即时决策
凭借 Kibana 的数据实时可视化与挖掘能力,Delhivery 可迅速做出运营决策,不断提升服务质量与效率。
递送网络效率高达 90%
Delhivery 能够快速发现并解决递送网络中的拥堵情况,在保持高效能的同时,最大程度降低整体延误时间。
灵活扩展与试用
Elastic Cloud 中的 Elasticsearch 服务帮助 Delhivery 无缝扩展部署范围,同时还可轻松拥有 Elastic Stack 中的全部最新功能。这项特性有益于 Delhivery 将重心专注于拓展物流业务,而无需在管理 IT 基础架构上耗费过多精力。
公司概览
Delhivery 成立于 2011 年,从最初主营最后一公里递送的小型企业,快速成长为印度领先的供应链服务提供商。公司拥有由 19 个自动分拣中心、数千个递送中心、14,000 辆运送车以及 21,000 位员工构成的庞大网络,平均每天递送的包裹数达 100 万件。
正是由于 Delhivery 不断优化其递送网络速度,才能够从激烈的竞争中脱颖而出,并最终颠覆了印度物流产业。在 Elastic Stack 丰富的信息和分析结果支持下,Delhivery 为超过 100,000 家客户提供极富成本效率且快速高效的物流服务,涵盖中小型企业、大型企业以及行业领先的电子商务平台。这些信息和分析大大加快了决策过程,是 Delhivery 成功制胜的关键因素。
Elastic 让我们能够在三十分钟甚至更短的时间内做出决策,这是最为关键的要素,对成本、收入、服务以及利益相关者关注的所有其他方面都有着巨大的影响。
Delhivery 与 Elastic 的合作历程
助力第三方物流实现卓越运营
Delhivery 成立于 2011 年,最初仅提供本地递送服务,主营靠近德里边界古尔冈地区食品和鲜花等物品的最后一公里递送。但是,距离创立仅仅过了数月,公司联合创始人就开始将目光投向了前景更为广阔的电子商务行业。彼时电子商务在印度才刚刚起步,但公司联合创始人已经看到了它的巨大潜力。2011 年中,Delhivery 赢得了首家电子商务客户。自此之后,Delhivery 一直专注于解决电子商务中的物流难题,尤其是递送速度。
在电子商务发展初期,物流速度是一个无法回避的痛点。这不只关乎买家的体验,也让卖家面临巨大挑战。印度经济以现金交易为主,大多数卖家需要等待快递送达后才能收款。因此如果物流受到延误,利润实现也会滞后。
Delhivery 解决这一问题的唯一途径就是不断优化整个递送网络的运营效率。在 Elastic 的协助下,Delhivery 取得了巨大的进展。Elastic Stack 帮助 Delhivery 对每天从递送网络中采集的数百万个数据点进行搜索、分析及可视化处理。凭借这些分析结果,公司的递送速度与效率得到持续提升,并塑造了物流行业的未来发展方向。
业务与数据爆发式增长
为了维持高效的运营,Delhivery 需要随时掌握公司的所有业务信息。每过 20 秒,Delhivery 就会从实际递送中采集数据,包括所有货件的尺寸、位置与状态。随着时间推移,每个包裹所涉及的数据点累计将超过 50 个,这些数据为构建智能高效的递送网络奠定了坚实的基础。
最开始,数据由 MongoDB 建立索引并分析。但随着第二年 Delhivery 每日递送包裹量由 500 件提升至 9,000 件,数据量也同样大幅度增长。对数据进行深入分析并从中提炼出新的洞见从而提升效率的难度与耗时随之增加。
“我们不断尝试各种工具与技术,并从中寻找能够简化数据汇总与挖掘流程的解决方案。”联合创始人兼首席技术官 Kapil Bharati 说道:“在这个过程中,我们看到由 Kibana 提供的一些仪表板。我们就想,何不把我们所有数据都融入 Elastic 中?很快我们就拥有了一款得心应手的强大工具。”
提升效率与速度
Delhivery 的首款应用程序采用 Elastic Stack 2.x,于 2013 年发布,通过一系列定制仪表板帮助电子商务卖家追踪其物流状态。如今,这些仪表板仍广为应用,为卖家提供所有包裹的实时地理位置数据,从而降低对 Delhivery 呼叫中心的依赖。
现在,公司内部也启用了大量仪表板来追踪包裹与效能。在 Kibana 技术的支持下,这些仪表板能够帮助 Delhivery 调度团队快速发现递送网络中的拥堵或延迟情况。随后,该团队能够以可视化的方式挖掘深层数据,从而发现问题的根源。
“利用 Kibana,我们能够实时了解所有业务信息。如果我们发现某个位置出现了货件阻滞,就能立即解决问题并提前通知我们的客户。”Kapil 说道。
通过对这些数据随时间变化的趋势进行更深入分析,Delhivery 还发现了改进效能的机会,其中包括优化包裹运送路线或扩大团队成员规模以应对业务高峰期。
“Kibana 最令人惊叹的一点在于您无需成为技术专家即可使用,因此我们的运营团队能够创建定制的复杂仪表板,以帮助他们更好地做出决策。”Kapil 说道。
提高智能化与扩展性
Delhivery 最初自行管理集群,但随着业务规模的扩展,以及面临着印度节假日期间活动量的激增,这一模式变得越来越困难重重。为了应对扩展与托管过程中遇到的难题,Delhivery 成为了 Elasticsearch 服务的早期用户之一(如今该服务位于 Elastic Cloud 中,但当时仍属于 Found.no)。自那时起,Delhivery 与 Elastic 间的合作关系随着业务发展日益加深。
“迁移到托管服务后,我们具有更大的扩展灵活性,并可将重心专注于核心业务上。”Elasticsearch 架构师兼高级工程经理 Karan Argarwal 说道:“这些年来我们也尝试了其他产品,包括亚马逊的 Elasticsearch 产品,但我们最终还是选择继续使用 Elasticsearch 服务,原因在于这款产品由专家运营,并且始终能够为我们提供 Elastic Stack 的最新功能。”
在 Elastic 支持团队的帮助下,Delhivery 最近还由 5.x 版本无缝升级到了 6.5 版本,新功能的引入可为公司创造更多价值。本次升级还向集群中引入了专门的节点类型,在优化内存与 CPU 的同时还能稳定性能。
Delhivery 每天都会采集超过 500 万个数据点,包括包裹地理位置数据。这些数据依次经过 Kafka 流和 Logstash 后,最终会进入 Elasticsearch 集群,用于为 Kibana 仪表板和定制应用提供信息。
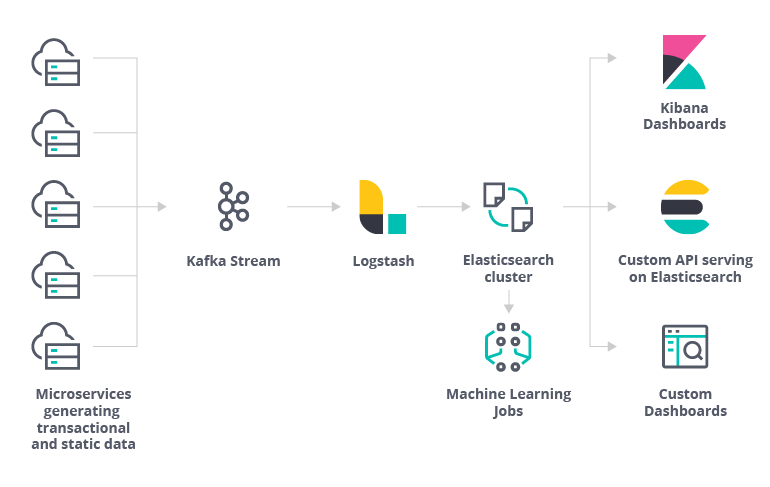
交易/事件数据体系结构
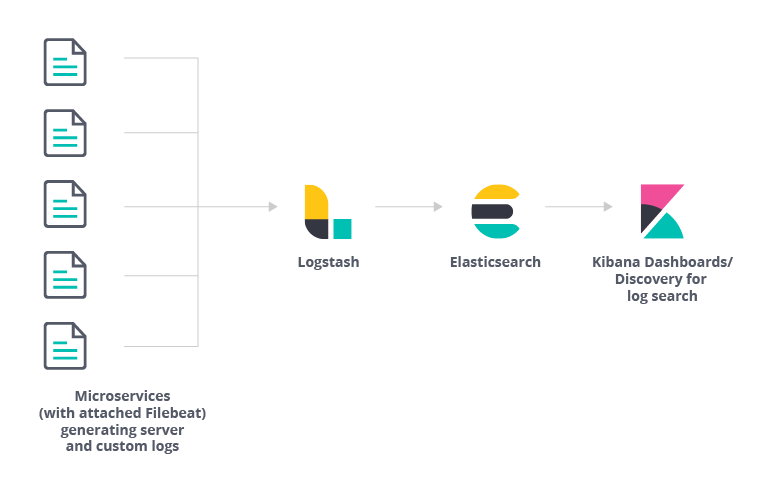
日志数据体系结构
日常运营的管理与监测仍然主要由 Kibana 负责,而 Elastic Stack 中的安全功能则用于控制每个人对不同数据的访问权限。这让 Delhivery 在确保数据安全性与隐私性的同时,还能向整个公司团队开放 Kibana,并最终开放给电子商务客户。
公司团队可在 Kibana 中查看各种运营指标,并利用 Elasticsearch 分析异常与趋势。举例来说,如果调度团队发现递送网络的效能下降至 97%,就可深入挖掘每个工作现场的效能,不断筛选数据直至发现问题。调度团队还能利用 Elastic Stack API 构建带有嵌入式可视化效果的前端工具,选择性监测递送网络的特定方面。
“支持 Elastic Stack 的 API 接口与文档相当完善,在出现不同需求时,我们可以轻松地进行各种尝试,并快速构建出新的工具与可视化效果。”Karan 说道:“对于我们这样一家在业内不断创新的企业来说,这简直是我见过的最棒的文档了。”
从最后一公里配送企业到世界级的物流提供商
得益于 Elastic 的积极支持,Delhivery 集群的健全性与稳定性不断优化,并且始终能够享受到 Elastic Stack 的最新功能与特性。公司目前正在探索使用 Elastic APM 监测和提醒运输与仓库管理系统、微服务以及扩展的请求与互操作性可视化堆栈轨迹。Delhivery 还在研究采用 Canvas 为现场团队打造插入式仪表板的可行性,从而减少各类用例中对于自建仪表板的依赖。这些仪表板将为操作人员与管理人员提供一目了然且可操作的数据,实时显示出每个场所的包裹数量波动以及其它事件。
“我们正在进行更多的尝试,不断了解机器学习等新功能与新产品,以便让我们的调度团队能够对递送网络的容量与效能做出更准确的预测。例如,如果某个中心的业务量激增,那么我们就能分析其他场所后续可能发生的状况。”Kapil 说道。
通过机器学习以及 Canvas 和 Elastic APM 的潜在用例所带来的智能与效率,将帮助 Delhivery 大大提升业务扩展与创新能力。如今,Elastic Stack 正在帮助 Delhivery 从资源调度到场所选址的各个方面更快更好地做出决策。但他们的宏伟蓝图远不止于此,下一步他们将打造出可以广泛适用的操作系统与平台,给物流行业带来更大颠覆。
Delhivery 集群
- 集群2
- 托管环境AWS 上 Elastic Cloud 中的 Elasticsearch 服务
- 文档Express 集群 - 86,906,895
核心集群 - 94,409,502 - 每日采集量Express 集群 - 平均 470/秒,最大 1000/秒
核心集群 - 平均 10/秒,最大 50/秒
- 索引Express 集群(按 2 个别名分组的月度指数) - 29
核心集群 - 15 - 查询速度Express 集群 - 平均 270/秒,最大 400/秒
核心集群 - 平均 10/秒,最大 15/秒 - 节点规格核心集群:3 个高 cpu m5 实例,每个配备 8GB 内存和 64GB 硬盘空间
Monitoring:1 个高 I/O 经典实例,配备 4GB 内存和 96GB 硬盘空间
Express: 4 个高 I/O 数据实例,每个配备 58GB 内存和 1.7TB 硬盘空间
3 个 Master r4 实例,每个配备 4GB 内存和 8GB 硬盘空间;2 个 Ml m5 实例,每个配备 4GB 内存和 8GB 硬盘空间