Como criar índices congelados com a API Freeze Index do Elasticsearch
Primeiro, vamos ao contexto
As arquiteturas Hot-Warm são usadas frequentemente quando queremos aproveitar ao máximo o hardware. Isso é especialmente útil quando os dados são baseados em tempo, como dados de registros, de métricas e do APM. A maioria dessas configurações se baseiam no fato de que esses dados são somente leitura (após a ingestão) e que os índices podem ter base no tempo ou no tamanho. Dessa forma, eles podem ser excluídos com facilidade considerando o período de retenção desejado. Nessa arquitetura, categorizamos os nós do Elasticsearch em dois tipos: “hot” e “warm”.
Os nós hot contêm os dados mais recentes e por isso lidam com toda a carga de indexação. Já que os dados mais recentes são os mais consultados, esses nós serão os mais poderosos de nosso cluster: armazenamento rápido, memória e CPU altas. Mas essa capacidade extra acaba ficando cara, então, não faz sentido armazenar dados mais antigos que não vão ser consultados com tanta frequência quanto os de um nó hot.
Por outro lado, os nós warm serão aqueles dedicados ao armazenamento de longo prazo com um custo-benefício melhor. A probabilidade de os dados dos nós warm serem consultados é pequena, então, os dados contidos no cluster transitarão entre os nós hot e warm tendo como base a retenção que planejarmos (com a filtragem de alocação de fragmentos), mantendo-se ainda disponíveis online para as consultas.
Desde a versão Elastic Stack 6.3, temos criado novos recursos para aprimorar as arquiteturas hot-warm e assim simplificar o trabalho com dados baseados em tempo.
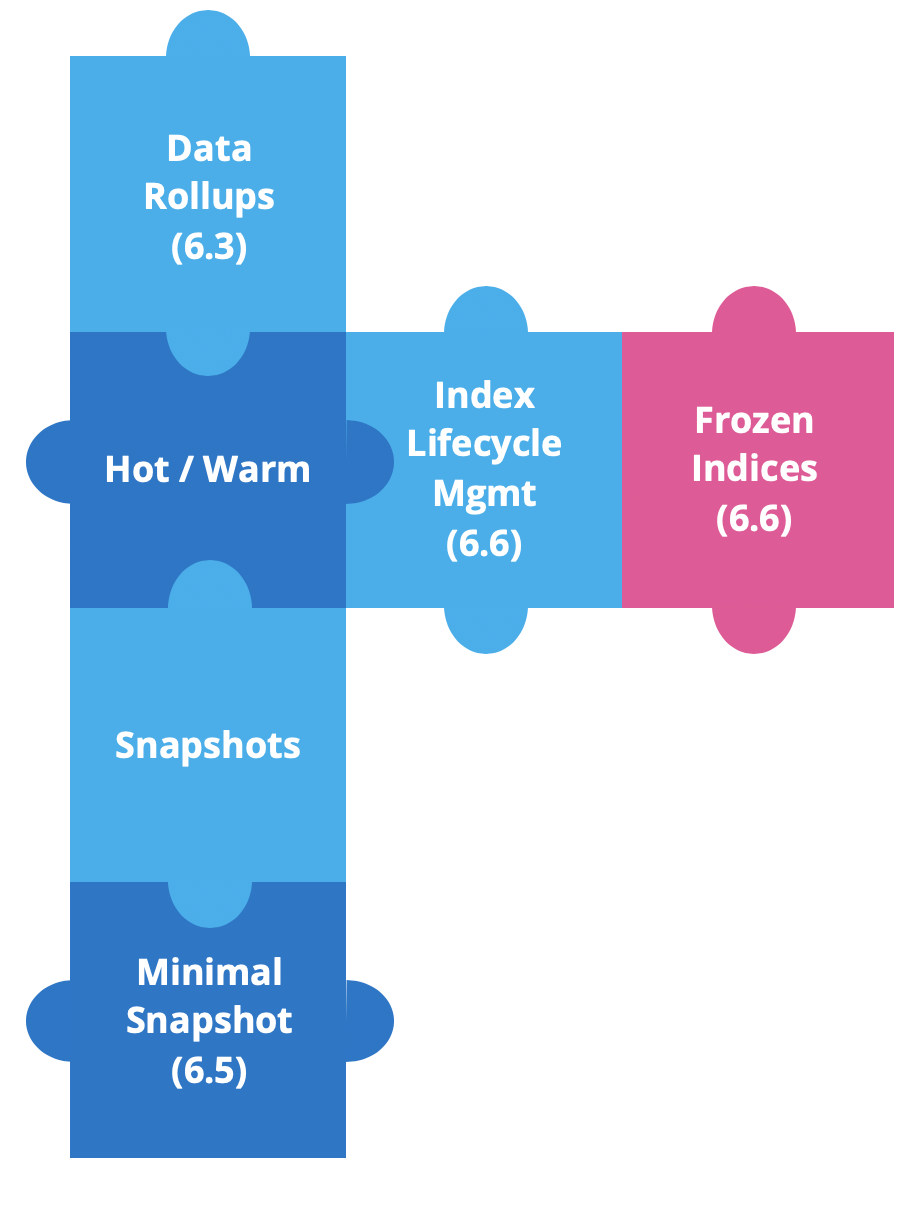
Os rollups de dados foram introduzidos na versão 6.3 para economizar espaço de armazenamento. Nos dados em séries de tempo, queremos detalhes em granularidade fina para os mais recentes. Mas é muito improvável que seja necessário o mesmo para dados históricos; nesse caso geralmente consideramos conjuntos de dados como um todo. É aí que entraram os rollups desde a versão 6.5, para nos permitir criar, gerenciar e visualizar os dados de rollup na Kibana.
Logo depois, introduzimos os snapshots somente na fonte. Esses snapshots mínimos oferecerão uma redução significativa do armazenamento de snapshots, mas em compensação os dados precisarão ser reindexados se desejarmos realizar as ações de restauração e consulta. Esse recurso está disponível desde a versão 6.5.
Na versão 6.6, lançamos dois recursos poderosos: o Index Lifecycle Management (ILM) e os índices congelados.
O ILM fornece meios de automatizar o gerenciamento dos índices ao longo do tempo. Ele simplifica a mudança de índices de hot para warm, permite a exclusão de índices muito antigos ou automatiza a mesclagem forçada de índices em um único segmento.
A partir desde ponto, falaremos sobre índices congelados.
Para que congelar um índice?
Um dos maiores aborrecimentos que temos com os dados antigos é que, independentemente de seu tempo de existência, os índices ainda consomem uma memória significativa. Mesmo que os coloquemos em nós do tipo cold, ainda assim eles vão usar heap.
Uma solução possível para isso seria fechar o índice. O fechamento de um índice não requer memória, mas caso precisemos realizar uma pesquisa, ele terá que ser reaberto. A reabertura de índices envolvem custos operacionais e também exige o uso do heap que o índice usava quando foi fechado.
Em cada nó, há uma memória (heap) para armazenar a taxa que limitará a quantidade de armazenamento disponível por nó. Essa taxa pode variar entre o mínimo de 1:8 (memória:dados) em cenários de uso intenso de memória e algo em torno de 1:100 para casos de uso com demanda menor de memória.
E é aí que os índices congelados entram. E se pudéssemos ter índices que ainda permanecessem abertos, mantendo-se pesquisáveis, mas que não ocupassem o heap? Poderíamos adicionar mais armazenamento aos nós de dados que abrigassem os índices congelados e quebrar a taxa de 1:100, tendo em mente que em compensação as pesquisas se tornariam provavelmente mais lentas.
Quando congelamos um índice, ele se torna somente leitura e suas estruturas de dados transitórios são retiradas da memória. Por outro lado, quando executamos uma consulta em índices congelados, precisamos carregar as estruturas de dados na memória. Pesquisar um índice congelado não precisa ser um procedimento lento. O Lucene depende maciçamente do cache do sistema de arquivos, que com certeza tem capacidade suficiente para reter porções significativas do seu índice na memória. Nesse caso, as pesquisas são comparáveis em velocidade por fragmento. Ainda assim, um índice congelado é limitado de maneira que um único fragmento congelado é executado por nó simultaneamente. Esse aspecto possivelmente retardará as pesquisas, se compararmos com os índices descongelados.
Como o congelamento funciona
Os índices congelados são pesquisados por meio de um threadpool dedicado e limitado para pesquisas. Por padrão, ele usa uma única thread para garantir que os índices congelados sejam carregados um de cada vez na memória. Se pesquisas simultâneas estiverem acontecendo, elas ficarão na fila para obter proteções adicionais e assim evitar que os nós fiquem sem memória.
Então, na arquitetura hot-warm, agora poderemos mover os índices de hot para warm e então congelá-los antes de arquivá-los ou excluí-los, o que nos permitirá reduzir os requisitos de hardware.
Antes dos índices congelados, tínhamos que realizar um snapshot e arquivar os dados para reduzir o custo de infraestrutura, mas isso por outro lado agregava um custo operacional significativo. Se precisássemos fazer uma nova pesquisa, teríamos que restaurar os dados. Agora, podemos manter nossos dados históricos disponíveis para pesquisa sem sobrecarga significativa na memória. Além disso, se precisarmos fazer alguma gravação novamente em um índice já congelado, bastará descongelá-lo.

Como congelar um índice do Elasticsearch
Os índices congelados são fáceis de implementar no seu cluster, então agora vamos aprender a usar a API Freeze index e a pesquisar nos índices congelados.
Primeiro, vamos criar alguns dados de exemplo em um índice de teste.
POST /sampledata/_doc
{
"name": "Jane",
"lastname": "Doe"
}
POST /sampledata/_doc
{
"name": "John",
"lastname": "Doe"
}
Em seguida, vamos ver se nossos dados foram ingeridos. Isto deve retornar dois resultados:
GET /sampledata/_search
Recomendamos a prática de executar um force_merge antes de congelar um índice. Dessa forma, você garantirá que cada fragmento esteja ocupando apenas um segmento no disco. Isso também permitirá uma compressão muito melhor e simplificará as estruturas de dados que serão necessárias quando formos executar uma agregação ou uma solicitação de pesquisa classificada no índice congelado. As pesquisas que são executadas em um índice congelado com vários segmentos podem ter uma sobrecarga de desempenho significativa de até várias ordens de magnitude.
POST /sampledata/_forcemerge?max_num_segments=1
A próxima etapa é chamar um congelamento em nosso índice via endpoint da API Freeze index.
POST /sampledata/_freeze
Como pesquisar índices congelados
Agora, com o índice congelado, você verá que pesquisas comuns não funcionarão. A razão disso é que, para limitar o consumo de memória por nó, os índices congelados são limitados. Já que podemos direcionar um índice congelado por engano, vamos evitar lentidões acidentais adicionando especificamente ignore_throttled=false à solicitação.
GET /sampledata/_search?ignore_throttled=false
{
"query": {
"match": {
"name": "jane"
}
}
}
Agora podemos verificar o status de nosso novo índice executando a seguinte solicitação:
GET _cat/indices/sampledata?v&h=health,status,index,pri,rep,docs.count,store.size
O resultado que obteremos será semelhante ao seguinte, com o status do índice sendo "open":
health status index pri rep docs.count store.size
green open sampledata 5 1 2 17.8kb
Conforme mencionado acima, precisamos proteger o cluster de ficar sem memória, por isso, há um limite no número de índices congelados que podemos carregar simultaneamente para pesquisar em um nó. Por padrão, o número de threads no threadpool limitados para pesquisas é 1, e a fila padrão comporta 100 threads. Isso significa que se executarmos mais de uma solicitação, elas entrarão na fila, que acolherá até uma centena de solicitações. Podemos monitorar o status do threadpool, para verificar filas e rejeições, com a seguinte solicitação:
GET _cat/thread_pool/search_throttled?v&h=node_name,name,active,rejected,queue,completed&s=node_name
A resposta a ela pode ser semelhante a esta:
node_name name active rejected queue completed
instance-0000000000 search_throttled 0 0 0 25
instance-0000000001 search_throttled 0 0 0 22
instance-0000000002 search_throttled 0 0 0 0
Os índices congelados podem ser mais lentos, mas é possível filtrá-los previamente de uma maneira muito eficiente. É recomendável definir o parâmetro da solicitação pre_filter_shard_size como 1.
GET /sampledata/_search?ignore_throttled=false&pre_filter_shard_size=1
{
"query": {
"match": {
"name": "jane"
}
}
}
Isso não adicionará uma sobrecarga significativa à consulta e nos permitirá aproveitar as vantagens do cenário usual. Por exemplo, em uma pesquisa que inclui uma faixa de data em índices em séries de tempo, não haverá correspondência em todos os fragmentos.
Como gravar em um índice do Elasticsearch congelado
O que acontecerá se tentarmos gravar em um índice já congelado? Vamos descobrir.
POST /sampledata/_doc
{
"name": "Janie",
"lastname": "Doe"
}
O que aconteceu? Índices congelados têm propriedades somente leitura, então, a gravação é bloqueada. Podemos verificar isso nas configurações de índice:
GET /sampledata/_settings?flat_settings=true
Elas retornam o seguinte:
{
"sampledata" : {
"settings" : {
"index.blocks.write" : "true",
"index.frozen" : "true",
....
}
}
}
Temos que usar a API Unfreeze index, chamando o endpoint de descongelamento no índice.
POST /sampledata/_unfreeze
Agora podemos criar um terceiro documento e pesquisá-lo.
POST /sampledata/_doc
{
"name": "Janie",
"lastname": "Doe"
}
GET /sampledata/_search
{
"query": {
"match": {
"name": "janie"
}
}
}
O descongelamento deve ser feito apenas em situações excepcionais. Lembre-se de sempre executar um "force_merge" antes de congelar o índice novamente, para assegurar desempenho ideal.
Como usar índices congelados na Kibana
Primeiro, precisaremos carregar alguns dados de exemplo, como os dados de voos de amostra.
Clique no botão “Add” (Adicionar) para os dados de voos de amostra.
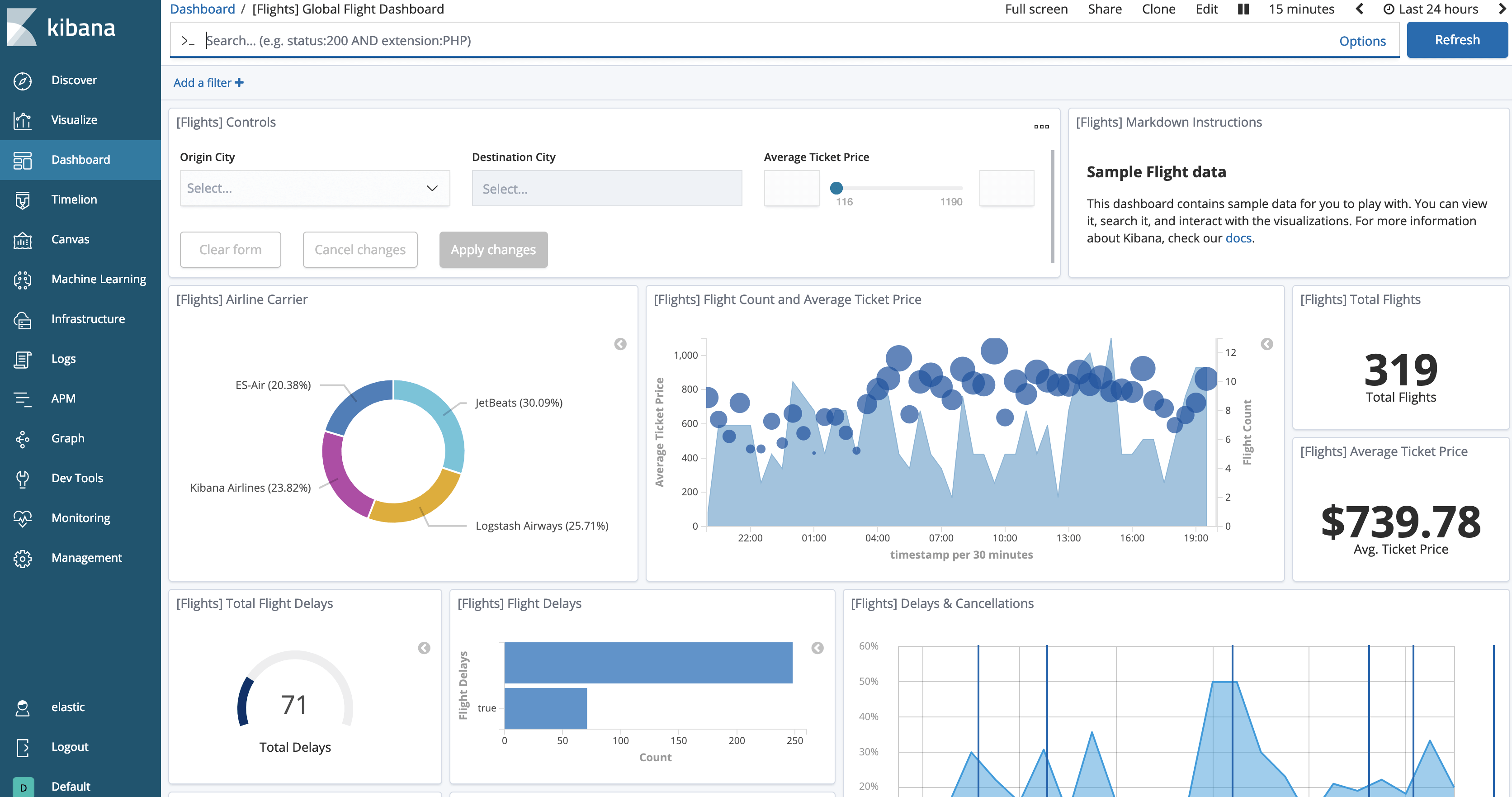
Agora, podemos ver os dados carregados clicando no botão “View data” (Ver dados). O painel ficará semelhante a este.
Agora, podemos testar o congelamento do índice:
POST /kibana_sample_data_flights/_forcemerge?max_num_segments=1
POST /kibana_sample_data_flights/_freeze
Se retornarmos ao painel, perceberemos que os dados aparentemente “desapareceram”.
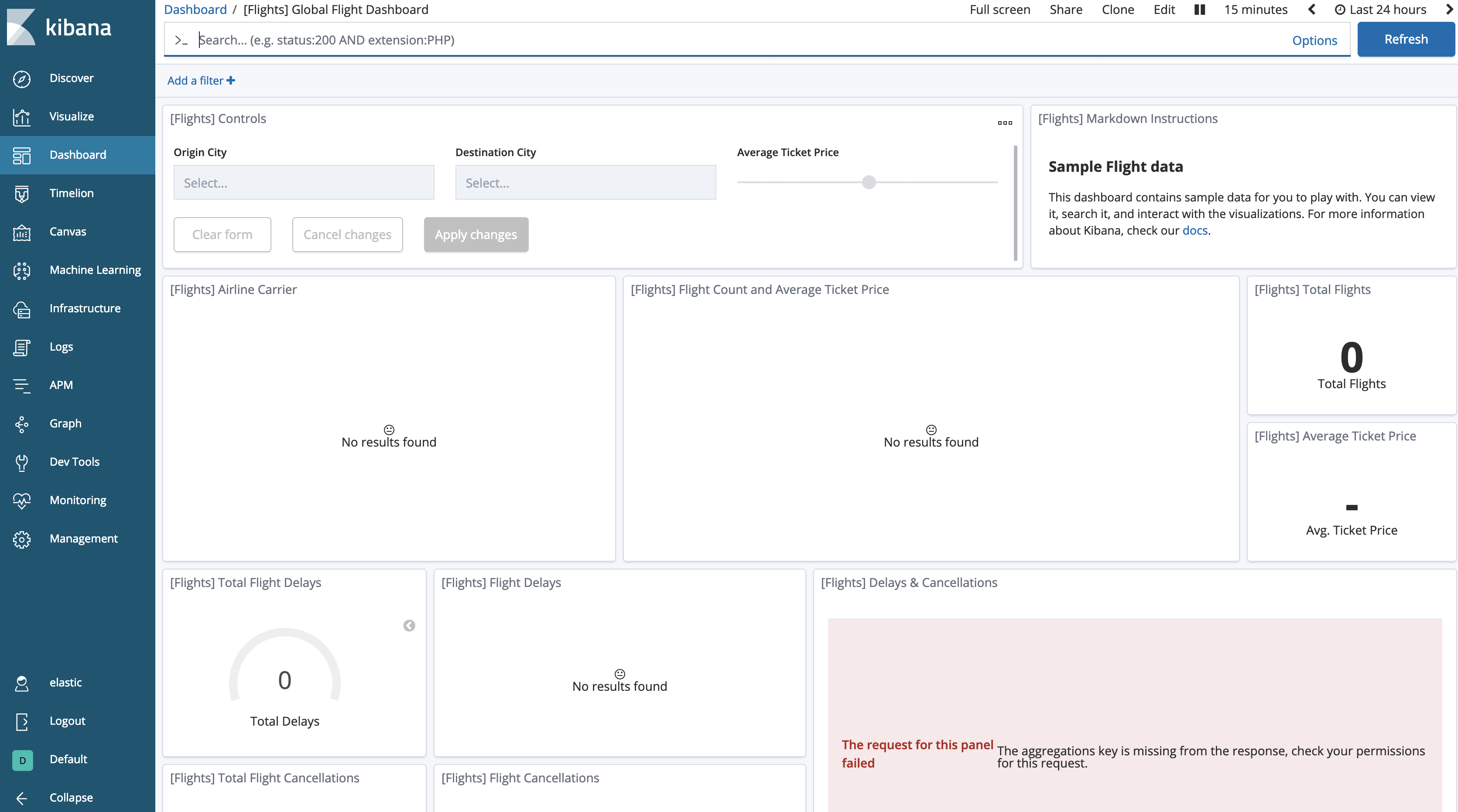
Precisamos pedir à Kibana para permitir pesquisas em índices congelados, o que é desabilitado por padrão.
Vá ao Kibana Management (Gerenciamento da Kibana) e escolha Advanced Settings (Configurações avançadas). Na seção Search (Pesquisar), você verá que a opção “Search in frozen indices” (Pesquisar em índices congelados) está desabilitada. Mude a configuração para permitir a pesquisa e, em seguida, salve as alterações.

O painel do voo mostrará os dados novamente.
Resumo
Os índices congelados são uma ferramenta muito poderosa nas arquiteturas hot-warm. Eles permitem uma solução com melhor custo-benefício e mantêm a pesquisa online. Recomendo que você teste a latência de pesquisa com seu hardware e seus dados, para que o dimensionamento correto seja conseguido, e também teste a latência de pesquisa em seus índices congelados.
Verifique a documentação do Elasticsearch para aprender mais sobre a API Freeze index. Como sempre, se você tiver dúvidas, vá a um de nossos fóruns de discussão. Bons congelamentos!