Vorgangsprotokollierung beim Fahrdienstvermittler Lyft: Migration von Splunk Cloud über Amazon ES zu Self-Managed Elasticsearch
Auf der Suche nach einer Alternative zu Splunk? Finden Sie heraus, wie Sie mit dem Wechsel von Splunk zu Elastic Ihre Observability- und Sicherheitsdaten in einer einzigen Plattform vereinheitlichen und gleichzeitig Ihre Gesamtkosten und Ihren Verwaltungsaufwand reduzieren können.
Dieser Blogpost ist eine Zusammenfassung eines Anwendertalks bei der Elastic{ON} 2018. Sind Sie an ähnlichen Talks wie diesem interessiert? Schauen Sie sich im Konferenzarchiv um oder informieren Sie sich über anstehende Elastic{ON} Tour-Termine in Ihrer Nähe.
Wenn Sie mehr über die Unterschiede zwischen dem Amazon Elasticsearch Service und unserem offiziellen Elasticsearch Service erfahren möchten, sehen Sie sich unseren AWS-Elasticsearch-Vergleich an.
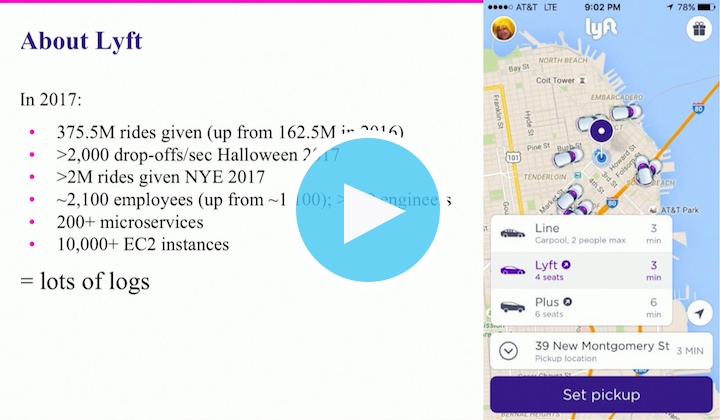
Der Fahrdienstvermittler Lyft benötigt eine leistungsstarke Technologieinfrastruktur, um jedes Jahr weltweit Hunderte von Millionen Fahrten abzuwickeln und um sicherzustellen, dass alle Kunden an ihr gewünschtes Ziel gelangen. Allein im Jahr 2017 waren es mehr als 375 Millionen Fahrten und dies bedeutete mehr als 200 Microservices, die über mehr als 10.000 EC2-Instanzen verteilt waren. An Tagen wie Silvester (mit mehr als 2 Millionen Fahrten an einem Tag) und Halloween (mit mehr als 2.000 Fahrten pro Minute in Spitzenzeiten) schnellten die Zahlen in die Höhe. Für eine reibungslose Abwicklung der Fahrten und für den unterbrechungsfreien Betrieb der Systeme ist es unerlässlich, dass die Ingenieure von Lyft Zugriff auf alle Vorgangsprotokolle haben. Aus diesem Grund müssen Michael Goldsby und sein Observability-Team dafür sorgen, dass ihr Protokoll-Pipelinedienst unterbrechungsfrei läuft.
Zu Beginn der Protokollanalyse bei Lyft nutzen sie Splunk Cloud als ihren Serviceanbieter. Doch die vertraglich festgelegten Aufbewahrungslimits, Ingestbackups von bis zu 30 Minuten in Spitzenzeiten und die mit der Skalierung verbundenen Kosten veranlassten Lyft dazu, zu Elasticsearch zu wechseln.
Ende 2016 gelang es einem Team aus zwei Ingenieuren, Lyft innerhalb von einem Monat von Splunk zu Amazon Elasticsearch Service auf AWS zu migrieren. Die Migration zu Elasticsearch war ein Erfolg, einige Teile des AWS-Angebots erfüllten jedoch nicht alle Ansprüche. So wünschte das Team um Michael Goldsby beispielsweise ein Upgrade auf Elasticsearch 5.x, doch AWS bot zu dieser Zeit nur die Version 2.3 an. Darüber hinaus war die Speicherung für neue Instanzen auf Amazon EBS beschränkt, was bei der von Lyft benötigten Größenordnung nur suboptimale Ergebnisse im Hinblick auf Leistung und Zuverlässigkeit lieferte. Zudem waren auch nicht alle Elasticsearch API auf AWS verfügbar. Doch trotz dieser AWS-Einschränkungen überwogen die Vorteile der Migration von Splunk Cloud zu Amazon Elasticsearch Service auf AWS.
Nachdem die Ingestlimits aufgehoben (oder zumindest drastisch reduziert) worden waren, entschied sich das Observability-Team zu mehr Offenheit und einem völlig neuen Ansatz: „Senden Sie uns all Ihre Protokolle“. Auf diese Weise erhöhten sich die Ingest-Raten schnell von 100.000 Ereignissen pro Minute auf 1,5 Millionen Ereignisse pro Minute. Dieser neue Ansatz war vier Monate lang erfolgreich. Als Probleme mit Ingesttimeouts, geringerer Aufbewahrung oder langsamen Kibana-Dashboards auftraten, musste das Team um Michael Goldsby lediglich ein Scale-up durchführen. Und als das AWS-Knotenlimit von 20 Knoten erreicht wurde, wurde Lyft eine spezielle Ausnahme gewährt, mit der das Limit auf 40 Knoten erhöht wurde.
Doch selbst mit 40 Knoten traten Probleme auf: Probleme im Zusammenhang mit roten Clustern.
Michael Goldsbys Team wusste jedoch, wie sie Probleme im Zusammenhang mit roten Clustern beheben konnten (Neustart, Ersetzen von Knoten usw.). Das eigentliche Problem bestand darin, dass sie keinen direkten Zugriff auf ihre Cluster hatten. Stattdessen mussten sie ein Ticket auf Amazon öffnen und dabei manchmal, während der Spitzenzeiten für den Support, stundenlang warten. Dann musste das Ticket eskaliert werden, weil die ersten Ansprechpartner im Support nicht auf die Cluster zugreifen konnten. Mit der Zeit lernte das Lyft-Team, dass sie den Eskalationsvorgang beschleunigen konnten, indem sie sich direkt an ihren Technical Account Manager (TAM) wandten. Der TAM sorgte dann dafür, dass das Cluster wieder in den grünen Zustand gelangte.
In Anbetracht der unvermeidbaren Supportmaßnahmen, der Beschränkung auf die Version 2.3, der EBS-Anforderung und anderer durch AWS verursachten Einschränkungen (Roundrobin-Lastenausgleich, 60-Sekunden-Timeouts, API-Obfuskation usw.) entschied sich das Observability-Team zu einer erneuten Migration – dieses Mal zu einem Self-Managed Elasticsearch-Deployment. „[Auf AWS] stehen uns nicht alle Funktionen zur Verfügung. Es ist nicht möglich, alle Schaltflächen auszuwählen“, sagte Michael Goldsby. „Wir wussten, dass wir intern genügend praktische Erfahrungen mit Elasticsearch hatten, ... um es durchzuziehen.“
Mit einem etwas größeren Team als bei der Splunk-Migration war Lyft in der Lage, innerhalb von nur zwei Wochen von Amazon Elasticsearch Service zu Self-Managed Elasticsearch zu migrieren. Nun verfügen sie über ihr eigenes Deployment sowie über all die Funktionen, die ihnen zuvor in AWS vorenthalten waren. Dies bedeutet auch, dass sie für alle betrieblichen Aspekte des Elastic Stack verantwortlich sind, einschließlich der Aufrechterhaltung des grünen Zustands ihrer Cluster und der Zufriedenheit ihrer Anwender (ihrer Kollegen und Kolleginnen).
Schauen Sie sich den auf der Elastic{ON} 2018 gehaltenen Talk Lyft's Wild Ride from Amazon ES to Self-Managed Elasticsearch for Operational Log Analytics an, um mehr darüber zu erfahren, wie das Self-Managed Elasticsearch-Deployment bei Lyft implementiert wurde. Sie erfahren alles über die Hardwareauswahl sowie über die Entscheidungen hinsichtlich des Index-Lifecycle-Managements und vieles mehr – u. a. auch, warum „alles protokollieren“ nicht das Gleiche ist wie „irgendetwas protokollieren“ („log everything ≠ log anything“).