ベクトルデータベースとグラフデータベース:違いを理解する


 Share on Twitter
Share on TwitterTwitter

 Share on LinkedIn
Share on LinkedInリンクトイン

 Share on Facebook
Share on FacebookFacebook

 Share by Email
Share by Emailメール

 Print this page
Print this page印刷
ビッグデータの管理において重要なのは、できる限りたくさんのデータを格納することだけではなく、有用なインサイトを特定し、隠れたパターンを見つけ出し、情報に基づく意思決定を行うことができるようにすることです。この高度な分析を求める思いが、従来型のリレーショナルデータベースをはるかに超えるデータモデリングとストレージソリューションのイノベーションを推進する原動力となってきました。
こうしたイノベーションに、ベクトルデータベースとグラフデータベースの2つがあります。どちらもデータ管理の点で大幅に進歩しており、独自のデータ構造を備え、それぞれに異なる長所があります。しかし、実際のプロジェクトや目的に最適なものを効果的に選択するには、それらがどのように機能し、どのように異なるのかを理解しておく必要があります。
このブログ記事では、両者がどのように機能するのか、どのように似ているのか、そしてどのように大きく異なるのかを概説します。対照的なデータ構造を探り、それぞれの理想的なユースケースを探り、2つのデータ構造のどちらを選ぶかサポートします。選択しやすいように、説明をいくつかのセクションに分けています。
ベクトルデータベースの定義とコンセプト
グラフデータベースとは
ベクトルデータベースとグラフデータベースの比較
ベクトルデータベースとグラフデータベースのユースケース
ベクトルデータベースとグラフデータベースの選択
この記事を読み終える頃には、意思決定に必要なすべての情報を手に入れて、自社のデータを最大限に活用できるようになっていることと思います。
ベクトルデータベースの定義とコンセプト
行と列の代わりに、ベクトルデータベースは広大な多次元空間のポイントとしてデータを整理します。各ポイントは1つのデータを表し、場所は他のデータを基準にした相対的な特徴を表します。宇宙のようなものと考えてください。各惑星は1つのデータを表し、似ている惑星は近くに、類似性の少ない惑星は遠くに配置されています。
これは、データを高次元ベクトルとして格納することで実現されます。高次元ベクトルとは、データ特徴量の数値表現です。これらのベクトルはベクトルが表すデータの本質を捉え、そうすることで多次元空間内にエンコードして整理することができます。多次元空間内で2つのポイントが近いほど、基になっているデータが類似しています。
これがベクトルデータベースが類似性検索を得意としている理由です。ベクトルは類似性に基づいて構造化されているため、クエリベクトルに最も近いデータポイントをすばやく特定できるのです。そのため、次のような数多くの重要な用途に適しています。
画像・文書検索:キーワードだけでなく、コンテンツに基づいて類似画像を検索します。
パーソナライズされたレコメンデーション:ユーザーが過去に利用したことのある商品やコンテンツに類似したものをレコメンドします。
異常検知:不正やシステムエラーを示す可能性のある、標準から逸脱した異常なデータポイントを特定します。
機械学習:テキスト分析、画像分類、自然言語処理などのタスクで高次元データを効率的に処理・分析します。
もっと詳しいガイドが必要ですか?「ベクトルデータベースとは何か?をご覧ください。全体の概要をご紹介します。
グラフデータベースとは
一見すると似ているように見えるかもしれませんが、グラフデータベースはデータをまったく異なる方法で整理します。リレーショナルデータベースのように固定のテーブルを使ったり、ベクトルデータベースのように類似性でデータを整理したりせずに、グラフ構造でデータを格納します。エンティティはグラフ上のノードで表され、関係はエッジで表されます。マインドマップのようなものと考えてください。各ノードは人や場所、物を表す円で、それらの間の線(エッジ)はつながりを示します。
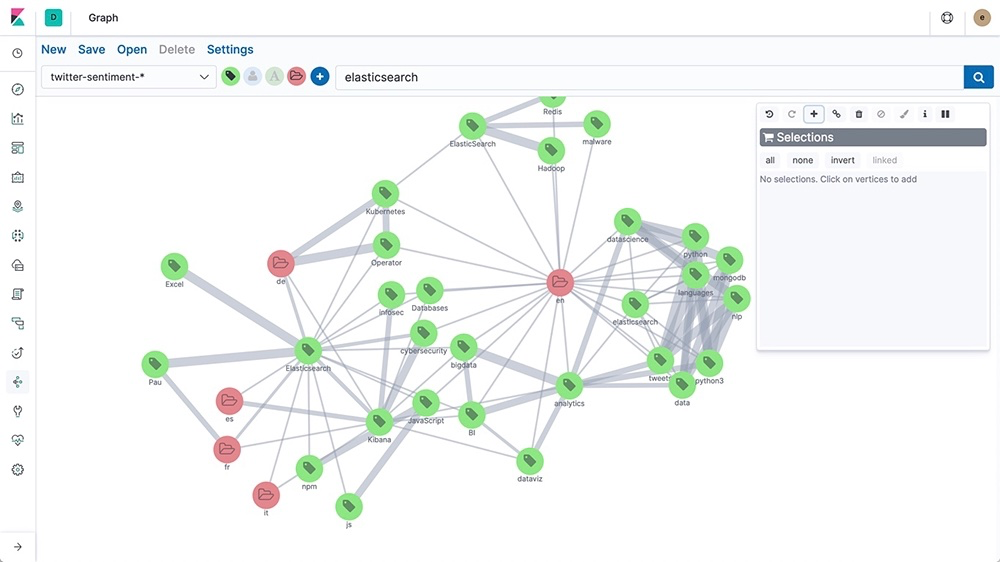
この種の構造の利点の一つは、複雑な関係をより自然に表現できることです。そのため、他のタイプのデータベースと比べて、つながりの把握が容易です。また、グラフデータベースはスキーマレス構造であるため、データの増加に合わせて新しいノードやエッジを簡単に追加できるという柔軟性とスケーラビリティを兼ね備えています。そのため、次のようなさまざまな用途に適しています。
リアルタイム分析:グラフデータベースを使用して、ストリーミングデータを分析し、将来の結果を予測し、動的なシステムをリアルタイムで最適化します。
マスターデータ管理:エンティティの統合ビューを作成し、あいまいさを解消し、相互に接続された単一のグラフ内でエンティティの進化を追跡します。
ネットワークの発見ネットワーク内の関係を分析することで、隠れたつながりを発見し、異常を特定し、連鎖的な障害を予測します。
知識グラフの構築インテリジェントな知識ベースを構築し、複雑な質問に答え、相互接続されたエンティティや概念を通じてインテリジェントなアプリケーションを強化します。
ベクトルデータベースとグラフデータベースの比較
ここまでで、各タイプのデータベースがどのようなもので、どのようなデータ構造になっているかを理解できたと思います。しかし、ベクトルデータベースとグラフデータベースの細かい相違点を理解することも大変重要です。その最も簡単な方法は、対照比較です。
| ベクトル検索 | グラフデータベース | |
| データ表現 | データは高次元空間のポイントとして構造化されます。互いに近いポイントはコンテンツが類似していることを表します。つながりや関係性に関係なく、データ自体が備えている類似性を取り込むのに適しています。 | データは相互接続されたノード(エンティティ)がエッジ(関係)でつながれているクモの巣のようなネットワークとして構造化されます。データポイント間のつながりと階層を表現することに重点を置き、エンティティ同士の関係性に関する有益なインサイトを提供します。 |
| クエリと検索 | 類似性検索を得意とし、クエリベクトルに似ているデータポイントを効率的に検索できます。コンテンツの類似性の把握が重要となる画像/ドキュメント検索などのタスクに適しています。 | 関係性やつながりを扱う場合に威力を発揮します。ネットワーク構造の効率的な走査を可能にし、ソーシャルネットワーク分析、レコメンデーションシステム、ナレッジグラフの探索に最適です。 |
| パフォーマンスとスケーラビリティ | 最適化された類似性検索アルゴリズムにより、一般的に大規模なデータセットでも難なく拡張できます。ただし、スキーマの変更によりデータの再埋め込みが必要になる場合があり、パフォーマンスに影響を与える可能性があります。 | スキーマレスという特性のため、柔軟性が高く、データの追加や変更が容易です。ただし、複雑なクエリや大規模なネットワークでは、パフォーマンスが低下し、慎重な最適化が必要になります。 |
ユースケース
ベクトルデータベースとグラフデータベースの違いをよりよく理解するために、同じ分野内でそれぞれがどのように活用できるかを比較してみましょう。そうすることで、相違点だけでなく、どのように併用すれば優れた成果を達成できる可能性があるかがわかります。
不正検知
ベクトルデータベース:取引パターンとユーザー情報を分析することで、不正な取引を特定します。学習された類似性プロファイルに基づき、支出習慣、購入場所、デバイス指紋の異常を検出します。
- グラフデータベース:つながりのある個人または取引の疑わしいネットワークを発見します。潜在的な不正行為に関与するエンティティ間の関係を分析することにより、不正行為を特定します。
科学的調査
ベクトルデータベース:タンパク質配列、遺伝子発現、化学物質のような複雑なデータ構造を分析します。多様なデータセットを比較し、多次元の特徴に基づいて類似点を特定することで、新たな科学的発見につながります。
- グラフデータベース:生物学的パスウェイや分子間相互作用をモデル化します。エンティティ間の複雑な関係を探索し、複雑なシステムを可視化することで、生物学的プロセスの理解を深めます。
eコマース
ベクトルデータベース:画像、テキスト説明、技術仕様などの製品属性を分析します。コンテンツの類似性に基づいて類似商品を推薦し、より適切で魅力的な提案を導きます。
- グラフデータベース:購入履歴、閲覧履歴、欲しいものリストなど、ユーザーと商品のやり取りをキャプチャします。同じような嗜好を持つユーザーとの類似性に基づいて商品を推薦し、よりパーソナライズされたショッピング体験を実現します。
メディア&エンターテインメント
ベクトルデータベース:音楽のジャンル、記事のトピック、映画のテーマなど、コンテンツの特徴を分析します。コンテンツ固有の類似性に基づいて、類似した曲、映画、記事を推薦します。
- グラフデータベース:視聴履歴、読書リスト、ソーシャルメディアでのシェアなど、ユーザーとコンテンツの関係を探索します。同じような興味を持つユーザー同士のつながりに基づいてコンテンツを推薦し、エンゲージメントと発見を促進します。
ベクトルデータベースとグラフデータベースの選択
この記事でお伝えしてきた情報だけでは、まだ適切なデータベースの選択は非常に難しい可能性があります。選びやすくなるように、目的達成に最適な決定を下すのに役立つフレームワークをご紹介します。
ステップ1. データを理解する
このプロセスではまず、データの複雑さを確認します。主に構造化データでしょうか、非構造化データでしょうか。込み入った関係や独立したエンティティを伴うデータでしょうか。
また、データ量やデータの予想増加速度も考慮する必要があります。その後で、データポイントを定義する具体的な特徴や属性、それらが数値かカテゴリかを決める必要があります。
ステップ2. 主なユースケースを特定する
簡単に言うと、データ分析からどのようなインサイトを得ることを望んでいるかということです。コンテンツに基づいて類似のデータポイントを見つけようとしていますか、エンティティ間の入り組んだつながりを探索しようとしていますか。どのようなクエリを頻繁に実行しますか。
ステップ3. パフォーマンスと拡張性のニーズ
3番目の手順では、目的を達成するうえでスピードとスケーラビリティがどれほど重要かを考えます。アプリケーションにとってリアルタイムの応答がどれほど大事でしょうか。データセットはどれくらい大規模でしょうか、予想されるクエリはどれくらい複雑でしょうか。また、予算による制約やリソースの制限も考慮する必要があります。
ステップ4.各テクノロジーの具体的なメリットを評価する
これらのデータベースタイプにはそれぞれの長所と短所があります。ベクトルデータベースは類似性検索に最適で、高次元データを効率的に処理し、大規模なデータセットをうまく処理できます。グラフデータベースは関係性の扱いが得意で、複雑なネットワーク分析で威力を発揮し、柔軟性の高いスキーマを備えています。
データの可能性をすべて引き出す
ビッグデータを扱うには強力なツールが必要で、ベクトルデータベースとグラフデータベースはこの情報領域における革新的なツールです。それでも、ニーズに適したモデルの選択は難しく感じられることがあります。
上記の項目を注意深く評価し、各テクノロジーのそれぞれの長所を把握しましょう。最終的には、データの可能性をすべて引き出すのに適したデータベースモデルの選択に役立つ、意思決定の情報源となる項目のリストが得られます。
次のアクション
準備ができたら、ビジネスに優れた検索エクスペリエンスをもたらすための次の4つのステップに進みましょう。
無料トライアルを開始して、Elasticがビジネスにどのように役立つのかを実感してください。
ソリューションのツアーを参考に、Elasticsearch Platformの仕組みと、ソリューションがニーズにフィットする仕組みをご確認ください。
興味を持ってくれそうな方とこの記事を共有してください。メール、LinkedIn、X(旧Twitter)、Facebookで共有できます。
本記事に記述されているあらゆる機能ないし性能のリリースおよびタイミングは、Elasticの単独裁量に委ねられます。現時点で提供されていないあらゆる機能ないし性能は、すみやかに提供されない可能性、または一切の提供が行われない可能性があります。
このブログ記事では、それぞれのオーナーが所有・運用するサードパーティの生成AIツールを使用したり、参照している可能性があります。Elasticはこれらのサードパーティのツールについていかなる権限も持たず、これらのコンテンツ、運用、使用、またはこれらのツールの使用により生じた損失や損害について、一切の責任も義務も負いません。個人情報または秘密/機密情報についてAIツールを使用する場合は、十分に注意してください。提供したあらゆるデータはAIの訓練やその他の目的に使用される可能性があります。提供した情報の安全や機密性が確保される保証はありません。生成AIツールを使用する前に、プライバシー取り扱い方針や利用条件を十分に理解しておく必要があります。
Elastic、Elasticsearch、ESRE、Elasticsearch Relevance Engine、および関連するマークは、米国およびその他の国におけるElasticsearch N.V.の商標、ロゴ、または登録商標です。他のすべての会社名および製品名は、各所有者の商標、ロゴ、登録商標です。
シェアする
- Share on Twitter
Twitter
- Share on LinkedIn
リンクトイン
- Share on Facebook
Facebook
- Share by Email
メール
- Print this page
印刷