Vom Konzept zur Realität: Elastic stellt neue, Pipe-basierte Abfragesprache vor: ES|QL


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Wir freuen uns, die Veröffentlichung der technische Vorschau von ES|QL (Elasticsearch Query Language), der neuen, Pipe-basierten Abfragesprache von Elastic®, bekanntgeben zu dürfen, die Datenuntersuchungen transformiert, vereinfacht und verbessert. ES|QL wird von einer neuen Abfrage-Engine angetrieben und liefert erweiterte Suchfunktionen mit paralleler Verarbeitung, was sich positiv auf die Geschwindigkeit und Effizienz von Suchen auswirkt – unabhängig von Datenquelle und ‑struktur. Die Möglichkeit, von einem einzigen Bildschirm aus verschiedene Aggregationen und Visualisierungen zu erstellen, beschleunigt die Lösung von Problemen und sorgt für einen iterativen und reibungslosen Workflow.

Kontinuierliche Weiterentwicklung von Elasticsearch
Elasticsearch® hat sich in den vergangenen 13 Jahren erheblich weiterentwickelt und sich kontinuierlich an die Bedürfnisse der Nutzer:innen und die sich verändernde digitale Landschaft angepasst. Ursprünglich als Tool für die Volltextsuche gedacht, bedient Elasticsearch heute – aufbauend auf dem Feedback der Nutzer:innen – eine Vielzahl von Anwendungsfällen. Dabei leistete Elasticsearch Query DSL, unsere erste Suchanfragensprache, mit einem umfangreichen Satz von Abfragen für Filter, Aggregationen und andere Operationen, hervorragende Dienste. Diese JSON-basierte DSL bildete letztendlich die Grundlage für unseren _search-API-Endpoint.
Im Laufe der Jahre und im Zuge der Diversifizierung der Bedürfnisse wurde deutlich, dass die Nutzer:innen mehr wollten als das, was Query DSL zu bieten imstande war. Aus diesem Grund begannen wir damit, unter unserer Query DSL zusätzliche DSLs fürs Scripting oder für Ereignisse bei Security-Untersuchungen und vieles mehr einzuführen und einzuflechten. So vielseitig diese Ergänzungen auch waren, war es mit ihnen nicht möglich, alle Anforderungen unserer Nutzer:innen vollständig abzudecken.
Die Nutzer:innen wünschten sich eine Abfragesprache, die die folgenden Kriterien erfüllt:
- Sie vereinfacht Bedrohungs- und Sicherheitsuntersuchungen bei gleichzeitiger Beobachtung und Lösung von Produktionsproblemen durch eine einzige Abfrage, die einen umfassenden und iterativen Ansatz liefert.
- Sie optimiert Datenuntersuchungen durch Suchen, Anreichern, Aggregieren, Visualisieren und vieles mehr – alles von einer zentralen Benutzeroberfläche aus.
- Sie nutzt erweiterte Suchfunktionen wie Datenbankabfragen mit paralleler Verarbeitung zur Verbesserung der Geschwindigkeit und Effizienz beim Suchen in großen Datenmengen, unabhängig von Quelle und Struktur.
Vom Konzept zur Realität – unsere neue Abfragesprache ES|QL
Wir haben unseren Nutzer:innen zugehört und können jetzt voller Stolz unsere neue innovative Pipe-basierte Abfragesprache Elasticsearch Query Language (ES|QL) präsentieren – eine einzige, zentralisierte Methode und Sprache für die Interaktion mit Daten in Elasticsearch, ohne die Daten vorher in externe Systeme zur speziellen Verarbeitung übertragen zu müssen. Im Unterschied zu anderen Sprachen, die bei Elastic im Laufe der Jahre zum Einsatz gekommen sind, wie z. B. Query DSL, wurde ES|QL von Grund auf speziell mit Blick auf eine deutliche Vereinfachung von Datenuntersuchungen und ein hohes Maß an Nutzerfreundlichkeit konzipiert und entwickelt, ohne dass fortgeschrittene Nutzer:innen Einbußen bei der Leistungsfähigkeit hinnehmen müssen.
ES|QL-Beispielbefehl:
from logstash-*
| stats avg_bytes = avg(bytes) by geo.src
| eval avg_bytes_kb = round(avg_bytes/1024, 2)
| enrich geo-data on geo.src with country, continent
| keep avg_bytes_kb, geo.src, country, continent
| limit 4ES|QL-Beispielergebnis:
| avg_bytes_kb | geo.src | country | continent |
| 8.84 | BD | Bangladesh | Asia |
| 6.92 | BR | Brazil | Americas |
| 2.75 | CI | Côte d'Ivoire | Africa |
| 4.55 | CL | Chile | Americas |
Optimierte Einfachheit – mit einer UI, die speziell auf verbesserte und iterative Workflows zugeschnitten ist
Für die Erkennung von Angriffen oder die Navigation durch Observability-Daten braucht es Funktionen zum Filtern, Durchsuchen, Transformieren und Aggregieren äußerst großer Datenmengen. Mit ES|QL können Sie all dies mit einer einzigen Abfrage tun.
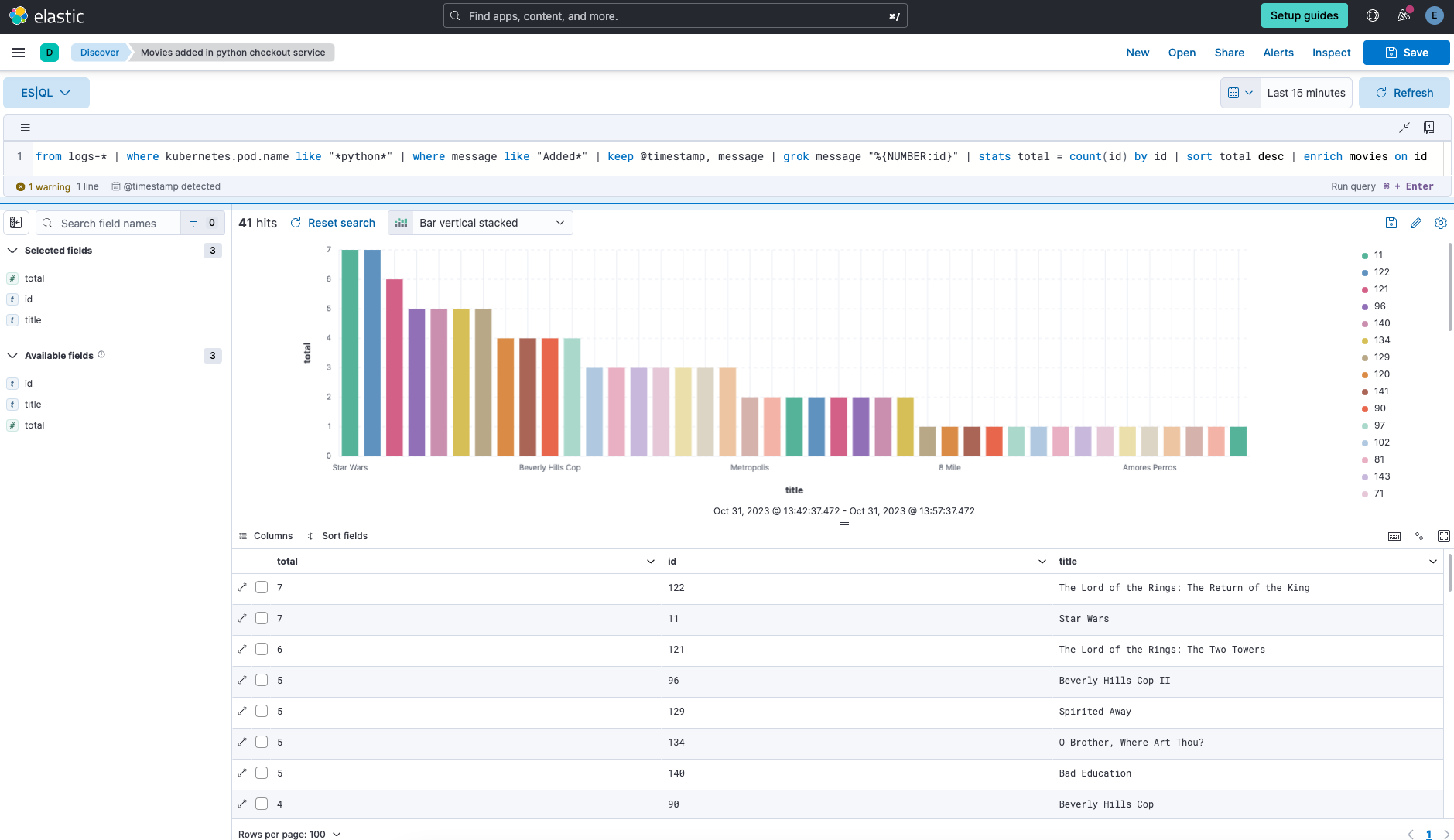
Das ständige Umschalten zwischen Kontexten oder die Nutzung vieler verschiedener Bildschirme, um das Gewünschte zu finden, kostet oft Zeit und Nerven. ES|QL bietet von einem zentralen Bildschirm aus Syntax zur automatischen Vervollständigung, integriert die Produktdokumentation und visualisiert die Suchergebnisse. So wird ein unterbrechungsfreier und effizienter Ablauf bei Datenabfragen sichergestellt. Ganz gleich, ob es um Security, Observability oder Search geht – ES|QL sorgt für mehr Effizienz, eine höhere Geschwindigkeit und eine größere Tiefe bei der Untersuchung von Daten.
ES|QL-Parallelität – zwei Threads sind besser als einer
Angetrieben von einer robusten Abfrage-Engine bietet ES|QL erweiterte Suchfunktionen mit paralleler Verarbeitung, sodass Nutzer:innen nahtlos Daten aus verschiedenen Datenquellen und ‑strukturen abfragen können.
Es erfolgen keine Übersetzungen oder Transpilationen in Query DSL. Stattdessen wird jede Abfrage in ES|QL zunächst aufgeschlüsselt, dann interpretiert und validiert und anschließend für eine bestmögliche Performance aufgewertet. Dann wird ein Prozess für die Ausführung der Abfrage auf verschiedenen Knoten innerhalb des Clusters festgelegt. Die Zielknoten bearbeiten die Abfrage und nehmen während der Ausführung mithilfe des von ES|QL bereitgestellten Frameworks Ad-hoc-Anpassungen am Ausführungsplan vor. Das Ergebnis sind blitzschnelle Abfragen – out of the box. Sehen wir uns zu Vergleichszwecken als Beispiel die nächtlichen Benchmark-Tests an.
Plattforminnovationen für bessere Elastic-Lösungen
Von den Features und Innovationen, die mit Elastic und Kibana® geliefert werden, profitieren alle Elastic-Lösungen: Search, Observability und Security. ES|QL verändert die User Experience bei diesen Lösungen grundlegend und bietet einen einfachen, aber leistungsstarken Workflow für die Datenuntersuchung.
ES|QL verbessert Elastic Security
ES|QL verändert grundlegend die Art und Weise, wie Analyst:innen Bedrohungen aufspüren, und es stärkt die Bedrohungserkennung. Die neue Abfragesprache, in deren Entwicklung umfangreiches Feedback aus der Community eingeflossen ist, nutzt das Potenzial von Pipe-basierten Abfragen, kombiniert es mit der Geschwindigkeit von Elasticsearch und verbessert damit die SIEM-, Endpoint-Security- und Cloud-Security-Fähigkeiten von Elastic Security.
- Schnelle und iterative Suche: Wichtig für das erfolgreiche Verfolgen von Anzeichen für eine aufkommende Bedrohung sind schnelles Handeln und eine Sprache, die einen iterativen Workflow ermöglicht.
- Anreichern von Ergebnissen mit Kontext: Mit ES|QL können Analyst:innen verdächtige IP-Adressen mit bekannten Threat-Intelligence-Datenbanken korrelieren, was sofortige Klarheit in Bezug auf potenzielle Bedrohungen schafft.
- Transformieren von Daten: ES|QL ermöglicht es Nutzer:innen, ihre Daten zu manipulieren, indem sie neue Felder definieren oder nicht normalisierte Daten parsen, um Daten klar und relevant zu machen.
- Aggregieren von Daten: Die Ergebnisse können konsolidiert und aggregiert werden, was den Weg für tiefere Analysen und Erkenntnisse ebnet.
Elastic ist die einzige Suchplattform, die die Effizienz einer Schema-on-Write-Architektur mit dem iterativen Sucherlebnis einer Pipe-basierten Schema-on-Read-Abfragesprache verbindet. Dank unglaublich schneller Suche – und maximaler Sichtbarkeit der Suchergebnisse – kommen Analyst:innen mit jeder weiteren Pipe ihrem Ziel ein Stück näher.
ES|QL verbessert auch die leistungsfähige Erkennungs-Engine von Elastic Security. Unternehmen können aggregierte Werte in die Erkennungsregeln einbeziehen, um der drohenden Alarmmüdigkeit vorzubeugen, die Relevanz von Alerts zu verbessern und eine weitere Möglichkeit zur Verhaltenserkennung zu bieten. Dank Inline-Evaluation lassen sich ES|QL-basierte Regeln iterativ entwickeln und verfeinern. Abfragen werden im Plaintext-Format formatiert, was die Zusammenarbeit vereinfacht und die Erkennung als Code (Detection as Code) unterstützt.
ES|QL verbessert Elastic Observability
SREs, die Elastic Observability nutzen, können mit ES|QL Logs, Metriken, Traces und Profiling-Daten analysieren, sodass sie mit einer einzigen Abfrage Engpässe bei der Performance und Systemprobleme ermitteln können. Die Verwaltung von Daten mit hoher Dimensionalität und hoher Kardinalität mit ES|QL in Elastic Observability profitiert von den folgenden Vorteilen:
- Entfernen von Signalrauschen: Mit ES|QL-Alerting verbessert sich die Erkennungsgenauigkeit, weil nicht einzelne Sicherheitsvorfälle, sondern signifikante Trends im Vordergrund stehen. Das führt dazu, dass die Zahl der Fehlalarme sinkt und die gesendeten Benachrichtigungen verwertbare Erkenntnisse bieten. SREs können diese Alerts über die Elastic-API verwalten und sie in DevOps-Prozesse integrieren.
- Verbesserte Analyse mit Erkenntnissen: ES|QL kann Observability-Daten unterschiedlichster Art verarbeiten, einschließlich Anwendungs-, Infrastruktur-, Geschäftsdaten und viele mehr. Dabei spielen weder die Quelle noch die Struktur der Daten eine Rolle. ES|QL kann die Daten problemlos mit zusätzlichen Feldern und Kontext anreichern, sodass mit einer einzigen Abfrage ganze Visualisierungen für Dashboards oder Problemanalysen erstellt werden können.
- Geringere MTTR: Die Kombination aus AIOps und AI Assistant von Elastic Observability und ES|QL ermöglicht das Identifizieren von Trends, das Isolieren von Incidents und die Senkung der Zahl falsch-positiver Ergebnisse, sodass die Erkennungsgenauigkeit steigt. Diese Verbesserung des Kontexts erleichtert das Troubleshooting und die schnelle Lokalisierung und Lösung von Problemen.
ES|QL in Elastic Observability verbessert nicht nur die Fähigkeit von SREs, die Customer Experience, den Umsatz des Unternehmens und die SLOs effektiver zu verwalten, sondern erleichtert auch die Zusammenarbeit mit Entwicklungs- und DevOps-Teams, indem kontextualisierte, aggregierte Daten bereitgestellt werden.
ES|QL unterstützt Elastic Search
Mit ES|QL können mit einer einzigen Abfrage Daten abgerufen, aggregiert, berechnet und transformiert werden. Nutzer:innen profitieren von wichtigen Funktionen wie der Möglichkeit, im Zuge der Abfrage Felder zu definieren, Datenanreicherungen vorzunehmen und Abfragen parallel zu verarbeiten. Mit ES|QL können Sie Ihre Daten auf die unterschiedlichsten Weisen kennenlernen und erkunden. Von der Nutzung von Clients für die direkte API/Code-Integration bis hin zur Visualisierung von Ergebnissen vom selben Bildschirm aus – ES|QL rationalisiert Ihre Datenuntersuchungen und sorgt dafür, dass Sie mühelos und einfach das Beste aus Ihren Datenbeständen herausholen.
Die Orientierung von ES|QL auf das Design zeigt sich in der Fähigkeit, die Komplexität von Code zu reduzieren, was letztendlich Kosten und Zeit spart. Durch die einfachere Möglichkeit der Wiederverwendung von Suchergebnissen in nachfolgenden Suchen minimiert ES|QL den Rechenaufwand und macht komplizierte Skripte und redundante Abfragen überflüssig. ES|QL ist nicht nur eine API, sondern eine einfache und leistungsfähige Möglichkeit, Ihre Herangehensweise an die Suche zu verändern.
Beginnen Sie Ihre ES|QL-Journey
Die Zukunft der Datenerkundung und ‑manipulation beginnt jetzt. Elastic lädt Security Analysts, SREs und Entwickler:innen ein, diese transformative Sprache selbst zu erleben und neue Horizonte für ihre Datenaufgaben zu erschließen. Lernen Sie mehr über die Möglichkeiten mit ES|QL (derzeit als technische Vorschau erhältlich) oder probieren Sie Elastic kostenlos aus.
Die Entscheidung über die Veröffentlichung von Features oder Leistungsmerkmalen, die in diesem Blogpost beschrieben werden, oder über den Zeitpunkt ihrer Veröffentlichung liegt allein bei Elastic. Möglicherweise werden aktuell nicht verfügbare Features oder Funktionen nicht rechtzeitig oder gar nicht bereitgestellt.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken