Les GPU s'emballent ! Elastic Inference Service (EIS) : inférence accélérée par GPU pour Elasticsearch
_(1).png)

 Share on Twitter
Share on TwitterPartager sur Twitter

 Share on LinkedIn
Share on LinkedInPartager sur LinkedIn

 Share on Facebook
Share on FacebookPartager sur Facebook

 Share by Email
Share by EmailPartage par e-mail

 Print this page
Print this pageImprimer
Nous sommes ravis d'annoncer le lancement du service Elastic Inference (EIS), qui introduit une inférence accélérée par GPU, intégrée de manière native à Elasticsearch sur Elastic Cloud.
Elasticsearch est la base de données de recherche vectorielle et sémantique la plus largement déployée. Les charges de travail modernes de recherche et d'IA dépendent d'une inférence rapide et dimensionnable pour les intégrations, le reclassement et les modèles de langage. À mesure que les volumes augmentent, la gestion de l'infrastructure, les tests de modèles, la gestion des intégrations et l'assemblage de solutions ponctuelles ajoutent une lourde charge opérationnelle. Cela a créé un besoin clair chez les clients pour des flottes gérées accélérées par GPU qui offrent rapidité, évolutivité et rentabilité sans les frais opérationnels liés à l'infrastructure ou aux intégrations. Le Service d'inférence Elastic est conçu pour offrir l'inférence en tant que service et pour fournir l'intégration, le reclassement, ainsi que des grands et petits modèles de langage en tant que service à l’échelle. Nous avons également conçu EIS pour qu'il soit un fournisseur de services multicloud, multirégional et multimodal afin de répondre à tous vos besoins d'inférence à long terme.
L’EIS donne déjà accès à un grand modèle de langage de pointe, qui à son tour alimente des fonctionnalités d’IA prêtes à l’emploi pour l’ingestion automatique, la détection des menaces, l’investigation des problèmes, l’analyse des causes profondes, et plus encore pour Playground et les assistants d’IA. Nous sommes maintenant ravis de présenter Elastic Learned Sparse EncodeR (ELSER), le modèle vectoriel dispersé intégré d’Elastic pour une pertinence de recherche de pointe, en tant que premier modèle d’intégration de texte sur EIS en préversion technique. ELSER soutient la majorité des cas d’utilisation de la recherche sémantique sur notre plate-forme et offre une pertinence et des performances de pointe. Ce n’est que le début ; des modèles supplémentaires pour les intégrations multilingues, le reclassement et les modèles de Jina.AI, qui a récemment rejoint Elastic par le biais d’une acquisition, sont en passe d’étendre encore les possibilités.
Architecture et performance de pointe
EIS offre une architecture dimensionnable grâce à des GPU NVIDIA modernes pour assurer une inférence à faible latence et à haut débit. Les GPU permettent aux modèles d’apprentissage automatique de traiter de nombreux calculs en parallèle, augmentant ainsi l'efficacité globale d'un ordre de grandeur.
EIS offre aux utilisateurs d'Elasticsearch une expérience d\'inférence rapide tout en simplifiant la configuration et la gestion des flux de travail. Le service garantit des performances supérieures cohérentes et une expérience développeur optimale en fournissant une inférence facile à consommer via des API pour une expérience semantic_text de bout en bout, générant des intégrations vectorielles et utilisant des grands modèles de langage pour alimenter l'ingénierie contextuelle et les flux de travail agentiques.
Expérience développeur rationalisée : aucun modèle à télécharger, aucune configuration manuelle ni ressource à configurer ne sont nécessaires. EIS s'intègre directement à semantic_text et aux API d'inférence pour offrir une expérience agréable aux développeurs. Il n''y a pas de démarrage à froid lors du déploiement des modèles et il n'est pas nécessaire de mettre en œuvre votre propre dimensionnement automatique.
- Expérience de recherche sémantique améliorée de bout en bout : vecteurs clairsemés, vecteurs denses ou reclassement sémantique, nous avons ce qu'il vous faut. D'autres modèles seront bientôt disponibles.
- Performances améliorées : l’inférence accélérée par GPU offre une latence cohérente et un débit d'ingestion jusqu'à 10 fois supérieur par rapport aux alternatives basées sur processeur, surtout à des charges plus élevées.
- Flux de travail d’IA générative simplifiés : évitez les difficultés dues aux services externes, aux clés API et aux contrats. Avec le grand modèle de langage géré par Elastic, les fonctionnalités d’IA pour l’ingestion, l’investigation, la détection et l’analyse fonctionnent dès le premier jour.
- Compatibilité descendante : les nœuds d’apprentissage automatique Elasticsearch existants restent pris en charge tandis que l'API d\'inférence vous offre une flexibilité totale pour connecter n'importe quel service tiers.
- Tarification facile à comprendre : EIS propose une tarification basée sur la consommation similaire à celle d'autres services d'inférence, facturée par modèle et par million de jetons. Elastic garantit également tous les modèles fournis sur EIS, ce qui facilite le démarrage et l'accès à l'assistance.
- Accès : les déploiements Elastic Cloud Serverless et Elastic Cloud Hosted pour tous les fournisseurs de services cloud et toutes les régions peuvent accéder aux points de terminaison d'inférence sur EIS.
Les diagrammes suivants illustrent l'évolution de l'inférence dans Elasticsearch, passant de flux de travail autogérés basés sur le processeur au service Elastic Inference entièrement intégré et optimisé pour le GPU.
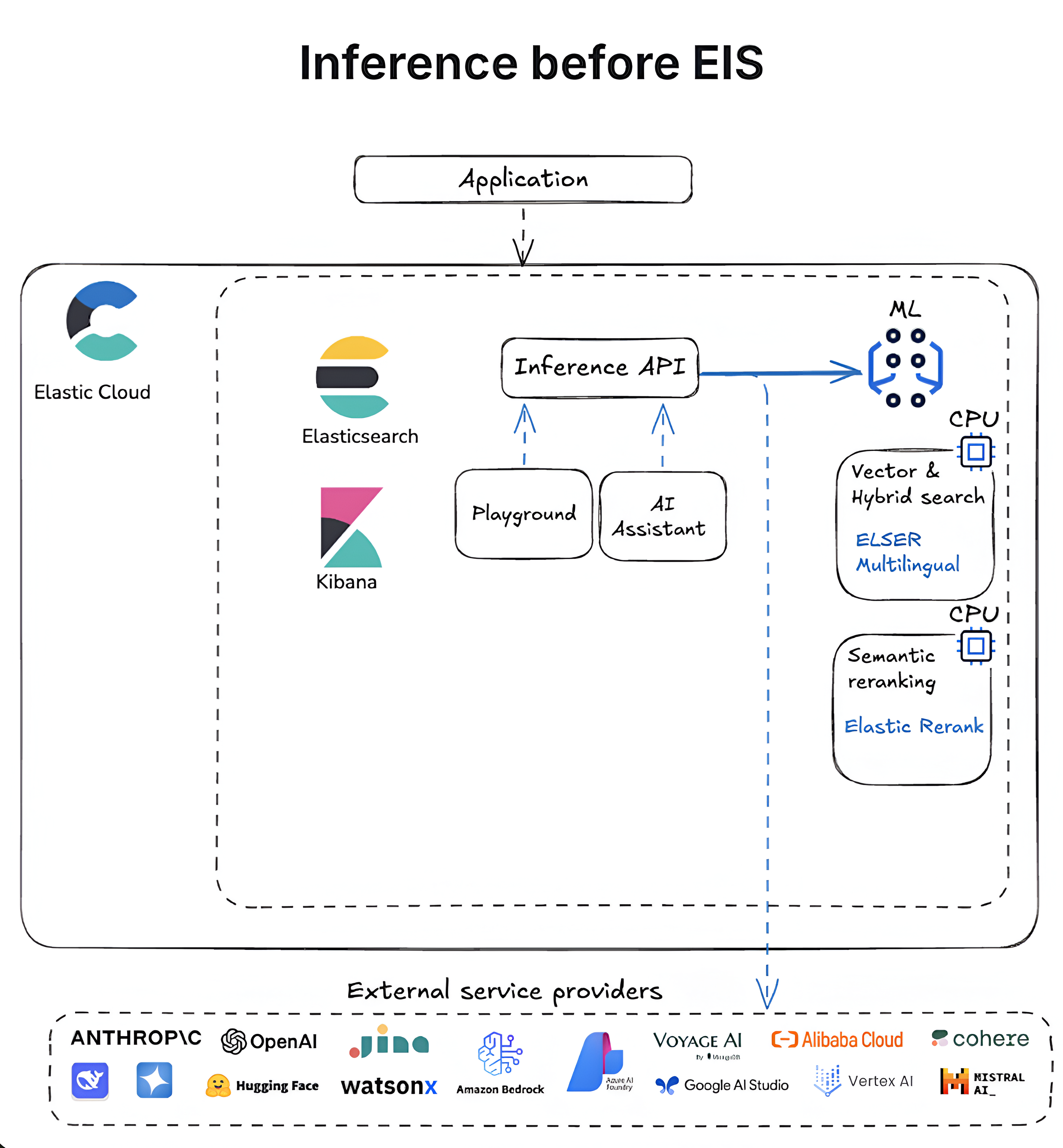
Et ensuite ?
Nous travaillons sur de nombreuses améliorations passionnantes du service Elastic Inference pour alimenter une grande variété de cas d'utilisation. Parmi les principales, on peut citer :
Plus de modèles : nous élargissons notre catalogue de modèles pour répondre aux besoins croissants de nos clients en matière d’inférence. Au cours des prochains mois, nous introduirons de nouveaux modèles sur EIS pour soutenir une plus grande variété de recherche et d’inférence, notamment :
Modèle d'intégration multilingue pour recherche sémantique
Modèle de reclassement sémantique pour une recherche sémantique améliorée et une recherche par mots-clés améliorée
Modèles d'intégration et de reclassement multimodaux
Petits modèles de langage
Plus de grands modèles de langage
Nous continuerons à ajouter d'autres types de modèles. Si vous souhaitez voir un modèle particulier, contactez-nous à l’adresse support@elastic.co.
Plus de fournisseurs de services cloud et de régions : nous travaillons à étendre prochainement la couverture à davantage de fournisseurs de services cloud et de régions. Pour connaître la disponibilité actuelle, consultez notre documentation.
- Recherche sémantique simplifiée : la recherche sémantique avec semantic_text, un type de champ dans la requête, simplifie le flux de travail d'inférence en fournissant l'inférence au moment de l'ingestion et des valeurs par défaut pertinentes automatiquement. Très bientôt, semantic_text commencera à utiliser par défaut le point de terminaison ELSER dans le service d’Inférence Elastic.
- Plus de considération pour les clients autogérés : nos utilisateurs autogérés pourront bientôt profiter de ce service. Dans un avenir proche, le mode connecté au cloud apportera l’EIS aux environnements autogérés, réduisant ainsi les frais généraux opérationnels et permettant d’installer des architectures hybrides et l’évolutivité là où cela vous convient le mieux.
Nous avons de nombreuses autres améliorations passionnantes sur lesquelles nous nous concentrons, alors n'hésitez pas à nous contacter si vous avez des questions.
Essayer EIS sur Elastic Cloud
Avec des flux de travail transparents, des informations en temps réel et des performances accélérées, EIS permet aux développeurs de créer plus rapidement des applications d'IA générative plus efficaces au sein de l'écosystème Elastic.
Toutes les versions d'essai d'Elastic Cloud ont accès au service Elastic Inference. Essayez-le dès maintenant sur Elastic Cloud Serverless et Elastic Cloud Hosted.
La publication et la date de publication de toute fonctionnalité ou fonction décrite dans le présent article restent à la seule discrétion d'Elastic. Toute fonctionnalité ou fonction qui n'est actuellement pas disponible peut ne pas être livrée à temps ou ne pas être livrée du tout.
Dans cet article, nous sommes susceptibles d'avoir utilisé ou mentionné des outils d'IA générative tiers appartenant à leurs propriétaires respectifs qui en assurent aussi le fonctionnement. Elastic n'a aucun contrôle sur les outils tiers et n'est en aucun cas responsable de leur contenu, de leur fonctionnement, de leur utilisation, ni de toute perte ou de tout dommage susceptible de survenir à cause de l'utilisation de tels outils. Lorsque vous utilisez des outils d'IA avec des informations personnelles, sensibles ou confidentielles, veuillez faire preuve de prudence. Toute donnée que vous saisissez dans ces solutions peut être utilisée pour l'entraînement de l'IA ou à d'autres fins. Vous n'avez aucune garantie que la sécurisation ou la confidentialité des informations renseignées sera assurée. Vous devriez vous familiariser avec les pratiques en matière de protection des données personnelles et les conditions d'utilisation de tout outil d'intelligence artificielle générative avant de l'utiliser.
Elastic, Elasticsearch et les marques associées sont des marques commerciales, des logos ou des marques déposées d'elasticsearch B.V. aux États-Unis et dans d'autres pays. Tous les autres noms de produits et d'entreprises sont des marques commerciales, des logos ou des marques déposées appartenant à leurs propriétaires respectifs.
Partager
- Share on Twitter
Partager sur Twitter
- Share on LinkedIn
Partager sur LinkedIn
- Share on Facebook
Partager sur Facebook
- Share by Email
Partage par e-mail
- Print this page
Imprimer