Détections Elastic SIEM
Lors du lancement d'Elastic Security 7.6, nous avons annoncé la création d'un moteur de détection moderne qui permet aux équipes en charge des centres opérationnels de sécurité de bénéficier d'une expérience unifiée en ce qui concerne les règles SIEM grâce aux détections Elastic SIEM. Ce moteur de détection se fonde sur un ensemble spécialement conçu de moteurs d'analyse Elasticsearch et s'exécute sur une nouvelle plateforme distribuée dans Kibana. Dans cet article, nous vous présentons dans les grandes lignes le flux des détections dans Elastic SIEM et vous détaillons les nouvelles fonctionnalités d'interface utilisateur et de back-end garantissant des détections infaillibles pour nos utilisateurs.
Avant de plonger dans le monde merveilleux des détections, n'oubliez pas de consulter notre série d'articles sur SIEM pour les PME et les particuliers si vous avez envie d'essayer l'application SIEM. Ces articles vous expliquent la configuration dans le cloud grâce à notre essai gratuit d'Elasticsearch Service, en utilisant notamment Beats pour collecter des données en toute sécurité et les récupérer dans vos systèmes afin d'alimenter SIEM. (C'est bien plus facile que ça n'en a l'air !) Nous fournissons également un guide de prise en main pour les déploiements hybrides.
Workflow de l'interface utilisateur pour la gestion des signaux
Les détections Elastic SIEM se fondent sur des signaux, c'est-à-dire des documents Elasticsearch créés dès que les conditions d'une règle de détection des signaux sont remplies. Dans le cas le plus simple, un document de signal est créé pour chaque événement correspondant à la requête définie dans la règle concernée. Le document de signal comprend un exemplaire des champs du document correspondant et est conservé dans un index de signaux distinct. Quand un signal est créé, les événements originaux ne sont pas modifiés.
Les signaux émergent dans l'application SIEM. Quand un professionnel expérimenté détecte un nouveau signal, son état est ouvert. Après analyse et définition des prochaines étapes, le professionnel le passe en état fermé. Tous ces changements peuvent être gérés dans la vue "Detections" de l'application SIEM.
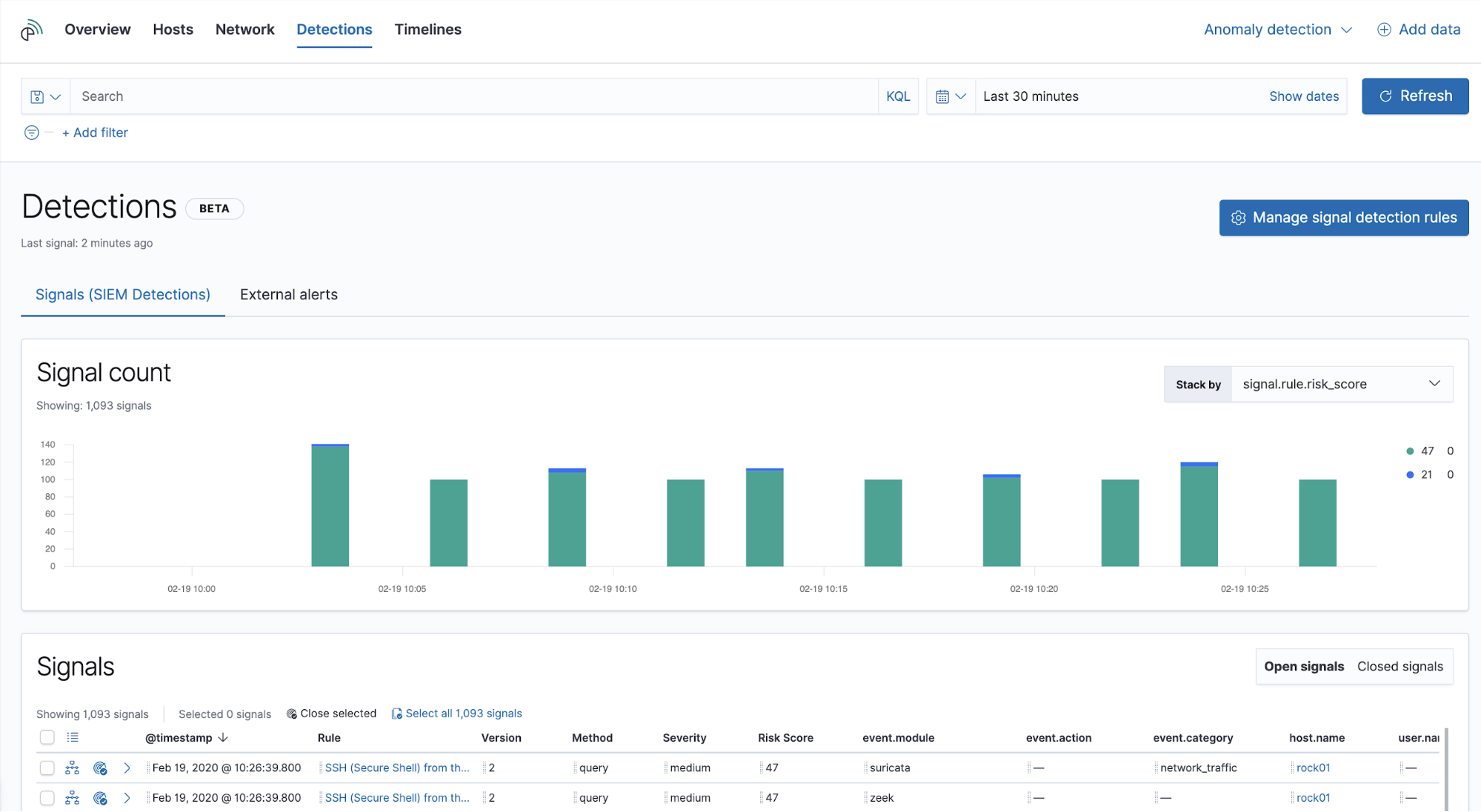
L'histogramme "Signal Count" (Nombre de signaux) indique le nombre de signaux ouverts et permet de comparer rapidement les principaux attributs :
- le score, la sévérité, le type, le nom ou le nom de la tactique MITRE ATT&CK™ ;
- l'adresse IP de destination ou source ;
- la catégorie ou l'action de l'événement ;
- le nom de l'utilisateur ou de l'hôte.
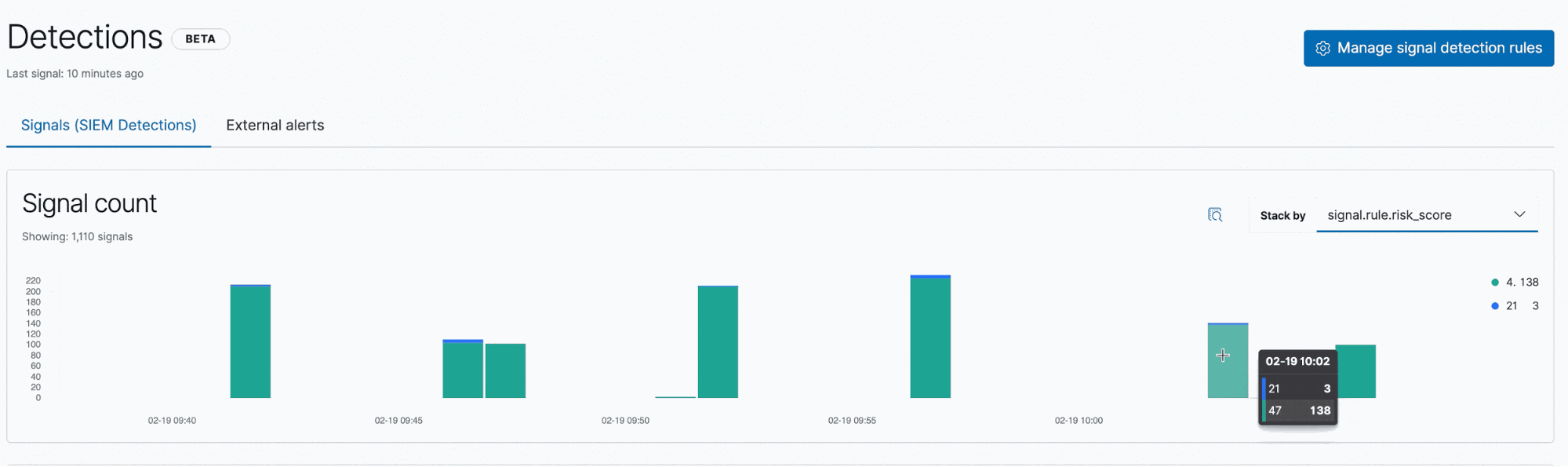
La prochaine étape consiste à analyser les signaux dans la chronologie.
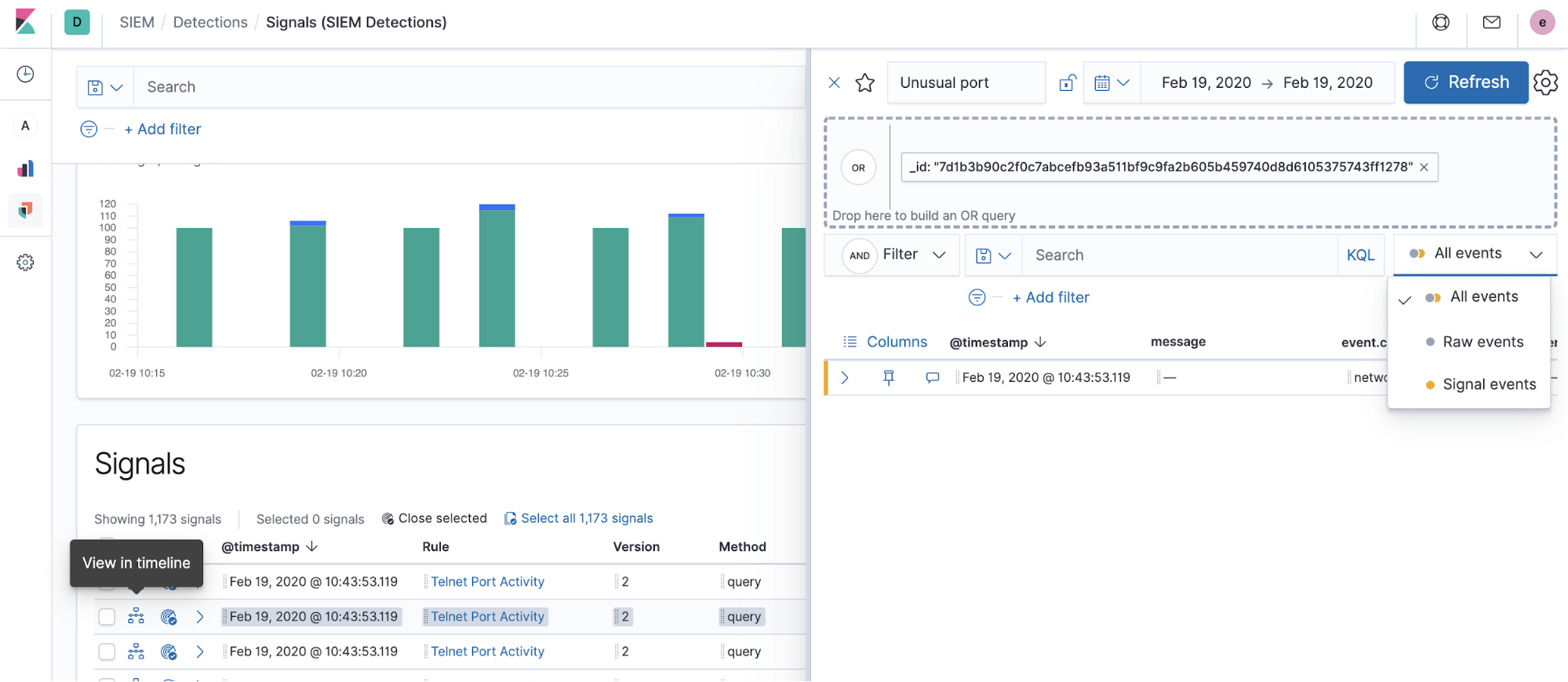
Si vous n'avez pas indiqué de modèle de chronologie à la création d'une règle, un document de signal est renseigné dans la chronologie. Si vous avez indiqué un modèle de chronologie, les enregistrements de l'utilisateur sont renseignés dans la chronologie, ce qui accélère les investigations pour certains types de règles.
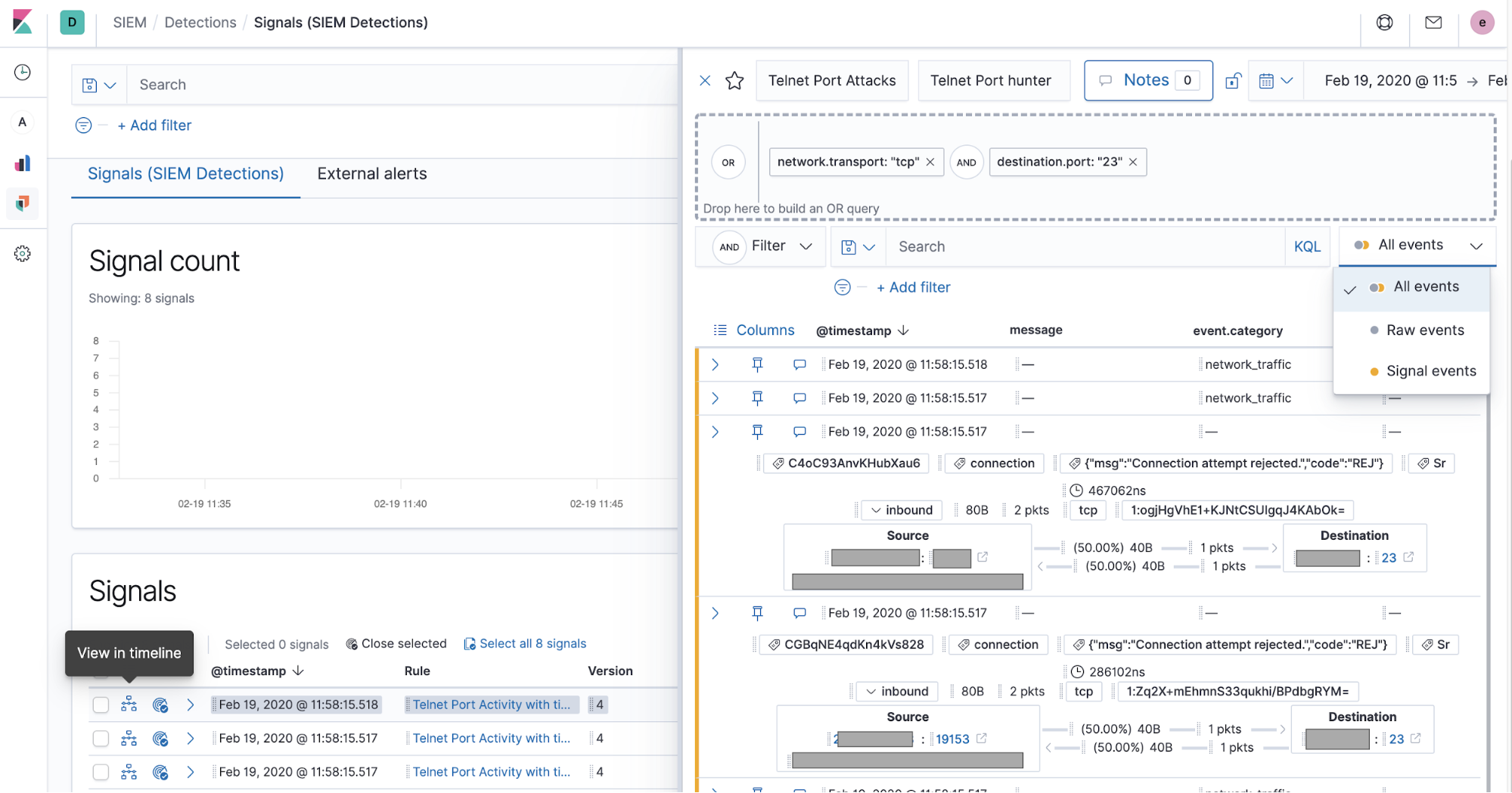
Les professionnels peuvent voir les alertes provenant des systèmes d'alerting externes, notamment Elastic Endpoint Security, Suricata, ou Zeek, dans l'onglet dédié "External alerts" (Alertes externes). Nombre d'entreprises mettent également en place des règles générant des signaux pour des alertes externes à forte valeur ajoutée afin de bénéficier d'un workflow d'investigation optimisé pour les signaux.
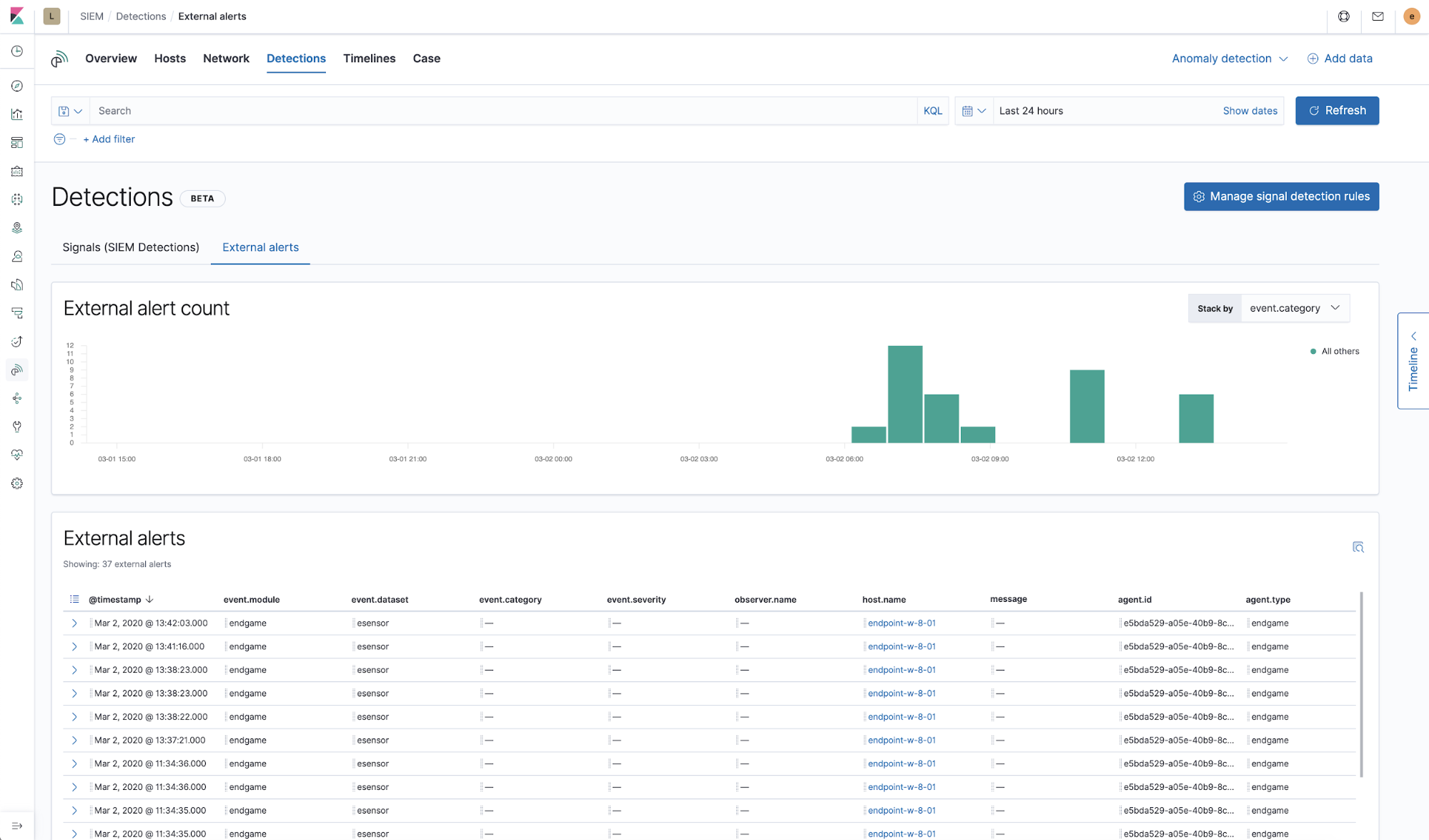
Une fois que l'analyste a pu enquêter sur un signal ou un ensemble de signaux à sa convenance, il peut le ou les fermer séparément ou en groupe. Si besoin, les signaux peuvent être rouverts. Nous nous efforçons d'automatiser la clôture des signaux dans les futures versions.
Workflow de l'interface utilisateur pour la création de règles
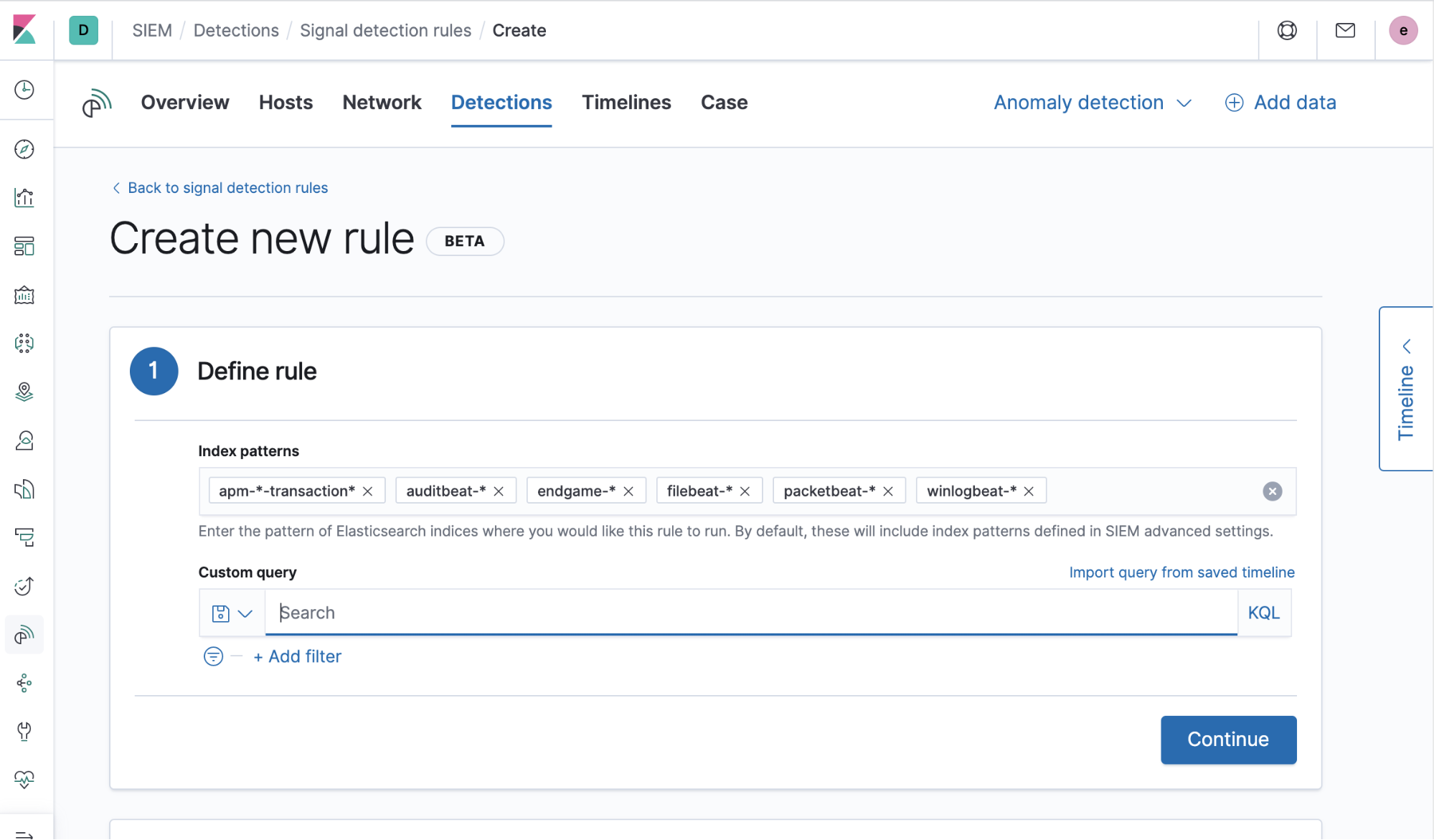
Pour les signaux qui s'affichent, les détections doivent être régies par des règles pour fonctionner correctement. Il est simple et facile de créer une règle pour les détections SIEM. Il suffit de suivre trois étapes.
1) Générer la requête à utiliser à chaque exécution de la règle. Il peut s'agir d'une syntaxe Lucene ou KQL, ou encore d'une recherche enregistrée. La requête peut également être importée depuis une chronologie enregistrée (à l'aide de nombreuses options supplémentaires pour les requêtes de règles actuellement en développement dans les versions futures).
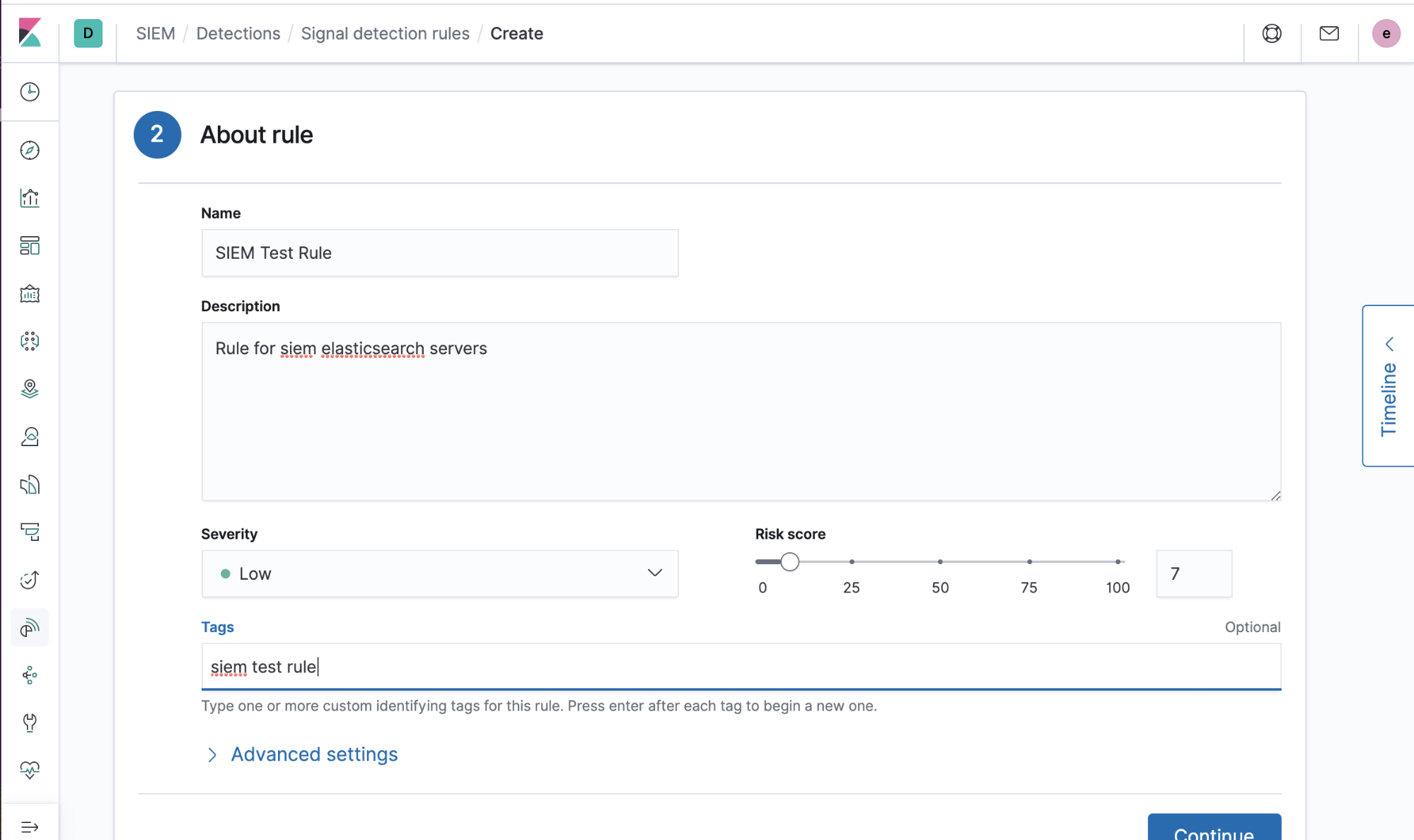
2) Ajouter des informations décrivant la règle (titre, description, etc.).
3) Planifier la fréquence d'exécution de la règle et tout temps de récupération supplémentaire pour les contrôles de conformité. En règle générale, nous recommandons un certain temps de récupération pour anticiper les éventuels retards pouvant survenir dans le pipeline d'ingestion d'un utilisateur donné. Nous recommandons aussi un temps de récupération supplémentaire, comme il n'est pas garanti que les règles s'exécutent aux fréquences exactes définies et qu'elles peuvent, par conséquent, être retardées. Des ressources informatiques insuffisantes ou une file d'attente surchargée de processus d'un gestionnaire de tâches peuvent causer de tels retards.
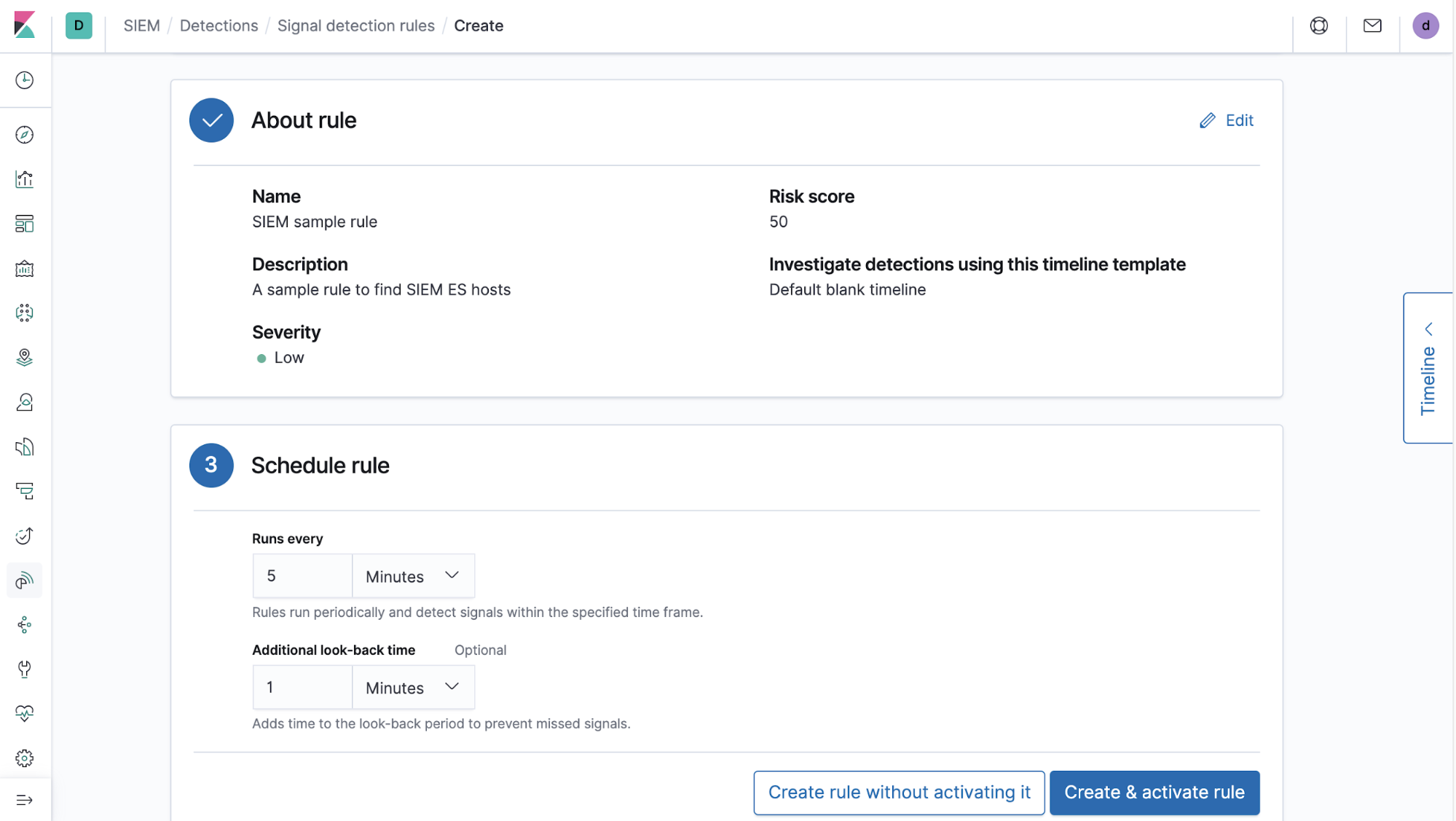
Ces trois étapes sont des composants fondamentaux d'une règle de détection. Par ailleurs, nous fournissons des paramètres pour classer ces règles, selon les techniques et tactiques MITRE ATT&CK, mais aussi des liens vers des références supplémentaires.
![]()
Les utilisateurs peuvent également réaliser des actions individuelles ou groupées sur des règles existantes, notamment dupliquer (pour optimiser), désactiver, exporter et supprimer des règles. En outre, nous fournissons un guide permettant d'en savoir plus sur la gestion générale des règles.
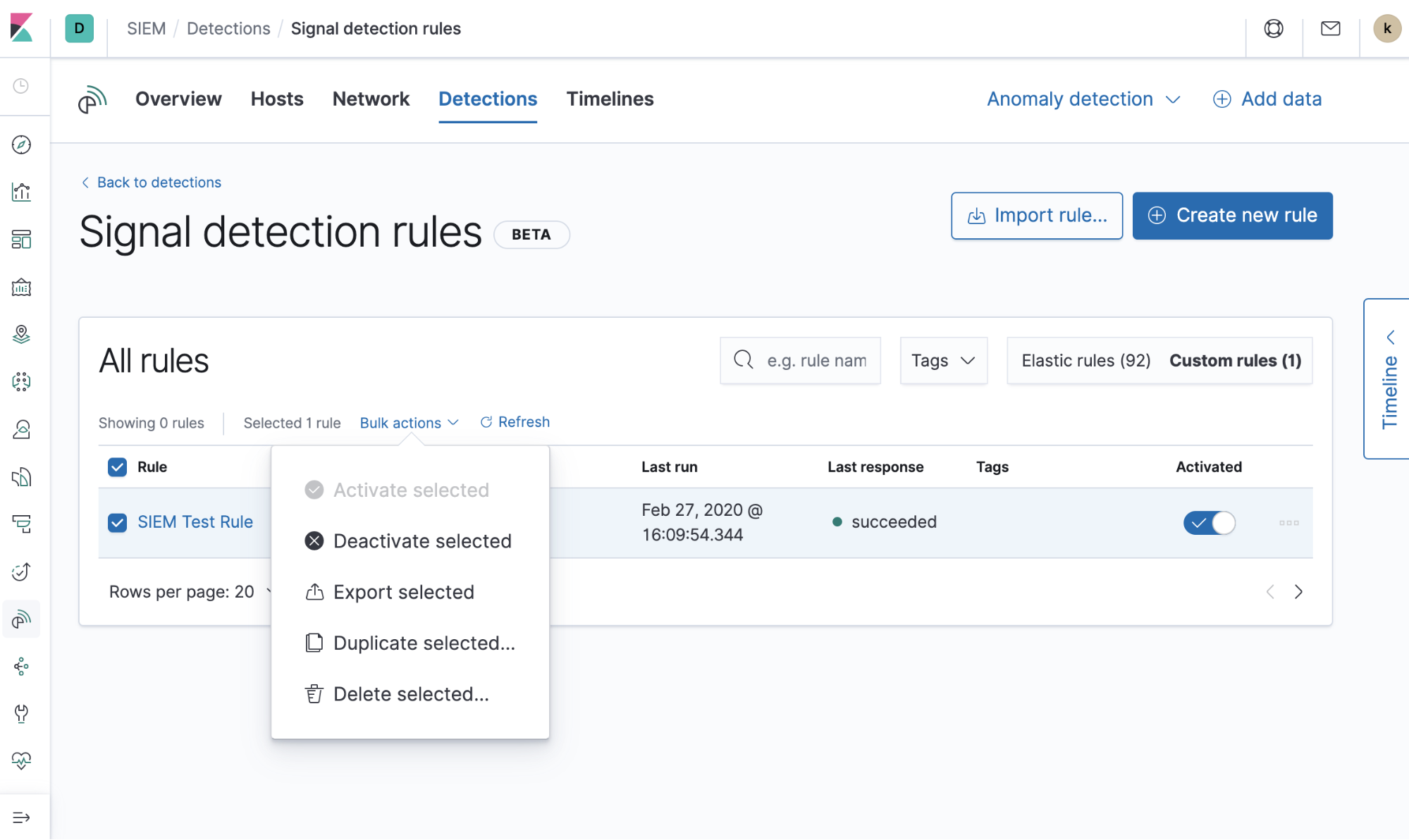
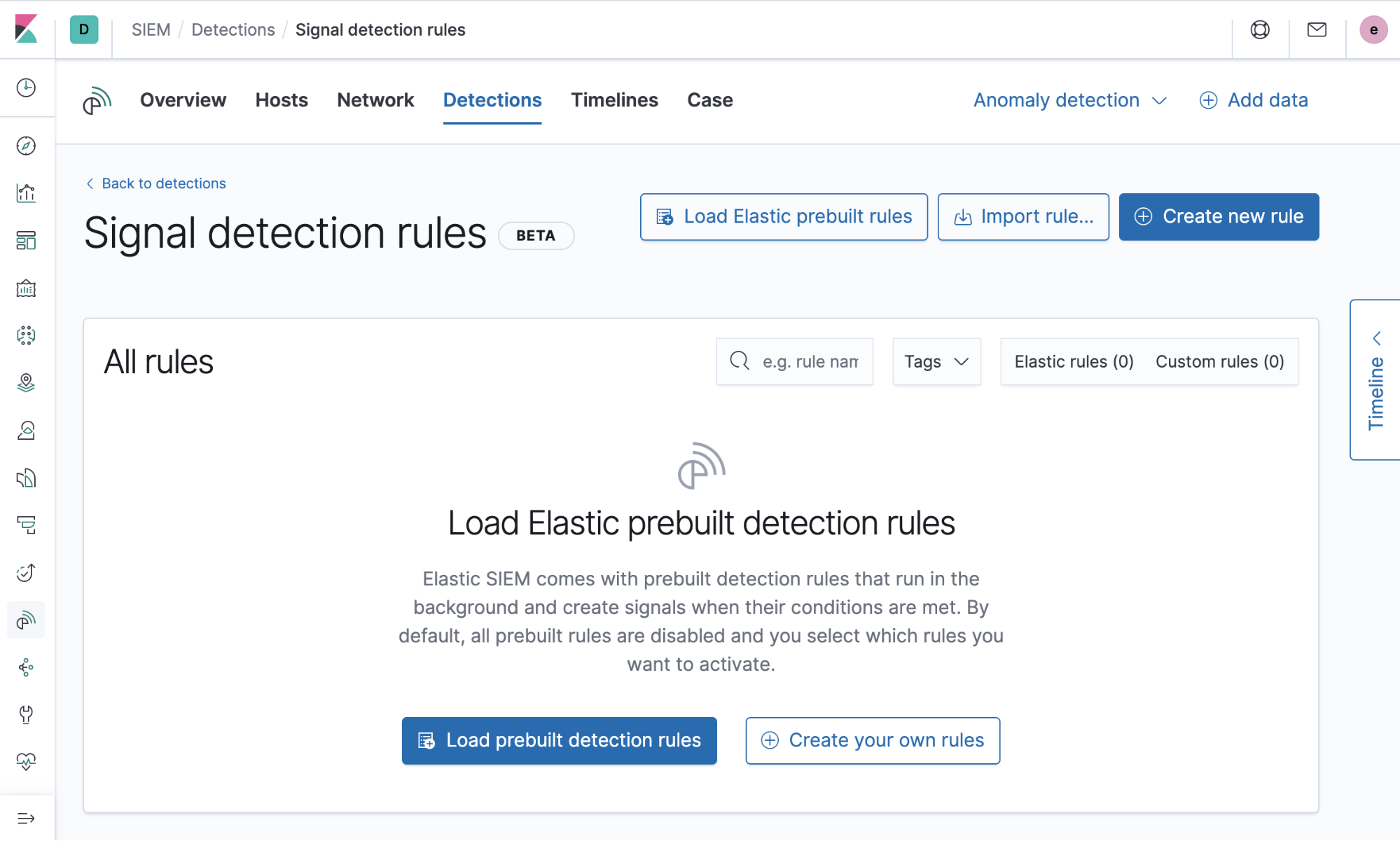
Règles prédéfinies
Il peut être difficile de développer des règles dont le test s'avère parfois long. Ainsi, à l'origine, les détections reposaient sur 92 règles prédéfinies développées par l'équipe en charge de l'analyse et de l'intelligence au sein d'Elastic Security. Elles ont été largement utilisées chez Elastic dans un environnement de production. De nouvelles règles répondant aux dernières menaces critiques sont développées en permanence. Les charger et les exécuter est un véritable jeu d'enfant. Vous pouvez en savoir plus ici sur l'utilisation et le réglage des règles prédéfinies.
Détails de la mise en œuvre des détections
Peu de temps après l'intégration de l'alerting dans la Suite Elastic au sein de Kibana afin de garantir la prise en charge des alertes en tant qu'éléments primordiaux, Elastic SIEM a utilisé l'alerting comme base de développement des détections. Outre l'interface utilisateur, la vue "Detections" (Détections) utilise une API reposant sur l'API Alerting. Grâce à l'API de détection SIEM, vous bénéficiez d'une méthode pratique, de workflows (comme l'ouverture et la fermeture des signaux), des caractéristiques du domaine en matière de sécurité (notamment l'identification MITRE ATT&CK) et de la prise en charge de KQL.
Les règles sont exécutées dans les coulisses via la création d'une clé d'API et son utilisation pour formuler des requêtes au nom de l'utilisateur grâce au paramètre search after visant à trouver des événements correspondants et à la variable bulk create permettant de copier les informations d'un événement dans un document de signal au sein d'un index dédié. Un signal comprend les détails de la règle et du document d'événement originel mis en correspondance par la règle.
Si plus de 100 documents correspondants sont trouvés dans une seule exécution de règle, seuls les 100 derniers (selon l'ordre chronologique basé sur le paramètre "@timestamp") sont copiés dans l'index de signaux. Ce dernier est automatiquement créé en fonction de l'espace disponible dans Kibana lors de votre première consultation de la page sur les règles de détection des signaux. Le nom des index est créé au format ".siem-signals-
Le mapping de l'index de signaux SIEM associe Elastic Common Schema (ECS) à un mapping personnalisé de notre définition d'unsignal. Lorsque la requête de règles détecte un document correspondant, elle copie les champs des index sources. Les champs de signaux ainsi obtenus peuvent faire l'objet de recherches, si les champs du document source sont conformes à ECS. Si les champs des index sources ne font pas partie d'ECS, ils seront stockés dans le paramètre "_source" du signal. Ils peuvent être visibles dans la chronologie et d'autres sections de l'application. Toutefois, ils ne peuvent pas faire l'objet de recherches.
Scalabilité
L'interface utilisateur de la vue "Detections" se fonde sur le tout nouveau cadre d'alerting de Kibana et le gestionnaire de tâches de Kibana. Ces deux éléments fournissent des capacités de montée en charge horizontale et verticale, ce qui apporte la souplesse adaptée au matériel disponible au moment requis. Il est possible d'augmenter le nombre de processus du gestionnaire de tâches de Kibana afin de tirer parti de la montée en charge verticale. Ils peuvent également être reproduits sur plusieurs instances Kibana distinctes et scalés horizontalement.
Lors de l'exécution de plusieurs instances Kibana, les gestionnaires de tâches se coordonnent en réseau afin d'équilibrer les tâches entre les différentes instances. En mettant à jour le nombre maximum de processus (max_workers) dans le fichier kibana.yml afin qu'il soit supérieur à sa valeur par défaut définie à 10, vous pouvez scaler verticalement à la hausse ou à la baisse afin d'attribuer les ressources adéquates de manière plus efficace pour chaque nœud Kibana.
Déduplication du signal
Lors de l'exécution d'une règle, elle génère des signaux en fonction des événements identifiés qui correspondent à sa requête. Parfois, des signaux dupliqués peuvent être créés soit en chevauchant les requêtes dans des règles distinctes, soit en exécutant deux fois de suite une règle et en détectant le même signal grâce à un long temps de récupération supplémentaire. Pour éviter qu'un signal dupliqué apparaisse dans le tableau des signaux, nous identifions ces derniers selon l'index d'origine, l'identifiant du document et le numéro de version de l'événement source mais aussi l'identifiant de la règle exécutée. En compartimentant ces propriétés, seuls les signaux uniques sont ajoutés à l'index.
Erreurs
Parfois, des erreurs surviennent à cause d'une mauvaise syntaxe dans une requête de règle ou d'autres problèmes au cours de l'exécution d'une règle. Nous les signalons dans l'onglet "Failure History" sur la page affichant les détails de la règle. Nous envisageons d'élargir à l'avenir la visibilité des informations sur l'exécution des règles et du monitoring général des règles.
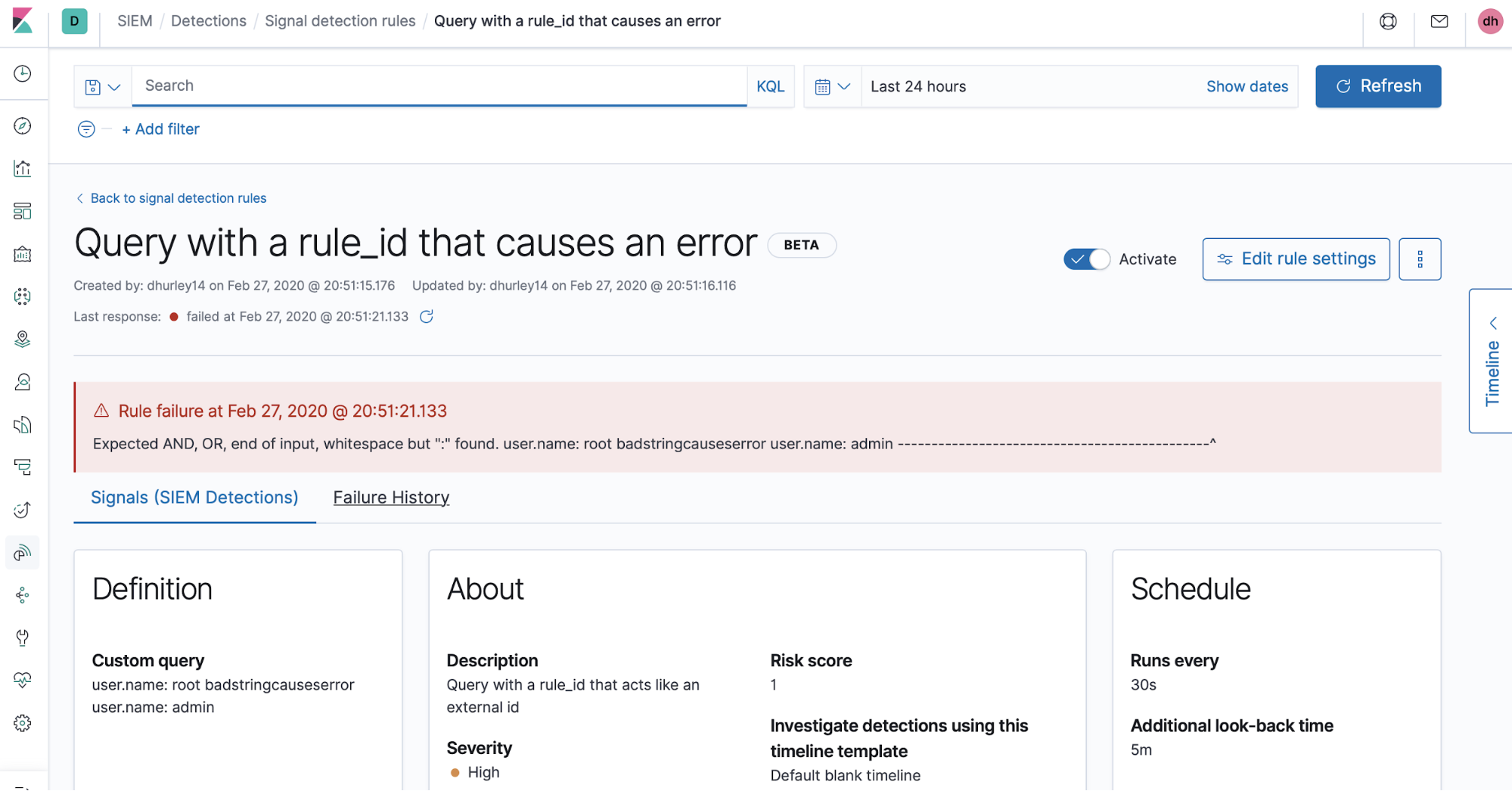
Voici une copie d'écran de l'historique des défaillances, qui affiche les cinq dernières erreurs survenues lors de l'exécution d'une règle.
Détections SIEM de demain
Dans le cadre du travail sur le lancement de cette version bêta des détections Elastic SIEM, nous apprécions tout particulièrement de recevoir dès les premiers développements et de manière continue des commentaires de la communauté sur le forum de discussion Elastic SIEM et sur notre liste de suivi des fonctionnalités ouvertes.
Nous envisageons de continuer à renforcer la puissance des détections. Par exemple, nous souhaitons élargir les requêtes de règles afin d'inclure les agrégations, les tâches de Machine Learning et EQL. Si vous connaissez un cas d'utilisation de sécurité particulièrement évocateur ou si vous avez des questions sur notre actualité, n'hésitez pas à nous en parler !