Importieren von CSV- und Logdaten in Elasticsearch mit File Data Visualizer
Zu den neuen Features im Elastic Stack 6.5 gehört der File Data Visualizer. Mit ihm können Nutzer Dateien mit trennzeichengetrennten Daten (wie CSV-Dateien), NDJSON-Dateien oder semistrukturierten Text (wie Logdateien) hochladen und vom neuen Elastic-Machine-Learning-Endpunkt find_file_structure analysieren lassen. Als Ergebnis der Analyse werden unter anderem Vorschläge zur Ingestieren-Pipeline und zu Mappings unterbreitet, die genutzt werden können, um die Datei aus der Benutzeroberfläche in Elasticsearch zu importieren.
Auf diese Weise können Nutzer, die ihre Daten mit Kibana oder Machine Learning erkunden möchten, schnell und einfach kleine Datenmengen in Elasticsearch importieren, ohne sich eingehender mit dem Ingestieren-Prozess beschäftigen zu müssen.
In diesem Blogpost hat jemand vom Elastic-Marketingteam, der selbst keinen Programmierhintergrund hat, vor Kurzem anschaulich beschrieben, wie einfach das ist. Mit dem File Data Visualizer konnte er ohne Weiteres Erdbebendaten in Elasticsearch importieren und mithilfe von geo_point-Visualisierungen in Kibana visualisieren, um die geografische Verbreitung von Erdbeben zu erkunden und zu analysieren.
Beispiel: Importieren einer CSV-Datei in Elasticsearch
Am besten lässt sich diese Funktionalität erklären, wenn wir uns ein Beispiel ansehen. Wir nehmen dazu Daten aus einer CSV-Datei, die imaginäre Daten von einer Flugbuchungswebsite enthält. Im Folgenden werden nur die ersten fünf Zeilen präsentiert, damit Sie eine Vorstellung davon erhalten, wie diese Daten aussehen:
time,airline,responsetime 2014-06-23 00:00:00Z,AAL,132.2046 2014-06-23 00:00:00Z,JZA,990.4628 2014-06-23 00:00:00Z,JBU,877.5927 2014-06-23 00:00:00Z,KLM,1355.4812
Konfigurieren des CSV-Imports im File Data Visualizer
Der File Data Visualizer ist in Kibana im Abschnitt Machine Learning > Data Visualizer zu finden. Der Nutzer sieht eine Seite, auf der er eine Datei auswählen oder per Drag & Drop ablegen kann. Zumindest in Version 6.5 darf die Datei nicht größer als 100 MB sein.
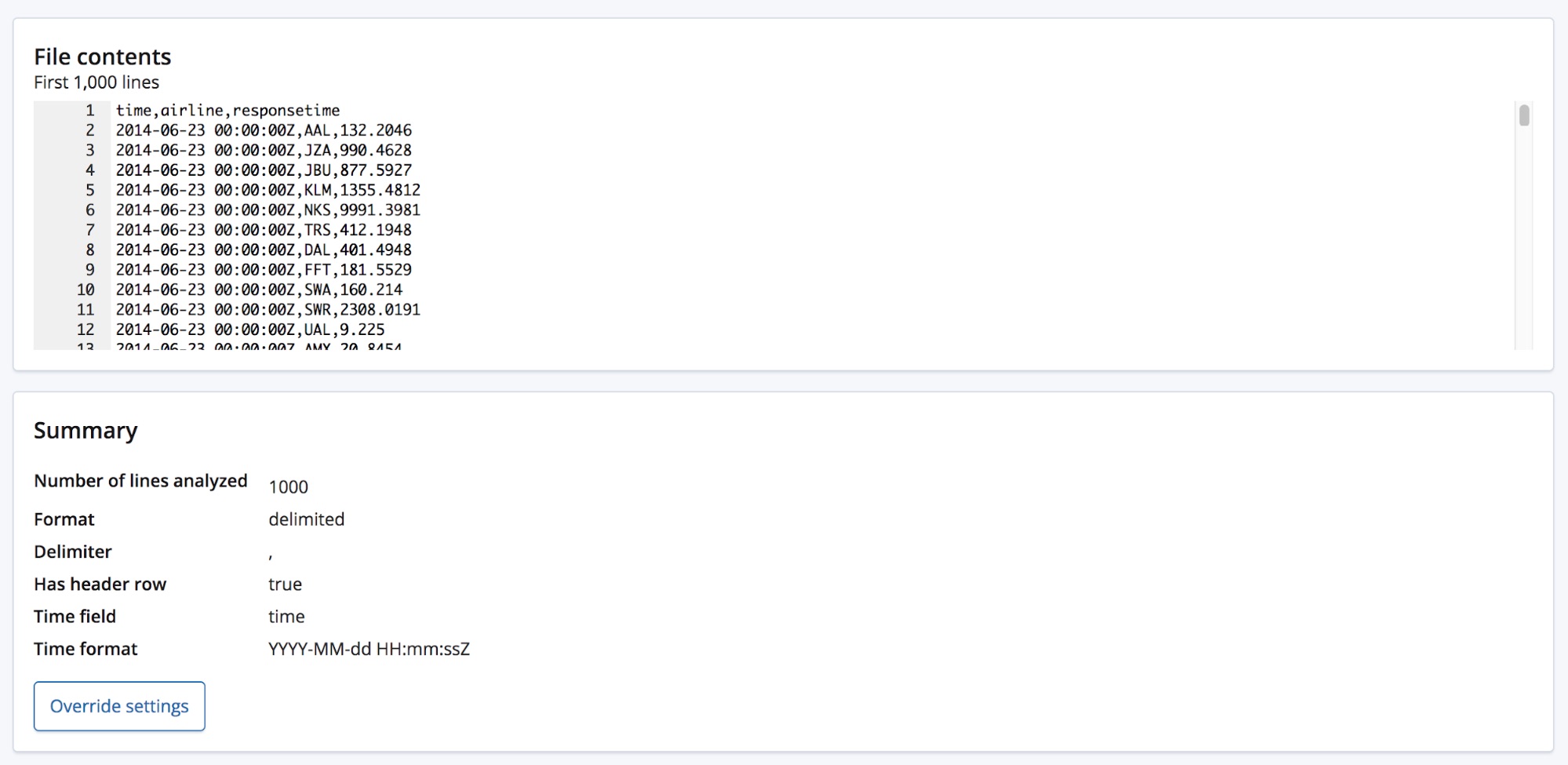
Wenn wir die CSV-Datei auswählen, sendet die Seite die ersten 1000 Zeilen aus der Datei an den Endpunkt find_file_structure, der die Datei analysiert und dann die Ergebnisse zurückgibt. Ein Blick auf den Abschnitt Summary zeigt, dass der Endpunkt korrekt erkannt hat, dass die Daten in einem trennzeichengetrennten Format vorliegen und dass als Trennzeichen Kommas verwendet werden.
Auch dass es einen Header gibt, wurde richtig erkannt, und die dort vorgegebenen Feldnamen wurden genutzt, um die Daten in den einzelnen Spalten zu beschriften. Für die erste Spalte wurde eine Übereinstimmung mit einem bekannten Datumsformat festgestellt, sodass sie als Feld time zurückgegeben wird.
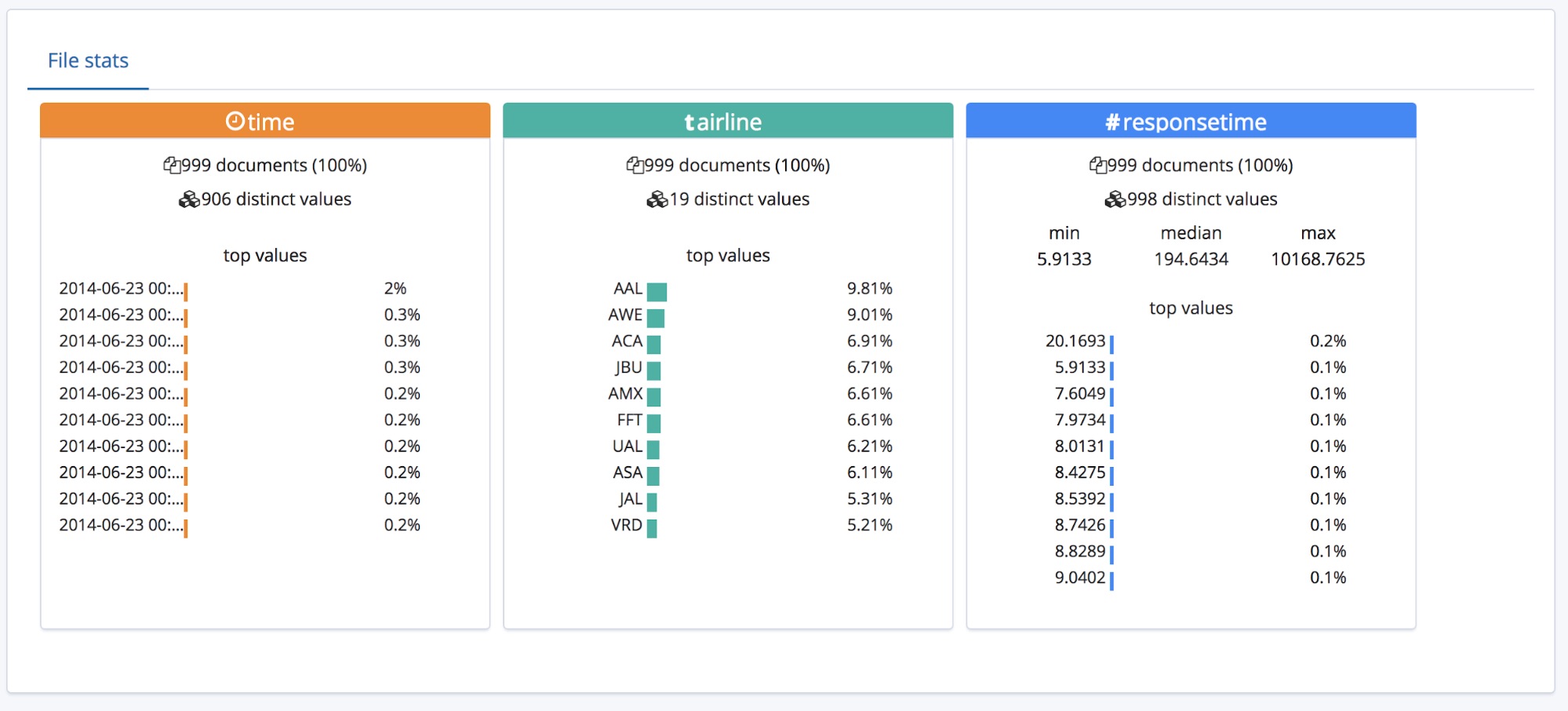
Unterhalb des Abschnitts Summary befindet sich der Abschnitt mit den Feldern, der allen, die schon einmal mit dem originalen Data Visualizer gearbeitet haben, bekannt vorkommen dürfte.
Wie wir sehen, wurden die Feldtypen bei allen drei Feldern richtig identifiziert, und für jedes Feld sind ein paar allgemeine statistische Informationen zu sehen. Für jedes Feld werden die 10 am häufigsten vorkommenden Werte aufgeführt. Bei responsetime, das als numerisches Feld erkannt wurde, werden zudem die Werte min, median und max angezeigt.
Für eine CSV-Datei mit Header ist das ja alles schön und gut, aber was, wenn es keine Header-Zeile gibt?
In diesem Fall verwendet der Endpunkt find_file_structure temporäre Feldnamen. Wir können dies demonstrieren, indem wir die erste Zeile aus der Beispieldatei entfernen und die Datei erneut hochladen. Jetzt tragen die Felder die allgemeinen Namen „column1“, „column2“ und „column3“.
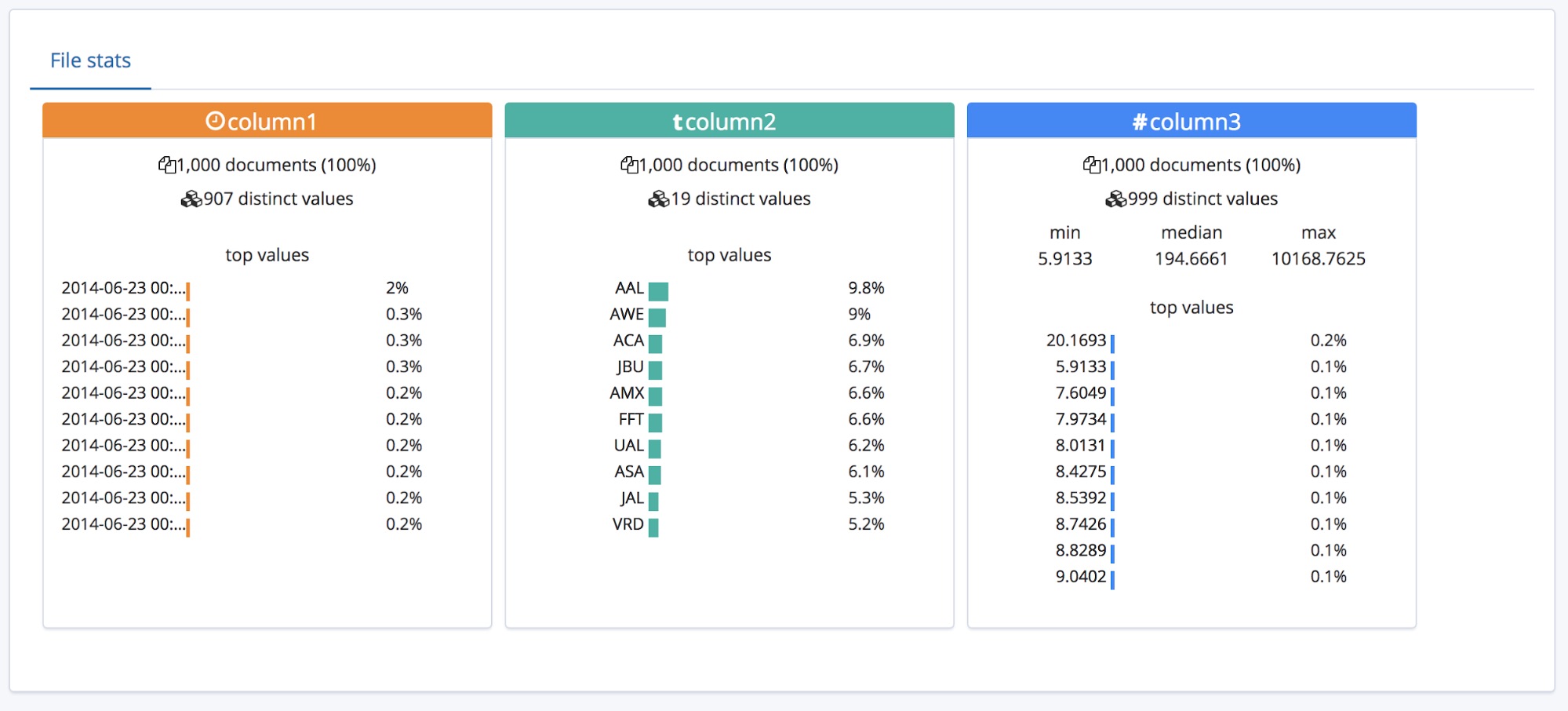
Wem diese Feldnamen zu allgemein sind, sodass er sie umbenennen möchte, kann die vorgegebenen Einstellungen über die Schaltfläche Override settings außer Kraft setzen.
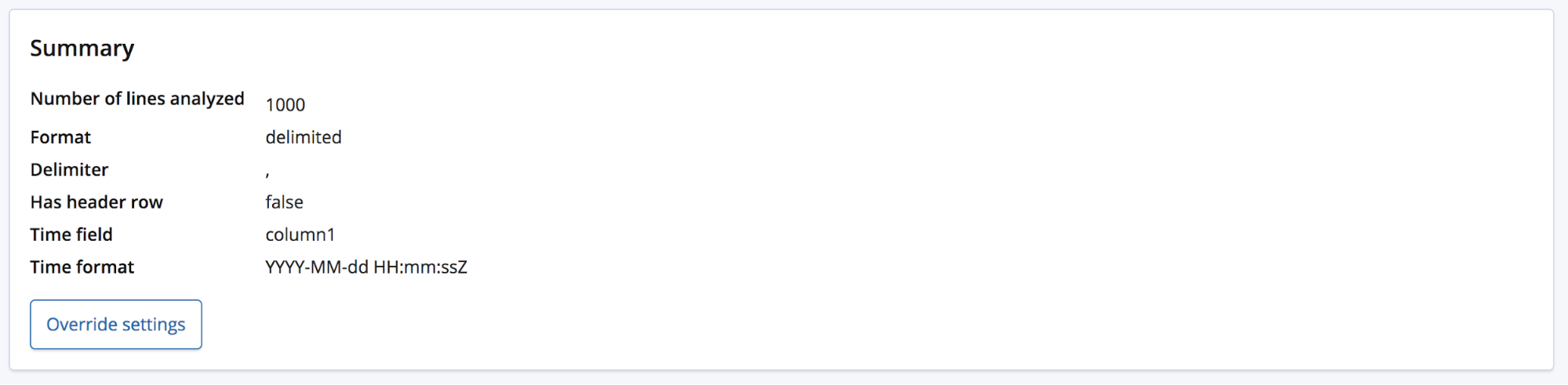
Der Nutzer kann nicht nur diese Felder umbenennen, sondern auch andere Einstellungen, wie das Datenformat, das Trennzeichen und das zu verwendende Anführungszeichen, ändern. Diese Einstellungen können also gewissermaßen zur Feinjustierung der Ergebnisse der find_file_structure-Datenanalyse verwendet werden. So können Sie beispielsweise festlegen, dass ein anderes als das vom Endpunkt gewählte erste Datumsfeld verwendet werden soll, oder die aus der Header-Zeile der Datei übernommenen Feldnamen ändern.
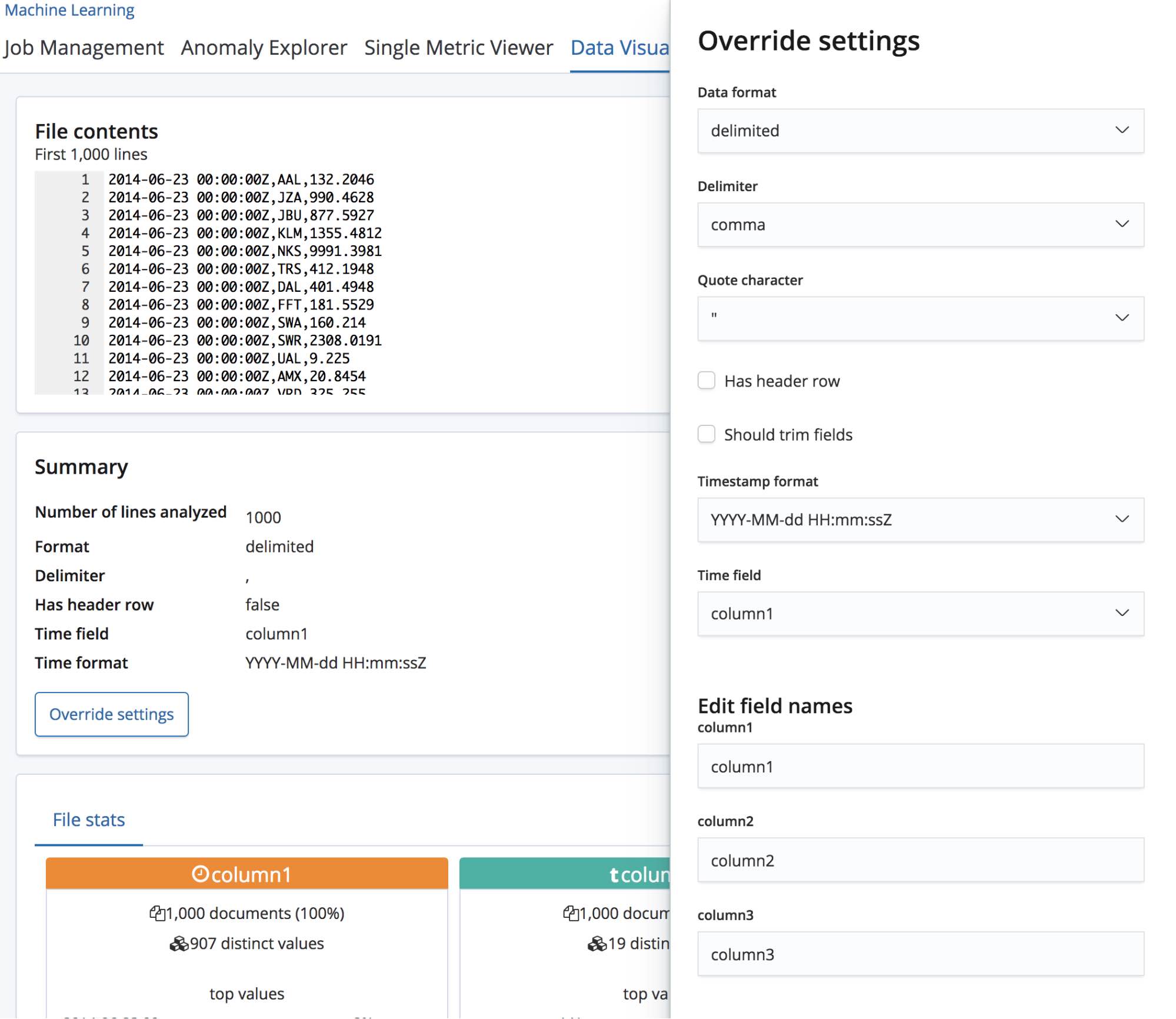
Wenn wir mit diesen Einstellungen zufrieden sind, klicken wir auf die Schaltfläche Import unten links auf der Seite.
Importieren der CSV-Daten in Elasticsearch
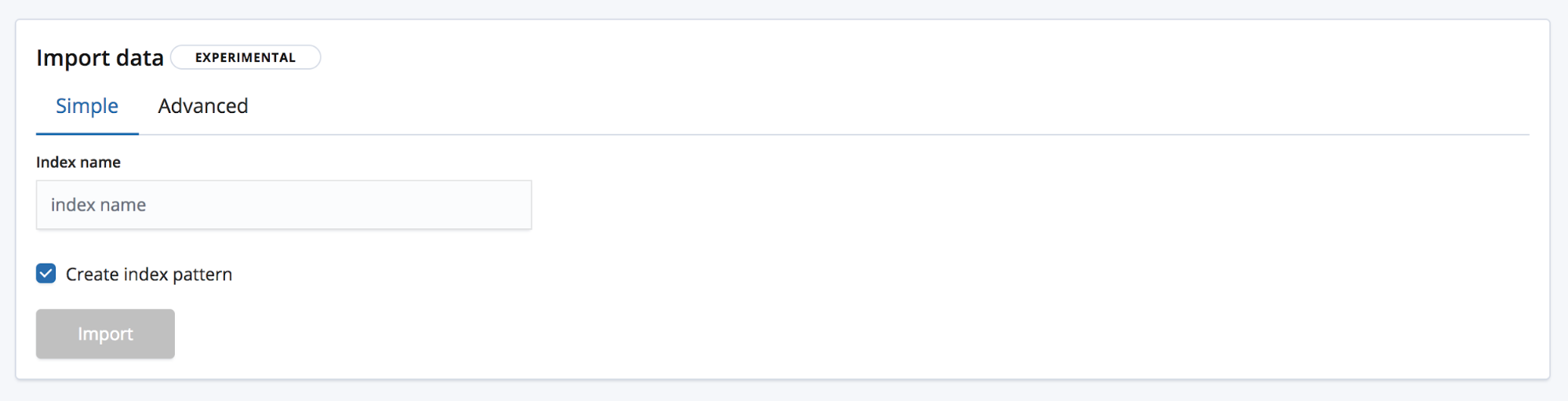
Wir sind jetzt auf der Seite „Import“, auf der wir die Daten in Elasticsearch importieren können. Dabei ist zu beachten, dass dieses Feature nicht dazu gedacht ist, Teil eines wiederholten Produktionsprozesses zu sein, sondern nur zur Ersterkundung der Daten dienen soll. Dies liegt hauptsächlich an fehlenden Automatisierungsoptionen, aber auch daran, dass es sich derzeit noch im Experimentierstadium befindet.
Für das Importieren gibt es zwei Modi: Der erste heißt Simple und der Nutzer muss hier nur einen neuen eindeutigen Indexnamen angeben und festlegen, ob auch ein Indexmuster erstellt werden soll.
Beim zweiten Modus, Advanced, hat der Nutzer weitergehende Möglichkeiten, die Einstellungen zur Indexerstellung zu justieren.
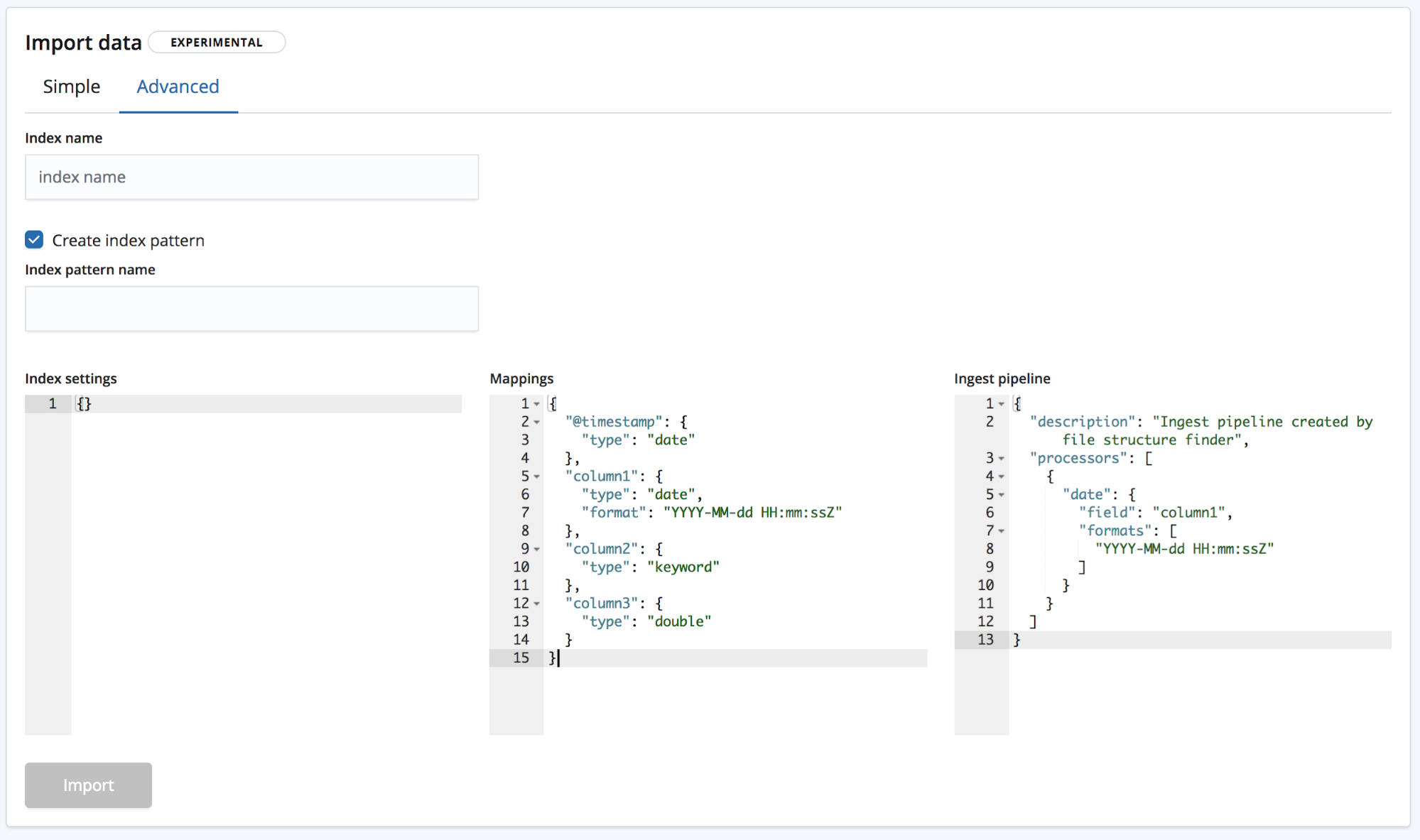
- Index settings – Standardmäßig sind für die Indexerstellung und das Importieren keine zusätzlichen Einstellungen erforderlich, aber es besteht die Möglichkeit, die Indexeinstellungen anzupassen.
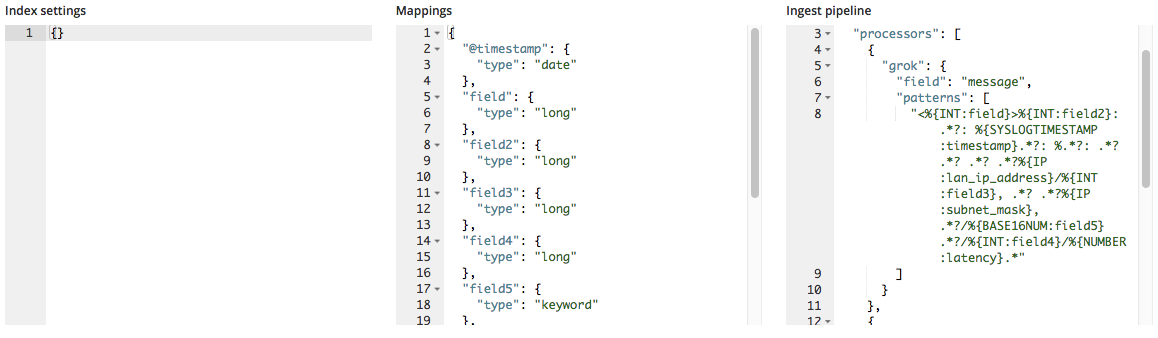
- Mappings – Der Endpunkt
find_file_structurestellt ein „Mappings“-Objekt auf der Basis der von ihm identifizierten Felder und Typen bereit. Eine Liste der möglichen Mappings finden Sie in unserer Elasticsearch-Mapping-Dokumentation. - Ingest pipeline – Der Endpunkt
find_file_structurestellt ein Standard-„Ingest pipeline“-Objekt bereit. Dieses wird beim Ingestieren der Daten verwendet und kann für das Hochladen zusätzlicher Daten eingesetzt werden.
In Version 6.5 wird nur das Erstellen neuer Indizes unterstützt; bestehenden Indizes können keine Daten hinzugefügt werden, um sie vor Beschädigung zu schützen.
Über die Schaltfläche „Import“ kann der Importprozess gestartet werden. Er besteht aus den folgenden Schritten:
- Verarbeiten der Datei – Die Daten werden in NDJSON-Dokumente umgewandelt, damit sie mit der Bulk-API ingestiert werden können.
- Erstellen des Index – Anhand der Einstellungen und der „Mappings“-Objekte wird der Index erstellt.
- Erstellen der Ingestieren-Pipeline – Anhand des „Ingest pipeline“-Objekts wird die Ingestieren-Pipeline erstellt.
- Hochladen der Daten – Daten werden in den neuen Elasticsearch-Index hochgeladen.
- Erstellen eines Indexmusters – Es wird ein Kibana-Indexmuster erstellt (wenn vom Nutzer gewünscht).

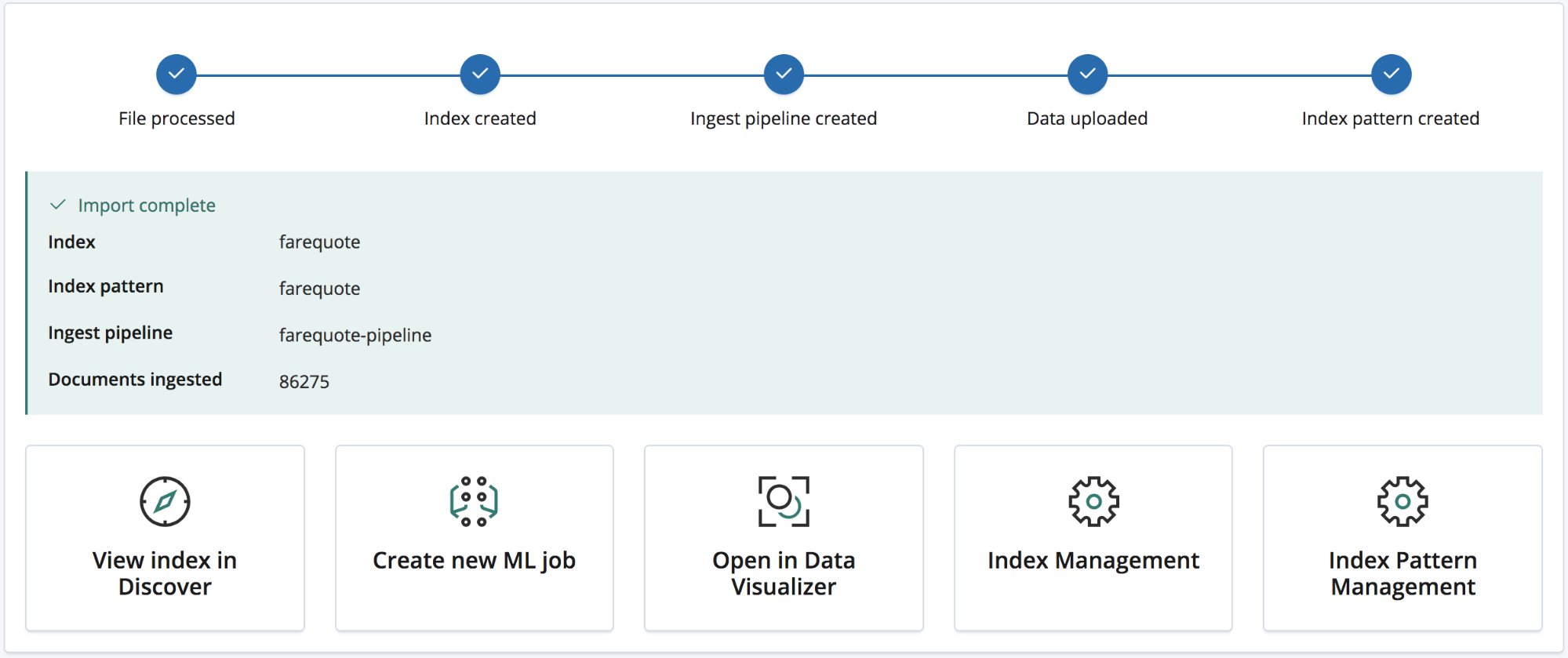
Nach dem Import wird eine Zusammenfassung präsentiert, die die erstellten Indexnamen, das Indexmuster und die Ingestieren-Pipeline enthält und Aufschluss über die Zahl der ingestierten Dokumente gibt.
Außerdem werden Kibana-Links zum Erkunden der neu importierten Daten angezeigt. Nutzer mit Platinum- und Test-Abonnement erhalten zudem einen Link, über den sie einen Machine-Learning-Job erstellen können, der auf den Daten basiert.
Beispiel: Importieren von Logdateien und anderem semistrukturiertem Text in Elasticsearch
Bisher ging es nur um CSV-Daten – und NDJSON ist noch einfacher und erfordert sehr wenig Verarbeitungsaufwand. Was ist aber mit semistrukturiertem Text? Sehen wir uns dazu an, wie sich die Analyse von CSV-Daten von der Analyse typischer Logdateidaten – also von semistrukturiertem Text – unterscheidet.
Das folgende Beispiel zeigt drei Zeilen aus einer von einem Router generierten Logdatei.
<190>38377: GOW45-AR002: Apr 18 08:44:02.434 GMT: %JHG_MS-6-ROUTE_EVENT_INFO: Route changed Prefix 10.156.26.0/23, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired <190>38378: GOW45-AR002: Apr 18 08:44:07.538 GMT: %JHG_MS-6-ROUTE_EVENT_INFO: Route changed Prefix 10.156.72.0/23, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired <190>38379: GOW45-AR002: Apr 18 08:44:08.818 GMT: %JHG_MS-6-ROUTE_EVENT_INFO: Route changed Prefix 10.156.55.0/24, BR 10.123.11.255, i/f Ki0/0/0.849, Reason None, OOP Reason Timer Expired
Der Endpunkt find_file_structure erkennt bei der Analyse korrekt, dass es sich um semistrukturierten Text handelt, und erstellt ein Grok-Muster, mit dessen Hilfe die Felder und deren Typen extrahiert werden. Dabei wird auch erkannt, welches Feld das „time“-Feld ist und welches Format verwendet wird.
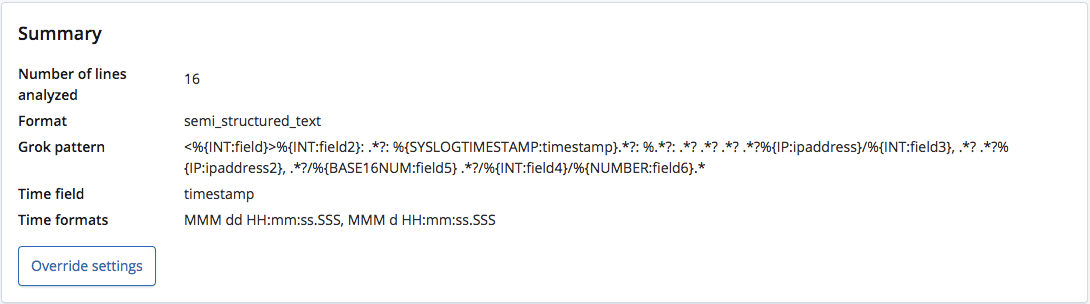
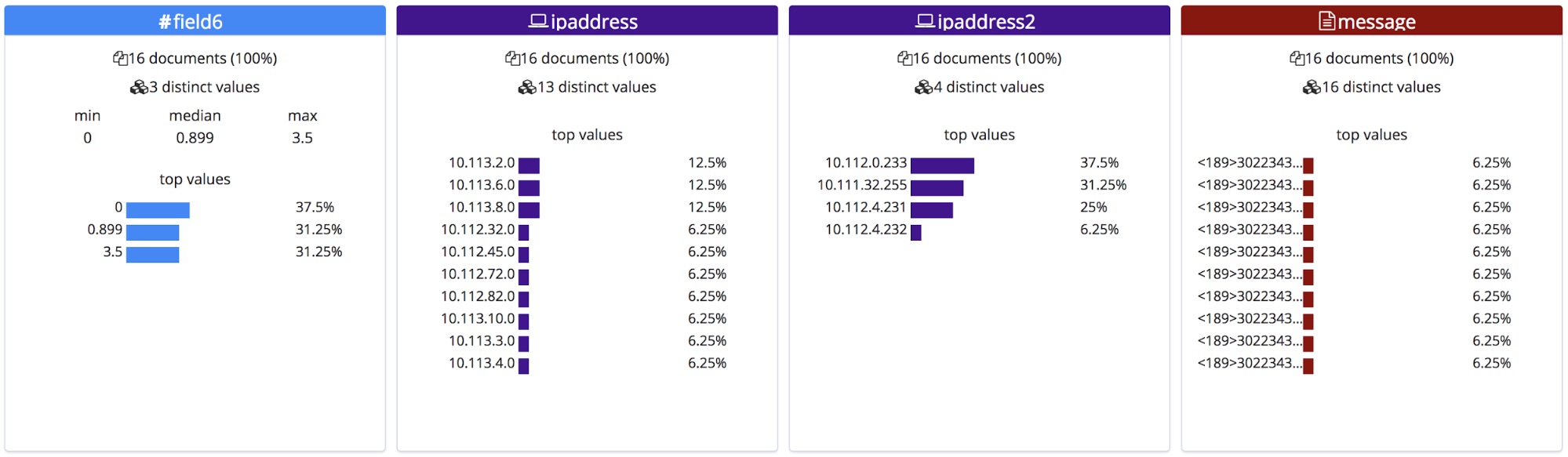
Im Gegensatz zu CSV-Dateien mit Header oder zu NDJSON-Dateien gibt es keine Möglichkeit, die korrekten Namen dieser Felder festzustellen. Der Endpunkt behilft sich damit, ihnen anhand ihres Typs allgemeine Namen zuzuweisen.
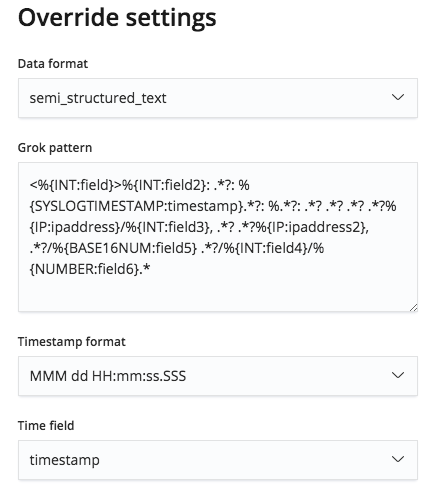
Dieses Grok-Muster kann jedoch über das Menü Override settings bearbeitet werden, sodass wir die Namen und Typen der Felder korrigieren können.
Im Abschnitt mit den statistischen Informationen zur Datei werden daraufhin die korrigierten Feldnamen angezeigt. Zu beachten ist, dass die Felder alphabetisch geordnet werden, sodass sich nach der Umbenennung die Reihenfolge ändern kann, wie hier zu sehen.
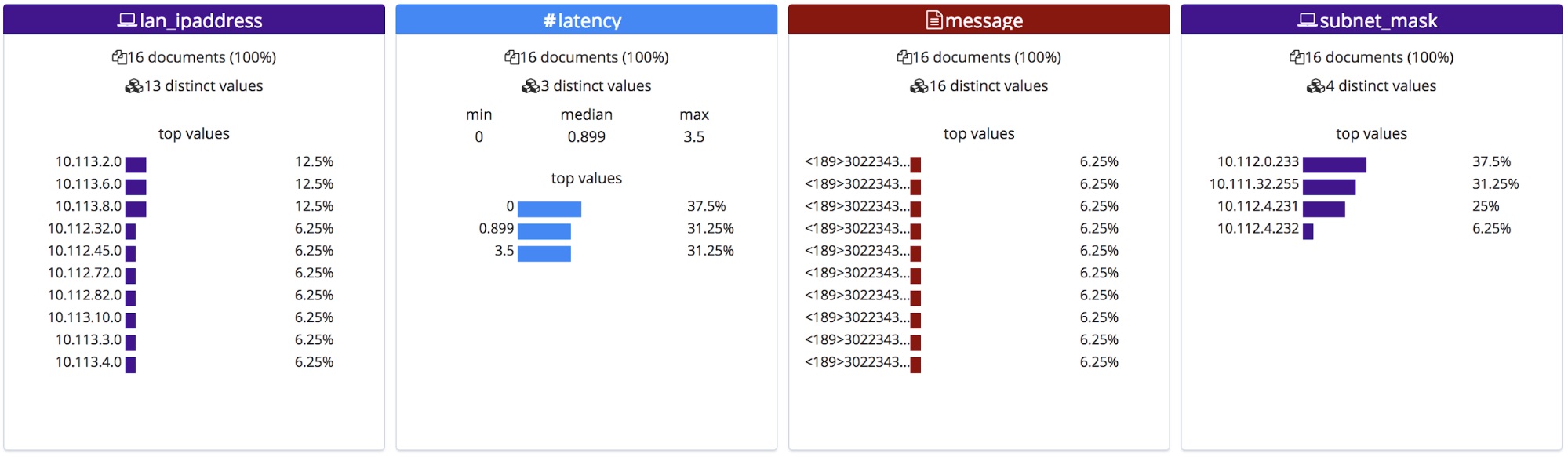
Nach dem Importieren werden dem „Mappings“-Objekt die neuen Feldnamen hinzugefügt, und die Liste der Prozessoren in der Ingestieren-Pipeline wird um das Grok-Muster erweitert.
Fazit
Wir hoffen, dass wir Ihnen ein wenig Appetit auf den neuen File Data Visualizer in 6.5 machen konnten. Es handelt sich dabei in 6.5 um ein Feature im Experimentierstadium, sodass wir nicht garantieren können, dass jedes Dateiformat korrekt identifiziert wird. Dennoch würden wir uns freuen, wenn Sie es einmal ausprobieren – und vielleicht uns anschließend wissen lassen, was Sie davon halten. Ihr Feedback hilft uns, das Feature schneller allgemein verfügbar zu machen.