Estratégias de economia de custos para o Elasticsearch Service: eficiência no armazenamento dos dados
Milhares de clientes nem pensam duas vezes ao escolher o Elasticsearch Service (ESS) oficial no Elastic Cloud para executar não apenas o Elasticsearch, mas produtos exclusivos como Elastic Logs, Elastic APM, Elastic SIEM e muitos outros. Com mais de sete anos de experiência operacional, o ESS é o único serviço gerenciado que fornece a experiência completa do Elasticsearch com todos os recursos, todas as soluções e suporte direto da fonte, além de vários benefícios operacionais e de implantação que complementam esses produtos.
Em um post anterior, explicamos o custo oculto da rede quando se usa uma solução de SaaS que não está na mesma região que seus serviços, infraestrutura ou dispositivos de logging, o que pode resultar em taxas pesadas. Neste post, destacaremos como o Elasticsearch Service no Elastic Cloud proporciona flexibilidade para você escolher várias estratégias e manter os custos sob controle à medida que suas cargas de trabalho se expandem.
Com qualquer crescimento, principalmente nos espaços de observabilidade e segurança, a infraestrutura necessária para armazenar e analisar logs, métricas, rastreamentos de APM e eventos de segurança gerados pelas suas aplicações aumenta, implicando custos adicionais. O ESS oferece várias maneiras de ajudar você a gerenciar seus dados para controlar os custos e ainda manter dados significativos por períodos mais longos. Além disso, ele fornece os mesmos recursos úteis do Elastic Stack: consolidação de dados de várias fontes, opções de visualização, alerta, detecção de anomalia e muito mais.
Vamos analisar as oportunidades de economia de custos disponíveis para dados de séries temporais, como casos de uso de observabilidade e segurança. Para ilustrar, abordaremos uma das aplicações mais comuns para as quais se utiliza o Elastic Stack: monitoramento de infraestrutura. O Elastic Stack inclui os Beats, uma coleção de agentes lightweight que residem nos seus clientes e enviam dados para o seu cluster. O Metricbeat é amplamente usado pelas equipes para enviar métricas do sistema como uso da CPU, IOPS de disco ou telemetria de container para aplicações em execução no Kubernetes.
À medida que você for expandindo o espaço ocupado pelas aplicações, suas necessidades de monitoramento exigirão mais armazenamento para abrigar as métricas geradas. A definição de um período de retenção é uma estratégia que as equipes usam atualmente para gerenciar dados de séries temporais em escala. Vamos explorar opções adicionais de eficiência de armazenamento que estão disponíveis imediatamente com o ESS hoje.
Cenário
Para fins de continuidade, vamos analisar de forma mais detalhada as estratégias de economia de custos para um cluster que monitora 1.000 hosts onde cada agente coleta 100 bytes por métrica e 100 métricas a cada 10 segundos, com um período de retenção de dados de 30 dias. Também armazenaremos uma réplica dos dados no cluster para alta disponibilidade, o que evita a perda de dados em caso de falha no nó. Vamos fazer as contas para calcular de quanto armazenamento precisaremos:
|
|
Isso define nossos requisitos de armazenamento como 5,2 TB para armazenar essas métricas. Por uma questão de simplicidade, ignoraremos o armazenamento que o cluster do Elasticsearch exige para operação.
Para resumir:
| Hosts monitorados | 1.000 |
| GB diários ingeridos | 86,4 GB |
| Período de retenção | 30 dias |
| Número de réplicas | 1 |
| Requisitos de armazenamento (incluindo réplicas) | 5,184 TB |
Armazenamento mais eficiente com implantações hot-warm e gestão de ciclo de vida do índice
Em casos de uso de observabilidade, como logging e métricas, a utilidade dos dados diminui com o tempo. Normalmente, as equipes utilizam dados recentes para investigar rapidamente incidentes do sistema, picos repentinos no tráfego da rede ou alertas de segurança. Conforme os dados envelhecem, são consultados com menos frequência, mas ainda residem no cluster e utilizam os mesmos recursos de computação, memória e armazenamento que o restante do cluster. Isso resulta em dois padrões muito distintos de acesso aos dados, mas o cluster é otimizado apenas para ingestão rápida e consultas frequentes, não para armazenamento de dados acessados com pouca frequência.
É aí que vemos a importância das arquiteturas hot-warm no Elasticsearch Service. Essa opção de implantação fornece dois perfis de hardware no mesmo cluster do Elasticsearch. Os nós hot lidam com todos os dados novos recebidos e têm armazenamento mais rápido para garantir que possam ingerir e recuperar dados rapidamente. Os nós warm apresentam densidade de armazenamento mais alta e também um custo-benefício melhor no armazenamento de dados por períodos de retenção mais longos.
No Elasticsearch Service, normalmente provisionamos SSDs NVMe conectados localmente na proporção de 1:30 de RAM para disco para nós hot e discos rígidos altamente densos a 1:160 para nós warm. Essa poderosa arquitetura se combina com outro recurso importante: a gestão de ciclo de vida do índice (ILM). O ILM fornece os meios para automatizar o gerenciamento de índices ao longo do tempo, o que simplifica a transferência dos dados de nós hot para nós warm com base em determinados critérios como tamanho do índice, número de documentos ou tempo de existência do índice.
Com esses dois recursos trabalhando juntos, você obtém dois perfis de hardware distintos no cluster — e as ferramentas de automação de índice para mover os dados entre as camadas.
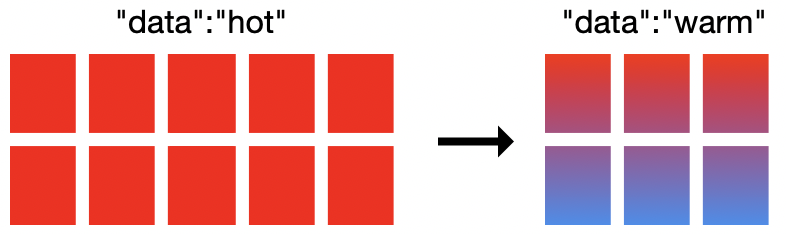
Agora vamos migrar para uma implantação hot-warm e configurar políticas de ILM. No ESS, você pode criar uma nova implantação hot-warm e, opcionalmente, restaurar um snapshot de outro cluster. Se você já tem uma implantação de E/S alta, basta migrar para uma implantação hot-warm adicionando nós warm ao seu cluster. Usando uma política de ILM, manteremos os dados na camada hot por sete dias e depois os moveremos para nossos nós warm.
Quando os dados passam para a fase warm, não é mais possível gravar nos índices. Isso nos dá outra oportunidade de economizar em custos, pois podemos optar por não armazenar nenhum dado de réplica nos nossos nós warm. Em caso de falha em um nó warm, faríamos a restauração a partir do último snapshot gerado, e não a partir de réplicas.
A desvantagem dessa abordagem é que a restauração a partir de um snapshot geralmente é mais lenta e pode aumentar o tempo de resolução após falha. No entanto, em muitos casos, isso pode ser aceitável, pois os nós warm normalmente contêm dados consultados com menos frequência, reduzindo o impacto no mundo real.
Por fim, excluiremos os dados assim que atingirem 30 dias de existência para alinhamento com a nossa política de retenção original. Usando um cálculo semelhante ao que fizemos acima, aqui está um resumo dessa abordagem:
| Cluster tradicional | Hot-warm + ILM | |
| Hosts monitorados | 1.000 | 1.000 |
| GB diários ingeridos | 86,4 GB | 86,4 GB |
| Período de retenção | 30 dias |
Hot: 7 dias
Warm: 30 dias |
| Réplicas necessárias | 1 |
Nós hot: 1
Nós warm: 0 |
| Requisitos de armazenamento | 5,184 TB |
Hot: 1,2096 TB (com réplicas)
Warm: 1,9872 TB (sem réplicas) |
| Tamanho aproximado do cluster necessário | 232 GB de RAM (armazenamento SSD de 6,8 TB) |
Hot: 58 GB de RAM com SSD
Warm: 15 GB de RAM com discos rígidos |
| Custo mensal do cluster | US$ 3.772,01 | US$ 1.491,05 |
Essa abordagem gera uma expressiva economia de 60% nos custos mensais, mantendo a capacidade de busca e a resiliência dos dados. Você pode fazer ajustes finos nas políticas de ILM para encontrar os períodos de rollover ideais a fim de ajudar a maximizar o uso do armazenamento em nós warm.
Libere mais espaço de armazenamento com rollups de dados
Outra opção de economia de armazenamento a considerar são os rollups de dados. Ao fazer o rollup dos dados em um único documento de resumo no Elasticsearch, as APIs de rollup possibilitam resumir os dados e armazená-los de forma mais compacta. Então, você pode arquivar ou excluir os dados originais para ganhar espaço de armazenamento.
Ao criar um rollup, você escolhe todos os campos de seu interesse para análises futuras, e um novo índice é criado apenas com esses dados de rollup. Isso é especialmente útil para monitorar casos de uso que lidam principalmente com dados numéricos que podem ser facilmente resumidos em uma granularidade mais alta, como ao nível de minuto, hora ou mesmo diariamente, enquanto continuam mostrando tendências ao longo do tempo. Os índices resumidos estão disponíveis em todo o Kibana e podem ser facilmente adicionados junto aos dashboards existentes para evitar interrupções em qualquer esforço de análise. Tudo isso pode ser configurado diretamente no Kibana.
Continuando com o cenário acima, lembre-se de que precisávamos de 5,2 TB de espaço de armazenamento para armazenar dados de métricas de 30 dias de 1.000 hosts, incluindo um conjunto de réplica para garantir alta disponibilidade. Em seguida, descrevemos um cenário usando um modelo de implantação hot-warm. Agora, usaremos a API de rollups de dados para configurar uma tarefa de rollup a ser executada quando os dados tiverem sete dias de existência e sacrificar um pouco de granularidade para ganhar muito mais armazenamento livre.
Vamos definir a tarefa para fazer o rollup dos nossos dados de métricas de 10 segundos em documentos resumidos por hora. Isso ainda nos permitirá consultar e visualizar nossas métricas mais antigas em intervalos de hora em hora, que podem ser usadas nas visualizações do Kibana e no Lens para revelar tendências e outros momentos importantes dos dados. Em seguida, excluiremos os documentos originais cujo rollup acabamos de fazer, liberando um grande volume de armazenamento no cluster. Se fizermos as contas, poderemos calcular quanto armazenamento é necessário para os dados cujo rollup acabamos de fazer.
|
|
Os dados originais desses documentos de rollup tinham mais de sete dias e, portanto, foram armazenados em nós warm no nosso cluster hot-warm. Todos esses 1,99 TB de dados podem ser simplesmente excluídos. A coluna à direita mostra como ficamos:
| Cluster tradicional | Hot-warm + ILM | Hot-warm + ILM com dados de rollup | |
| Hosts monitorados | 1.000 | 1.000 | 1.000 |
| GB diários ingeridos | 86,4 GB | 86,4 GB | 86,4 GB |
| Período de retenção | 30 dias |
Hot: 7 dias
Warm: 30 dias |
Hot: 7 dias
Warm: 30 dias |
| Granularidade | 10 segundos | 10 segundos |
Primeiros 7 dias: 10 segundos
Após 7 dias: 1 hora |
| Réplicas necessárias | 1 |
Nós hot: 1
Nós warm: 0 |
Nós hot: 1
Nós warm: 0 |
| Requisitos de armazenamento | 5,184 TB |
Hot: 1,2096 TB (com réplicas)
Warm: 1,9872 TB (sem réplicas) |
Hot: 1,2096 TB (com réplicas)
Warm: 5,52 GB (sem réplicas, dados de rollup) |
| Tamanho aproximado do cluster necessário | 232 GB de RAM (armazenamento SSD de 6,8 TB) |
Hot: 58 GB de RAM com SSDs
Warm: 15 GB de RAM com discos rígidos |
Hot: 58 GB de RAM com SSDs
Warm: 2 GB de RAM com discos rígidos |
| Custo mensal do cluster | US$ 3.772,01 | US$ 1.491,05 | US$ 1.024,92 |
A diferença na economia de custos é expressiva. Quando adicionamos rollups de dados ao nosso cluster hot-warm existente, podemos obter uma redução de 31% nos custos. Os resultados são ainda mais amplificados quando comparamos nosso cenário final a um cluster tradicional com hardware de camada única: a economia é de 73%!
Faça a implantação do seu jeito
Cada método tem suas vantagens e desvantagens. Você tem a flexibilidade de ajustar cada estratégia da forma que atenda melhor às suas necessidades.
As políticas de ILM permitem definir períodos de rollover com base no tamanho do índice, no número de documentos ou no tempo de existência dos documentos, o que transfere os dados para nós warm no seu cluster hot-warm. Os nós warm podem comportar um grande volume de armazenamento com eficiência, ajudando você a gastar menos em custos de computação. As consultas podem não ter o mesmo desempenho que nos nós hot, tornando essa a abordagem preferida para dados que são consultados com pouca frequência.
Os rollups de dados resumem os dados em documentos menos granulares, o que é útil se os dados envelheceram até um ponto em que a granularidade original não é mais necessária. Os documentos de origem podem ser excluídos, ajudando a economizar nos custos de armazenamento. Você pode definir quanto quer resumir os documentos e também quando. Encontre o equilíbrio certo para que seus dados de rollup continuem fornecendo insights importantes, como tendências ao longo do tempo ou comportamento do sistema devido a um pico de tráfego.
Agora que conhece as estratégias prontas para otimizar as cargas de trabalho das métricas no cluster do Elasticsearch, o que você deve fazer com todo esse espaço extra de armazenamento? O Elastic Stack é usado em todo o mundo para uma infinidade de casos de uso: logs, rastreamentos de APM, eventos de auditoria, dados de endpoint e muito mais.
O Elasticsearch Service no Elastic Cloud fornece tudo o que o Elastic Stack tem a oferecer, combinado com a experiência operacional de seus próprios criadores. Se você não está pronto para expandir para novos casos de uso, pode continuar colocando seu cluster para trabalhar aproveitando a otimização do armazenamento. Expanda seu tempo de retenção de dados e armazene ainda mais por um preço semelhante ou reduza o tamanho do cluster com apenas alguns cliques, economizando sem comprometer a visibilidade.
Quer começar com o Elasticsearch Service no Elastic Cloud? Faça uma avaliação gratuita de 14 dias.