Machine Learning in der Cybersicherheit: Erkennen von DGA-Aktivität in Netzwerkdaten
In Teil 1 dieser Blogpost-Serie haben wir uns angesehen, wie wir mit den Machine-Learning-Funktionen des Elastic Stack ein überwachtes Klassifizierungsmodell zur Erkennung von Schad-Domains trainieren können. Im zweiten Teil beschäftigen wir uns damit, wie dieses trainierte Modell uns dabei hilft, die ingestierten Netzwerkdaten mit Klassifizierungsinformationen anzureichern. Das hilft uns bei der Suche nach potenzieller DGA-Aktivität in Packetbeat-Daten.
DGA-Erkennung mit dem Elastic Stack
Schadprogramme müssen zur Erfüllung ihres Einsatzzwecks häufig mit einem vom Angreifer gesteuerten Server – „Command-&-Control“-Server oder auch „C&C“- bzw. „C2-Server“ genannt – kommunizieren. An dieser Stelle setzen Verteidigungsmaßnahmen an und sperren hartcodierte IP-Adressen oder URLs. Um diese Sperren zu umgehen, nutzen die Angreifer in ihrer Malware sogenannte „Domain-Generation-Algorithmen“ (DGAs). Wenn eine Malware einen C&C-Server kontaktieren muss, generiert sie mithilfe des DGA Hunderte oder Tausende von Domains und versucht, für jede dieser Domains eine IP-Adresse aufzulösen. Der Angreifer muss dann nur eine oder einige wenige der vom DGA generierten Domains registrieren – und schon kann er mit der Malware auf der infizierten Maschine kommunizieren. Um es Verteidigungsmaßnahmen zu erschweren, DGAs zu entdecken und zu sperren, werden die DGAs auf verschiedene Art und Weise geseedet und randomisiert.
Da DGA-Aktivität in der Regel mit DNS-Abfragen verbunden ist, manifestiert sie sich häufig in den DNS-Anforderungen, die von der infizierten Maschine ausgehen. Packetbeat kann DNS-Traffic erfassen und zur Analyse an Elasticsearch senden. In diesem Blogpost werfen wir einen Blick darauf, wie Sie die in Packetbeat enthaltenen DNS-Abfrage-Informationen mit einem Score anreichern können, der Auskunft über den Grad der Schädlichkeit der Domain gibt.

Inferenzprozessoren und die Ingestions-Pipeline
Wenn wir Packetbeat-Daten mit Prognosen eines Modells anreichern möchten, das darauf trainiert wurde, gutartige Domains von Schad-Domains zu unterscheiden, müssen wir eine Ingestions-Pipeline mit geeigneten Inferenzprozessoren konfigurieren. Inferenzprozessoren sind eine Möglichkeit, anhand eines im Elastic Stack (oder in einer unserer unterstützten externen Bibliotheken) trainierten Modells Prognosen für neue Dokumente abzugeben, die in Elasticsearch ingestiert werden. Damit wir verstehen, wie all diese Teile zusammenpassen und welche Konfigurationen wir benötigen, schauen wir noch einmal auf Teil 1 dieser Serie zurück.
In Teil 1 haben wir die Schritte zum Trainieren eines Klassifizierungsmodells besprochen, mit dem prognostiziert werden kann, ob eine bestimmte Domain eine Schad-Domain ist. Einer dieser Schritte besteht darin, die Trainingsdaten – eine Gruppe von gutartigen und Schad-Domains anhand derer unser Modell lernt, wie es neue, bisher noch nicht gesehene Domains, einstufen soll – einem Feature-Engineering zu unterziehen. Dabei müssen die Roh-Domains manipuliert werden, um Features – Unigramme, Bigramme und Trigramme – zu extrahieren, die für das Modell nützlich sind. Dasselbe Feature-Engineering ist dann auch auf die Domains in unseren Packetbeat-Daten anzuwenden, von denen wir wissen möchten, ob sie schädlich sind.
Aus diesem Grund enthält unsere Ingestions-Pipeline neben einem Inferenzprozessor auch Painless-Skript-Prozessoren, mit denen beim Ingestieren aus den Packetbeat-DNS-Daten Unigramme, Bigramme und Trigramme extrahiert werden. Abbildung 2 zeigt die komplette Pipeline.
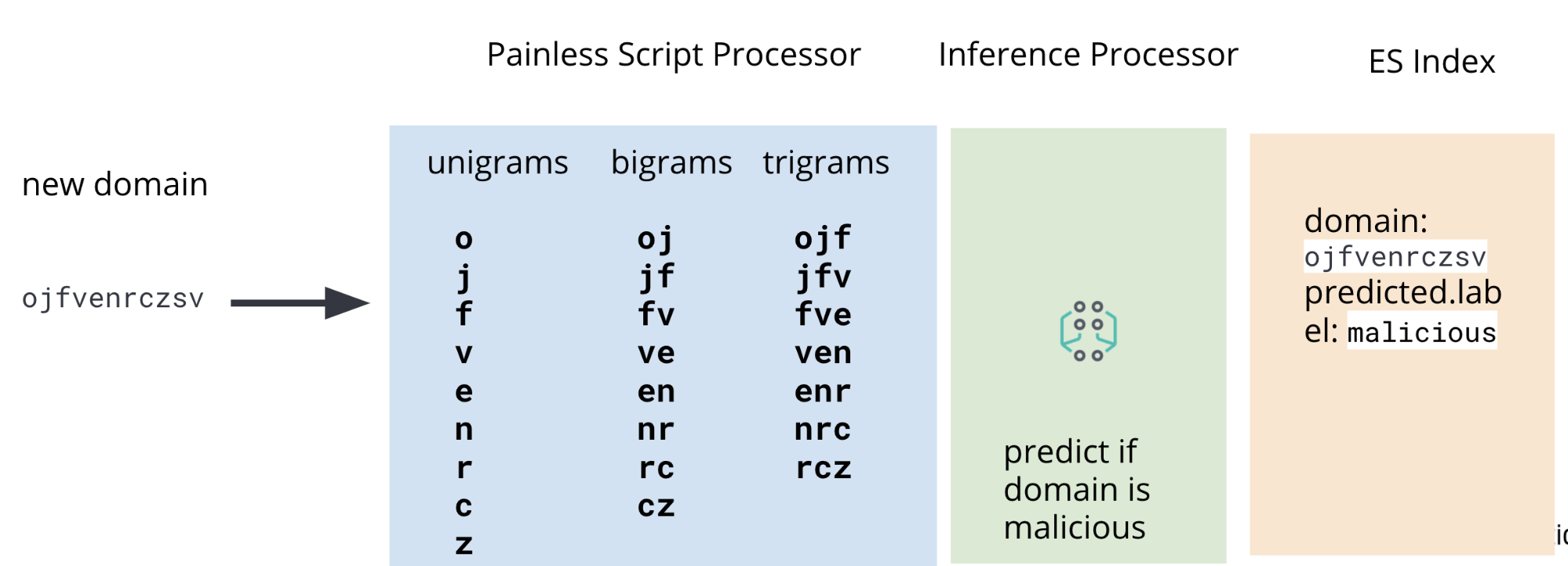
Das Feld in den Packetbeat-Daten, das uns interessiert, ist das Feld dns.question.registered_domain. Es gibt zwar ein paar Randfälle, in denen dieses Feld nicht die uns interessierende Domain enthält, aber für die Illustration des Anwendungsfalls in diesem Blogpost reicht es, sich auf dieses Feld zu konzentrieren. Abbildung 3 zeigt die uns interessierenden Felder in einem Packetbeat-Beispieldokument.

dns.question.registered_domainUm Unigramme, Bigramme und Trigramme aus dns.question.registered_domain extrahieren zu können, benötigen wir ein Painless-Skript wie das in Abbildung 4.
POST _scripts/ngram-extractor-packetbeat
{
"script": {
"lang": "painless",
"source": """
String nGramAtPosition(String fulldomain, int fieldcount, int n){
String domain = fulldomain.splitOnToken('.')[0];
if (fieldcount+n>=domain.length()){
return ''
}
else
{
return domain.substring(fieldcount, fieldcount+n)
}
}
for (int i=0;i<ctx['dns']['question']['registered_domain'].length();i++){
ctx['field_'+Integer.toString(params.ngram_count)+'_gram_'+Integer.toString(i)] = nGramAtPosition(ctx['dns']['question']['registered_domain'], i, params.ngram_count)
}
"""
}
}
Nachdem die erforderlichen Features extrahiert wurden, passiert das Dokument beim Durchlaufen der Ingestions-Pipeline den Inferenzprozessor, wo das Klassifizierungsmodell, das wir in Teil 1 trainiert haben, anhand der extrahierten Features eine Prognose ausgibt. Da wir unseren Index nicht mit all den zusätzlichen Features verstopfen möchten, die das Modell benötigt, fügen wir zu guter Letzt eine Reihe von Painless-Skript-Prozessoren hinzu, um die Felder mit den Unigrammen, Bigrammen und Trigrammen zu entfernen.
Am Ende der Ingestions-Pipeline wird somit ein Packetbeat-Dokument mit den neuen zusätzlichen Feldern ingestiert, die das Ergebnis der ML-Prognosen enthalten. Abbildung 5 zeigt ein Beispiel für eine Ingestions-Pipeline-Konfiguration. Ausführliche Informationen finden Sie im Beispiele-Repository.
PUT _ingest/pipeline/dga_ngram_expansion_inference
{
"description": "Expands a domain into unigrams, bigrams and trigrams and make a prediction of maliciousness",
"processors": [
{
"script": {
"id": "ngram-extractor-packetbeat",
"params":{
"ngram_count":1
}
}
},
{
"script": {
"id": "ngram-extractor-packetbeat",
"params":{
"ngram_count":2
}
}
},
{
"script": {
"id": "ngram-extractor-packetbeat",
"params": {
"ngram_count":3
}
}
},
{
"inference": {
"model_id": "dga-ngram-job-1587729368929",
"target_field": "predicted_label",
"field_mappings":{},
"inference_config": { "classification": {"num_top_classes": 2} }
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params":{
"ngram_count":1
}
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params":{
"ngram_count":2
}
}
},
{
"script": {
"id": "ngram-remover-packetbeat",
"params": {
"ngram_count":3
}
}
}
]
}
Da nicht in jedem Packetbeat-Dokument eine DNS-Anforderung enthalten ist, müssen wir dafür sorgen, dass die Ingestions-Pipeline nur dann ausgeführt wird, wenn die benötigten DNS-Felder im ingestierten Dokument vorhanden sind. Dazu können wir mithilfe eines Pipeline-Prozessors (siehe Konfiguration in Abbildung 6) prüfen, ob die gewünschten Felder vorhanden sind und Werte enthalten, und dann die Verarbeitung des Dokuments an die in Abbildung 5 definierte Pipeline dga_ngram_expansion_inference umleiten. Die unten gezeigte Konfiguration eignet sich für einen Prototyp, aber für einen Produktionsanwendungsfall muss die Ingestions-Pipeline Fehlerbehandlungsmechanismen enthalten. Ausführliche Informationen zu Konfigurationen und entsprechende Anleitungen finden Sie im Beispiele-Repository.
PUT _ingest/pipeline/dns_classification_pipeline
{
"description": "A pipeline of pipelines for performing DGA detection",
"version": 1,
"processors": [
{
"pipeline": {
"if": "ctx.containsKey('dns') && ctx['dns'].containsKey('question') && ctx['dns']['question'].containsKey('registered_domain') && !ctx['dns']['question']['registered_domain'].empty",
"name": "dga_ngram_expansion_inference"
}
}
]
}
Anwendung der Anomalieerkennung auf die Inferenzergebnisse als Analytics-Methode zweiter Ordnung
Das Modell, das wir in Teil 1 der Serie trainiert haben, hatte eine Falsch-positiv-Quote von 2 %. Das mag zwar recht niedrig klingen, aber man darf nicht vergessen, dass der DNS-Traffic in der Regel mit sehr großen Datenmengen verbunden ist. Daher kann auch bei einer Falsch-positiv-Quote von „nur“ 2 % die Zahl der als schädlich eingestuften Abfragen recht hoch sein. Um die Zahl der falsch positiven Ergebnisse zu reduzieren, könnte man sich daran machen, das Feature-Engineering zu intensivieren. Oder aber man unterzieht die Ergebnisse unserer Klassifizierung einer Anomalieerkennung. Sehen wir uns an, wie wir Letzteres im Elastic Stack bewerkstelligen können.
Als Erstes stellen wir fest, dass wir beim Plotten der Zahl der als schädlich eingestuften angereicherten Packetbeat-Dokumente gegen die Zeit eine Zeitreihe erhalten (Abbildung 7).
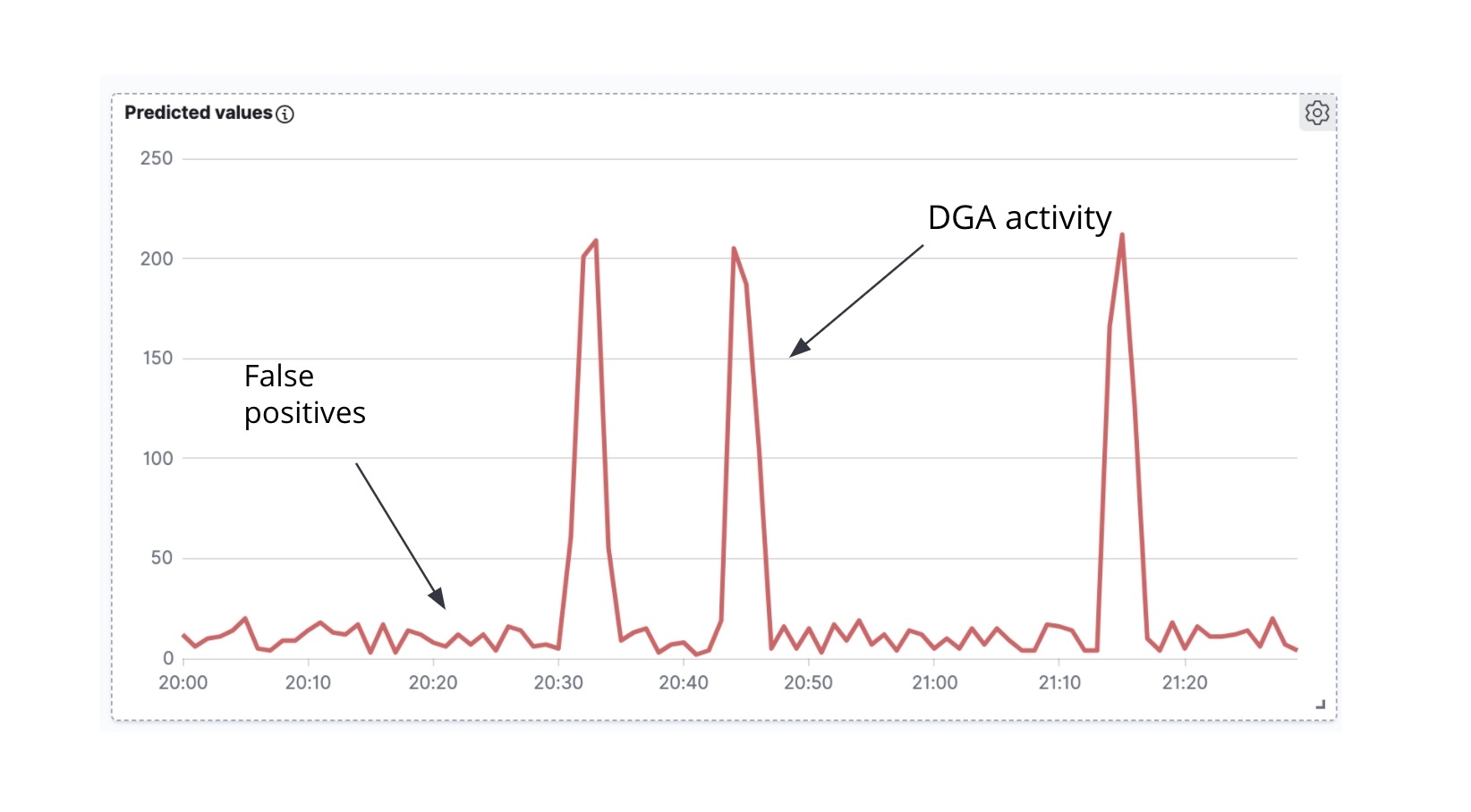
Als Zweites ist festzustellen, dass DGA-Malware häufig (wenn auch nicht immer) beim Versuch der aktiven Kommunikation mit dem C&C-Server eine ganze Welle von DNS-Anforderungen lostritt (d. h., die Malware geht viele der vom Algorithmus generierten Domains durch und versucht, die IP-Adresse jeder dieser Domains aufzulösen). In der Zeitreihenanalyse der prognostizierten Schad-Domains im Zeitverlauf (Abbildung 6) sind Aktivitätsspitzen sowie geringes Rauschen zwischen den Spitzen zu bemerken. Die Spitzen zeigen, dass unser Klassifizierungsmodell innerhalb eines kurzen Zeitraums viele Domains als Schad-Domains eingestuft hat, sodass wir daher mit einiger Wahrscheinlichkeit davon ausgehen können, dass wir es mit einem echten DGA zu tun haben. Dagegen ist das Hintergrundrauschen zwischen den Spitzen sehr wahrscheinlich auf falsch positive Ergebnisse zurückzuführen. Genau diese Intuition ist es, die wir für die Erstellung eines high_count-Anomalieerkennungsjobs für diese Zeitreihe nutzen werden.
Wenn wir die Anomalieerkennungs-Zeitleiste und die Zeitreihe in Abbildung 7 miteinander vergleichen, sehen wir, dass die Anomalie-Alerts, die wir erhalten, mit den Spitzen in der Zeitreihe (der echten DGA-Aktivität) korrespondieren und es in den Intervallen zwischen den Spitzen (dem Hintergrundrauschen der falsch positiven Ergebnisse) keine Alerts gibt.
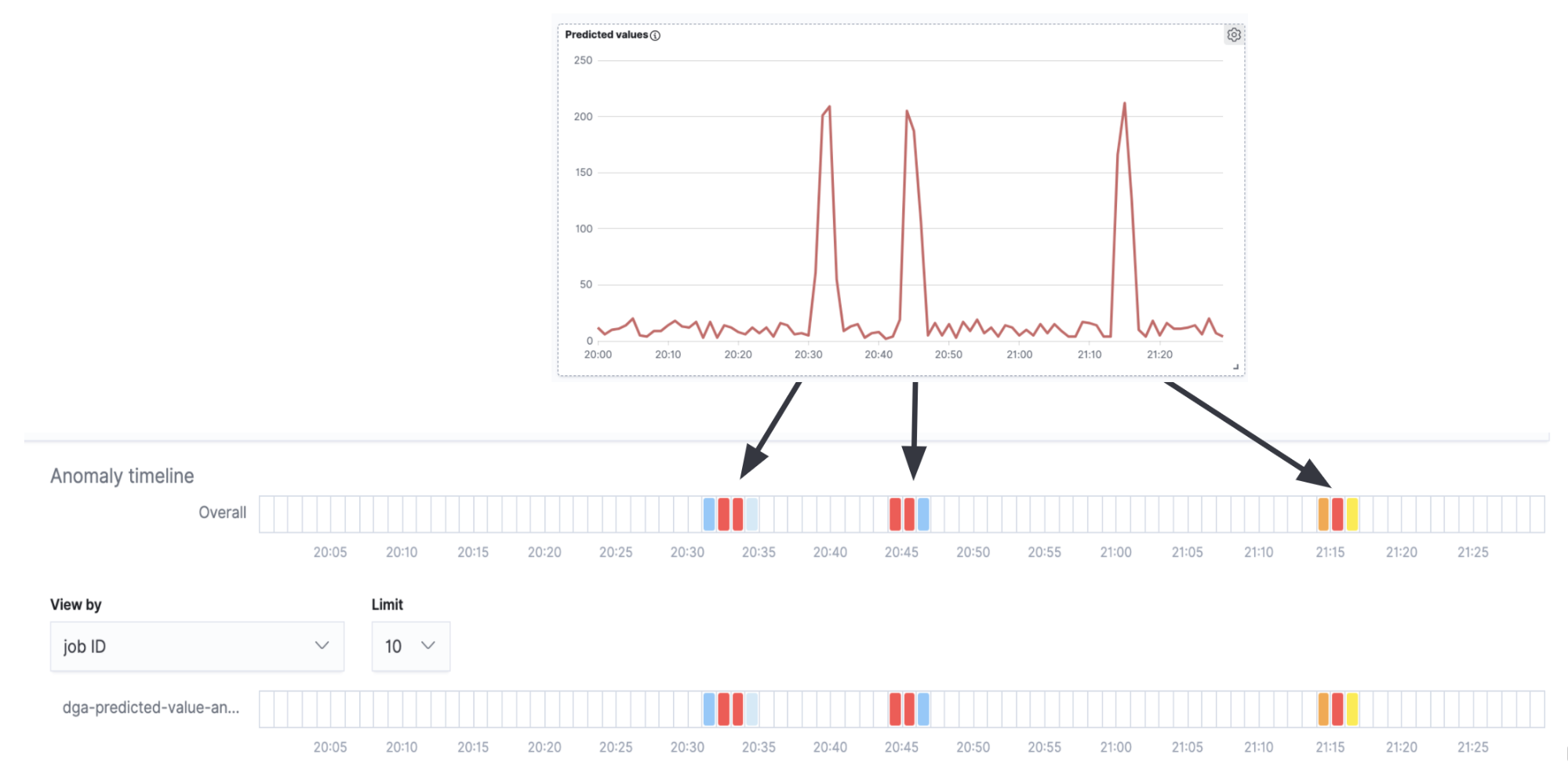
Auch wenn dieses Beispiel sehr einfach gehalten wurde und für den Einsatz in einer Produktionsumgebung sicherlich noch Einiges an Feinjustierung und Konfiguration erforderlich ist, zeigt es doch, dass Anomalieerkennungsjobs für eine Inferenzergebnis-Analyse zweiter Ordnung effektiv sein können.
Fazit
In diesem Blogpost haben wir ein trainiertes Klassifizierungsmodell verwendet, um Netzwerkdaten (Packetbeat-Dokumente) beim Ingestieren mit Informationen anzureichern. Der Anreicherungsprozess, der durch den Inferenzprozessor und Ingestions-Pipelines möglich gemacht wird, fügt jeder Domain, die in einer DNS-Anforderung abgefragt wird, eine prognostische Einstufungsinformation hinzu. Dieser kann entnommen werden, wie groß die Wahrscheinlichkeit ist, dass es sich um eine Schad-Domain handelt. Um die Zahl falsch positiver Alerts zu reduzieren, haben wir uns auch angeschaut, wie die Ergebnisse der Inferenz mit einem Anomalieerkennungsjob verifiziert werden können. Wir planen darüber hinaus, in Elastic SIEM eine kuratierte Konfiguration und Modelle für die DGA-Erkennung bereitzustellen.
Wenn Sie sich ansehen möchten, wie das Ingestieren und Analysieren mit Ihren eigenen Netzwerkdaten funktioniert, können Sie Elasticsearch Service 14 Tage lang kostenlos ausprobieren. Außerdem können Sie Machine Learning kostenlos 30 Tage lang ausprobieren, indem Sie den Elastic Stack herunterladen und lokal eine Probelizenz verwenden. Oder Sie nutzen das kostenlose und offene Elastic SIEM, um heute noch damit zu beginnen, Ihre Daten zu schützen.