Visão detalhada do armazenamento em cache do Elasticsearch: como aumentar a velocidade de consulta, um cache de cada vez
O cache é fundamental para recuperarmos dados com rapidez. Portanto, se você se interessa em saber como o Elasticsearch utiliza vários caches para garantir que você recupere os dados o mais rápido possível, aperte o cinto pelos próximos 15 minutos e leia este post. Falaremos sobre vários recursos de cache do Elasticsearch que ajudam você a recuperar os dados mais rapidamente após os acessos iniciais. O Elasticsearch utiliza vários caches de forma intensiva, mas, neste post, vamos nos concentrar apenas nos seguintes:
- Cache de página (às vezes chamado de cache do sistema de arquivos)
- Cache de solicitação no nível do shard
- Cache de consulta
Você aprenderá o que cada um desses caches faz, como funciona e qual cache é melhor para cada caso de uso. Também exploraremos como às vezes você pode controlar o cache e às vezes precisa confiar em outro componente para fazer um bom trabalho de cache.
Veremos ainda como os caches de página lidam com a expiração de dados. Uma coisa que você nunca quer encontrar é um cache que retorna dados obsoletos. Um cache precisa estar vinculado ao ciclo de vida dos seus dados, e veremos como isso funciona para cada um deles.
E se você está se perguntando se este post se aplica a você, independentemente de estar executando o Elasticsearch ou usando o Elastic Cloud, você utilizará esses caches prontos para uso. OK, vamos lá.
Cache de página
O primeiro cache existe no nível do sistema operacional. Embora esta seção seja principalmente sobre a implementação do Linux, outros sistemas operacionais têm um recurso semelhante.
A ideia básica do cache de página é colocar os dados na memória disponível após a leitura do disco, de forma que a próxima leitura seja retornada da memória e a obtenção dos dados não exija uma busca no disco. Tudo isso é completamente transparente para a aplicação, que está emitindo as mesmas chamadas do sistema, mas o sistema operacional tem a capacidade de usar o cache de página em vez de ler do disco.
Vamos dar uma olhada neste diagrama, onde a aplicação está executando uma chamada do sistema para ler dados do disco, e o kernel/sistema operacional acessaria o disco para fazer a primeira leitura e colocaria os dados no cache de página na memória. Então, uma segunda leitura poderia ser redirecionada pelo kernel para o cache de página na memória do sistema operacional e, portanto, seria muito mais rápida.
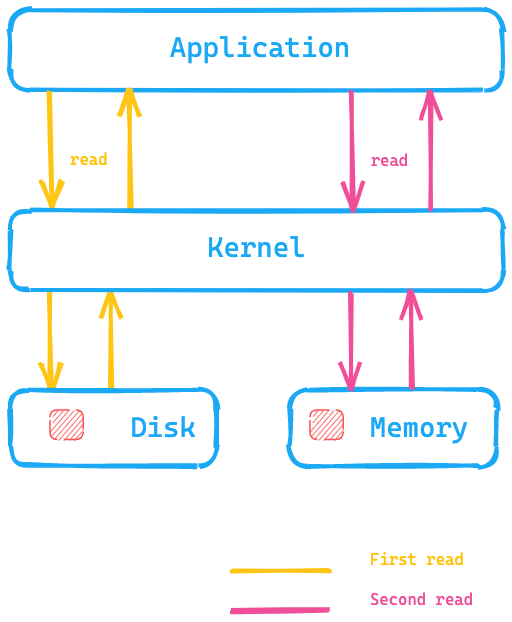
O que isso significa para o Elasticsearch? Em vez de acessar dados no disco, o cache de página pode ser muito mais rápido para acessar os dados. Esse é um dos motivos pelos quais a recomendação para a memória do Elasticsearch geralmente não é mais do que a metade da sua memória total disponível, para que a outra metade possa ser usada para o cache de página. Isso também significa que nenhuma memória é desperdiçada; em vez disso, é reutilizada para o cache de página.
Como os dados expiram fora do cache? Se os próprios dados forem alterados, o cache de página marcará esses dados como sujos, e eles serão liberados do cache de página. Como os segmentos com o Elasticsearch e o Lucene são gravados apenas uma vez, esse mecanismo se ajusta muito bem à maneira como os dados são armazenados. Os segmentos são somente leitura após a gravação inicial, portanto, uma alteração de dados pode ser uma fusão ou adição de novos dados. Nesse caso, é necessário um novo acesso ao disco. A outra possibilidade é a memória ficar cheia. Nesse caso, o cache se comportará de maneira semelhante a um LRU, conforme declarado pela documentação do kernel.
Testar o cache de página
Se você quer conferir a funcionalidade do cache de página, podemos usar o hyperfine para isso. O hyperfine é uma ferramenta de benchmark de CLI. Vamos criar um arquivo com 10 MB via dd
dd if=/dev/urandom of=test1 bs=1M count=10
Se quiser executar o comando acima usando o macOS, convém usar o gdd em vez do dd
e se certificar de que o coreutils seja instalado via brew.
# para Linux hyperfine --warmup 5 'cat test1 > /dev/null' \ --prepare 'sudo sync; sudo echo 3 > /proc/sys/vm/drop_caches'
# para osx hyperfine --warmup 5 'cat test1 > /dev/null' --prepare 'sudo purge' Benchmark #1: cat test1 > /dev/null Time (mean ± σ): 38.1 ms ± 6.4 ms [User: 1.4 ms, System: 17.5 ms] Range (min … max): 30.4 ms … 50.5 ms 10 runs hyperfine --warmup 5 'cat test1 > /dev/null' Benchmark #1: cat test1 > /dev/null Time (mean ± σ): 3.8 ms ± 0.6 ms [User: 0.7 ms, System: 2.8 ms] Range (min … max): 2.9 ms … 7.0 ms 418 runs
Portanto, na minha instância local do macOS, a execução do mesmo comando cat sem limpar o cache de página é cerca de 10 vezes mais rápida, pois é possível pular o acesso ao disco. Com certeza, esse é um tipo de padrão de acesso que você vai querer para os dados do Elasticsearch!
Uma análise mais a fundo
A classe responsável pela leitura de um índice do Lucene é a classe HybridDirectory. Com base na extensão dos arquivos em um índice do Lucene, toma-se a decisão de usar mapeamento de memória ou acesso regular aos arquivos usando Java NIO.
Observe também que algumas aplicações reconhecem mais seus próprios padrões de acesso e vêm com seus próprios caches muito específicos e otimizados, e o cache de página provavelmente funcionaria contra isso. Se necessário, qualquer aplicação pode ignorar o cache de página usando O_DIRECT ao abrir um arquivo. Voltaremos a isso no final deste post.
Se quiser verificar a taxa de acertos do cache, você pode usar o cachestat, que faz parte das perf-tools.
Uma última coisa sobre o Elasticsearch aqui. Você pode configurar o Elasticsearch para pré-carregar dados no cache de página por meio das configurações do índice. Considere esta uma configuração de especialista e tenha cuidado com ela para garantir que o cache de página não seja afetado de forma constante.
Resumo
O cache de página ajuda a executar buscas arbitrárias com mais rapidez, carregando estruturas de dados de índice completas na memória principal do sistema operacional. Não há mais granularidade, e ele se baseia exclusivamente no padrão de acesso dos seus dados. O sistema operacional cuida do despejo.
Vamos para o próximo nível dos caches.
Cache de solicitação no nível do shard
Esse cache ajuda muito a acelerar o Kibana, armazenando as respostas da busca que consistem apenas em agregações. Vamos sobrepor a resposta de uma agregação com os dados obtidos de diversos índices para visualizar o problema que é resolvido com esse cache.
Um dashboard do Kibana no seu escritório geralmente exibe dados de diversos índices, e você simplesmente especifica um intervalo de tempo como os últimos 7 dias. Você não se importa com a quantidade de índices ou shards que são consultados. Portanto, se estiver usando fluxos de dados para seus índices baseados em tempo, você poderá acabar tendo uma visualização como esta cobrindo cinco índices.
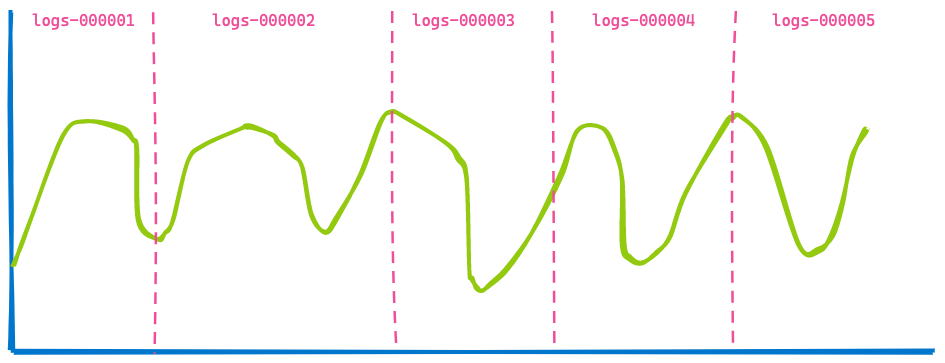
Agora, vamos avançar três horas no futuro, exibindo o mesmo dashboard:
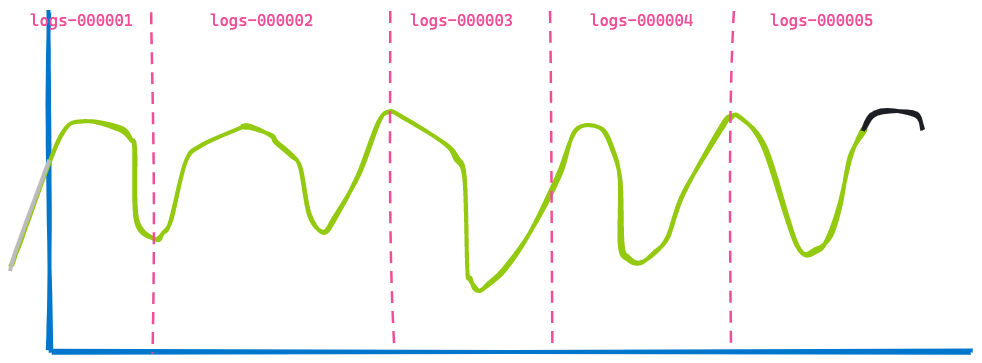
A segunda visualização é muito semelhante à primeira: alguns dados não são mais mostrados porque envelheceram (à esquerda da linha azul), e mais alguns dados foram adicionados no final, mostrados na linha preta. Você consegue identificar o que não mudou? Os dados retornados dos índices logs-000002, logs-000003 e logs-000004.
Mesmo que esses dados estivessem no cache de página, ainda precisaríamos executar a busca e a agregação sobre os resultados. Portanto, não há necessidade de fazer esse trabalho duplo. Para fazer isso funcionar, mais uma otimização foi adicionada ao Elasticsearch: a capacidade de regravar uma consulta. Em vez de especificar um intervalo de registro de data/hora para os índices dos logs logs-000002, logs-000003 e logs-000004, podemos regravar isso em um match_all query internamente, já que cada documento dentro desse índice corresponde ao registro de data/hora (outros filtros ainda se aplicariam, é claro). Usando essa regravação, ambas as solicitações agora terminam como exatamente a mesma solicitação nesses três índices e, portanto, podem ser armazenadas em cache.
Esse se tornou o cache de solicitação no nível de shard. A ideia é armazenar em cache a resposta completa de uma solicitação para que você não precise executar nenhuma busca e possa, basicamente, retornar a resposta de forma instantânea — desde que os dados não tenham mudado para garantir que você não retorne dados obsoletos!
Uma análise mais a fundo
O componente responsável pelo armazenamento em cache é a classe IndicesRequestCache. Esse método é usado no SearchService ao executar a fase de consulta. Há também uma verificação adicional se uma consulta é elegível para armazenamento em cache — por exemplo, consultas cujo perfil está sendo criado nunca são armazenadas em cache para evitar distorção dos resultados.
Esse cache é habilitado por padrão, pode ocupar até 1% do heap total e pode até ser configurado por solicitação se necessário. Por padrão, esse cache está habilitado para solicitações de busca que não retornam nenhum resultado — exatamente aquilo que é uma solicitação de visualização do Kibana! No entanto, você também pode usar esse cache quando acertos são retornados, habilitando-o por meio de um parâmetro de solicitação.
Você pode recuperar estatísticas sobre o uso desse cache via:
GET /_nodes/stats/indices/request_cache?human
Resumo
O cache de solicitação no nível de shard lembra a resposta completa a uma solicitação de busca e a retornará se a mesma consulta vier novamente sem acessar o disco ou o cache de página. Como o próprio nome indica, essa estrutura de dados está vinculada ao shard que contém os dados e também nunca retornará dados obsoletos.
Cache de consulta
O cache de consulta é o último cache que veremos neste post. Novamente, a maneira como esse cache funciona é bastante diferente dos outros caches. O cache de página armazena dados independentemente de quanto desses dados são realmente lidos em uma consulta. O cache de solicitação no nível de shard armazena dados quando uma consulta semelhante é usada. O cache de consulta é ainda mais granular e pode armazenar dados que são reutilizados entre diferentes consultas.
Vejamos como isso funciona. Vamos imaginar que estejamos fazendo uma busca em logs. Três usuários diferentes podem estar navegando nos dados deste mês. No entanto, cada usuário usa um termo de busca diferente:
- O usuário 1 buscou por “falha”
- O usuário 2 buscou por “Exceção”
- O usuário 3 buscou por “pcre2_get_error_message”
Cada busca retorna resultados diferentes e, ainda assim, eles estão dentro do mesmo intervalo de tempo. É aqui que entra o cache de consulta: ele é capaz de armazenar apenas aquela parte de uma consulta. A ideia básica é armazenar informações em cache em vez de acessar o disco e executar a busca apenas nos documentos que já estão no cache. Sua consulta provavelmente é parecida com esta:
GET logs-*/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"message": "pcre2_get_error_message"
}
}
],
"filter": [
{
"range": {
"@timestamp": {
"gte": "2021-02-01",
"lt": "2021-03-01"
}
}
}
]
}
}
}
Para cada consulta, a parte filter permanece igual. Essa é uma visão altamente simplificada de como ficam os dados em um índice invertido. Cada registro de data/hora é mapeado para um ID de documento.
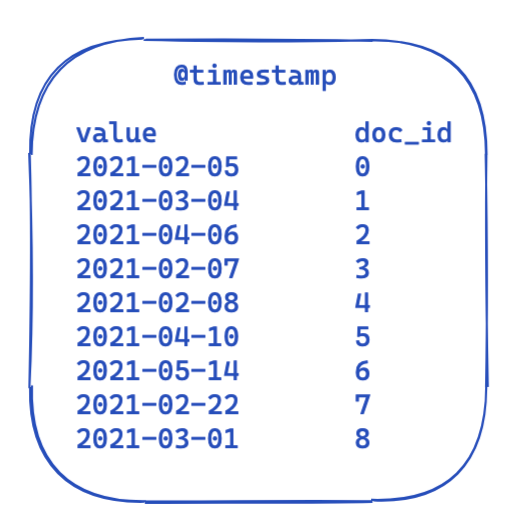
Então, como isso pode ser otimizado e reutilizado nas consultas? É aqui que os conjuntos de bits (também chamados de matrizes de bits) entram em ação. Um conjunto de bits é basicamente uma matriz na qual cada bit representa um documento. Podemos criar um conjunto de bits dedicado para este filtro @timestamp específico cobrindo um único mês. Um 0 significa que o documento está fora desse intervalo, enquanto um 1 significa que está dentro. O conjunto de bits resultante ficaria assim:
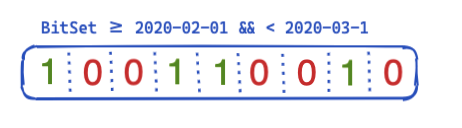
Depois de criar este conjunto de bits por segmento (o que significa que ele precisa ser recriado após uma mesclagem ou sempre que um novo segmento é criado), a próxima consulta não precisa fazer nenhum acesso ao disco para excluir cinco documentos antes mesmo de executar o filtro. Os conjuntos de bits têm algumas propriedades interessantes. Primeiro, eles podem ser combinados. Se você tiver dois filtros e dois conjuntos de bits, poderá facilmente descobrir os documentos nos quais ambos os bits estão definidos — ou mesclar uma consulta OR. Outro aspecto interessante dos conjuntos de bits é a compressão. Você precisa de um bit por documento por filtro por padrão. No entanto, ao usar não conjuntos de bits fixos, mas outra implementação como roaring bitmaps, você pode reduzir os requisitos de memória.
Então, como isso é implementado no Elasticsearch e no Lucene? Vamos ver!
Uma análise mais a fundo
O Elasticsearch apresenta uma classe IndicesQueryCache. Essa classe está vinculada ao ciclo de vida do IndicesService, o que significa que não é um recurso por índice, mas por nó — o que faz sentido, já que o próprio cache usa o heap Java. Esse cache de consulta de índices ocupa duas opções de configuração:
indices.queries.cache.count: o número total de entradas do cache; o padrão é 10.000indices.queries.cache.size: a porcentagem do heap Java usada para esse cache; o padrão é 10%
No construtor IndicesQueryCache, um novo ElasticsearchLRUQueryCache é configurado. Esse cache estende-se da classe LRUQueryCache do Lucene. Essa classe tem o seguinte construtor:
public LRUQueryCache(int maxSize, long maxRamBytesUsed) {
this(maxSize, maxRamBytesUsed, new MinSegmentSizePredicate(10000, .03f), 250);
}
O MinSegmentSizePredicate garante que apenas segmentos com pelo menos 10 mil documentos sejam elegíveis para armazenamento em cache e tenham mais de 3% do total de documentos desse shard.
No entanto, as coisas são um pouco mais complexas a partir daqui. Mesmo que os dados estejam no heap da JVM, há outro mecanismo que rastreia as partes mais comuns da consulta e coloca apenas essas no cache. Esse rastreamento, no entanto, ocorre no nível do shard. Há uma classe UsageTrackingQueryCachingPolicy que usa um FrequencyTrackingRingBuffer (implementado usando matrizes de inteiros de tamanho fixo). Essa política de armazenamento em cache também tem regras adicionais em seu método shouldNeverCache, que impede o armazenamento de certas consultas como consultas de termos, consultas de correspondência com todos/nenhum documento ou consultas vazias, pois estas são rápidas o suficiente sem o armazenamento em cache. Também há uma condição para a frequência mínima a ser elegível para armazenamento em cache, de forma que uma única invocação não resulte no preenchimento do cache. Você pode rastrear o uso, as taxas de acerto do cache e outras informações via:
GET /_nodes/stats/indices/query_cache?human
Resumo
O cache de consulta chega ao próximo nível granular e pode ser reutilizado em todas as consultas! Com sua heurística integrada, ele apenas armazena os filtros que são usados várias vezes e também decide com base no filtro se ele vale a pena ser armazenado ou se as formas existentes de consulta são rápidas o suficiente para evitar o desperdício de memória heap. O ciclo de vida desses conjuntos de bits está vinculado ao ciclo de vida de um segmento para evitar o retorno de dados obsoletos. Uma vez que um novo segmento esteja em uso, um novo conjunto de bits precisará ser criado.
Os caches são a única possibilidade de acelerar as coisas?
Depende (você já tinha adivinhado que essa resposta tinha de aparecer neste post em algum momento, certo?). Um desenvolvimento recente no kernel do Linux é bastante promissor: io_uring. Esta é uma nova maneira de fazer E/S assíncronas no Linux usando filas de conclusão disponíveis desde o Linux 5.1. Observe que o io_uring ainda está em franco desenvolvimento. No entanto, existem as primeiras tentativas no mundo Java para usar o io_uring como netty. Os testes de desempenho para aplicações simples parecem impressionantes. Acho que teremos de esperar um pouco até vermos os números de desempenho do mundo real, embora eu tenha a expectativa de que eles também terão mudanças significativas. Vamos esperar que o suporte para isso em algum momento também esteja disponível no JDK. Existem planos para dar suporte ao io_uring como parte do Project Loom, o que pode trazer o io_uring para a JVM. Mais otimizações, como ser capaz de dar a dica do padrão de acesso para o kernel do Linux por meio de madvise (), também ainda não foram expostas na JVM. Essa dica evita um problema de leitura antecipada, no qual o kernel tenta ler mais dados do que o necessário em antecipação à próxima leitura, o que é inútil quando o acesso aleatório é necessário.
Isso não é tudo! Os desenvolvedores do Lucene estão trabalhando como sempre para obter o máximo de qualquer sistema. Há um primeiro rascunho de uma regravação do Lucene MMapDirectory usando a API de memória externa, que pode se tornar uma prévia de um recurso no Java 16. No entanto, isso não foi feito por motivos de desempenho, mas para superar certas limitações com a implementação atual do MMap.
Outra mudança recente no Lucene foi a eliminação das extensões nativas usando E/S diretas (O_DIRECT) na classe FileChannel. Isso significa que a gravação de dados não afetará o cache da página — esse será um recurso do Lucene 9.
Às vezes, você também pode acelerar as coisas de forma a provavelmente nem ter mais de pensar em um cache, reduzindo a sua complexidade operacional. Recentemente, a aceleração das agregações date_histogram se tornou muitas vezes melhor. Reserve um tempo para ler aquele longo, mas esclarecedor post do blog.
Outro exemplo muito bom de uma tremenda melhoria (sem cache) foi a implementação do block-max WAND no Elasticsearch 7.0. Você pode ler tudo sobre isso neste post do blog de Adrien Grand.
Conclusão da visão detalhada do armazenamento em cache
Espero que você tenha gostado desse passeio pelos vários caches e agora tenha uma ideia de quando e qual cache será ativado. Além disso, lembre-se de que monitorar seus caches pode ser especialmente útil para descobrir se um cache faz sentido ou se continua sendo afetado devido a adição e expiração constantes. Depois de habilitar o monitoramento do seu cluster da Elastic, você poderá ver o consumo de memória do cache de consulta e do cache de solicitação na aba Advanced (Avançado) de um nó, bem como em cada índice individualmente se você observar um determinado índice:
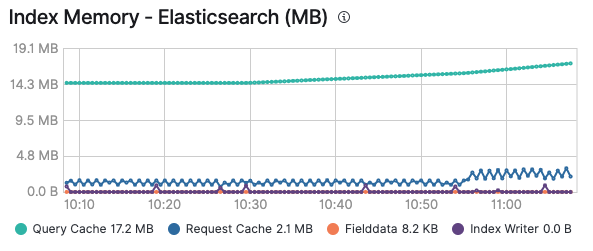
Todas as soluções existentes baseadas no Elastic Stack farão uso desses caches para garantir a execução de consultas e a entrega dos dados o mais rápido possível. Lembre-se de que você pode habilitar o logging e o monitoramento no Elastic Cloud com um único clique e ter todos os seus clusters monitorados sem custo adicional. Experimente!
Recursos adicionais sobre cache
- Page cache (Wikipedia) (Cache de página)
- Introduction to page cache (post do blog) (Introdução ao cache de página)
- Why mmap is faster than system calls (post do blog) (Por que o mmap é mais rápido do que as chamadas do sistema)
- Ferramentas de cache de página: vmtouch e pcstat