Fünf technische Komponenten der Bildähnlichkeitssuche


 Share on Twitter
Share on TwitterAuf Twitter teilen

 Share on LinkedIn
Share on LinkedInAuf LinkedIn teilen

 Share on Facebook
Share on FacebookAuf Facebook teilen

 Share by Email
Share by EmailPer E-Mail teilen

 Print this page
Print this pageDrucken
Im ersten Teil dieser Blogreihe haben wir die Bildähnlichkeitssuche vorgestellt und eine Architektur besprochen, mit der Sie die Komplexität reduzieren und die Implementierung vereinfachen können. Dieser Blogeintrag befasst sich mit den zugrunde liegenden Konzepten und technischen Aspekten der erforderlichen Komponenten für die Implementierung einer Anwendung mit Bildähnlichkeitssuche. Sie erfahren mehr über die folgenden Themen:
- Einbetten von Modellen: Machine-Learning-Modelle zum Generieren der numerischen Darstellung Ihrer Daten, um die Vektorsuche nutzen zu können
- Inferenz-Endpoint: API, mit der Sie die Einbettungsmodelle auf Ihre Daten in Elastic anwenden können
- Vektorsuche: Funktionsweise der Ähnlichkeitssuche mit dem Nächster-Nachbar-Algorithmus
- Generieren von Bildeinbettungen: Skalieren der Generierung numerischer Darstellungen für große Datensätze
- Anwendungslogik: Kommunikation zwischen interaktivem Frontend und der Vektorsuchmaschine im Backend
Mit diesen fünf Komponenten erhalten Sie eine Blaupause für die Implementierung intuitiver Sucherlebnisse mit der Vektorsuche in Elastic.
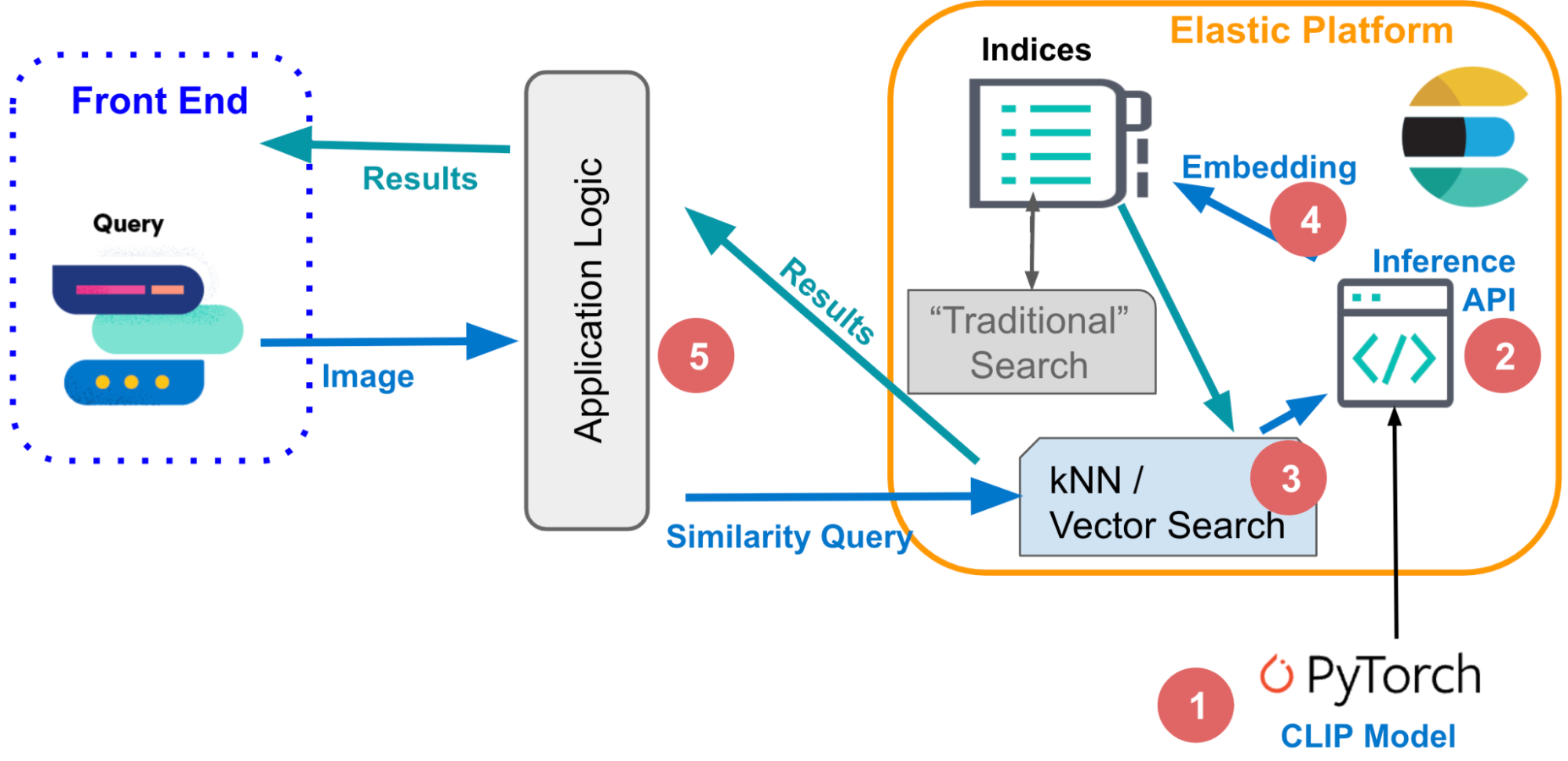
1. Einbettungsmodelle
Um die Ähnlichkeitssuche auf natürliche Sprache oder auf Bilddaten anwenden zu können, brauchen Sie Machine-Learning-Modelle, die Ihre daten in eine numerische Darstellung übersetzen, die man auch als Vektoreinbettung bezeichnet. Dieses Beispiel umfasst Folgendes:
- Das NLP-Transformationsmodell übersetzt natürliche Sprache in einen Vektor.
- Das OpenAI-CLIP-Modell (Contrastive Language-Image Pre-training) vektorisiert Bilder.
Transformationsmodelle sind spezielle Machine-Learning-Modelle, die natürliche Sprachdaten auf verschiedene Arten verarbeiten, etwa für Übersetzungen, Textklassifizierung oder zur Erkennung benannter Entitäten. Diese Modelle werden mit riesigen, kommentierten Textdatensätzen trainiert, um Muster und Strukturen der menschlichen Sprache kennenzulernen.
Die Bildähnlichkeitssuche findet Bilder anhand von Textbeschreibungen in natürlicher Sprache. Um eine solche Ähnlichkeitssuche zu implementieren, benötigen Sie ein Modell, das mit Text und mit Bildern trainiert wurde und das die Textabfrage in einen Vektor übersetzen kann. Mit diesem Vektor können Sie anschließend ähnliche Bilder finden.
Weitere Informationen zum Hochladen und Verwenden des NLP-Modells in Elasticsearch >>
CLIP ist ein umfangreiches Sprachmodell, das von OpenAI entwickelt wurde und sowohl Text als auch Bilder verarbeiten kann. Das Modell versucht, die Textbeschreibung eines Bilds mit einem kurzen Text als Eingabe vorherzusagen. Grafische und Textdarstellungen des Bilds müssen aufeinander abgestimmt werden, um mit dem Modell genaue Vorhersagen treffen zu können.
CLIP ist außerdem ein „Zero-Shot“-Modell und kann daher Aufgaben ausführen, für die es nicht speziell trainiert wurde. Es kann beispielsweise zwischen Sprachen übersetzen, die es beim Training nicht gesehen hat, oder Bilder in bisher unbekannte Kategorien einordnen. Mit diesen Eigenschaften ist CLIP ein sehr flexibles und vielseitiges Modell.
Sie werden das CLIP-Modell verwenden, um Ihre Bilder mit dem weiter unten beschriebenen Inferenz-Endpoint in Elastic zu vektorisieren. Anschließend führen Sie die Inferenz für eine große Anzahl an Bildern aus, wie in Abschnitt 3 weiter unten beschrieben.
2. Der Inferenz-Endpoint
POST _ml/trained_models/sentence-transformers__clip-vit-b-32-multilingual-v1/deployment/_infer
{
"docs" : [
{"text_field": "A mountain covered in snow"}
]
}3. Vector- (Ähnlichkeits-) Suche
Nachdem Sie sowohl Abfragen als auch Dokumente mit Vektoreinbettungen indexiert haben, sind einander ähnliche Dokumente die nächsten Nachbarn Ihrer Abfrage im Einbettungsraum. Dazu wird häufig der k-Nearest-Neighbor-Algorithmus (kNN) verwendet, mit dem Sie die k nächstgelegenen Vektoren zu einem Abfragevektor finden können. Für große Datensätze, wie sie üblicherweise in Bildsuchanwendungen verarbeitet werden, benötigt kNN jedoch Unmengen an Rechenressourcen, und die Ausführung kann unverhältnismäßig lang dauern. Die Lösung ist der geschätzte nächste Nachbar (Approximate Nearest Neighbor, ANN). Dieser Algorithmus ist nicht zu 100 % genau, wird jedoch auch in hochdimensionalen Einbettungsräumen sehr effizient und skalierbar ausgeführt.
Der Elastic-Endpoint „_search“ unterstützt Suchvorgänge mit kNN und mit ANN. Verwenden Sie den folgenden Code für die kNN-Suche. Der Code geht davon aus, dass die Einbettungen für sämtliche Bilder in your-image-index im Feld image_embedding verfügbar sind. Im nächsten Abschnitt erfahren Sie, wie Sie die Einbettungen erstellen können.
# Run kNN search against <query-embedding> obtained above
POST <your-image-index>/_search
{
"fields": [...],
"knn": {
"field": "image_embedding",
"k": 5,
"num_candidates": 10,
"query_vector": <query-embedding>
}
}Weitere Informationen zu kNN in Elastic finden Sie in unserer Dokumentation (momentan nur auf Englisch): https://www.elastic.co/guide/en/elasticsearch/reference/current/knn-search.html.
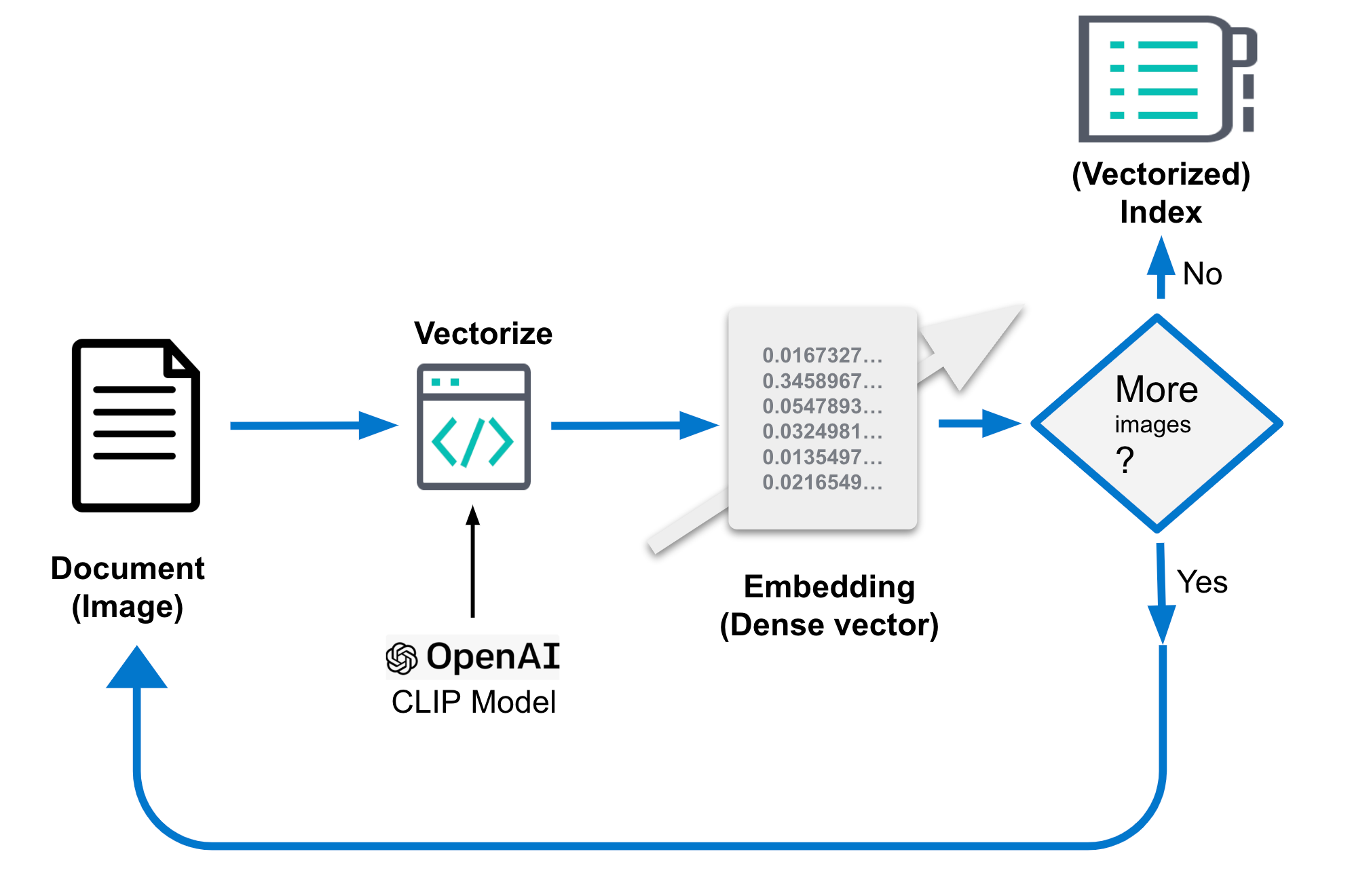
4. Generieren von Bildeinbettungen
Die oben genannten Bildeinbettungen sind entscheidend für die Leistung Ihrer Bildähnlichkeitssuche. Sie sollten in einem separaten Index gespeichert werden, der nur Bildeinbettungen enthält und im obigen Code als your-image-index bezeichnet wird. Der Index enthält ein Dokument pro Bild zusammen mit Feldern für den Kontext und die Dichtevektor-Interpretation (Bildeinbettung) des Bilds. Bildeinbettungen stellen ein Bild in einem niedrigdimensionalen Raum dar. Ähnliche Bilder werden in diesem Raum zu nahe beieinander liegenden Punkten zugeordnet. Das ursprüngliche Bild kann je nach Auflösung mehrere MB groß sein.
Der genaue Erstellungsvorgang für die Einbettungen hängt vom Einzelfall ab. Normalerweise werden dabei jedoch Merkmale der Bilder extrahiert und anschließend mit einer mathematischen Funktion zu einem niedrigdimensionalen Raum zugeordnet. Diese Funktion wird meistens mit einem großen Bilderdatensatz trainiert, um die Merkmale in diesem Raum möglichst gut darstellen zu können. Die Einbettungen werden nur einmal generiert.
In diesem Blogeintrag verwenden wir dafür das CLIP-Modell. Es wird von OpenAI bereitgestellt und liefert einen guten Ausgangspunkt. Für spezielle Anwendungsfälle und Leistungsanforderungen müssen Sie unter Umständen ein eigenes Einbettungsmodell trainieren. Dies hängt davon ab, wie gut die Arten von Bildern, die Sie klassifizieren möchten, in den öffentlichen Daten repräsentiert sind, mit denen das CLIP-Modell trainiert wurde.
Die Einbettung muss in Elastic beim Ingestieren generiert werden und erfolgt daher separat von der Suche mit den folgenden Schritten:
- CLIP-Modell laden
- Für jedes Bild:
- Bild laden
- Bild mit dem Modell bewerten
- Generierte Einbettungen in einem Dokument speichern
- Dokument im Datenspeicher bzw. in Elasticsearch speichern.
Der folgende Pseudocode verdeutlicht diese Schritte, und Sie finden den vollständigen Code im Beispiel-Repository.
...
img_model = SentenceTransformer('clip-ViT-B-32')
...
for filename in glob.glob(PATH_TO_IMAGES, recursive=True):
doc = {}
image = Image.open(filename)
embedding = img_model.encode(image)
doc['image_name'] = os.path.basename(filename)
doc['image_embedding'] = embedding.tolist()
lst.append(doc)
...Die folgende Abbildung ist ebenfalls hilfreich:
Nach der Verarbeitung könnte das Dokument in etwa so aussehen. Der entscheidende Teil ist das Feld „image_embedding“, das die Dichtevektor-Darstellung enthält.
{
"_index": "my-image-embeddings",
"_id": "_g9ACIUBMEjlQge4tztV",
"_score": 6.703597,
"_source": {
"image_id": "IMG_4032",
"image_name": "IMG_4032.jpeg",
"image_embedding": [
-0.3415695130825043,
0.1906963288784027,
.....
-0.10289803147315979,
-0.15871885418891907
],
"relative_path": "phone/IMG_4032.jpeg"
}
}5. Die Anwendungslogik
Wenn Sie diese Komponenten haben, können Sie das Puzzle zusammenfügen und die Logik vervollständigen, um eine interaktive Bildähnlichkeitssuche zu implementieren. Sehen wir uns zunächst an, was passieren muss, wenn Sie Bilder, die einer bestimmten Beschreibung entsprechen, interaktiv abrufen möchten.
Im Fall von Textabfragen reicht manchmal ein einziges Wort aus, wie etwa „Rosen“, oder eine ausführlichere Beschreibung wie „ein schneebedeckter Berg“. Als Alternative könnten Sie ein Bild vorlegen, um ähnliche Bilder abzurufen.
Obwohl Sie Ihre Abfrage auf unterschiedliche Arten formulieren, wird bei der zugrunde liegenden Vektorsuche immer dieselbe Abfolge von Schritten ausgeführt: eine Abfrage (kNN) über Dokumente, die durch ihre Einbettungen dargestellt werden (als „dichte“ Vektoren). Wir haben in der Vergangenheit bereits beschrieben, welche Mechanismen Elasticsearch einsetzt, um eine extrem schnelle und skalierbare Vektorsuche über große Bilddatensätze ausführen zu können. In dieser Dokumentation erfahren Sie mehr über die Effizienzoptimierung der kNN-Suche in Elastic.
- Also, wie können Sie die oben beschriebene Logik implementieren? Das folgende Ablaufdiagramm zeigt den Fluss der Informationen: Die Abfrage des Nutzers (als Text oder Bild) wird – je nach Eingabetyp – vom Einbettungsmodell vektorisiert: Ein NLP-Modell verarbeitet Textbeschreibungen, und das CLIP-Modell ist für Bilder zuständig.
- Beide Varianten konvertieren die Eingabe in eine numerische Darstellung und speichern das Ergebnis als Dichtevektor in Elasticsearch ([Zahl, Zahl, Zahl ...]).
- Die Vektordarstellung wird anschließend in einer kNN-Suche verwendet, um ähnliche Vektoren (Bilder) zu finden und als Ergebnis zurückzugeben.
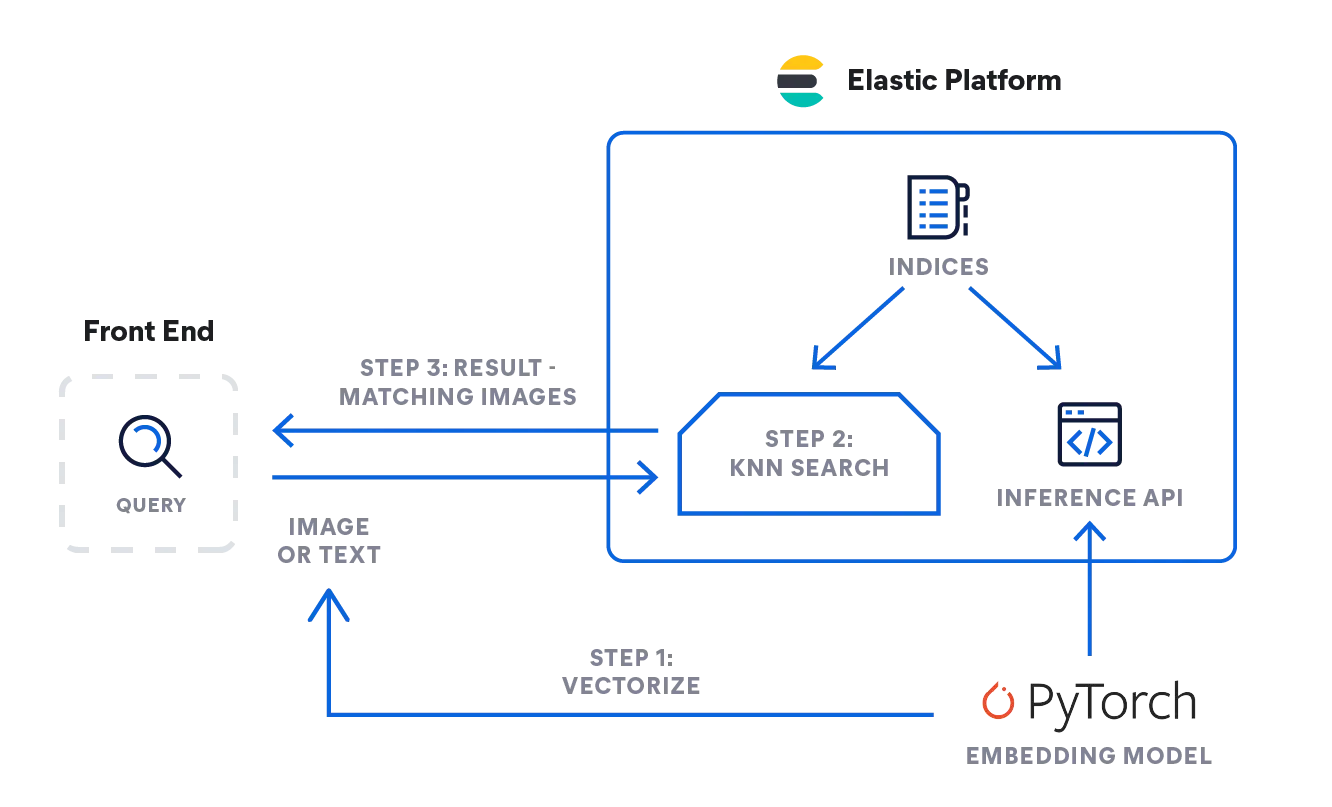
Inferenz: Vektorisieren von Benutzeranfragen
Die Anwendung läuft im Hintergrund und sendet eine Anfrage an die Inferenz-API in Elasticsearch. Für Textanfragen in etwa so:
POST _ml/trained_models/sentence-transformers__clip-vit-b-32-multilingual-v1/deployment/_infer
{
"docs" : [
{"text_field": "A mountain covered in snow"}
]
}Für Bilder können Sie mit dem folgenden vereinfachten Code ein einzelnes Bild mit dem CLIP-Modell verarbeiten, das Sie vorab auf Ihrem Elastic-Machine-Learning-Knoten laden müssen.
model = SentenceTransformer('clip-ViT-B-32')
image = Image.open(file_path)
embedding = model.encode(image)Als Rückgabe erhalten Sie ein Float32-Array mit 512 Elementen:
{
"predicted_value" : [
-0.26385045051574707,
0.14752596616744995,
0.4033305048942566,
0.22902603447437286,
-0.15598160028457642,
...
]
}Suche: nach ähnlichen Bildern
Die Suche funktioniert für beide Eingabetypen gleich. Senden Sie die Abfrage mit der kNN-Suchdefinition an den Index mit den Bildeinbettungen: „my-image-embeddings“. Fügen Sie den Dichtevektor aus der vorherigen Anfrage ("query_vector": [ ... ]) ein und führen Sie die Suche aus.
GET my-image-embeddings/_search
{
"knn": {
"field": "image_embedding",
"k": 5,
"num_candidates": 10,
"query_vector": [
-0.19898493587970734,
0.1074572503566742,
-0.05087625980377197,
...
0.08200495690107346,
-0.07852292060852051
]
},
"fields": [
"image_id", "image_name", "relative_path"
],
"_source": false
}Daraufhin gibt Elasticsearch die in Elasticsearch als Dokumente gespeicherten Bilder mit der besten Übereinstimmung auf Basis unserer kNN-Suchabfrage zurück.
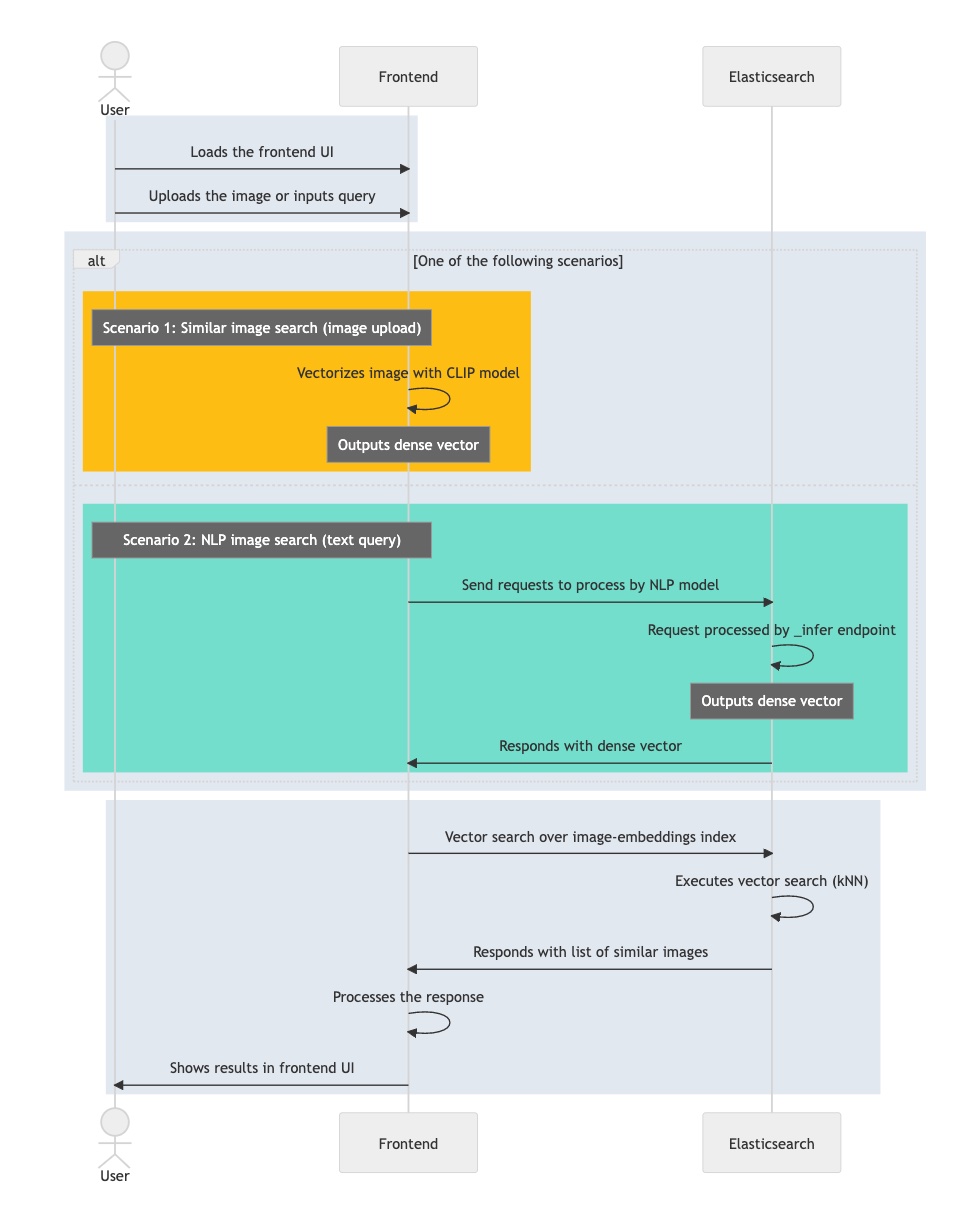
Das folgende Ablaufdiagramm zeigt die Schritte in Ihrer interaktiven Anwendung beim Verarbeiten einer Benutzerabfrage:
- Sie laden die interaktive Anwendung (Frontend).
- Der Nutzer wählt ein Bild aus, für das er sich interessiert.
- Ihre Anwendung vektorisiert das Bild mit dem CLIP-Modell und speichert die resultierende Einbettung als Dichtevektor.
- Die Anwendung führt eine kNN-Abfrage in Elasticsearch aus, die die Einbettung entgegennimmt und deren nächste Nachbarn zurückgibt.
- Ihre Anwendung verarbeitet die Antwort und stellt ein übereinstimmendes Bild (oder mehrere Bilder) dar.
Jetzt kennen Sie die wichtigsten Komponenten und den Informationsfluss für die Implementierung einer interaktiven Bildähnlichkeitssuche und können im letzten Teil der Reihe herausfinden, wie Sie dieses Wissen praktisch umsetzen können. Dort finden Sie eine Schritt-für-Schritt-Anleitung, mit der Sie die Anwendungsumgebung einrichten, das NLP-Modell importieren und zuletzt die Generierung der Bildeinbettung abschließen können. Anschließend können Sie natürliche Sprache verwenden, um nach Bildern zu suchen – ohne jegliche Schlüsselwörter.
Teilen
- Share on Twitter
Auf Twitter teilen
- Share on LinkedIn
Auf LinkedIn teilen
- Share on Facebook
Auf Facebook teilen
- Share by Email
Per E-Mail teilen
- Print this page
Drucken