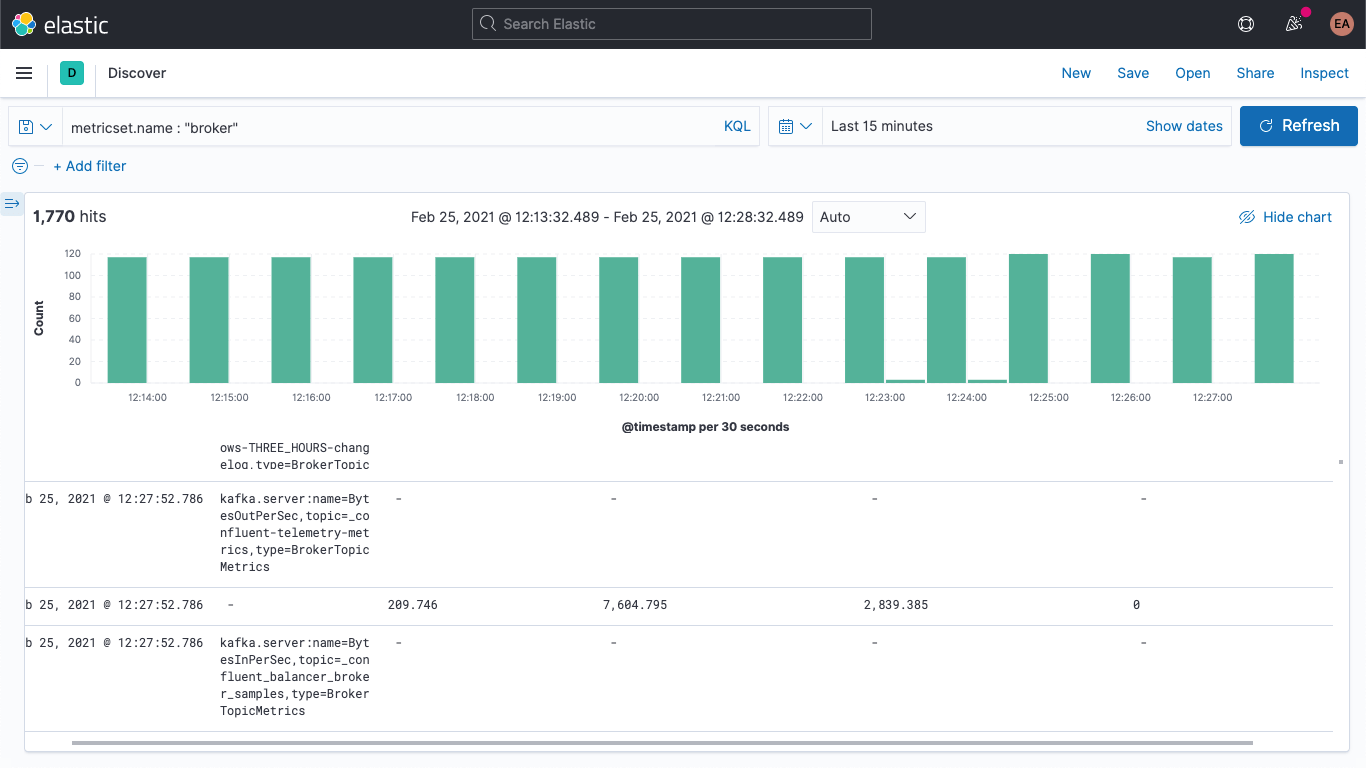
Poderemos recolher isso um pouco se adicionarmos um pipeline de ingestão, para dividir o campo mbean em campos individuais, o que também nos permitirá visualizar os dados com mais facilidade. Vamos dividi-lo em três campos:
- KAFKA_BROKER_METRIC (que seria BytesOutPerSec do exemplo acima)
- KAFKA_BROKER_TOPIC (que seria _confluent-controlcenter-6-1-0-1-TriggerEventsStore-changelog do exemplo acima)
- KAFKA_BROKER_TYPE (que seria BrokerTopicMetrics do exemplo acima)
No Kibana, vá para Dev Tools (Ferramentas do desenvolvedor):
Lá, cole o seguinte para definir um pipeline de ingestão chamado kafka-broker-fields
PUT _ingest/pipeline/kafka-broker-fields
{
"processors": [
{
"grok": {
"if": "ctx.kafka?.broker?.mbean != null",
"field": "kafka.broker.mbean",
"patterns": ["kafka.server:name=%{GREEDYDATA:kafka_broker_metric},topic=%{GREEDYDATA:kafka_broker_topic},type=%{GREEDYDATA:kafka_broker_type}"
]
}
}
]
}
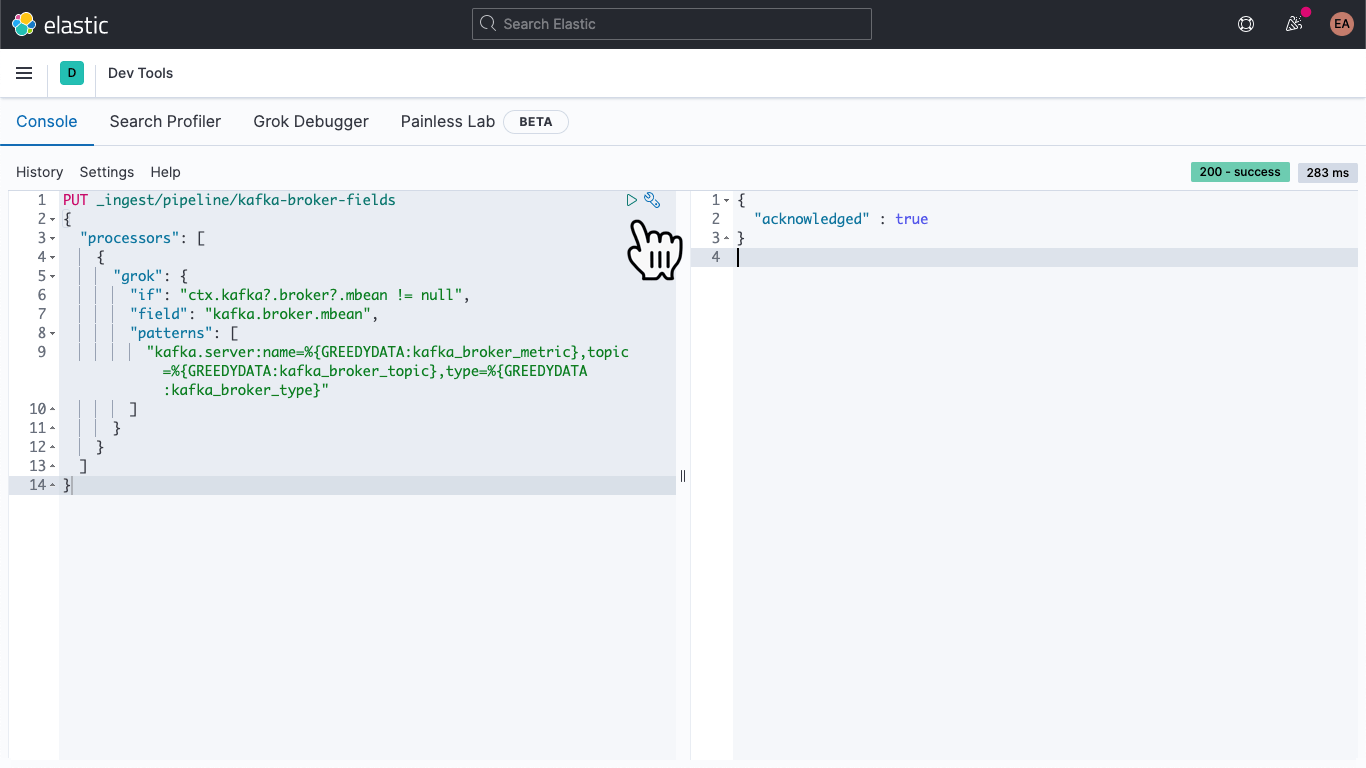
Em seguida, clique no ícone de reprodução (Play). Você deverá obter um reconhecimento, conforme mostrado acima.
Nosso pipeline de ingestão está em vigor, mas não fizemos nada com ele ainda. Nossos dados antigos ainda são esparsos e difíceis de acessar, e os novos dados ainda chegam da mesma maneira. Vamos abordar a última parte primeiro.
Abra o arquivo metricbeat.docker.yml no seu editor de texto favorito, adicione uma linha ao bloco output.elasticsearch (você poderá remover a configuração de hosts, nome de usuário e senha lá se não estiver usando) e especifique o nosso pipeline, desta forma:
output.elasticsearch: pipeline: kafka-broker-fields
Isso informa ao Elasticsearch que cada documento que chegar deverá passar por esse pipeline para verificar o nosso campo mbean. Reinicie o Metricbeat:
docker rm --force metricbeat
docker run -d \
--name=metricbeat \
--user=root \
--network cp-all-in-one_default \
--volume="$(pwd)/metricbeat.docker.yml:/usr/share/metricbeat/metricbeat.yml:ro" \
--volume="/var/run/docker.sock:/var/run/docker.sock:ro" \
docker.elastic.co/beats/metricbeat:7.11.1 \
-E cloud.id=elastic-observability-deployment:dXMtY2VudHJhbDEuZ2NwLmNsb3VkLmV... \
-E cloud.auth=elastic:some-long-random-password \
-e -strict.perms=false
Podemos verificar no Discover (Descoberta) que os novos documentos têm os novos campos:
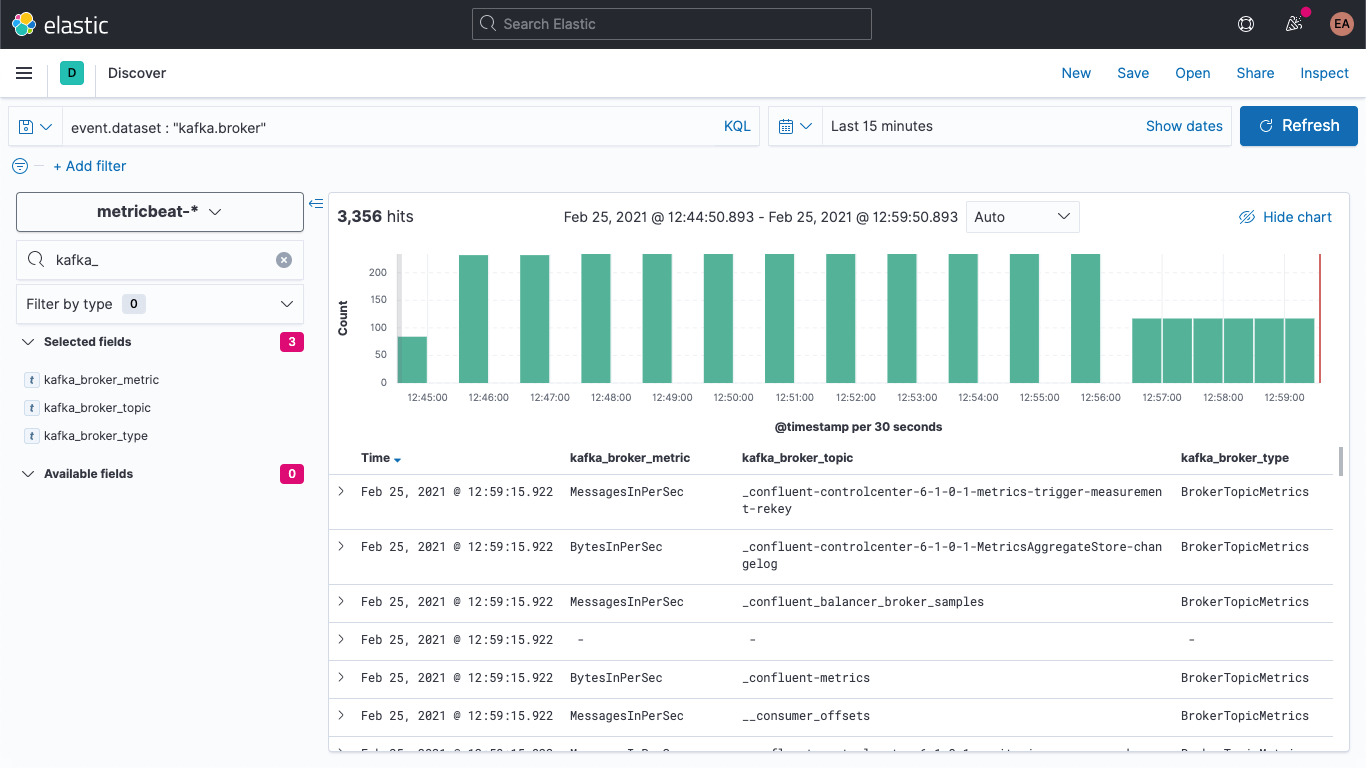
Também podemos atualizar os documentos mais antigos para que eles também tenham esses campos preenchidos. De volta ao Dev Tools, execute este comando:
POST metricbeat-*/_update_by_query?pipeline=kafka-broker-fields
Ele provavelmente avisará que o tempo limite expirou, mas está em execução em segundo plano e terminará de forma assíncrona.
Visualização das métricas do broker
Vá para o app Metrics e selecione a aba “Metrics Explorer” (Explorador de métricas) para dar uma olhada em nossos novos campos. Cole kafka.broker.topic.net.in.bytes_per_sec e kafka.broker.topic.net.out.bytes_per_sec para vê-los traçados juntos:
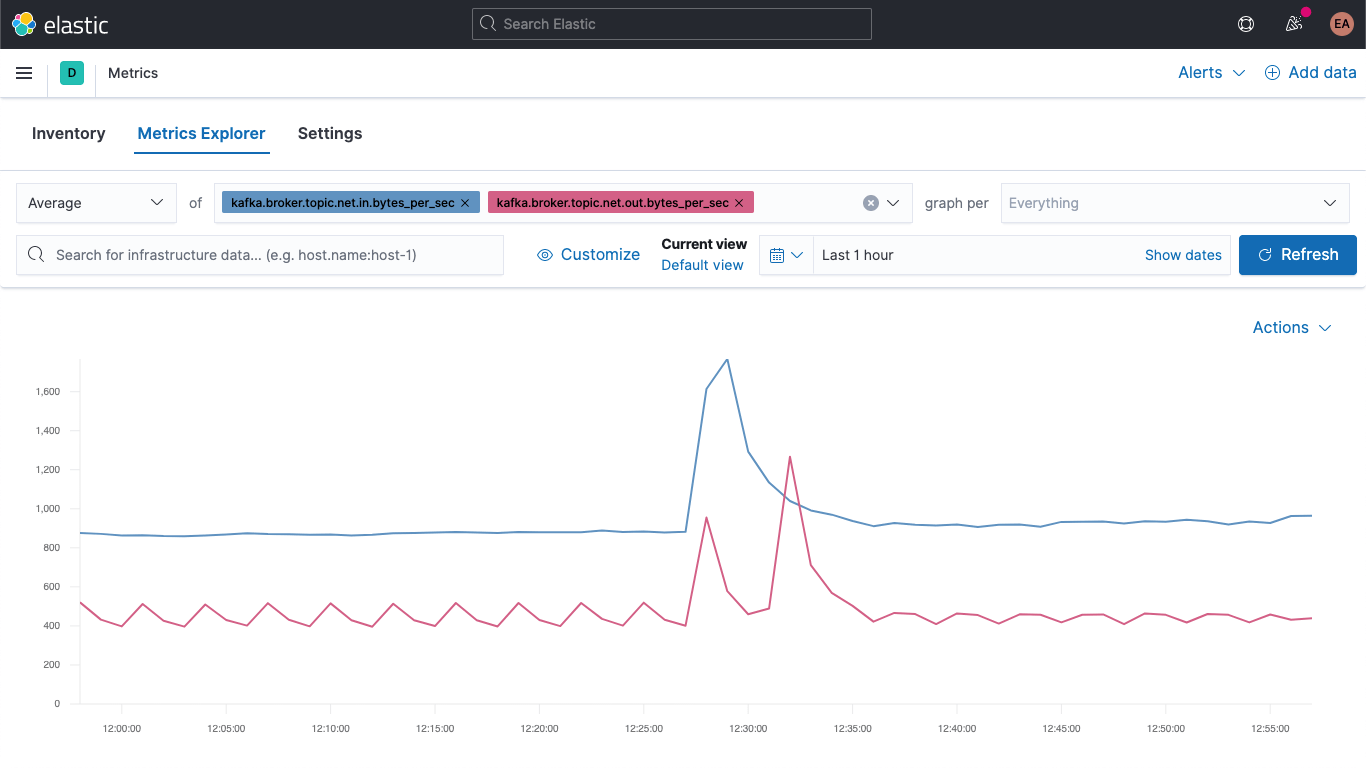
E agora, utilizando um de nossos novos campos, abra o menu suspenso “graph per” (gráfico por) e selecione kafka_broker_topic:
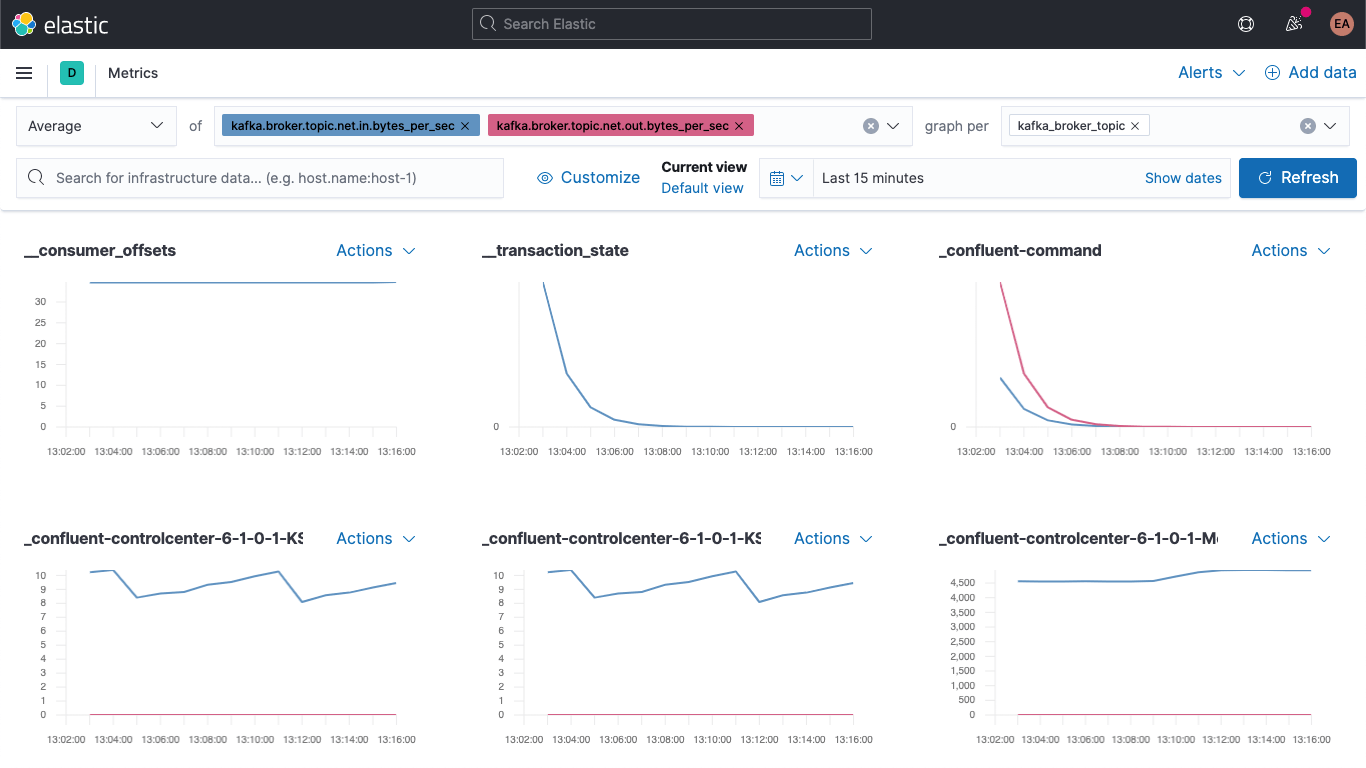
Nem tudo terá valores diferentes de zero (não há muito acontecendo no cluster no momento), mas é muito mais fácil traçar as métricas do broker e dividi-las por tópico agora. Você pode exportar qualquer um desses gráficos como visualizações e carregá-los no seu dashboard de métricas do Kafka ou criar suas próprias visualizações usando a variedade de tabelas e gráficos disponíveis no Kibana. Se preferir uma experiência de arrastar e soltar para a construção da visualização, experimente o Lens.
Um bom lugar para começar com as visualizações das métricas do broker são as falhas nos blocos de produção e busca:
kafka
└─ broker
└── request
└── channel
├── fetch
│ ├── failed
│ └── failed_per_second
├── produce
│ ├── failed
│ └── failed_per_second
└── queue
└── size
A gravidade das falhas aqui realmente depende do caso de uso. Se as falhas ocorrerem em um ecossistema onde estamos apenas recebendo atualizações intermitentes — por exemplo, preços de ações ou leituras de temperatura, onde sabemos que teremos outra atualização em breve —, algumas falhas poderão não ser tão ruins, mas se forem, digamos, em um sistema de pedidos, perder algumas mensagens poderá ser catastrófico, porque significará que alguém não vai receber sua encomenda.
Resumo
Agora podemos monitorar brokers do Kafka e o ZooKeeper usando o Elastic Observability. Também vimos como utilizar dicas para você monitorar automaticamente novas instâncias de serviços em container e aprendemos como um pipeline de ingestão pode tornar seus dados mais fáceis de visualizar. Experimente hoje mesmo com uma avaliação gratuita do Elasticsearch Service no Elastic Cloud ou baixe o Elastic Stack e execute-o localmente.
Se não estiver executando um cluster do Kafka em container, mas sim como um serviço gerenciado ou em bare metal, fique atento(a). Em um futuro próximo, daremos continuidade a este post do blog com alguns posts relacionados:
- Como monitorar um cluster do Kafka autônomo com o Metricbeat e o Filebeat
- Como monitorar um cluster do Kafka autônomo com o Elastic Agent