Nouveautés d'Elastic Observability 7.11 : la bibliothèque de logging d'ECS et la page d'aperçu de l'intégrité des services dans APM en disponibilité générale
Nous avons le plaisir de vous présenter la version 7.11 d'Elastic Observability qui comprend plusieurs fonctionnalités accélérant les workflows d'investigation, mais aussi diminuant le temps moyen d'accès aux informations et le temps moyen de résolution dans tous les cas d'utilisation d'observabilité. La nouvelle page d'aperçu des services proposée dans Elastic APM regroupe les principaux aspects de l'intégrité des services dans une seule vue. Ainsi, les développeurs et les ingénieurs de fiabilité peuvent rapidement résoudre les problèmes liés aux services et identifier leur cause première avec très peu de changements de contexte. De même, l'application Metrics ajoute une vue améliorée présentant l'intégrité de l'hôte dans un seul panneau facilement accessible, ce qui rationalise les workflows de résolution des problèmes et le monitoring de l'infrastructure. Enfin, les bibliothèques de logging d'Elastic Common Schema (ECS), qui injectent automatiquement du contexte de trace dans les logs d’application afin de permettre la corrélation des logs et des traces, sont désormais en disponibilité générale.
Découvrez la dernière version d'Elastic Observability grâce à notre Elasticsearch Service sur Elastic Cloud (dont un essai gratuit de 14 jours est proposé) ou en installant la dernière version de la Suite Elastic pour vivre une expérience autogérée.
Et maintenant, sans plus attendre, voici quelques points forts de cette version.
Aperçu de l'intégrité des services dans Elastic APM accélérant l'analyse de la cause première d'un problème et sa résolution
Les applications modernes natives sur le cloud comprennent souvent des dizaines ou des centaines de microservices. La capacité à déterminer rapidement l'état d'un service individuel est essentielle au déroulement des enquêtes sur les incidents. En outre, elle peut aider à diminuer le temps moyen d'accès aux informations et le temps moyen de résolution. Par exemple, grâce à une carte indiquant les services, vous pouvez plus facilement relier un problème d'application à un service spécifique. Or, dans ce cas, vous devez identifier le service au fonctionnement anormal. Dans la version 7.11, nous proposons une toute nouvelle page d’aperçu des services qui résume en un seul endroit toutes les informations sur l’état d’un service et permet aux développeurs et aux SRE de répondre aux questions suivantes sur une page :
- Quel impact un nouveau déploiement a-t-il eu sur les performances ?
- Quelles ont été les principales transactions touchées ?
- Les back-end ou les services en aval ont-ils entraîné une régression ?
- Quelle est la corrélation entre les performances et l'infrastructure sous-jacente ? Quelles instances (conteneurs et machines virtuelles) sont-elles touchées par les problèmes de performance ?
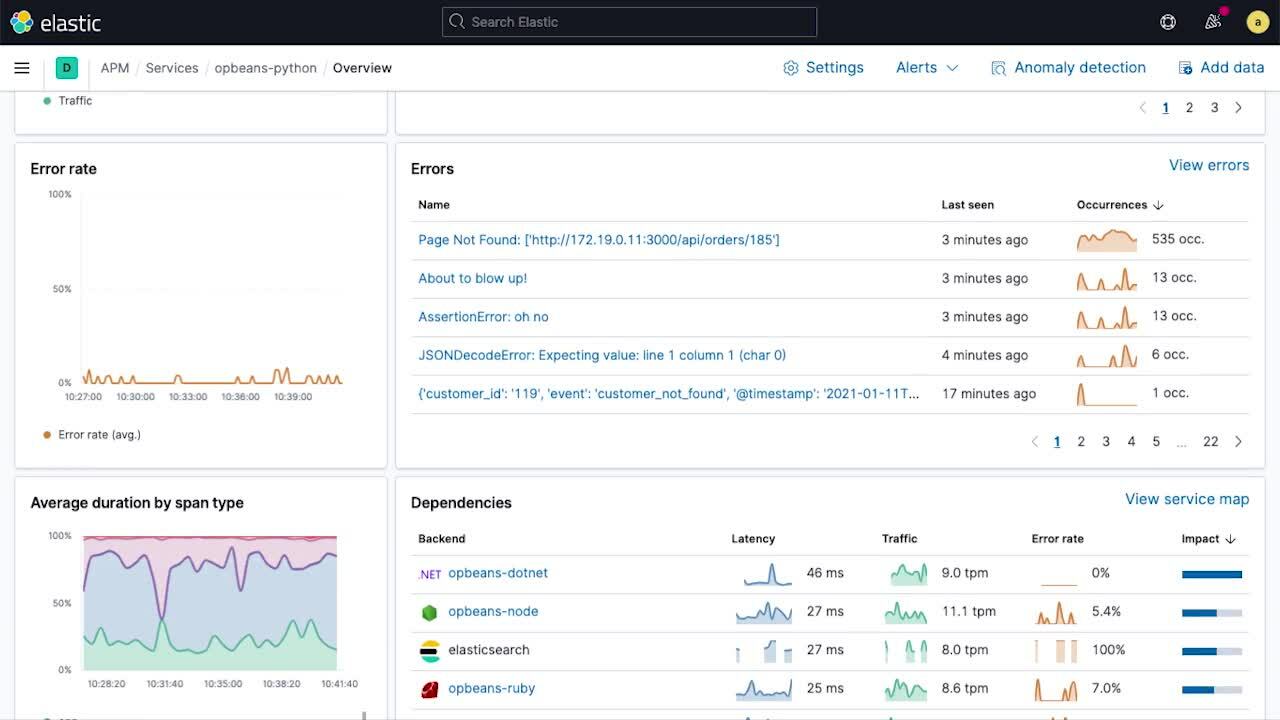
Les graphiques des séries temporelles affichant la latence du service, le trafic et le taux d’erreur confèrent une vue d’ensemble des indicateurs clés de performance du service dans le temps. Des annotations superposées (marqueurs de déploiement, alertes d’anomalie, etc.) sur les graphiques fournissent un contexte riche en événements clés qui pourraient avoir contribué à des changements de comportement. Grâce à ces annotations, vous pouvez immédiatement réduire la portée des investigations et ainsi bénéficier d'un chemin de résolution (par exemple, une restauration).
Les lignes de tendance de la page d'aperçu des services donnent une vue compacte des tendances temporelles des sous-composants. Ainsi, il est facile de repérer les changements de comportement inhabituels (par exemple, un pic d'un taux d'erreur lors d'une transaction spécifique) et de mettre au jour les "prochaines étapes" appropriées dans le cadre d'une investigation. La page d’aperçu des services en indique également l'intégrité, en fonction des instances de l’infrastructure (par exemple, des conteneurs) sur lesquelles le service est déployé, ce qui permet de relier facilement les questions aux problèmes de l’infrastructure sous-jacente.
La version 7.11 constitue la première étape dans cette nouvelle vue de l'intégrité des services. Les prochaines versions apporteront un contexte et des vues supplémentaires afin de rationaliser et d’accélérer les processus de résolution et d’analyse des causes profondes.
Résolution des problèmes d'infrastructure plus rapide grâce à une nouvelle vue détaillée sur les hôtes
Dans l'application Metrics, la carte thermique des ressources donne une vue à 360° de l'état de votre infrastructure. Vous pouvez donc facilement repérer les ressources perturbées (par exemple, les hôtes dont le processeur affiche des pics d'utilisation) et limiter les prochaines étapes d'une investigation grâce à l'identification des hôtes nécessitant une inspection plus poussée. Nous proposons une nouvelle vue d'ensemble de l'application Metrics permettant de prendre de la hauteur et d'obtenir une tendance historique des principaux indicateurs pour chaque hôte.
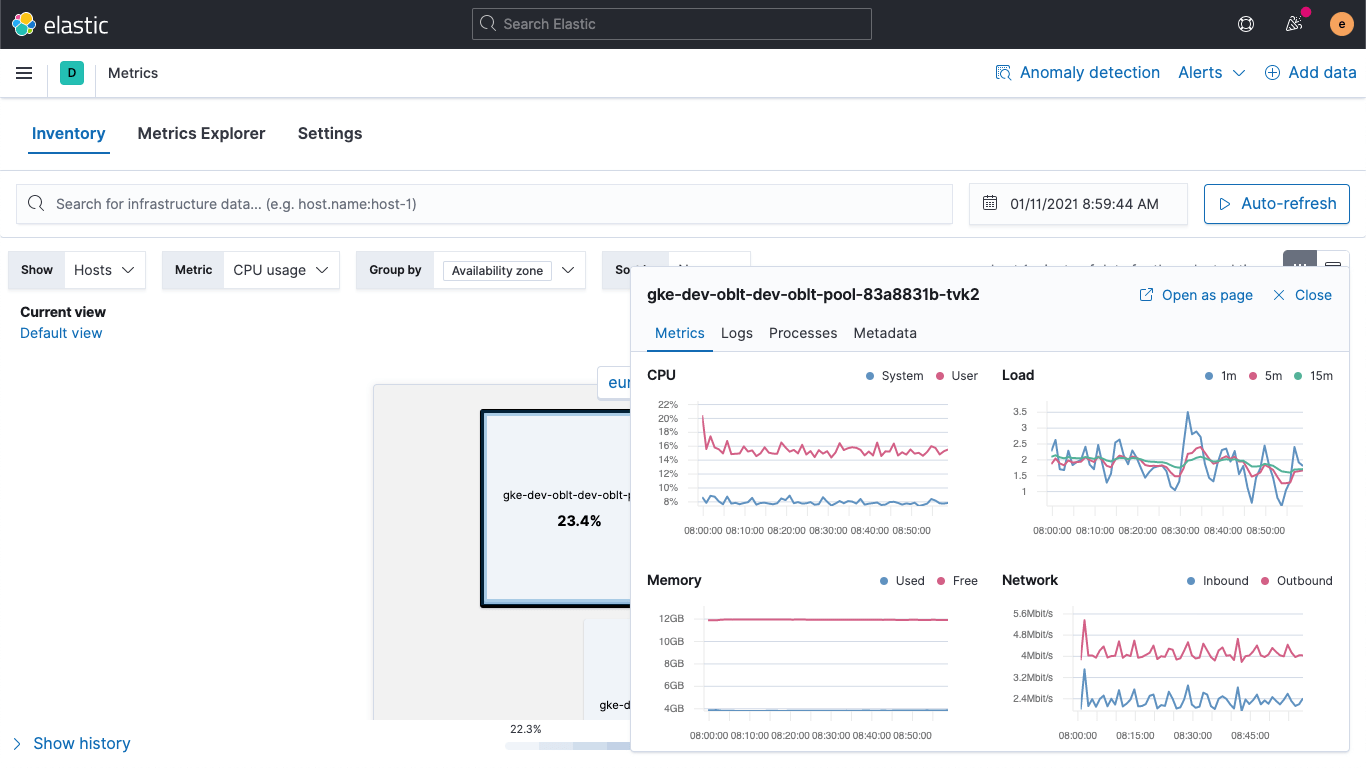
À l'instar de la nouvelle page de destination des services dans APM regroupant toutes les tendances, la nouvelle vue détaillée sur les hôtes accélère l'analyse de la cause première des problèmes en consolidant dans une vue unique toutes les informations sur un hôte (logs, indicateurs, processus, etc.) dont vous avez besoin. Ainsi, les équipes en charge des opérations des infrastructures peuvent facilement monitorer ces dernières et résoudre leurs problèmes.
Un clic sur la carte thermique fait apparaître une fenêtre contextuelle qui présente des informations clés, notamment :
- des diagrammes temporels des principaux indicateurs de l’hôte (processeur, mémoire, réseau, etc.) ;
- les logs générés par l’hôte ou les services qu'il exécute ;
- les principaux processus exécutés sur l’hôte (en fonction du processeur ou de la mémoire) ;
- des métadonnées de l’hôte (système d'exploitation, informations sur le fournisseur cloud) ;
- des liens pour obtenir davantage d'informations détaillées concernant les traces ou des données de disponibilité.
La version 7.11 propose pour la première fois cette vue améliorée dédiée aux hôtes et aux machines virtuelles. Les prochaines versions fourniront cette fonctionnalité pour d'autres types de ressources (les pods, les conteneurs, etc.) dans l'application Metrics.
Pour en savoir plus sur la page d'aperçu des services et les autres fonctionnalités APM inédites, consultez la documentation consacrée aux nouveautés de la version 7.11.
Bibliothèques de logging d'ECS approfondissant l'observabilité des applications grâce à la mise en relation automatique de leurs logs et leurs traces
La capacité à corréler des logs et des traces de l’application, puis à naviguer entre eux sans perdre le contexte est essentielle pour le dépannage des applications. Quels logs correspondent à une trace spécifique ? Quelle trace les a générés ? Quelle demande d'application a entraîné la création de ces logs ? Les bibliothèques de logging d’Elastic Common Schema (ECS), désormais en disponibilité générale dans la version 7.11, facilitent pour les développeurs d’applications l'injection automatique du contexte de trace capturé par l’agent APM dans leurs logs d’application, ce qui permet la corrélation des logs et des traces nécessaire à une analyse rationalisée.
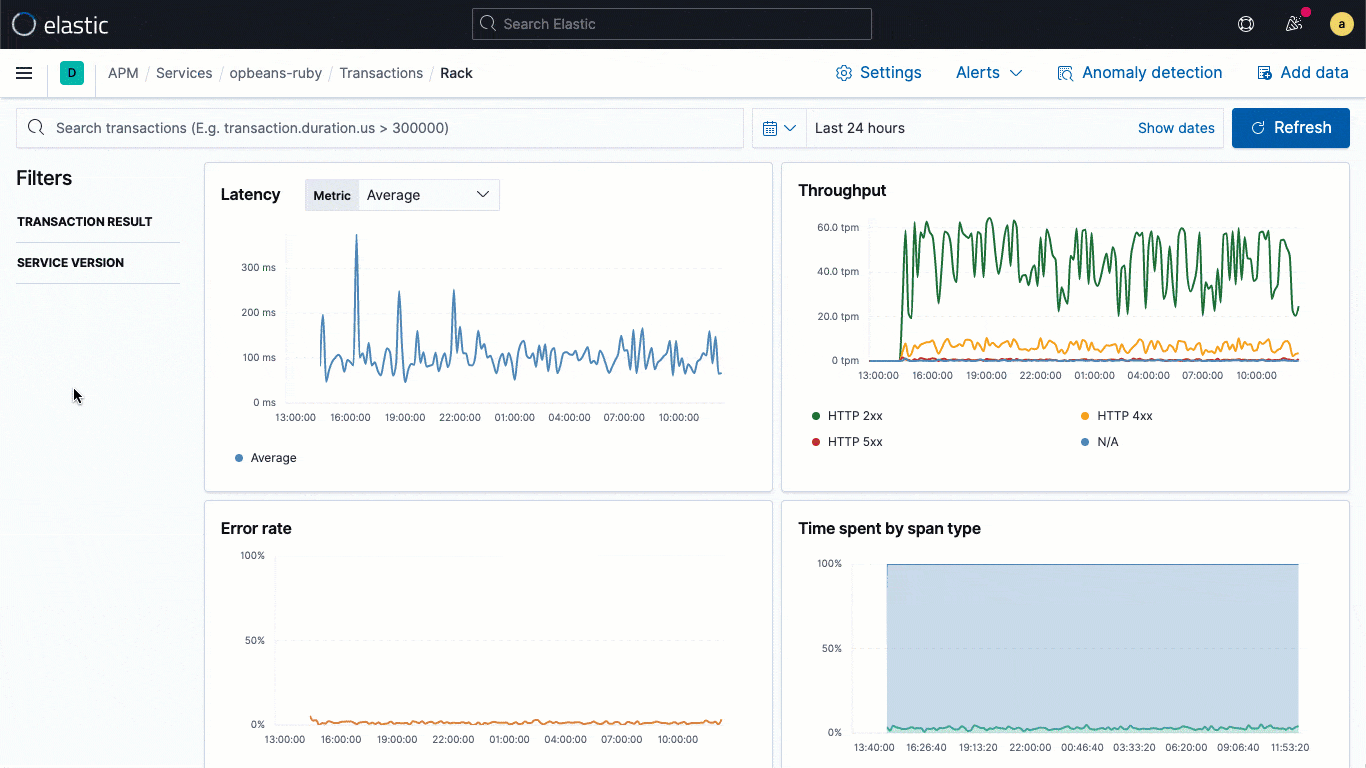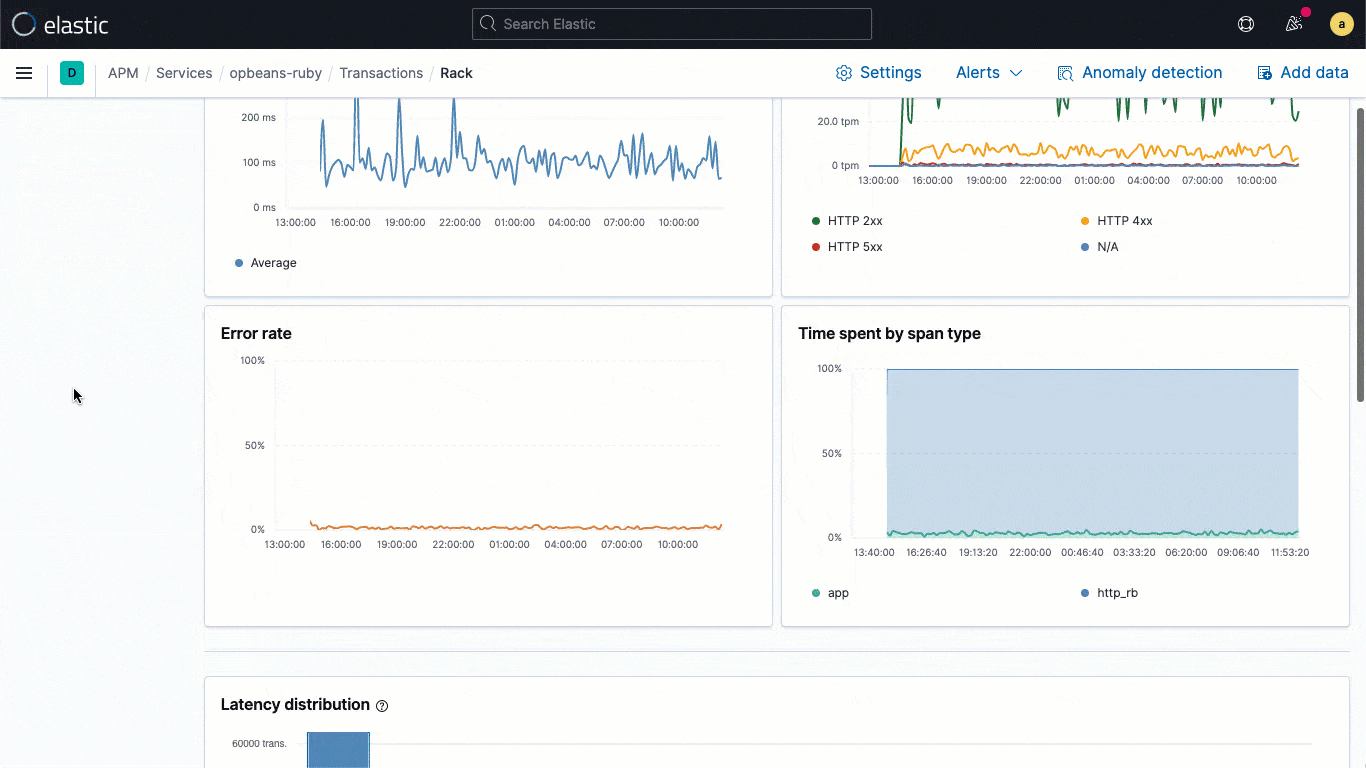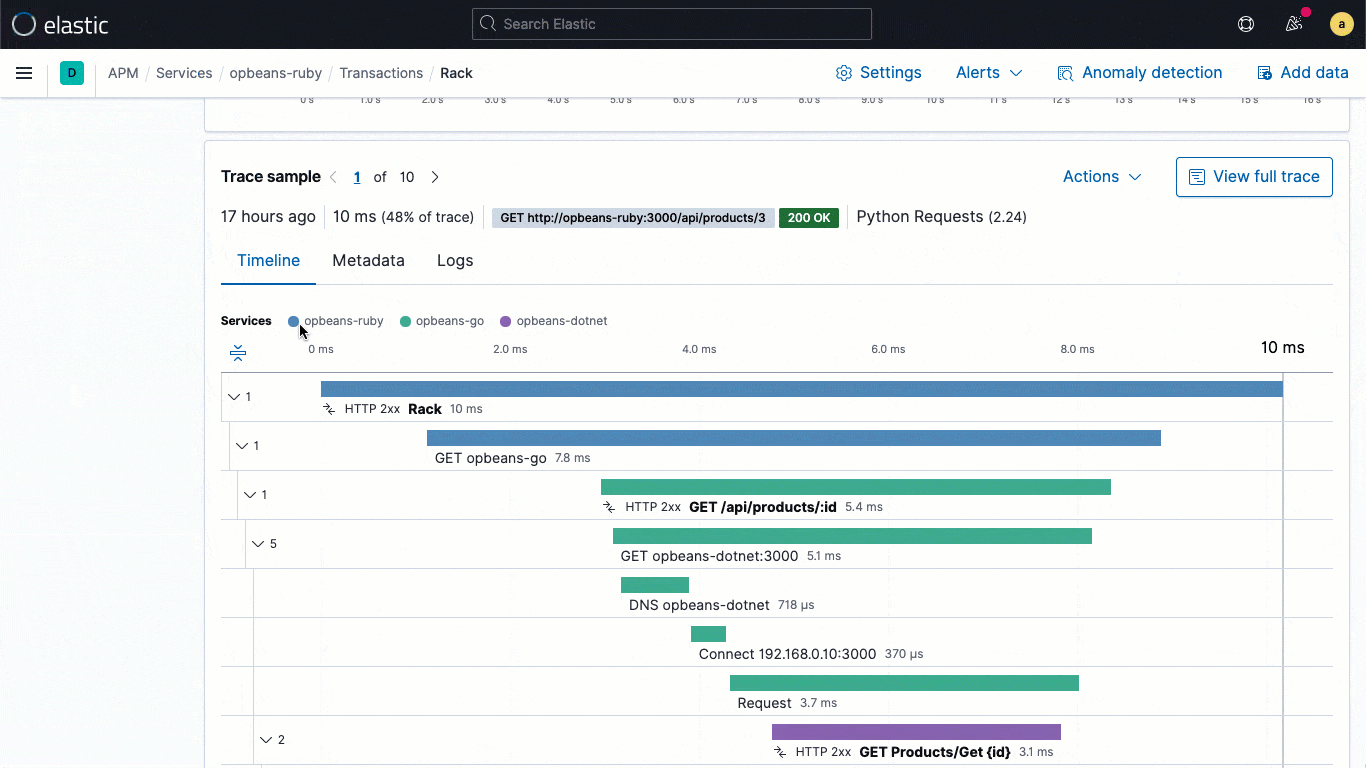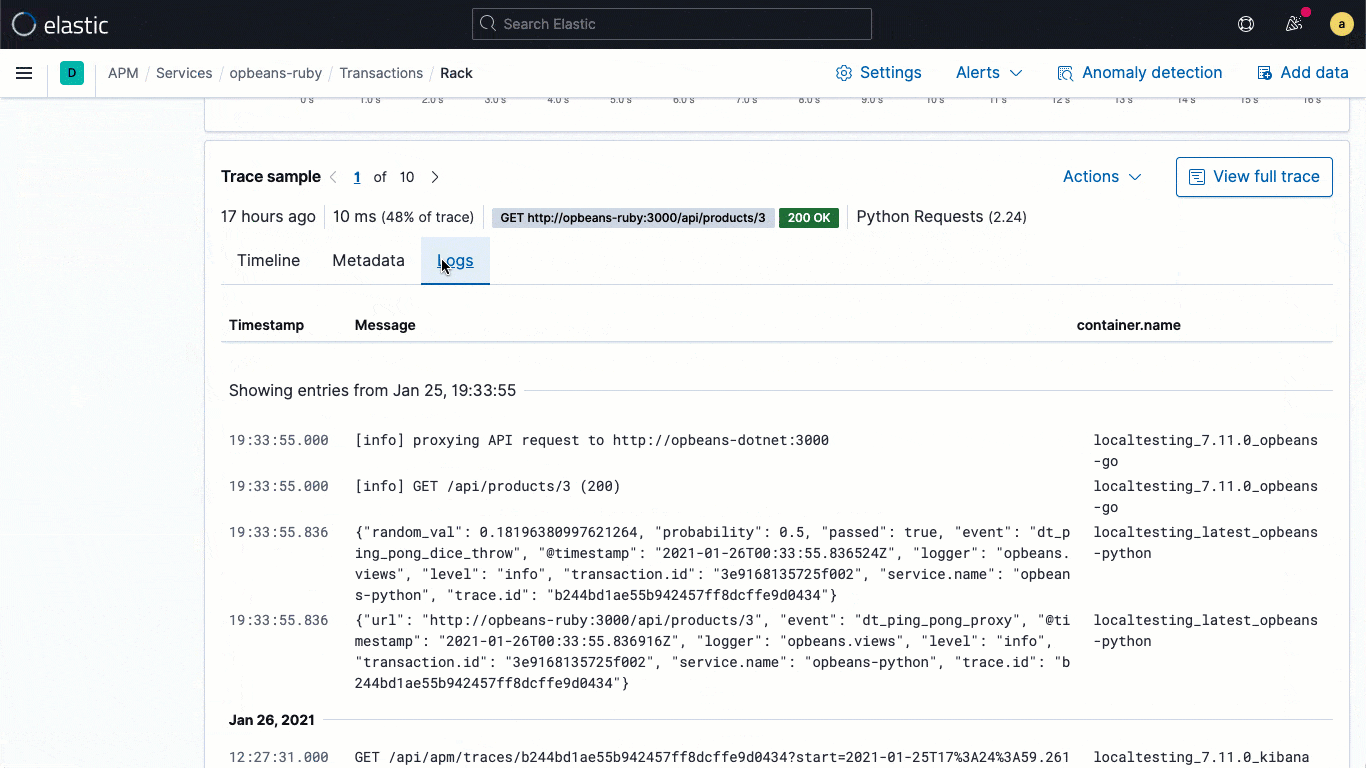
Les bibliothèques de logging d'ECS sont des plug-ins pour vos frameworks de logging préférés (comme log4j) et permettent aux développeurs d’écrire facilement des logs d’application au format JSON compatible ECS, sans modifier leur workflow natif. Les loggers ECS incluent automatiquement dans le log le contexte de trace pertinent capturé par l’agent APM, ce qui aide les développeurs à créer des applications observables sans travail supplémentaire. En règle générale, le contexte de trace capturé comprend les champs trace.id, transaction.id et span.id, le cas échéant.
Grâce à cette mise en relation essentielle au niveau des données, la version 7.11 ajoute un flux de logs intégrés directement dans la vue de traces. Ainsi, les utilisateurs peuvent voir les logs associés à une trace spécifique sans devoir changer de contexte visuel au cours d'une investigation.
En plus de cette corrélation log ↔ trace, la capture des logs au format ECS apporte d'autres avantages, comme l'analyse automatique, les logs lisibles par l'utilisateur et un modèle normalisé de données sur l'ensemble de votre suite d'applications.
Pour en savoir plus sur cette amélioration et d'autres concernant le monitoring de l'infrastructure, consultez la documentation consacrée aux nouveautés de la version 7.11.
Autres points forts remarquables
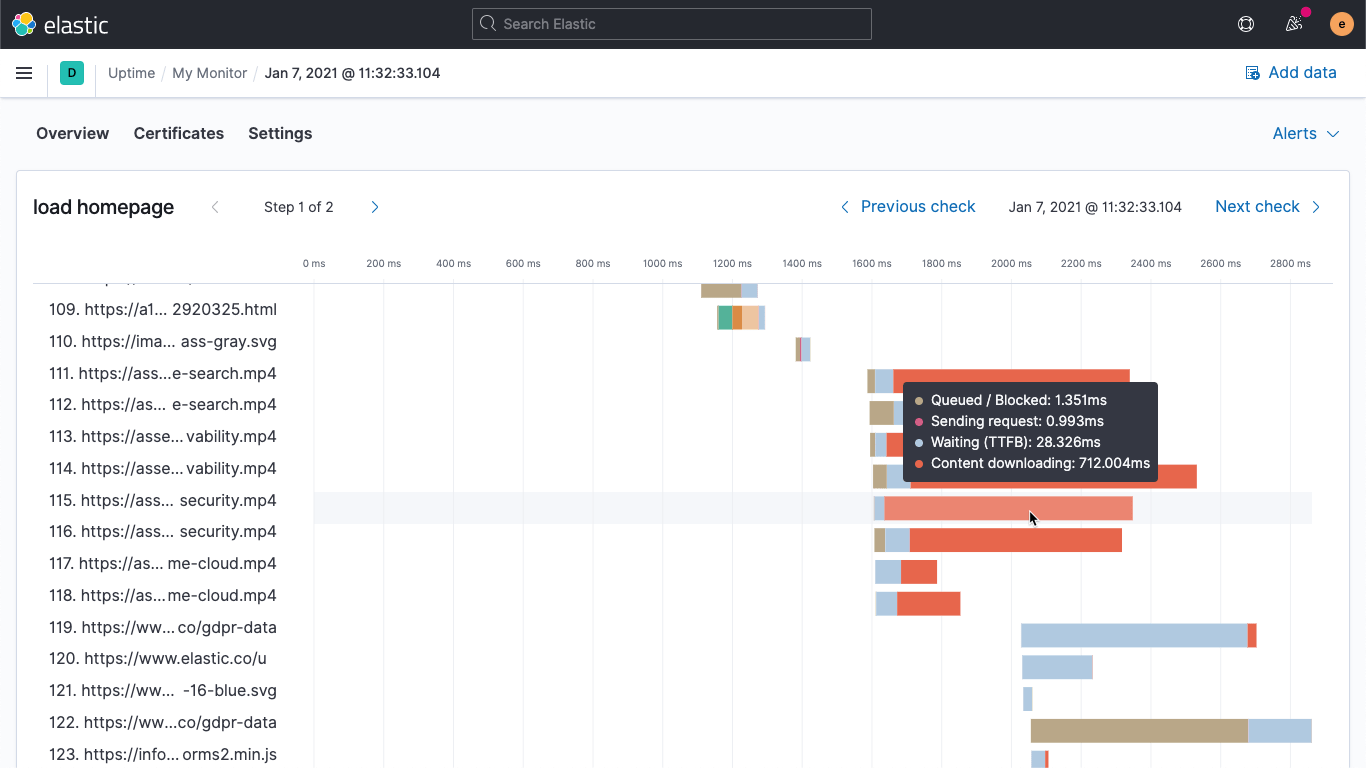
Graphique en cascade de chargement de page
La version 7.10 proposait pour la première fois le monitoring synthétique pour les parcours d'utilisateurs à plusieurs étapes. Dans la version 7.11, nous présentons la première itération de notre cascade de chargement de page qui vous fournit les statistiques de connexion pour chaque objet de la page concernée. Grâce à cette vue en cascade du temps de chargement, les utilisateurs peuvent identifier rapidement les goulets d'étranglement des performances influant sur leur expérience lors des tests synthétiques.
Champs d'exécution posant les bases pour le schéma de lecture
Comme leur nom l'indique, les champs d'exécution (une des fonctionnalités les plus demandées par la communauté Elastic Observability) vous permettent de créer des champs en temps réel lors de l'exécution en transformant, enrichissant ou extrayant des champs à partir de données indexées. Grâce à cette fonctionnalité fondamentale, vous bénéficiez de nouveaux workflows d'observabilité, y compris l'une des fonctionnalités les plus plébiscitées de tous les temps, à savoir le schéma de lecture.
Suite au lancement de cette dernière, les utilisateurs bénéficient désormais des avantages des deux fonctionnalités. Le schéma d'écriture vous garantit des vitesses d'analyse et de recherche supersoniques grâce à l'analyse et à la structuration des données lors de l'indexation. En parallèle, le schéma de lecture permet de définir des champs en temps réel lors de l'exécution, ce qui fournit davantage de flexibilité pour les workflows d'analyse.
Les champs d'exécution sont pris en charge par Elasticsearch dans la version 7.11 et comprennent un support technique limité pour les interfaces utilisateur dans Kibana. Pour tout savoir sur notre vision, lisez cet article dédié.
Snapshots interrogeables et niveau cold désormais en disponibilité générale
Après avoir fait leur apparition en tant que fonctionnalité bêta dans la version 7.10, les snapshots interrogeables sont désormais en disponibilité générale. Ils permettent aux utilisateurs de mener des analyses et des recherches de données directement dans les services de stockage d'objets, comme Amazon S3. Ainsi, il est facile de mettre en œuvre une stratégie de niveau de données afin d'équilibrer les compromis entre performances et coûts. Le nouveau niveau cold, propulsé par les snapshots interrogeables, peut diviser les coûts de stockage de près de 50 % avec un impact minimal sur les performances.
Les snapshots interrogeables et les niveaux de données sont des fonctionnalités qui changent la donne pour les cas d'utilisation d'observabilité : les utilisateurs gagnent en efficacité sans augmenter la complexité de leurs opérations, modifier leurs workflows d'investigation, ni entraver l'accès aux données.
Essayez la nouvelle version dès aujourd'hui !
Pour en savoir plus sur l'ensemble de ces nouvelles fonctionnalités et bien d'autres choses, consultez la documentation consacrée aux points forts de cette version.
Mieux encore, commencez à utiliser ces formidables fonctionnalités inédites en passant à la version 7.11 pour votre déploiement, en démarrant un essai gratuit de 14 jours d'Elasticsearch Service ou en installant la dernière version de la Suite Elastic.