클러스터에 노드 추가 시 Elasticsearch 성능 극대화


 Share on Twitter
Share on Twitter트위터에서 공유하기

 Share on LinkedIn
Share on LinkedIn링크드인에서 공유하기

 Share on Facebook
Share on Facebook페이스북에서 공유하기

 Share by Email
Share by Email이메일로 공유하기

 Print this page
Print this page인쇄하기
Elasticsearch 클러스터에 노드를 추가하면 엄청난 워크로드로 확장할 수 있습니다. 성능을 저하시키지 않도록 Elasticsearch 클러스터를 확장하는 최적의 방법을 이해하는 것이 중요합니다.
Elasticsearch는 빠르고 강력한 검색 기술입니다. 데이터가 증가함에 따라 데이터의 뛰어난 확장성을 활용해야 합니다. 클러스터에 노드를 더 많이 추가하면 클러스터가 보유할 수 있는 데이터의 양이 증가할 뿐만 아니라 보통 한 번에 처리하는 요청의 수가 증가하고 결과를 반환하는 데 걸리는 시간도 단축됩니다.
Elasticsearch 클러스터에 노드를 추가하면 불안정, 가동 중단 시간, 좌절감 증가 및 수익 손실을 초래한 이유를 밝혀내기 위해 엄청나게 고된 주말을 보내게 됩니다. 따라서 클러스터를 확장할 경우 심각한 성능 병목 현상이 발생할 수 있는 몇 가지 일반적인 구성에 대해 알아보겠습니다.
Elasticsearch 크기 조정과 용량 계획이라는 아주 유용한 웨비나가 있는데, 여기에서는 클러스터의 네 가지 주요 하드웨어 리소스를 다음과 같이 정의합니다.
- 컴퓨팅 - 중앙 처리 장치(CPU), 클러스터가 작업을 수행할 수 있는 속도.
- 저장 공간 - 하드 디스크 드라이브(HDD) 또는 솔리드 스테이트 드라이브(SSD), 클러스터가 장기적으로 보유할 수 있는 데이터의 양.
- 메모리 - 랜덤 액세스 메모리(RAM), 클러스터가 한 번에 수행할 수 있는 작업량.
- 네트워크 - 대역폭, 노드가 서로 간에 데이터를 전송하는 속도.
가장 일반적인 두 가지 성능 병목 현상은 컴퓨팅과 저장 공간입니다. 이 두 가지가 부족할 경우 클러스터의 데이터 노드에 엄청난 영향을 미칩니다. 마스터, 수집 또는 변환과 같은 다른 노드 역할은 별도로 논의해야 하는 부분입니다.
참고: 단순화를 위해, 이 글에서는 단일 Elasticsearch 클러스터의 확장에 중점을 두고 있습니다. 공유 하드웨어에서 여러 클러스터를 실행하면 또 다른 복잡성 계층이 추가됩니다.
하드웨어 리소스는 플랫폼에 따라 다르게 할당됩니다. 예를 들어, 노드는 하드웨어일까요, 가상 머신일까요, 아니면 컨테이너 기반 시스템일까요?
Elasticsearch 노드 추가 시 용량이 추가되는 경우
전용 하드웨어 노드 추가
클러스터 성능을 높이는 가장 예측 가능한 방법은 새 하드웨어를 추가하는 것입니다. 새 전용 하드웨어를 추가하면 네 가지 주요 리소스가 모두 증가합니다. 새 하드웨어 노드를 추가하면 클러스터 성능이 향상됩니다. 한 가지 주요 예외가 있는데 이것은 나중에 다루겠습니다.
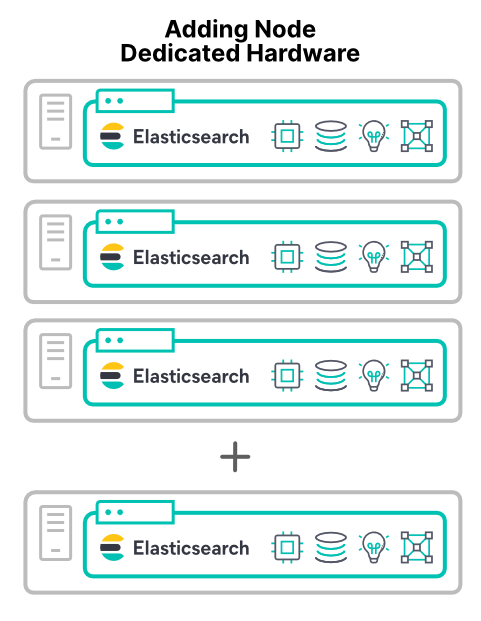
새 호스트의 가상 머신이나 컨테이너에서 노드 추가
노드를 가상 머신(VM)이나 컨테이너로 추가하면 얘기가 달라집니다. 클러스터에 새 호스트의 새 노드를 할당할 때, 더 많은 하드웨어 리소스를 할당합니다. CPU 코어, RAM, 저장 공간, 총 대역폭이 모두 증가합니다.
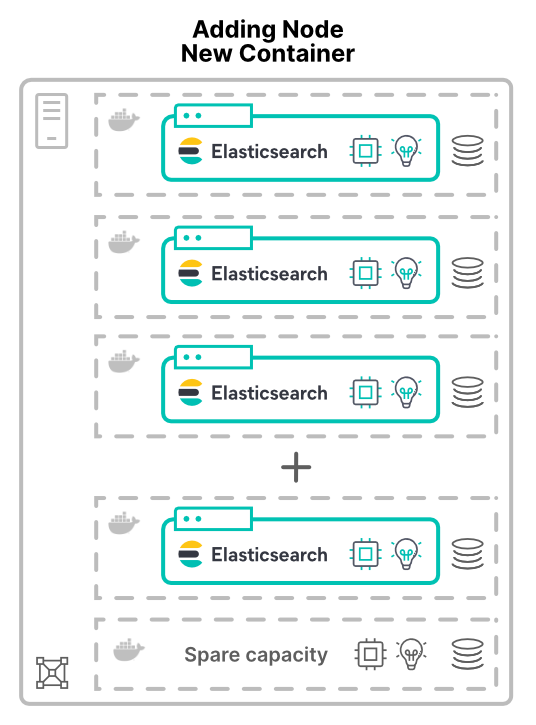
애플리케이션을 가상화(또는 컨테이너화)해야 하는 한 가지 이유는 하드웨어 사용률을 향상시키는 것입니다. 여기서 노드를 추가하면 클러스터에서 사용할 수 있는 하드웨어의 양이 증가할 뿐입니다. 결과적인 성능 향상은 공유 리소스의 한도에 따라 달라집니다.
노드 추가 시 용량이 분할되는 경우
가상 머신을 사용하든 컨테이너를 사용하든 하드웨어를 분할하면 Elasticsearch 노드는 결국 하드웨어를 공유하게 됩니다. 이러한 고려 사항은 Elastic Cloud Enterprise(ECE)와 Kubernetes의 Elastic Cloud(ECK)를 비롯한 모든 배포 모델에 적용됩니다.
컴퓨팅 병목 현상 발생
가상 머신을 사용하여 CPU를 할당하는 것은 일반적으로 예측 가능합니다. 즉, 각 가상 머신에 사용할 코어 수를 할당하는 것입니다. 컨테이너를 사용하면, CPU 공유가 덜 간단합니다.
Kubernetes와 같은 컨테이너 시스템은 CPU 리소스를 1000분의 1 CPU 또는 밀리코어 단위로 측정할 수 있습니다. 요청과 한도 사이에는 상당한 차이가 있습니다. 요청된 CPU만 정의하면 컨테이너가 호스트 CPU의 최대 100%를 사용할 수 있습니다. 그러나 CPU를 너무 많이 제한하면 값비싼 리소스가 유휴 상태가 됩니다.
> 팁: 스레드 풀은 CPU 코어를 시작점으로 사용합니다. 컨테이너의 경우 스레드 풀 구성이 예상대로 작동하는지 확인하는 것이 좋습니다.
Kubernetes에서, 총 컨테이너의 CPU 한도가 사용 가능한 총 하드웨어를 초과할 수 있습니다. 이는 모든 컨테이너가 동시에 최대 CPU 사용률을 달성하지 못할 것이라고 가정합니다.
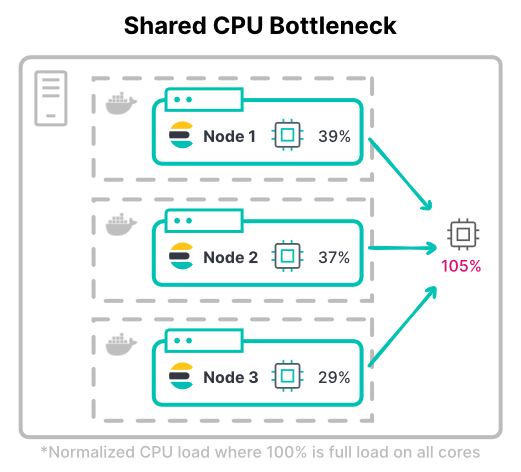
클러스터의 최대 처리량을 고려해 보세요. 컴퓨팅 집약적인 워크로드에서, 노드는 색인을 위해 전체 할당된 CPU 한도를 필요로 하는 경우가 많습니다. 인덱스를 많이 사용하는 워크로드 중 가장 일반적인 것은 대량 로깅 클러스터입니다.
> 팁: CPU 한도를 결정할 때 피크 및 일반적인 CPU 사용량을 모두 고려하세요. 또한 CPU 스로틀링이 허용 가능한 정도도 고려하세요.
저장 공간 병목 현상 발생
저장 공간 병목 현상을 방지하기 어려울 수 있습니다. 저장 공간은 처리량이 아니라 공간별로 할당되기 때문입니다. Elasticsearch 노드의 저장 공간이 부족해지면 low disk watermark에 도달하여 샤드 할당을 중지합니다.
가상 머신이든 컨테이너든, 대부분의 플랫폼은 저장 공간 디바이스 사용률을 제한할 수 있는 쉬운 방법이 없습니다. 대부분의 환경에는 초당 입/출력 처리량(IOPS) 또는 읽기/쓰기 처리량에 대한 구성 가능한 제한이 없습니다. 권장 XFS 파일 시스템에서도 디스크 공간에 따른 디스크 할당량만 허용합니다.
한도가 없으면, 저장 공간 집약적 워크로드를 갖는 모든 컨테이너는 저장 공간 하드웨어를 포화시킬 수 있습니다. 이로 인해 해당 하드웨어를 공유하는 다른 노드가 활용할 수 있는 여지가 없어집니다. 대규모 배포는 자체/데이터 디렉터리에 문제가 발생할 수 있습니다. 여러 노드가 동일한 스토리지 영역 네트워크(SAN) 하드웨어에 자체/데이터 디렉터리를 마운트하는 경우, 모든 노드의 총 처리량은 디바이스가 감당할 수 있는 양을 넘어설 수 있습니다.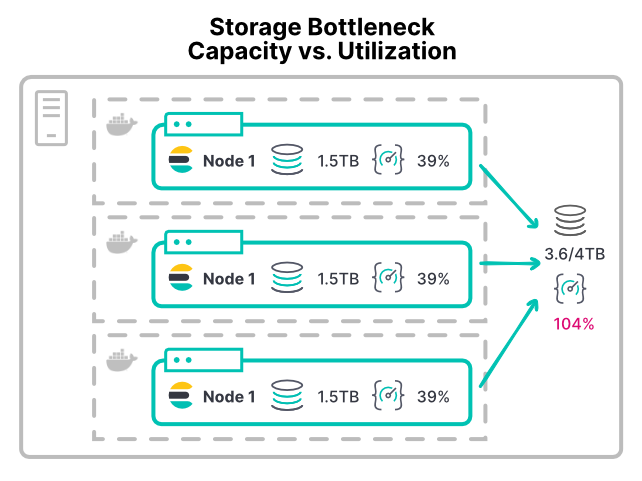
이와 같은 컨테이너 설정에서는, 노드를 더 많이 추가하면 클러스터에 더 많은 CPU와 메모리가 할당되지만 기존 저장 공간 처리량은 더 분할되므로 디스크 작업 시간이 길어지고 노드를 추가함으로써 성능이 저하됩니다.
> 팁: 저장 공간 처리량을 활용할 수 있는 여지가 부족한 노드의 경우, 조기 경고 표시는 CPU I/O 대기 시간이 10%를 초과합니다. 개별 컨테이너에서 이 메트릭을 보고하지 않으므로 가상 머신이나 컨테이너 호스트에서 이를 확인하세요.
노드 추가가 망 중립인 경우
효과적으로 확장할 수 있는 마지막 방법이 있습니다. 물리적 하드웨어를 추가할 때도 이러한 구성 병목 현상이 발생합니다.
샤드가 충분하지 않은 인덱스 처리량 제한
어떤 방법을 사용하든, 노드를 추가한다고 해서 인덱스의 샤드 수가 변경되지는 않습니다. 인덱스에 기본 샤드 2개와 복제본 1세트가 있는 경우, 총 샤드는 4개입니다. 노드 클러스터 4에서 노드당 하나의 샤드만 갖는 것은 색인 처리량을 극대화하는 아주 좋은 방법입니다.
인바운드 데이터 볼륨이 증가함에 따라, 우리는 클러스터에 또 다른 노드 2개를 추가합니다. 이는 전체 클러스터 리소스가 50% 증가한 것이지만, 수집 속도는 정확히 0%가 향상된 것을 볼 수 있습니다. 왜 그럴까요?
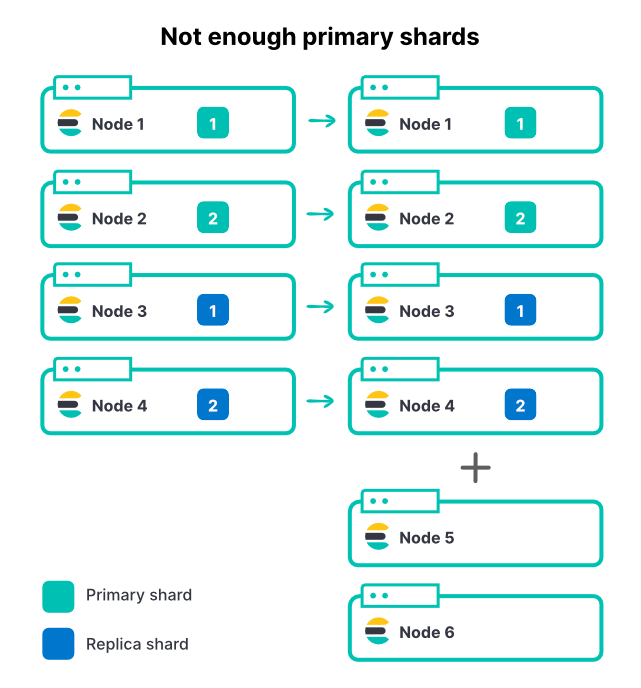
여기서 모든 샤드가 이미 할당되어 있기 때문에 새 노드는 색인에 기여할 수 없습니다. 인덱스가 더 많은 노드를 활용하려면 기본 샤드 수도 역시 증가해야 합니다. 클러스터에 활성 인덱스가 많은 경우(흔히 있는 경우입니다) 노드를 추가하면 클러스터의 총 처리량이 증가하게 되지만, 기본 샤드의 수가 한정되어 있기 때문에 가장 활성화된 인덱스는 여전히 제한될 수 있습니다. Elasticsearch를 위해 적절한 샤드 수를 선택하는 것은 용량 계획의 중요한 부분입니다.
따라서 위의 예에서 기본 샤드를 2개에서 3개로 늘리면, 샤드당 복제본이 1개씩 추가되어 6개 노드에 걸쳐 총 6개의 샤드가 할당됩니다.
> 팁: index.routing.allocation.total_shards_per_node를 설정[설명서]하면 안전망이 될 수 있습니다. 그러나 이 한도를 너무 낮게 설정하면 샤드가 할당되지 않은 채로 남을 수 있습니다.
결론
Elasticsearch 클러스터에 노드를 추가하면 그 성능이 향상될까요? 경우에 따라 다릅니다. 노드가 하드웨어를 공유하는 경우, 공유 리소스 병목 현상에 주의해야 합니다. 일반적인 두 가지 병목 현상은 CPU와 저장 공간의 과도한 사용입니다. 신중한 계획과 좋은 샤드 전략으로 노드를 추가하면 성능이 향상될 것입니다.
Elastic Cloud에서 실행할 경우의 많은 이점 중 하나는 바로 이러한 종류의 공유 리소스 성능 우려 사항을 파악하고 해결하기 위한 Elastic 팀의 헌신적인 노력입니다. https://www.elastic.co/kr/cloud/에서 지금 바로 클라우드 체험판 사용을 시작하세요.
또한 Elasticsearch 크기 조정 및 용량 계획을 시청하시면 Elasticsearch의 성능을 보다 심층적으로 이해하실 수 있습니다.
공유하기
- Share on Twitter
트위터에서 공유하기
- Share on LinkedIn
링크드인에서 공유하기
- Share on Facebook
페이스북에서 공유하기
- Share by Email
이메일로 공유하기
- Print this page
인쇄하기