Qu'est-ce que la classification de textes ?
Définition de la classification de textes
La classification de textes est un type de Machine Learning qui catégorise les documents texte et les phrases en classes ou catégories prédéfinies. Elle analyse le contenu et la signification du texte, puis utilise l'étiquetage de texte pour lui attribuer l'étiquette la plus appropriée.
Les applications concrètes de la classification de textes comprennent l'analyse des sentiments (qui détermine les sentiments positifs ou négatifs dans les avis), la détection de spams (par exemple, repérer les courriers indésirables) et la catégorisation par sujet (par exemple organiser des articles de journaux en sujets pertinents). La classification de textes joue un rôle important dans le traitement du langage naturel (NLP) en permettant aux ordinateurs de comprendre et d'organiser de grosses quantités de texte non structuré. Cela simplifie les tâches telles que le filtrage du contenu, les systèmes de recommandations et l'analyse des commentaires clients.
Types de classification de textes
Parmi les types de classification de texte que vous pouvez rencontrer :
L'analyse du sentiment du texte détermine le sentiment ou l'émotion exprimés dans un texte, généralement catégorisés comme positifs, négatifs ou neutres. Il est utilisé pour produire des avis, des publications sur les réseaux sociaux et des commentaires clients.
La détection de la toxicité, associée à l'analyse du sentiment du texte, identifie le langage offensant ou nuisible en ligne. Elle aide les modérateurs de communautés en ligne à maintenir un environnement numérique respectueux dans les discussions en ligne, les commentaires ou les publications sur les réseaux sociaux.
La reconnaissance de l'intention est un autre sous-ensemble de l'analyse du sentiment du texte, utilisé pour comprendre l'objectif (ou l'intention) qui se cache derrière le texte d'un utilisateur. Les chatbots et les assistants virtuels utilisent souvent la reconnaissance de l'intention pour répondre aux requêtes des utilisateurs.
La classification binaire catégorise le texte en une ou deux classes ou catégories. Un exemple courant est la détection de spams, qui classe le texte, tels que des e-mails ou messages, dans des catégories spam ou courrier légitime, afin de filtrer automatiquement le contenu non désiré ou potentiellement nuisible.
La classification multiclasses catégorise le texte en trois classes ou catégories distinctes ou plus. Cela facilite l'organisation et la récupération d'informations à partir de contenus tels que des articles de journaux, des articles de blog ou des documents de recherche.
La catégorisation par sujet, liée à la classification multiclasses, regroupe des documents ou des articles en sujets ou thèmes prédéfinis. Des articles de journaux peuvent par exemple être catégorisés en sujets comme la politique, le sport ou le divertissement.
L'identification de la langue détermine la langue dans laquelle un texte est écrit. Cette identification est utile dans des contextes multilingues et des applications basées sur la langue.
La reconnaissance d'entités nommées se concentre sur l'identification et la classification d'entités nommées au sein d'un texte, comme le nom de personnes, les organisations, les lieux et les dates.
La classification des questions catégorise les questions sur la base du type de réponse attendue, ce qui peut s'avérer utile pour les moteurs de recherche et les systèmes de réponses aux questions.
Processus de classification de textes
Le processus de classification de textes implique plusieurs étapes, de la collecte de données au déploiement du modèle. Voici un aperçu de son fonctionnement :
1e étape : collecte de données
Collectez un ensemble de documents textes avec leurs catégories correspondantes pour le processus d'étiquetage de texte.
2e étape : prétraitement des données
Nettoyez et préparez les données de texte en supprimant les symboles non nécessaires, en convertissant en minuscules et en gérant les caractères spéciaux tels que la ponctuation.
3e étape : conversion en tokens
Divisez le texte en tokens, c'est-à-dire de petites unités telles que des mots. Les tokens aident à trouver des correspondances et des connexions en créant des parties pouvant être recherchées de façon individuelle. Cette étape est particulièrement utile pour la recherche vectorielle et la recherche sémantique, qui délivrent des résultats basés sur l'intention de l'utilisateur.
4e étape : extraction des caractéristiques
Convertissez le texte en représentations numériques que les modèles de Machine Learning peuvent comprendre. Certaines méthodes courantes comprennent le fait de compter les occurrences des mots (également connu sous le nom de sac de mots) ou d'utiliser des plongements lexicaux pour capturer la signification des mots.
5e étape : entraînement des modèles
Maintenant que les données sont propres et prétraitées, vous pouvez les utiliser pour entraîner un modèle de Machine Learning. Le modèle apprendra des schémas et associations entre les caractéristiques du texte et leurs catégories. Cela l'aide à comprendre les conventions d'étiquetage de texte grâce aux exemples pré-étiquetés.
6e étape : étiquetage du texte
Créez un nouvel ensemble de données séparées pour commencer à étiqueter le texte et à classifier de nouveaux textes. Lors du processus d'étiquetage de texte, le modèle sépare le texte en catégories prédéterminées lors de l'étape de collecte des données.
7e étape : évaluation du modèle
Observez de près les performances du modèle entraîné lors du processus d'étiquetage de texte pour voir s'il peut classifier facilement le texte inconnu.
8e étape : réglage des hyperparamètres
En fonction de l'évaluation du modèle, vous devrez peut-être ajuster les paramètres du modèle afin d'optimiser ses performances.
9e étape : déploiement du modèle
Utilisez le modèle entraîné et ajusté pour classifier de nouvelles données de texte dans leurs catégories appropriées.
Pourquoi la classification de textes est-elle importante ?
La classification de textes est importante, car elle permet aux ordinateurs de catégoriser et de comprendre automatiquement de larges volumes de données textuelles. Dans notre monde numérique, nous rencontrons constamment d'énormes quantités d'informations textuelles. Pensez notamment aux e-mails, aux réseaux sociaux, aux avis et plus encore. La classification de textes permet aux machines d'organiser ces données non structurées en groupes qui ont du sens, à l'aide d'étiquetage de texte. En comprenant le contenu incompréhensible, la classification de textes améliore l'efficacité, facilite la prise de décision et améliore l'expérience utilisateur.
Cas d'utilisation de la classification de textes
Les cas d'utilisation de classification de textes couvrent toute une variété d'environnements professionnels. En voici quelques exemples concrets :
- Automatiser et catégoriser les tickets de support client technique, les classer par ordre de priorité et les diriger vers les bonnes équipes pour qu'ils soient résolus.
- Analyser les commentaires des utilisateurs, les réponses aux enquêtes et les discussions en ligne pour détecter les tendances du marché et les préférences des consommateurs.
- Suivre les mentions sur les réseaux sociaux et les avis en ligne pour monitorer la réputation de votre marque et le sentiment qu'elle suscite.
- Organiser et taguer du contenu sur les sites web et les plateformes d'e-commerce en utilisant l'étiquetage de texte ou les tags pour faciliter la découverte de contenus, ce qui améliore les expériences utilisateur des clients.
- Identifier les pistes commerciales potentielles à partir des réseaux sociaux et autres sources en ligne sur la base de mots-clés et critères spécifiques.
- Analyser les avis et commentaires concernant vos concurrents pour glaner des informations sur leurs forces et leurs faiblesses.
- Segmenter vos clients sur la base de leurs interactions et commentaires en utilisant l'étiquetage du texte pour adapter les stratégies marketing et les campagnes.
- Détecter les activités et transactions frauduleuses dans vos systèmes financiers sur la base de modèles d'étiquetage du texte et d'anomalies (également connu sous le nom de détection des anomalies).
Techniques et algorithmes pour la classification de textes
Voici quelques techniques et algorithmes utilisés pour la classification de textes :
- Le sac de mots (Bag-of-Words – BoW) est une technique simple qui compte les occurrences des mots sans prendre leur ordre en compte.
- Les plongements lexicaux utilisent diverses techniques qui convertissent les mots en représentations numériques placées dans un espace multidimensionnel, capturant ainsi les relations complexes entre les mots.
- Les arbres de décision sont des algorithmes de Machine Learning qui créent une structure en forme d'arbre de nœuds et feuilles de décision. Chaque nœud teste la présence d'un mot, ce qui aide l'arbre à apprendre les modèles des données textuelles.
- La forêt aléatoire est une méthode qui associe plusieurs arbres décisionnels pour améliorer la précision de la classification de textes.
- BERT (Bidirectional Encoder Representations from Transformers) est un modèle de classification sophistiqué basé sur les transformateurs, qui peut comprendre le contexte des mots.
- Naive Bayes calcule la probabilité qu'un document donné appartienne à une classe en particulier sur la base de l'occurrence de mots dans le document. Il estime la probabilité de l'apparition de chaque mot dans chaque classe et associe ces probabilités à l'aide du théorème de Bayes (un théorème fondamental dans la théorie des probabilités) pour formuler des prédictions.
- SVM (Support Vector Machine) est un algorithme de Machine Learning utilisé pour les tâches de classification binaires et multiclasses. SVM recherche l'hyperplan qui sépare le mieux les points de données des différentes classes dans un espace de description à haute dimensionnalité. Cela aide à formuler des prédictions précises sur de nouvelles données textuelles inconnues.
- TF-IDF (Term Frequency-Inverse Document Frequency) est une méthode qui mesure l'importance des mots dans un document par rapport à l'intégralité de l'ensemble des données.
Indicateurs d'évaluation dans la classification de textes
Les indicateurs d'évaluation dans la classification de textes servent à mesurer les performances du modèle de diverses façons. Parmi les indicateurs d'évaluation les plus courants :
Exactitude
La proportion d'exemples de textes correctement classifiés parmi le nombre total d'exemples. Elle donne une mesure globale de l'exactitude du modèle.
Précision
La proportion d'exemples positifs correctement prédits parmi tous les exemples positifs prédits. Elle indique combien de cas positifs prédits étaient réellement corrects.
Rappel (ou sensibilité)
La proportion d'exemples positifs correctement prédits parmi tous les exemples réellement positifs. Il mesure si le modèle identifie bien les cas positifs.
Score F1
Une mesure équilibrée qui associe la précision et le rappel, et vous donne une évaluation globale des performances du modèle lorsqu'il rencontre des classes déséquilibrées.
L'aire sous la courbe ROC (AUC-ROC)
Une représentation graphique de la capacité du modèle à distinguer différentes classes. Cette représentation est particulièrement pratique dans le cas d'une classification binaire.
Matrice de confusion
Un tableau qui affiche le nombre de vrais positifs, de vrais négatifs, de faux positifs et de faux négatifs. Il fournit une analyse détaillée des performances de votre modèle.
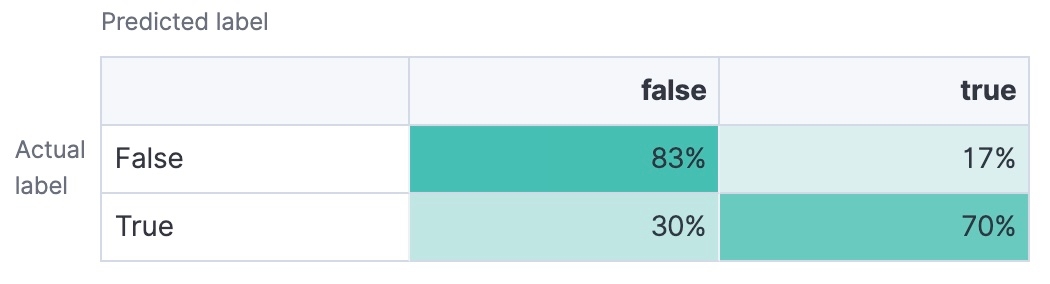
Au final, votre objectif doit être de choisir un modèle de classification de textes dont l'exactitude, la précision, le rappel et le score F1 sont très élevés, en fonction de vos besoins particuliers. L'AUC-ROC et la matrice de confusion peuvent également offrir des informations exploitables concernant la capacité de votre modèle à gérer différents seuils de classification, et vous fournir une meilleure compréhension de ses performances.
Tendances à venir de la classification de textes
Les tendances à venir de la classification de textes vont de l'IA ouverte aux outils propres au secteur. À mesure que la technologie de Machine Learning se développera, les capacités de classification de textes feront de même. Par exemple, à mesure que les outils et la technologie de pointe deviendront de plus en plus accessibles, ils devront également se diversifier. Nous verrons bientôt émerger la classification de textes multilingues pour prendre en charge le besoin grandissant de support technique multilingue dans les applications globales, qui analysera plusieurs langues dans le même ensemble de données. La classification de textes spécifiques au domaine devrait également commencer à augmenter, parallèlement aux modèles qui seront entraînés à fournir des classifications plus spécifiques, et donc plus précises, adaptées aux secteurs d'activité juridique, médical ou financier par exemple.
Bien entendu, les tendances de classification de texte joueront un rôle dans les nouvelles capacités de l'IA. À mesure que les applications d'IA se répandent, il existe un besoin croissant de modèles de classification de textes transparents et interprétables. L'IA explicable implique d'incorporer des méthodes d'explicabilité pour comprendre le raisonnement qui se cache derrière les prédictions des modèles.
Les modèles de Deep Learning – comme les CNN (réseaux de neurones à convolution) et les RNN (réseaux de neurones récurrents) – ainsi que les modèles hybrides sont des architectures de réseaux de neurones appliquées à la classification de textes. Les CNN sont utilisés principalement pour les tâches de traitement d'images, et les RNN sont conçus pour gérer les données séquentielles, mais les deux ont démontré la capacité de bien comprendre les modèles de texte. Les modèles hybrides associent plusieurs architectures (tels que les CNN, les RNN et les modèles basés sur les transformateurs tels que BERT) pour exploiter les avantages des différentes approches dans le but de mieux classifier les textes.
De futures recherches pourront également explorer les techniques qui permettent aux modèles de classification de texte d'apprendre en faisant appel à moins d'exemples étiquetés (apprentissage few-shot), ou même de réaliser une classification de textes dans des classes inconnues lors de l'entraînement (entraînement zero-shot). Les deux ont le potentiel de réduire considérablement la dépendance vis-à-vis des ensembles de données fort étiquetés, ce qui rendra la classification de textes plus scalable et adaptable aux nouvelles tâches.
Classification de textes avec Elastic
La classification de texte est l'une des nombreuses fonctionnalités de traitement du langage naturel que vous trouverez dans les solutions de recherche d'Elastic. Grâce à Elasticsearch, vous pourrez classifier vos données non structurées, en extraire des informations et les appliquer rapidement et facilement aux besoins de votre entreprise.
Que vous en ayez besoin pour la recherche, l'observabilité ou la sécurité, Elastic vous laisse tirer parti de la classification de textes pour extraire et organiser des informations de façon plus efficace pour votre entreprise.