Cinco componentes técnicos da busca de similaridade de imagem


 Share on Twitter
Share on TwitterCompartilhar no Twitter

 Share on LinkedIn
Share on LinkedInCompartilhar no LinkedIn

 Share on Facebook
Share on FacebookCompartilhar no Facebook

 Share by Email
Share by EmailCompartilhar por e-mail

 Print this page
Print this pageImprimir
Na primeira parte desta série de posts do blog, apresentamos a busca de similaridade de imagem e analisamos uma arquitetura geral que pode reduzir a complexidade e facilitar a implementação. Este blog explica os conceitos e as considerações técnicas subjacentes para cada componente, necessários para implementar uma aplicação de busca de similaridade. Saiba mais sobre os seguintes recursos:
- Modelos de embedding: modelos de machine learning que geram a representação numérica dos seus dados, necessária para aplicar a busca vetorial
- Endpoint de inferência: API para aplicar os modelos de embedding aos seus dados no Elastic
- Busca vetorial: como a busca de similaridade funciona com a busca de vizinho mais próximo
- Geração de embeddings de imagem: geração de redimensionamento de representações numéricas para grandes conjuntos de dados
- Lógica da aplicação: como o front-end interativo se comunica com o mecanismo de busca vetorial no back-end
Ao se aprofundar nesses cinco componentes, você conseguirá visualizar um esquema de como implementar experiências de busca mais intuitivas aplicando a busca vetorial no Elastic.
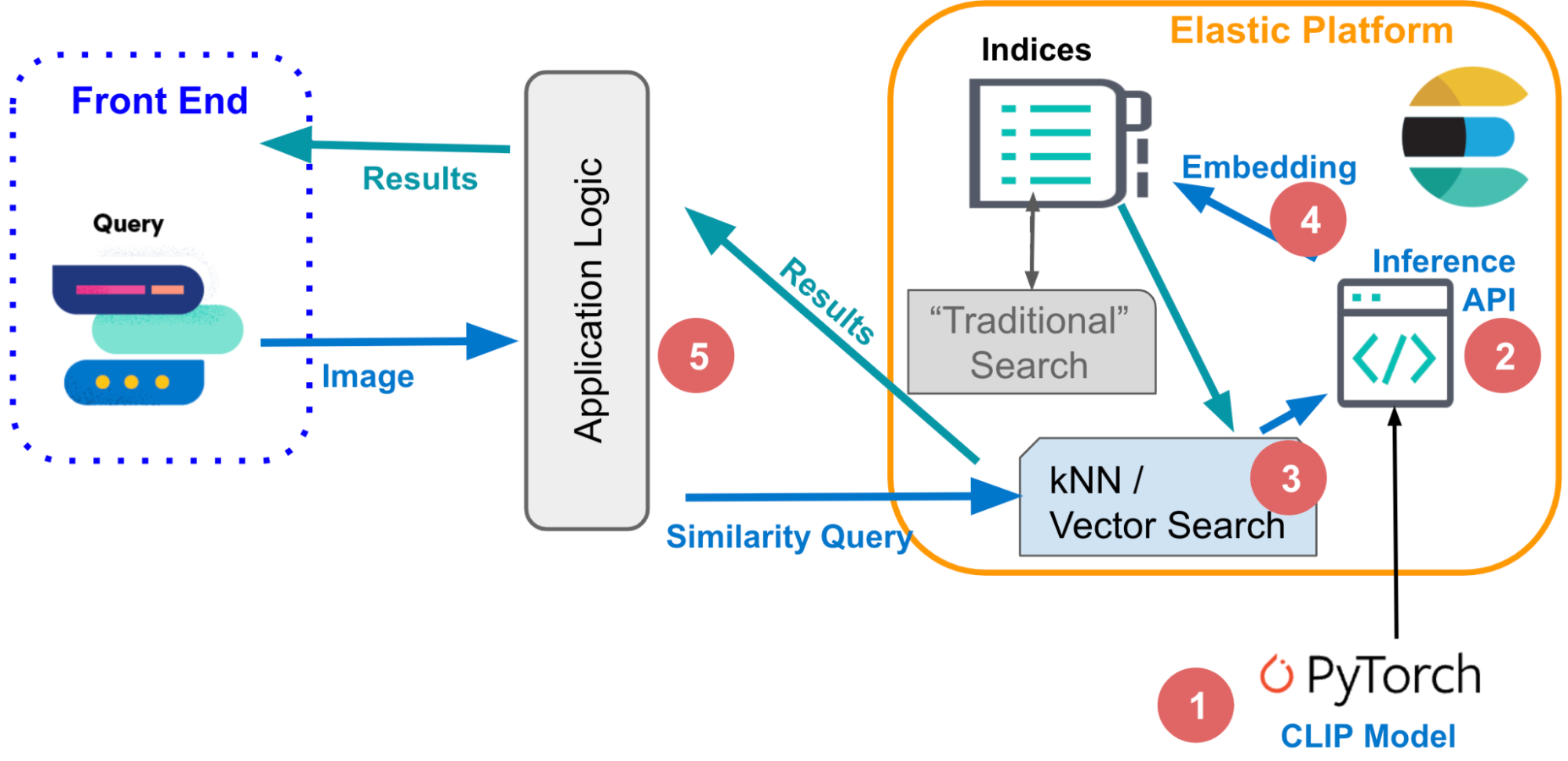
1. Modelos de embedding
Para aplicar a busca de similaridade à linguagem natural ou aos dados de imagem, você precisa de modelos de machine learning que convertam seus dados em representações numéricas próprias, o que chamamos de embeddings vetoriais. Neste exemplo:
- O modelo “transformador” de PLN converte a linguagem natural em um vetor.
- O modelo CLIP (Contrastive Language-Image Pre-training) da OpenAI vetoriza as imagens.
Os modelos transformadores são modelos de machine learning treinados para processar dados de linguagem natural de diversas maneiras, por exemplo, tradução de idiomas, classificação de texto ou reconhecimento de entidades nomeadas. Eles são treinados em conjuntos de dados de texto extremamente grandes para aprender os padrões e estruturas da linguagem humana.
A aplicação de similaridade de imagem encontra imagens que correspondem às descrições de texto e linguagem natural dadas. Para implementar esse tipo de busca de similaridade, você precisa de um modelo que tenha sido treinado tanto em texto quanto em imagens e que possa converter a consulta de texto em um vetor. O resultado pode então ser usado para encontrar imagens similares.
Saiba mais sobre como carregar e usar o modelo de PLN no Elasticsearch >>
O CLIP é um modelo de linguagem em grande escala, desenvolvido pela OpenAI, que trabalha com texto e imagens. O modelo é treinado para prever a representação textual de uma imagem, com base em um pequeno trecho de texto fornecido. O treinamento consiste em aprender a alinhar as representações visuais e textuais de uma imagem de modo que o modelo consiga fazer previsões precisas.
Outro aspecto importante do CLIP é que se trata de um modelo "zero-shot", que lhe permite realizar tarefas para as quais ele não foi treinado especificamente. Por exemplo, ele pode traduzir idiomas com os quais não teve contato durante o treinamento ou classificar imagens em categorias que nunca viu antes. Isso faz do CLIP um modelo muito flexível e versátil.
Você usará o modelo CLIP para vetorizar suas imagens, usando o endpoint de inferência no Elastic conforme descrito a seguir e executando a inferência em um conjunto de imagens grande da maneira detalhada na seção 3 mais adiante.
2. Endpoint de inferência
POST _ml/trained_models/sentence-transformers__clip-vit-b-32-multilingual-v1/deployment/_infer
{
"docs" : [
{"text_field": "A mountain covered in snow"}
]
}3. Busca vetorial (similaridade)
Após você indexar consultas e documentos com embeddings vetoriais, documentos semelhantes serão os vizinhos mais próximos da sua consulta no espaço de embedding. Um algoritmo popular que consegue esse resultado é o k-ésimo vizinho mais próximo (kNN), que encontra os k vetores mais próximos de um vetor de consulta. Entretanto, nos grandes conjuntos de dados nos quais o processamento costuma ser feito nas aplicações de busca de imagem, o kNN requer um altíssimo uso de recursos computacionais, podendo resultar em um excesso de tempo de execução. Para solucionar isso, a busca do vizinho mais próximo aproximado (ANN) sacrifica a precisão perfeita em troca da eficiência na execução em espaços de embedding altamente dimensionais, em grande escala.
No Elastic, o endpoint _search usa tanto a busca exata quanto a aproximada do vizinho mais próximo. Use o código abaixo para a busca de kNN. Ele pressupõe que os embeddings para todas as imagens emyour-image-index estejam disponíveis no campo image_embedding. A seção a seguir explica como criar os embeddings.
# Run kNN search against <query-embedding> obtained above
POST <your-image-index>/_search
{
"fields": [...],
"knn": {
"field": "image_embedding",
"k": 5,
"num_candidates": 10,
"query_vector": <query-embedding>
}
}Para saber mais sobre o kNN no Elastic, consulte nossa documentação: https://www.elastic.co/guide/en/elasticsearch/reference/current/knn-search.html.
4. Geração de embedding de imagem
Os embeddings de imagem mencionados acima são essenciais para o bom desempenho da sua busca de similaridade de imagem. Eles devem ser armazenados em um índice separado que inclua os embeddings de imagem, chamado de you-image-index no código acima. O índice consiste em um documento por imagem que reúne também campos para interpretação de contexto e vetor denso (embedding de imagem) da imagem. Os embeddings de imagem representam uma imagem em um espaço de menor dimensão. Imagens similares são mapeadas para pontos vizinhos nesse espaço. O tamanho da imagem bruta pode ter muitos MB, dependendo da resolução.
Os detalhes específicos de como esses embeddings são gerados podem variar. Em geral, esse processo consiste na extração de recursos das imagens e, a seguir, seu mapeamento em um espaço de dimensão menor usando uma função matemática. Essa função normalmente é treinada em um conjunto de dados de imagens grande para que seja aprendida a melhor maneira de representar os recursos no espaço de dimensão menor. A tarefa de geração de embeddings é executada uma única vez.
Neste blog, empregaremos o modelo CLIP para esse propósito. Ele é distribuído pela OpenAI e oferece um ótimo ponto de partida. Para obter o desempenho desejado, você pode precisar treinar um modelo de embedding customizado para casos de uso especializados, dependendo de como os tipos de imagens que você quer classificar são representados nos dados disponíveis publicamente que são usados para treinar o modelo CLIP.
A geração de embedding no Elastic precisa ocorrer no momento da ingestão e, por isso, em um processo externo à busca, com as seguintes etapas:
- Carregue o modelo CLIP.
- Para cada imagem:
- Carregue a imagem.
- Avalie a imagem usando o modelo.
- Salve os embeddings gerados em um documento.
- Salve o documento no datastore/Elasticsearch.
O pseudocódigo torna essas etapas mais concretas, e você pode acessar o código completo no repositório de exemplo.
...
img_model = SentenceTransformer('clip-ViT-B-32')
...
for filename in glob.glob(PATH_TO_IMAGES, recursive=True):
doc = {}
image = Image.open(filename)
embedding = img_model.encode(image)
doc['image_name'] = os.path.basename(filename)
doc['image_embedding'] = embedding.tolist()
lst.append(doc)
...Ou então, consulte a figura abaixo como ilustração:
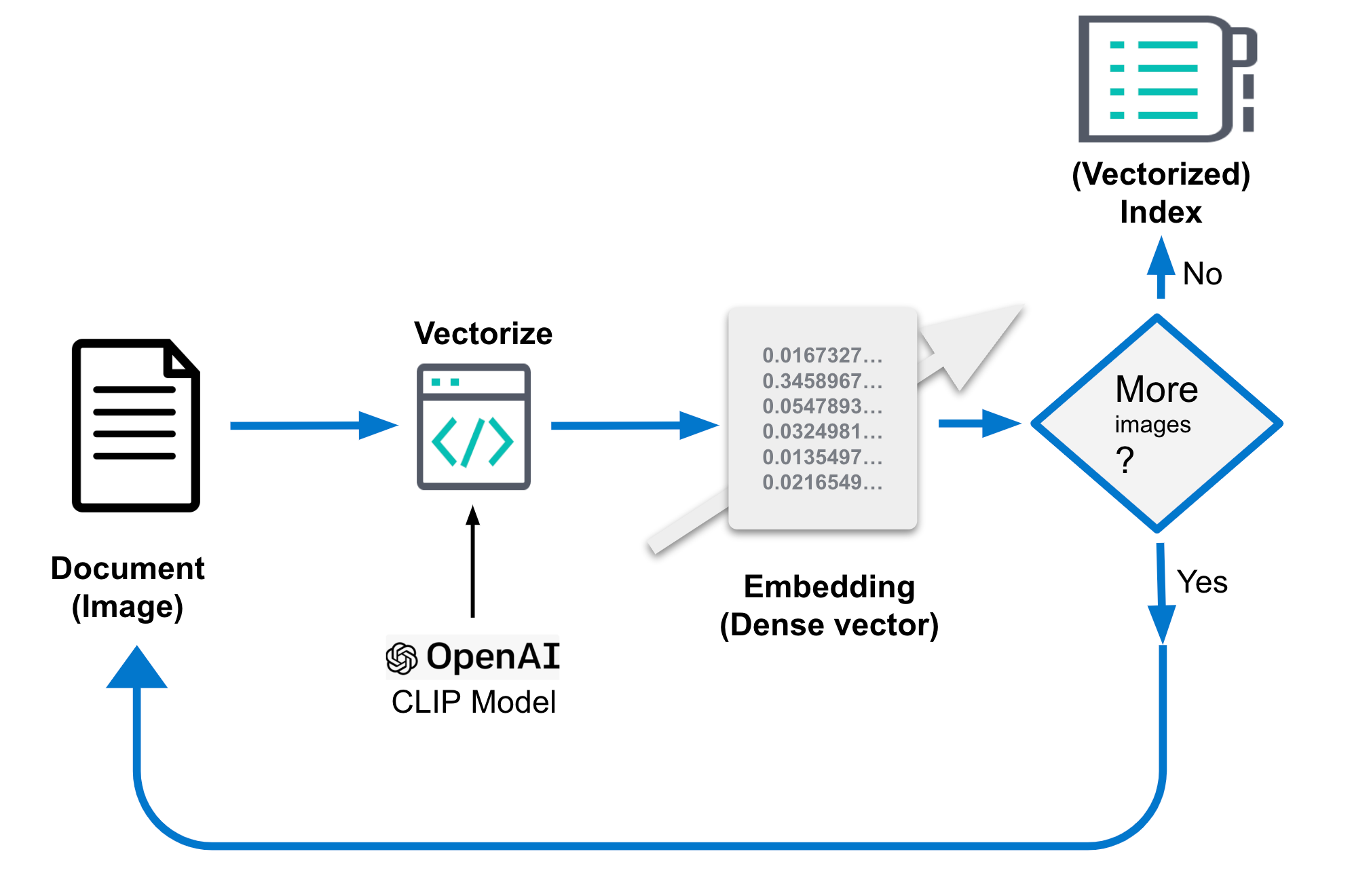
O documento resultante do processamento deve ficar mais ou menos assim. A parte mais importante é o campo “image_embedding”, no qual a representação do vetor denso é armazenada.
{
"_index": "my-image-embeddings",
"_id": "_g9ACIUBMEjlQge4tztV",
"_score": 6.703597,
"_source": {
"image_id": "IMG_4032",
"image_name": "IMG_4032.jpeg",
"image_embedding": [
-0.3415695130825043,
0.1906963288784027,
.....
-0.10289803147315979,
-0.15871885418891907
],
"relative_path": "phone/IMG_4032.jpeg"
}
}5. A lógica da aplicação
Usando esses componentes básicos, você pode finalmente juntar todas as partes e trabalhar na lógica para implementar uma busca de similaridade de imagem interativa. Para começar, vamos usar uma abordagem conceitual, indicando o que é preciso acontecer quando a intenção é recuperar imagens de forma interativa para corresponder a uma descrição específica.
Nas consultas textuais, a entrada pode ser simples, de uma única palavra, como “rosas”, ou uma descrição mais detalhada como “uma montanha coberta de neve”. Ou então você pode também fornecer uma imagem e solicitar imagens similares à que você já tem.
Mesmo que você esteja usando modalidades diferentes para formular sua consulta, ambas são executadas com a mesma sequência de etapas na busca vetorial subjacente, ou seja, usando uma consulta (kNN) em documentos representados por seus embeddings (como vetores “densos”). Em seções anteriores, descrevemos os mecanismos que permitem que o Elasticsearch execute uma busca vetorial muito rápida e redimensionável, necessária em grandes conjuntos de dados de imagem. Consulte esta documentação para saber mais sobre o ajuste da busca de kNN no Elastic para obter mais eficiência.
- Então, como você pode implementar a lógica descrita acima? No diagrama de fluxo abaixo, você pode ver como a informação flui: A consulta emitida pelo usuário, seja de texto ou de imagem, é vetorizada pelo modelo de embedding, dependendo do tipo de entrada: um modelo de PLN para descrições de texto e um modelo CLIP para imagens.
- Ambos os tipos convertem a consulta de entrada em suas representações numéricas e armazenam o resultado em um tipo de vetor denso no Elasticsearch ([número, número, número...]).
- A representação do vetor é então usada em uma busca de kNN para encontrar vetores similares (imagens), que são retornados como resultado.
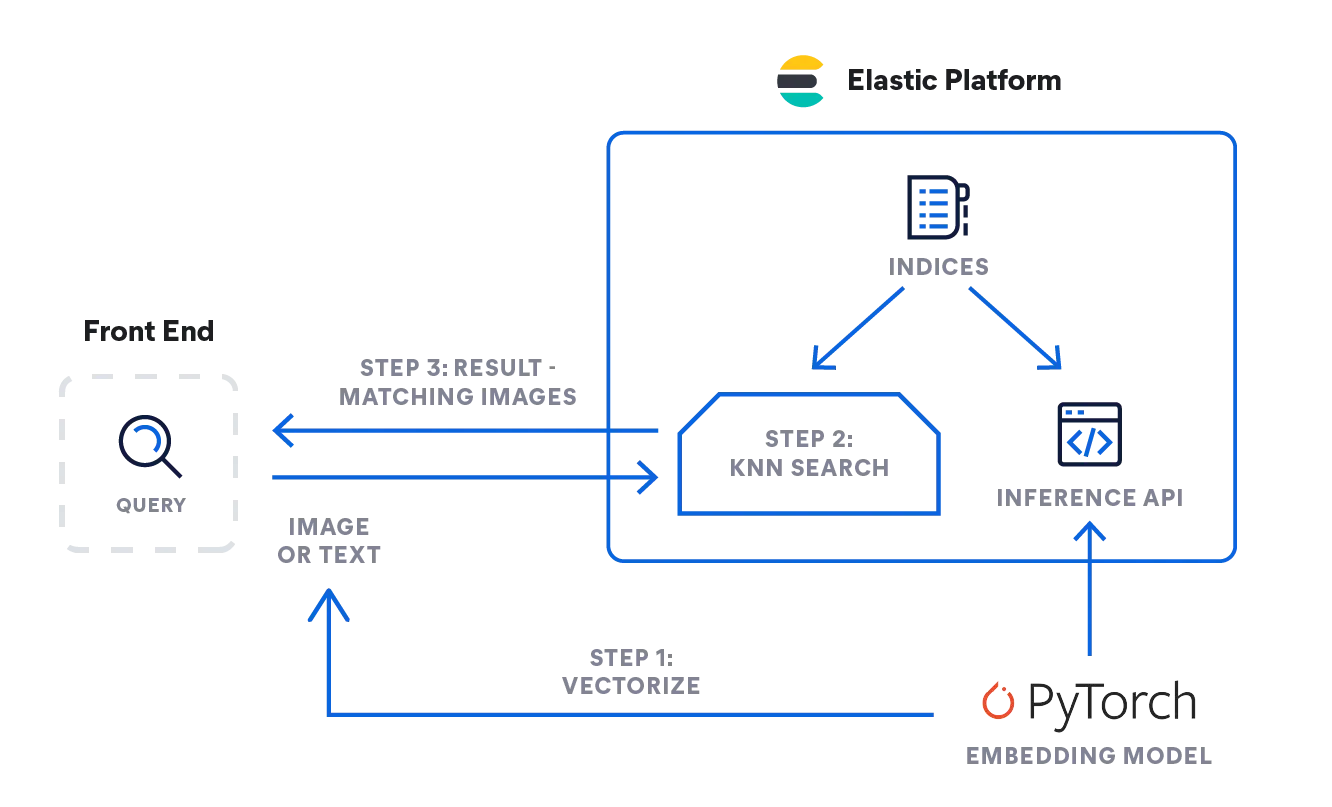
Inferência: vetorizar as consultas do usuário
A aplicação em segundo plano enviará uma solicitação para a API de inferência no Elasticsearch. Para a entrada de texto, algo como o seguinte:
POST _ml/trained_models/sentence-transformers__clip-vit-b-32-multilingual-v1/deployment/_infer
{
"docs" : [
{"text_field": "A mountain covered in snow"}
]
}Para imagens, você pode usar o código simplificado abaixo para processar uma única imagem com o modelo CLIP, que você precisou carregar em seu nó de machine learning do Elastic com antecedência:
model = SentenceTransformer('clip-ViT-B-32')
image = Image.open(file_path)
embedding = model.encode(image)Você receberá de volta uma matriz de 512 com valores Float32 como esta:
{
"predicted_value" : [
-0.26385045051574707,
0.14752596616744995,
0.4033305048942566,
0.22902603447437286,
-0.15598160028457642,
...
]
}Busca: por imagens similares
A busca funciona da mesma maneira nos dois tipos de entrada. Envie a consulta com definição de busca de kNN no índice com embeddings de imagem my-image-embeddings. Inclua o vetor denso da consulta anterior ("query_vector": [ ... ]) e execute a busca.
GET my-image-embeddings/_search
{
"knn": {
"field": "image_embedding",
"k": 5,
"num_candidates": 10,
"query_vector": [
-0.19898493587970734,
0.1074572503566742,
-0.05087625980377197,
...
0.08200495690107346,
-0.07852292060852051
]
},
"fields": [
"image_id", "image_name", "relative_path"
],
"_source": false
}A resposta do Elasticsearch lhe fornecerá as melhores imagens correspondentes, com base em nossa consulta de busca de kNN, armazenadas no Elastic como documentos.
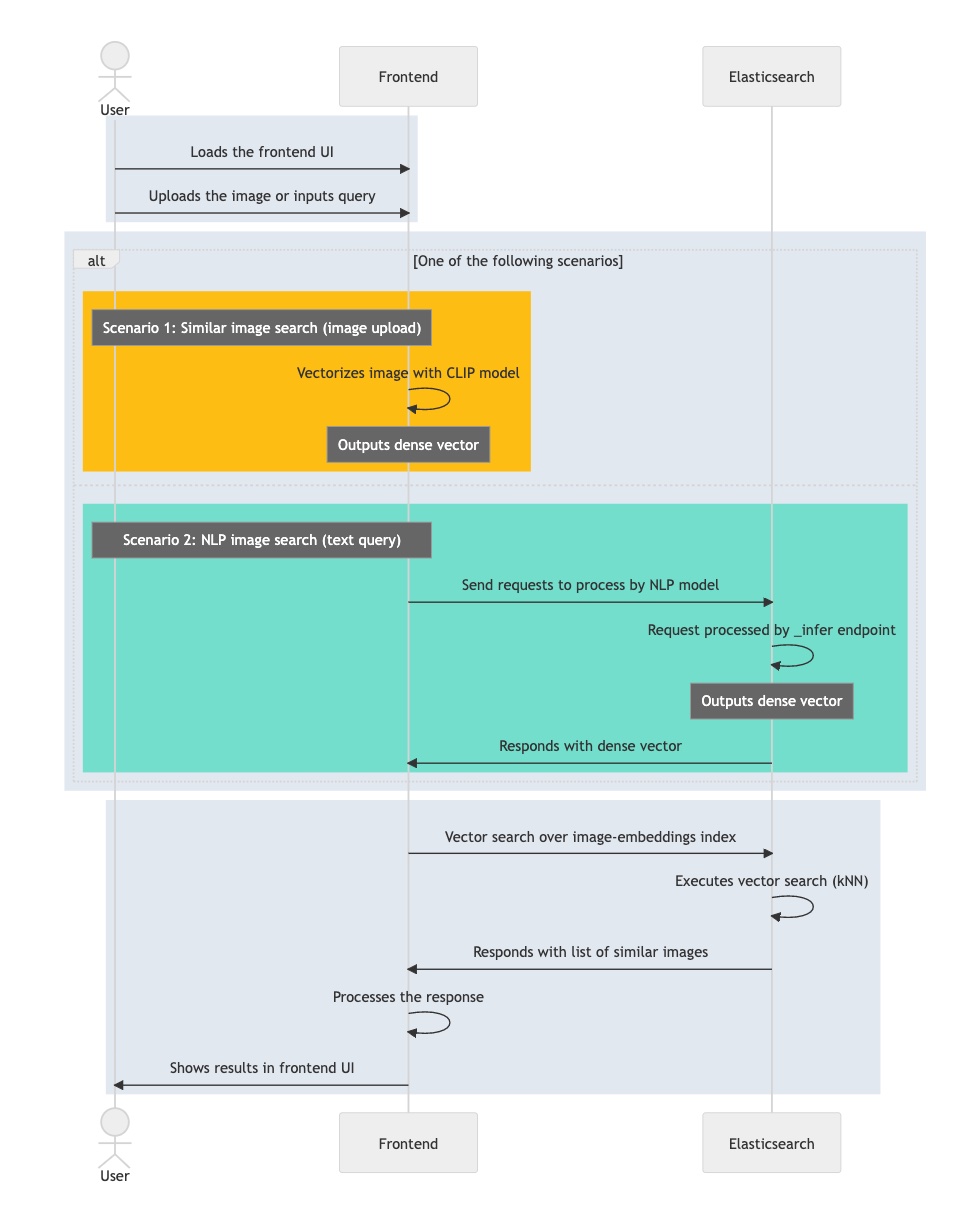
O gráfico de fluxo abaixo resume as etapas pelas quais a aplicação interativa passa ao longo do processamento da consulta do usuário:
- Carregue a aplicação interativa, seu front-end.
- O usuário seleciona uma imagem interessante.
- Sua aplicação vetoriza a imagem com a aplicação do modelo CLIP, armazenando o embedding resultante como vetor denso.
- A aplicação inicia uma consulta de kNN no Elasticsearch, que usa o embedding e retorna seus vizinhos mais próximos.
- Sua aplicação processa a resposta e devolve uma ou mais imagens correspondentes.
Agora que você entendeu quais são os principais componentes e o fluxo de informação necessários para implementar uma busca de similaridade de imagem interativa, pode passar para a parte final da série para aprender como fazer isso funcionar. Você terá um guia passo a passo para configurar o ambiente da aplicação, importar o modelo de PLN e, por fim, completar a geração do embedding de imagem. Em seguida, você poderá buscar imagens com linguagem natural, sem a necessidade de palavras-chave.
Compartilhar
- Share on Twitter
Compartilhar no Twitter
- Share on LinkedIn
Compartilhar no LinkedIn
- Share on Facebook
Compartilhar no Facebook
- Share by Email
Compartilhar por e-mail
- Print this page
Imprimir