Elasticsearch에서 일본어 NLP 모델을 사용하여 시맨틱 검색 활성화


 Share on Twitter
Share on Twitter트위터에서 공유하기

 Share on LinkedIn
Share on LinkedIn링크드인에서 공유하기

 Share on Facebook
Share on Facebook페이스북에서 공유하기

 Share by Email
Share by Email이메일로 공유하기

 Print this page
Print this page인쇄하기
매일 생성되는 대량의 내부 문서와 제품 정보 중에서 필요한 문서를 빠르게 찾는 것은 업무와 일상 모두에서 극히 중요한 작업입니다. 그러나 검색해야 할 문서의 양이 많은 경우, 컴퓨터가 실시간으로 모든 문서를 다시 읽고 대상 파일을 찾는 데에도 시간이 많이 걸릴 수 있습니다. 이것은 Elasticsearch® 및 기타 검색 엔진 소프트웨어의 출현으로 이어졌습니다. 검색 엔진을 사용하면, 문서에 포함된 주요 검색어를 사용하여 해당 문서를 빠르게 찾을 수 있도록 검색 인덱스 데이터가 먼저 생성됩니다.
그러나 사용자가 검색하고 있는 정보가 어떤 유형인지 대략적으로 알고 있더라도, 적합한 키워드를 기억하지 못하거나 동일한 의미를 가진 다른 표현을 검색할 수도 있습니다. Elasticsearch에서는 이러한 상황을 처리하기 위해 동의어 및 유사 용어를 정의할 수 있지만, 어떤 경우에는 단순히 대응표를 사용하여 검색 쿼리를 보다 적합한 것으로 변환하는 것이 어려울 수 있습니다.
이러한 요구를 해결하기 위해, Elasticsearch 8.0은 구문의 시맨틱 콘텐츠로 검색하는 벡터 검색 기능을 출시했습니다. 그 외에도, Elasticsearch를 사용하여 벡터 검색 및 기타 NLP 작업을 수행하는 방법에 대한 블로그 시리즈도 있습니다. 그러나 8.8 릴리즈까지는 영어 이외의 언어로 된 텍스트를 올바르게 분석할 수 없었습니다.
8.9 릴리즈에서, Elastic은 텍스트 분석 처리에서 일본어를 적절하게 분석하기 위한 기능을 추가했습니다. 이 기능을 통해 Elasticsearch는 일본어 텍스트에 대한 벡터 검색과 같은 시맨틱 검색은 물론 일본어 정서 분석과 같은 자연어 처리 작업도 수행할 수 있습니다. 이 글에서는, 이러한 기능을 사용하는 방법에 대한 구체적인 단계별 지침을 제공합니다.
전제 조건
시맨틱 검색을 구현하기 전에, 이 기능을 사용하기 위한 전제 조건을 확인하세요. Elasticsearch 클러스터에서는, 개별 역할에 노드 역할이 할당됩니다. 한편, Elasticsearch 머신 러닝 노드는 머신 러닝 모델을 구동하는 요소입니다. 이 기능을 사용하려면, Elasticsearch 클러스터에 머신 러닝 노드가 활성화되어 있어야 하므로, 이에 해당하는지 미리 확인하시기 바랍니다. 머신 러닝 노드를 사용하려면 Platinum 라이선스 이상이 있어야 합니다. 그러나 기능을 테스트하고 제대로 작동하는지 확인하려는 경우에는 체험판 라이선스를 사용할 수 있습니다. 개발 환경이나 유사한 인스턴스에서 작업 기능을 확인하려면, Kibana® 화면에서 또는 API.를 통해 체험판을 활성화하세요.
시맨틱 검색을 실행하는 과정
Elasticsearch에서 시맨틱 검색을 실행하려면 다음 단계가 필요합니다.
(준비) 워크스테이션에 Eland 및 관련 라이브러리를 설치합니다.
자연어 처리 작업을 활성화하기 위해 머신 러닝 모델을 가져옵니다.
가져온 머신 러닝 모델에서 텍스트 분석 결과를 색인합니다.
머신 러닝 모델을 사용하여 kNN 검색을 수행합니다.
시맨틱 검색은 자연어 처리를 통해 구현되는 유일한 기능이 아닙니다. 이 블로그 포스팅의 후반부에서는, 텍스트 분류 작업을 가능하게 하는 머신 러닝 모델을 사용하여 텍스트의 정서 분석(긍정적 카테고리와 부정적 카테고리)을 수행하는 방법에 대한 예를 제시합니다.
다음 작업을 수행하는 방법에 대해 심층적으로 설명하도록 하겠습니다.
Eland 설치
Elasticsearch는 이제 자연어 처리 플랫폼처럼 작동할 수 있습니다. 그러나 실제로 Elasticsearch에서는 심층적인 자연어 처리가 구현되지 않는 것이 현실입니다. 필요한 모든 자연어 처리는 사용자가 머신 러닝 모델로서 Elasticsearch로 가져와야 합니다. 이 가져오기 프로세스는 Eland를 사용하여 수행됩니다. 사용자는 이러한 방식으로 외부 모델을 자유롭게 가져올 수 있으므로, 필요할 때마다 필요한 머신 러닝 기능을 추가할 수 있습니다.
Eland는 Elastic에서 제공하는 Python 라이브러리로, 이를 통해 사용자는 Elasticsearch 데이터를 PyTorch 및 scikit-learn과 같은 포괄적인 Python 머신 러닝 라이브러리와 연결할 수 있습니다. Eland 내에 번들로 포함된 eland_import_hub_model 명령줄 도구를 사용하여 Hugging Face에 게시된 Elasticsearch NPL 모델을 가져올 수 있습니다. 이 글의 아래에서 다루는 모든 명령줄 작업은 Google Colaboratory와 같은 Python 노트북을 사용한다고 가정합니다. (당연히 Mac이나 Linux 시스템과 같은 다른 유형의 터미널을 사용할 수 있습니다. 이러한 경우, 아래 명령 시작 부분의 !를 무시하세요.)
먼저, 종속 라이브러리를 설치합니다.
!pip install torch==1.13
!pip install transformers
!pip install sentence_transformers
!pip install fugashi
!pip install ipadic
!pip install unidic_lite일본어 모델을 사용하려면 Fugashi, ipadic 및 unidic_lite가 필요합니다.
이러한 라이브러리를 설치한 후, Eland도 설치할 수 있습니다. 일본어 모델을 사용하려면, Eland 8.9.0 이상이 필요하므로 버전 번호를 꼭 메모해 두세요.
!pip install eland설치가 완료되면, 아래 명령을 사용하여 Eland를 사용할 수 있는지 확인하세요.
!eland_import_hub_model -h
NLP 모델 가져오기
벡터 검색을 활성화하는 기본 방법은 이 글에서 영어로 사용되는 방법과 동일합니다. 여기서는 동일한 절차를 간단히 검토하여 살펴보겠습니다.
위에서 설명한 것처럼, Elasticsearch에서 NLP 처리를 활성화하려면 적절한 머신 러닝 모델을 Elasticsearch로 가져와야 합니다. PyTorch를 사용하여 머신 러닝 모델을 직접 구현하는 것도 가능하지만, 그러기 위해서는 머신 러닝과 자연어 처리에 대한 충분한 전문 지식은 물론 머신 러닝에 필요한 컴퓨팅 능력도 필요합니다. 그러나 이제 머신 러닝 및 자연어 처리 분야의 연구자와 개발자가 많이 사용하는 온라인 리포지토리인 Hugging Face가 있으며, 많은 모델이 이 리포지토리에 게시됩니다. 이 예에서는 Hugging Face에 게시된 모델을 사용하여 시맨틱 검색 기능을 구현하겠습니다.
먼저, 일본어 문장을 숫자 벡터로 임베드(벡터화)할 Hugging Face의 모델을 선택하겠습니다. 이 글에서는, 아래에 링크된 모델을 사용하겠습니다.
8.9에서 일본어 모델을 선택할 때 주의할 점을 몇 가지 살펴보겠습니다.
첫째, BERT 모델 알고리즘만 지원됩니다. Hugging Face의 태그와 기타 정보를 확인하여 원하는 NLP 모델이 BERT 훈련된 모델인지 확인하세요.
또한 BERT 및 기타 NLP 작업의 경우, 입력된 텍스트는 '사전 토큰화'됩니다. 즉, 텍스트가 단어 수준에서 여러 개의 단위로 나누어집니다. 이 경우에는, 일본어 형태소 분석 엔진을 사용하여 일본어 텍스트를 사전 토큰화합니다. Elasticsearch 8.9는 MeCab를 사용한 형태학적 분석을 지원합니다. Hugging Face의 모델 페이지에서, "파일 및 버전(tokenizer_config.json)" 탭을 열고 tokenizer_config.json 파일의 내용을 확인하세요. word_tokenizer_type 값이 mecab인지 확인하세요.
{
"do_lower_case": false,
"word_tokenizer_type": "mecab",
"subword_tokenizer_type": "wordpiece",
"mecab_kwargs": {
"mecab_dic": "unidic_lite"
}
}
안타깝게도, 사용하려는 모델의 word_tokenizer_type에 mecab 이외의 값이 있는 경우, 해당 모델은 현재 Elasticsearch에서 지원되지 않습니다. 지원이 필요한 특정 단어 토크나이저 유형(word_tokenizer_type)에 대한 피드백을 환영합니다.
가져올 모델을 결정한 후, 가져오는 데 필요한 단계는 영어 모델에 대한 것과 동일합니다. 먼저, eland_import_hub_model을 사용하여 모델을 Elasticsearch로 가져옵니다. eland_import_hub_model 사용 방법은 이 페이지를 참조하세요.
!eland_import_hub_model \
--url "https://your.elasticserach" \
--es-api-key "your_api_key" \
--hub-model-id cl-tohoku/bert-base-japanese-v2 \
--task-type text_embedding \
--start
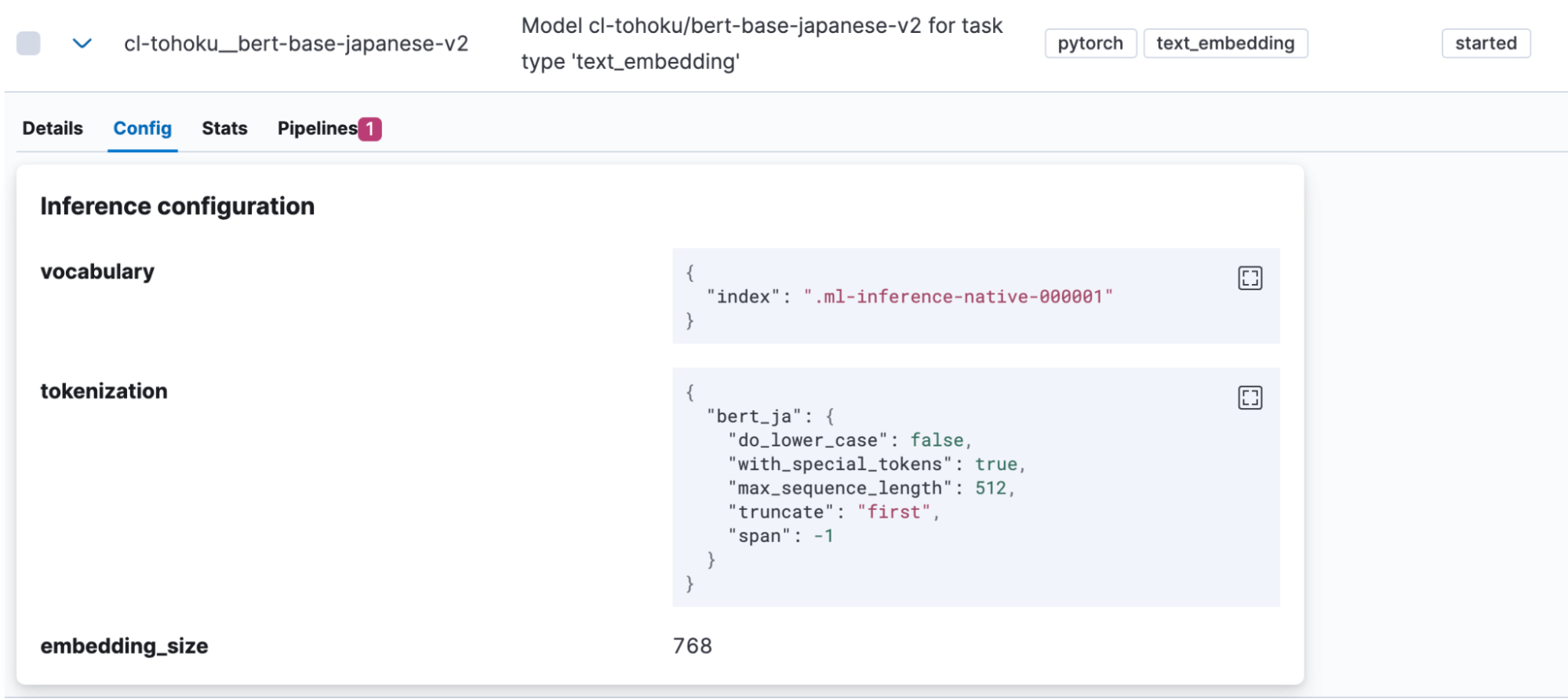
모델을 성공적으로 가져오면, Kibana의 머신 러닝 > 모델 관리 > 훈련된 모델에 표시됩니다. 모델 “Config(구성)” 탭을 열어 “bert_ja”가 토큰화에 사용되고 모델이 일본어를 처리하도록 올바르게 설정되었는지 확인하세요.
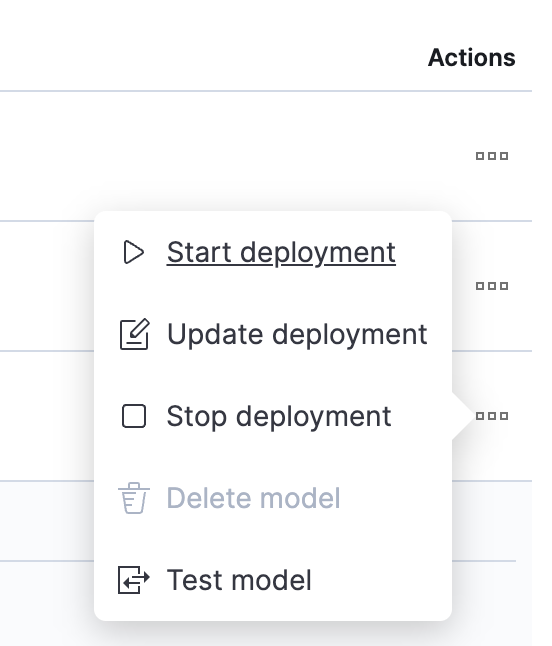
모델 업로드가 완료되면, 테스트해 보겠습니다. 메뉴를 열려면 Actions(작업) 열의 버튼을 클릭하세요.
“Test model(모델 테스트)”을 선택한 다음 “Input text(텍스트 입력)”에 일본어 문구를 입력하고 “Test(테스트)” 버튼을 클릭하세요.
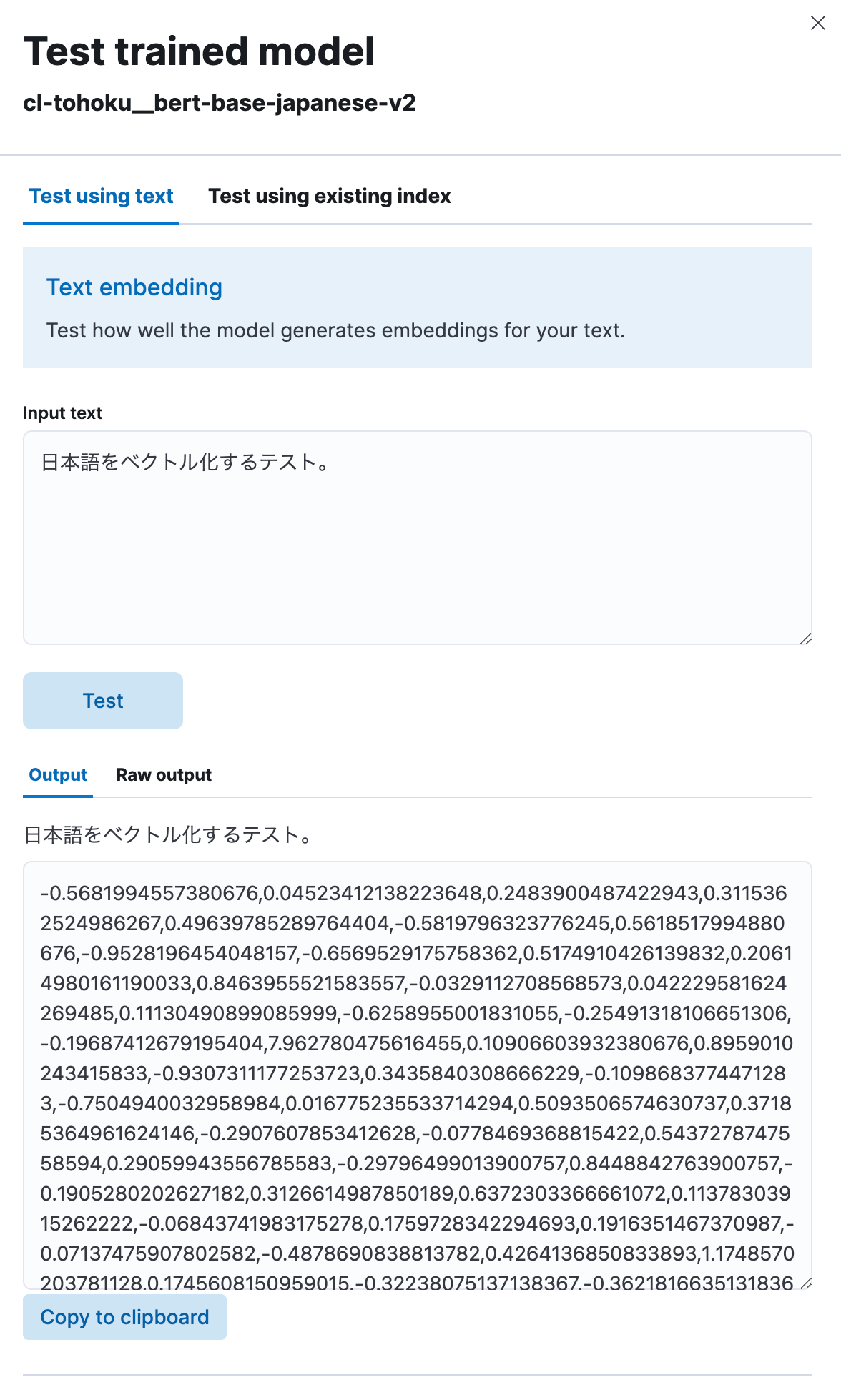
그러면 여기에 표시된 것처럼, 여러분이 입력한 일본어 텍스트를 모델이 숫자 스트링으로 벡터화한 것을 확인할 수 있습니다. 제대로 작동하는 것 같습니다.
벡터 임베딩을 사용하여 시맨틱 검색 구현
이제 모델이 업로드되었으므로, Elasticsearch에서 시맨틱 검색(벡터 검색) 기능을 구현할 수 있습니다.
먼저, 벡터 검색을 수행하려면, 일본어 원본 텍스트가 임베드된 벡터 값을 색인해야 합니다. 이를 위해, 앞서 업로드한 모델을 사용하여 일본어 텍스트를 인덱스에 입력하기 전에 벡터화하는 유추 프로세서가 포함된 파이프라인을 생성하겠습니다.
PUT _ingest/pipeline/japanese-text-embeddings
{
"description": "Text embedding pipeline",
"processors": [
{
"inference": {
"model_id": "cl-tohoku__bert-base-japanese-v2",
"target_field": "text_embedding",
"field_map": {
"title": "text_field"
}
}
}
],
"on_failure": [
{
"set": {
"description": "Index document to 'failed-<index>'",
"field": "_index",
"value": "failed-{{{_index}}}"
}
},
{
"set": {
"description": "Set error message",
"field": "ingest.failure",
"value": "{{_ingest.on_failure_message}}"
}
}
]
}
유추 프로세서를 사용하면, model_id에서 지정된 모델이 대상 필드(이 경우, title)에 저장된 텍스트에 적용되고 그 출력이 target_field에 저장됩니다. 또한 각 모델은 프로세스의 입력 값에 대해 서로 다른 필드(이 경우, text_field)를 기대합니다. 이러한 이유로, field_map은 프로세스 대상에 대한 실제 입력 필드와 ML 모델에서 예상하는 필드 이름 간의 대응 관계를 지정하는 데 사용됩니다.
파이프라인이 설정되면, 인덱스를 생성하는 데 사용할 수 있습니다. 벡터를 저장하려면 해당 인덱스에 필드가 필요하므로, 적절한 매핑을 정의하겠습니다. 아래 예에서, text_embedding.predicted_value 필드는 768차원의 dense_vector 데이터를 보유하도록 설정됩니다. 차원 수는 모델에 따라 다릅니다. Hugging Face(모델의 config.json에 있는 hidden_size 값) 또는 그 밖에 다른 곳에서 모델의 페이지를 확인하고 적절한 숫자를 설정하세요.
PUT japanese-text-with-embeddings
{
"mappings": {
"properties": {
"text_embedding.predicted_value": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "cosine"
}
}
}
}
검색 대상 일본어 텍스트 데이터가 포함된 인덱스가 이미 있는 경우, 재색인 API를 사용할 수 있습니다. 이 예에서, 원본 텍스트 데이터는 일본어 텍스트 인덱스에 있습니다. 해당 텍스트의 벡터화가 포함된 문서가 japanese-text-embeddings 인덱스에 등록됩니다.
POST _reindex?wait_for_completion=false
{
"source": {
"index": "japanese-text"
},
"dest": {
"index": "japanese-text-with-embeddings",
"pipeline": "japanese-text-embeddings"
}
}
또는 아래와 같이 생성된 파이프라인을 지정하고 이를 인덱스에 저장하여 테스트 목적으로 문서를 직접 등록할 수도 있습니다.
POST japanese-text-with-embeddings/_doc?pipeline=japanese-text-embeddings
{
"title": "日本語のドキュメントをベクトル化してインデックスに登録する。"
}
벡터화된 문서가 등록되면, 드디어 검색을 실행할 수 있습니다. kNN(k-최근접 유사 항목) 검색은 벡터를 활용하는 방법 중 하나입니다. 이제 표준 _search API의 query_vector_builder 옵션을 사용하여 kNN 벡터 검색을 실행하겠습니다. query_vector_builder를 사용하면, model_id에서 지정된 모델을 사용하여 model_text의 텍스트를 해당 텍스트가 임베드된 벡터가 포함된 쿼리로 변환할 수 있습니다.
GET japanese-text-with-embeddings/_search
{
"knn": {
"field": "text_embedding.predicted_value",
"k": 10,
"num_candidates": 100,
"query_vector_builder": {
"text_embedding": {
"model_id": "cl-tohoku__bert-base-japanese-v2",
"model_text": "日本語でElasticsearchを検索したい"
}
}
}
}
이 검색 쿼리가 실행되면, 다음과 같은 형태의 응답을 받습니다.
"hits": [
{
"_index": "japanese-text-with-embeddings",
"_id": "vOD6MIoBdRdLZd7EKaBy",
"_score": 0.82438844,
"_source": {
"title": "日本語のドキュメントをベクトル化してインデックスに登録する。",
"text_embedding": {
"predicted_value": [
-0.13586345314979553,
-0.6291824579238892,
0.32779985666275024,
0.36690405011177063,
(略、768次元のベクトルが表示される)
],
"model_id": "cl-tohoku__bert-base-japanese-v2"
}
}
}
]
검색 성공! 검색에는 일본어가 임베드된 필드도 포함됩니다. 대부분의 실제 사용 사례에서는, 이 텍스트를 응답에 포함할 필요가 없습니다. 이러한 경우에는, _source 매개변수 또는 다른 방법을 사용하여 응답에서 해당 정보를 제외하거나 다른 조치를 취하세요.
검색 순위를 미세 조정하기 위해, 벡터 검색과 표준 키워드 검색의 결과를 적절하게 혼합하는 상호 순위 결합(RRF) 기능이 출시되었습니다. 이 내용도 꼭 살펴보시기 바랍니다.
이것으로 벡터 검색을 사용하여 시맨틱 검색을 활성화하는 방법에 대한 논의를 마칩니다. 이 기능을 설정하려면 표준 검색보다 더 많은 작업이 필요할 수 있고 독특한 머신 러닝 용어를 접할 수도 있지만, 설정 단계가 완료되면 평소와 거의 동일한 방식으로 검색을 실행할 수 있습니다. 그러니 시도해 보세요.
텍스트 분류(정서 분석)
일본어에서 kNN을 사용하여 벡터 검색을 사용할 수 있다는 것을 살펴보았으므로, 다른 NLP 작업도 같은 방식으로 사용하는 방법을 살펴보겠습니다.
텍스트 분류는 텍스트 입력이 일종의 카테고리에 배치되는 작업입니다. 이 예에서는, 일본어 텍스트 입력이 긍정적인 정서를 동반하는지 아니면 부정적인 정서를 동반하는지 판단하는 Hugging Face의 정서 분석 모델(koheiduck/bert-japanese-finetuned-sentiment)을 사용하겠습니다. tokenizer_config.json을 보면, 이 모델도 word_tokenizer_type으로 mecab을 사용하므로, Elasticsearch의 bert_ja와 함께 사용할 수 있음을 알 수 있습니다.
이전과 마찬가지로, Eland를 사용하여 모델을 Elasticsearch로 가져옵니다.
!eland_import_hub_model \
--url "https://your.elasticserach" \
--es-api-key "your_api_key" \
--hub-model-id koheiduck/bert-japanese-finetuned-sentiment \
--task-type text_classification \
--start
모델을 성공적으로 가져오면, Kibana의 머신 러닝 > 모델 관리 > 훈련된 모델에 표시됩니다.
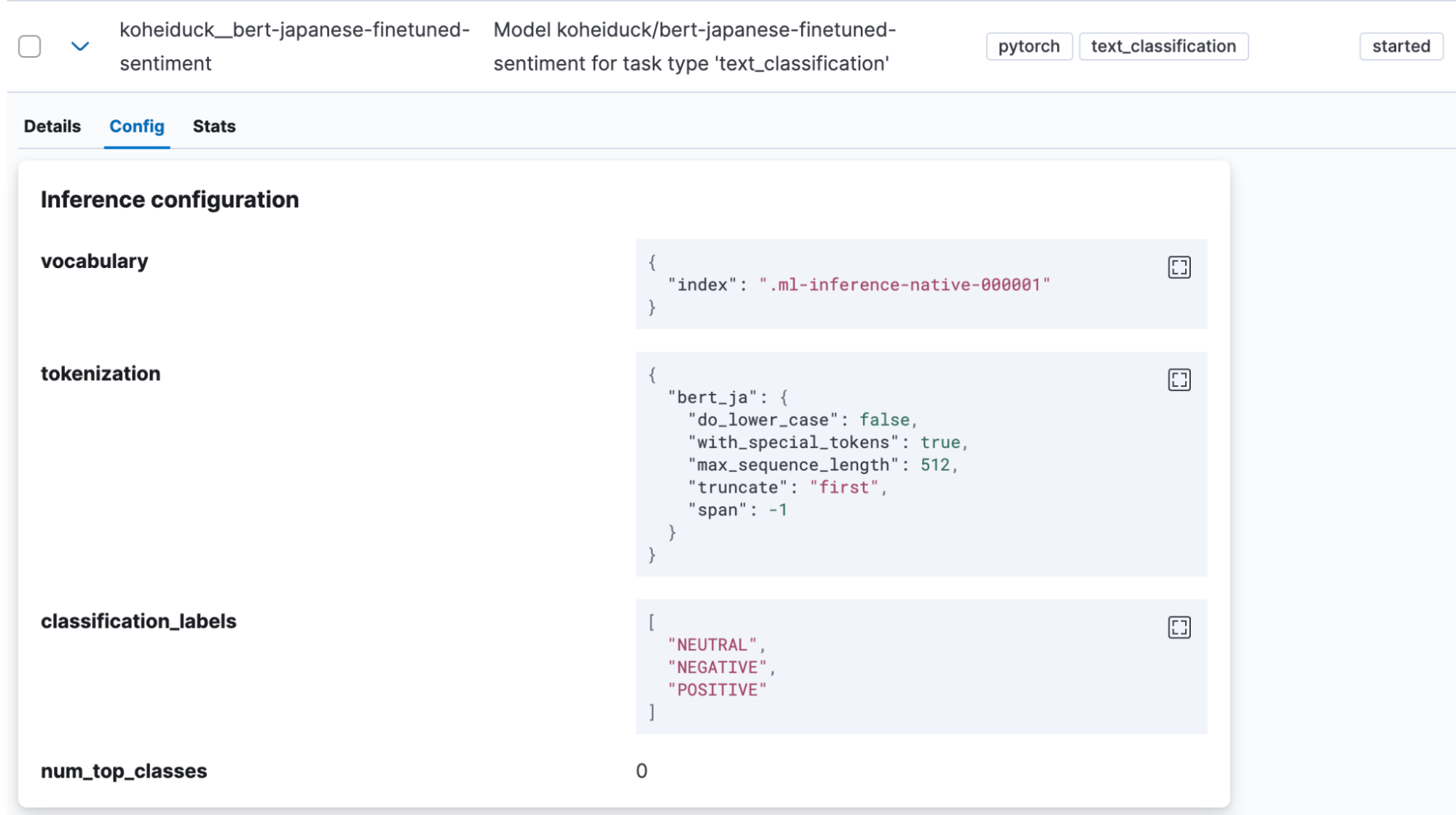
이 경우에도, Actions(작업) 메뉴에서 “Test model(모델 테스트)”을 클릭하세요.
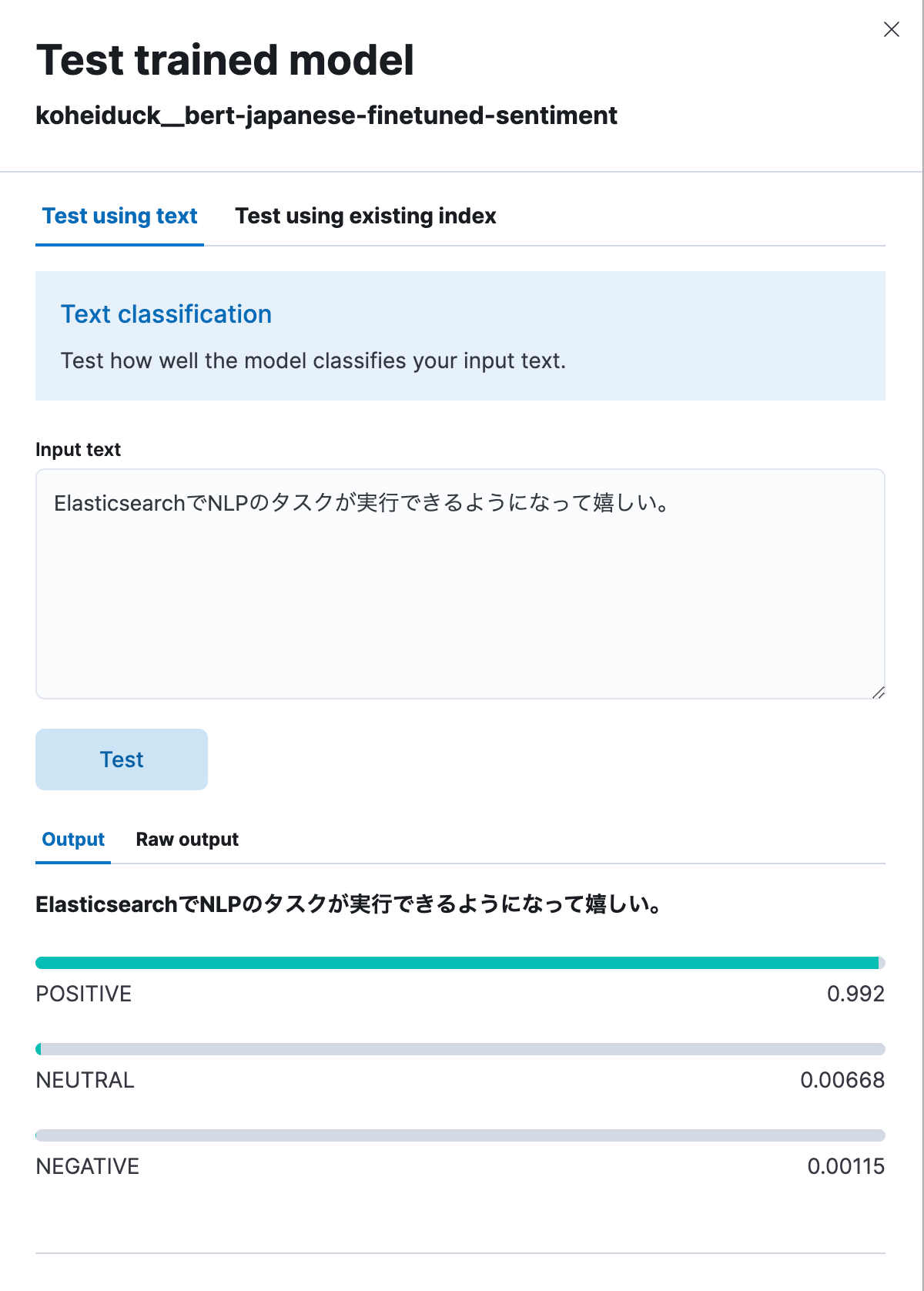
이전과 마찬가지로, 테스트용 대화상자가 표시됩니다. 여기에 분류할 텍스트를 입력하면, 해당 텍스트가 POSITIVE, NEUTRAL, NEGATIVE로 분류됩니다. 테스트로 다음을 입력해 보겠습니다. “I’m happy that I’m now able to execute NLP tasks with Elasticsearch.” (“이제 Elasticsearch로 NLP 작업을 실행할 수 있게 되어 기쁩니다.”) 아래와 같이 99.2%의 POSITIVE 결과가 나왔습니다.
아래는 API를 통해 실행되는 동일한 프로세스입니다.
POST _ml/trained_models/koheiduck__bert-japanese-finetuned-sentiment/_infer
{
"docs": [{"text_field": "ElasticsearchでNLPのタスクが実行できるようになって嬉しい。"}],
"inference_config": {
"text_classification": {
"num_top_classes": 3
}
}
}
응답은 다음과 같습니다.
{
"inference_results": [
{
"predicted_value": "POSITIVE",
"top_classes": [
{
"class_name": "POSITIVE",
"class_probability": 0.9921651090124636,
"class_score": 0.9921651090124636
},
{
"class_name": "NEUTRAL",
"class_probability": 0.006682728902566756,
"class_score": 0.006682728902566756
},
{
"class_name": "NEGATIVE",
"class_probability": 0.0011521620849697567,
"class_score": 0.0011521620849697567
}
],
"prediction_probability": 0.9921651090124636
}
]
}이 프로세스는 유추 프로세서로도 실행할 수 있으므로, 일본어 텍스트를 색인하기 전에 이러한 분석 결과를 첨부하는 것이 가능합니다. 예를 들어, 특정 제품에 대한 댓글 텍스트에 이 프로세스를 적용하면 해당 제품에 대한 사용자 평가를 숫자 값으로 변환하는 데 도움이 될 수 있습니다.
피드백
Elasticsearch 8.9 버전 기준으로, 일본어 NLP 모델 지원은 아직 기술 미리보기 단계에 있습니다. 버그를 발견하거나 BERT가 아닌 알고리즘이나 MeCab이 아닌 토크나이저 등에 대한 지원이 필요한 경우, Elastic®에 문의하세요.
GitHub Issue는 Elastic에 피드백을 보내는 가장 좋은 방법입니다. elastic/elasticsearch 리포지토리의 “Issues(문제)” 아래에, :ml 태그를 추가하고 요청을 제출하세요. 해당 팀이 조사를 할 것입니다.
Elastic의 컨설팅 아키텍트로서(따라서 개발팀 소속이 아닙니다), 저는 외부 기여자로 GitHub를 통해 수정을 하기 위해 풀 리퀘스트를 보내 일본어에 대한 지원을 추가할 수 있었습니다. 여러분이 개발자이고 특정 사용 사례에 추가를 요청하고 싶은 기능이 있는 경우, 제가 한 것처럼 시도해 보세요.
결론
현재 Elastic은 검색 기능에 머신 러닝을 사용하여 NLP 기능을 구현하는 데 많은 리소스를 투자하고 있으며, Elasticsearch에서 실행할 수 있는 기능이 점점 더 많아지고 있습니다. 그러나 대부분의 기능은 영어로 먼저 출시되고 다른 언어에 대해서는 제한적으로 지원됩니다.
그러나 일본어에 대한 지원을 제공하기로 결정되어 매우 기쁩니다. 이러한 새로운 Elasticsearch 기능이 여러분의 검색을 더욱 의미 있게 만드는 데 도움이 되기를 바랍니다.
이 포스팅에 설명된 기능의 릴리즈 및 시기는 Elastic의 단독 재량에 따릅니다. 현재 이용할 수 없는 기능은 정시에 또는 전혀 제공되지 않을 수도 있습니다.
이 블로그 포스팅에서, Elastic은 각 소유자가 소유하고 운영하는 서드파티 생성형 AI 도구를 사용했거나 참조했을 수 있습니다. Elastic은 서드파티 도구에 대한 어떠한 통제권도 없으며 당사는 그 내용, 작동 또는 사용에 대한 책임이나 법적 의무가 없고 이러한 도구의 사용으로 인해 발생할 수 있는 손실 또는 손상에 대해 책임을 지지 않습니다. 개인 정보, 민감한 정보 또는 기밀 정보와 함께 AI 도구를 사용할 때 주의하세요. 제출하신 모든 데이터는 AI 교육을 위해 또는 다른 목적으로 사용될 수 있습니다. 제공하시는 정보가 안전하게 유지되거나 기밀로 유지된다는 보장은 없습니다. 사용 전에 생성형 AI 도구의 개인 정보 보호 관행 및 사용 약관을 숙지하셔야 합니다.
Elastic, Elasticsearch, ESRE, Elasticsearch Relevance Engine 및 관련 마크는 미국 및 기타 국가에서 Elasticsearch N.V.의 상표, 로고 또는 등록 상표입니다. 기타 모든 회사 및 제품 이름은 해당 소유자의 상표, 로고 또는 등록 상표입니다.
공유하기
- Share on Twitter
트위터에서 공유하기
- Share on LinkedIn
링크드인에서 공유하기
- Share on Facebook
페이스북에서 공유하기
- Share by Email
이메일로 공유하기
- Print this page
인쇄하기